深入解析Linux文件描述符:原理、机制与应用实践
目录
一、什么是文件描述符
二、文件描述符的本质
三、标准文件描述符
四、文件描述符相关系统调用
1、open() - 打开文件
2、close() - 关闭文件描述符
3、read() - 从文件描述符读取数据
4、write() - 向文件描述符写入数据
5、dup()/dup2() - 复制文件描述符
五、文件描述符的底层原理
内核中的三级结构
1、进程级文件描述符表
2、系统级打开文件表
3、文件系统inode表
六、FILE* 结构
1、FILE* 的基本概念
2、FILE 结构通常包含的内容
3、标准I/O函数与FILE*
文件打开与关闭
文件读写
文件定位
错误处理
4、缓冲机制(重点!!!)
1. setbuf 函数
功能
参数说明
特点
示例
2. setvbuf 函数
功能
参数说明
返回值
特点
示例
3. 两个函数的比较
5、标准流
6、注意事项
7、底层实现
8、性能考虑
七、文件描述符与内核文件管理机制解析
1、进程和文件之间的对应关系是如何建立的?
2、什么叫做进程创建的时候会默认打开0、1、2?
3、磁盘文件 VS 内存文件
八、文件描述符的分配规则
一、什么是文件描述符
文件描述符(File Descriptor, 简称fd)是Linux系统中用于访问文件或其他输入/输出资源的抽象指示符,它是一个非负整数。在Linux系统中,所有对文件或设备的操作都是通过文件描述符完成的。
二、文件描述符的本质
-
内核数据结构索引:文件描述符实际上是进程文件描述符表的索引,通过它可以找到对应的文件表项和inode表项
-
进程级资源:每个进程都有自己独立的文件描述符空间
-
非负整数:范围通常是0到
RLIMIT_NOFILE-1(默认1024,可调整)
三、标准文件描述符
每个Linux进程启动时都会自动打开三个标准文件描述符:
| 文件描述符 | 名称 | 符号常量 | 默认连接 |
|---|---|---|---|
| 0 | 标准输入 | STDIN_FILENO | 键盘 |
| 1 | 标准输出 | STDOUT_FILENO | 终端 |
| 2 | 标准错误 | STDERR_FILENO | 终端 |
因此,输入输出操作也可以采用以下方式实现:
#include <stdio.h>
#include <unistd.h>
#include <string.h>int main() {char buf[1024];ssize_t s = read(0, buf, sizeof(buf));if(s > 0) {buf[s] = 0;write(1, buf, strlen(buf));write(2, buf, strlen(buf));}return 0;
}
这段代码实现了一个简单的功能,从标准输入(键盘)读取数据,并将数据同时写入标准输出(屏幕)和标准错误输出(屏幕):
四、文件描述符相关系统调用
1、open() - 打开文件
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);示例:
int fd = open("file.txt", O_RDONLY); // 只读方式打开
if (fd == -1) {perror("open failed");
}2、close() - 关闭文件描述符
#include <unistd.h>
int close(int fd);3、read() - 从文件描述符读取数据
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);4、write() - 向文件描述符写入数据
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);5、dup()/dup2() - 复制文件描述符
#include <unistd.h>
int dup(int oldfd);
int dup2(int oldfd, int newfd);五、文件描述符的底层原理
内核中的三级结构
1、进程级文件描述符表
-
每个进程独有
-
包含该进程打开的文件描述符
-
每个条目指向文件表中的一个条目
2、系统级打开文件表
-
全局共享
-
包含文件状态标志、当前偏移量、指向inode的指针等
-
多个文件描述符可以指向同一个文件表条目
3、文件系统inode表
-
包含文件的元数据(权限、大小等)和数据块位置
-
每个inode在文件系统中唯一
六、FILE* 结构
FILE* 是C语言标准I/O库中的一个重要概念,它代表一个指向文件流的指针。
1、FILE* 的基本概念
FILE* 是一个指向FILE结构的指针,FILE结构包含了操作系统进行文件操作所需的全部信息。在标准C库中,FILE结构的具体实现是隐藏的(不透明类型),不同平台可能有不同的实现细节。
2、FILE 结构通常包含的内容
虽然具体实现可能不同,但FILE结构通常包含以下信息:
-
文件描述符(底层I/O使用)
-
文件位置指针(当前读写位置)
-
缓冲区指针和大小
-
错误和文件结束标志
-
文件访问模式(读、写、追加等)
3、标准I/O函数与FILE*
标准I/O库提供了一系列操作FILE*的函数:
文件打开与关闭
FILE *fopen(const char *filename, const char *mode);
int fclose(FILE *stream);文件读写
int fgetc(FILE *stream);
int fputc(int c, FILE *stream);
char *fgets(char *s, int size, FILE *stream);
int fputs(const char *s, FILE *stream);
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);文件定位
int fseek(FILE *stream, long offset, int whence);
long ftell(FILE *stream);
void rewind(FILE *stream);错误处理
int feof(FILE *stream);
int ferror(FILE *stream);
void clearerr(FILE *stream);4、缓冲机制(重点!!!)
标准I/O库使用缓冲机制提高效率,缓冲类型包括:
-
全缓冲:缓冲区满时才进行实际I/O操作
-
行缓冲:遇到换行符或缓冲区满时进行I/O
-
无缓冲:立即进行I/O操作
可以使用以下函数控制缓冲:
void setbuf(FILE *stream, char *buf);
int setvbuf(FILE *stream, char *buf, int mode, size_t size);1. setbuf 函数
功能
用于为指定的文件流设置缓冲区。
参数说明
-
stream:要设置缓冲的文件流指针 -
buf:指向用户提供的缓冲区的指针
特点
-
如果
buf为NULL,流将被设置为无缓冲 -
如果
buf不为NULL,它必须指向一个长度至少为BUFSIZ的字符数组 -
缓冲区会在流打开后、任何I/O操作前设置
-
通常用于设置全缓冲(但标准没有明确规定)
示例
#include <stdio.h>int main() {char buffer[BUFSIZ];FILE *fp = fopen("file.txt", "w");setbuf(fp, buffer); // 使用自定义缓冲区// 或者 setbuf(fp, NULL); // 设置为无缓冲fputs("This is a test", fp);fclose(fp);return 0;
}2. setvbuf 函数
功能
提供比setbuf更精细的缓冲控制,可以指定缓冲类型和大小。
参数说明
-
stream:要设置缓冲的文件流指针 -
buf:指向用户提供的缓冲区的指针 -
mode:缓冲模式,可以是:-
_IOFBF:全缓冲 -
_IOLBF:行缓冲 -
_IONBF:无缓冲
-
-
size:缓冲区大小
返回值
成功返回0,失败返回非0值(通常是参数无效)
特点
-
如果
buf为NULL,库会自动分配缓冲区 -
size参数指定缓冲区大小 -
必须在流打开后、任何I/O操作前调用
-
比
setbuf更灵活,可以精确控制缓冲类型和大小
示例
#include <stdio.h>int main() {char buffer[1024];FILE *fp = fopen("file.txt", "w");// 设置行缓冲,使用自定义缓冲区,大小为1024if (setvbuf(fp, buffer, _IOLBF, sizeof(buffer)) != 0) {perror("Failed to set buffer");return 1;}fputs("This is a line buffered test\n", fp);fclose(fp);return 0;
}3. 两个函数的比较
| 特性 | setbuf | setvbuf |
|---|---|---|
| 缓冲类型控制 | 有限 | 精确控制(全/行/无) |
| 缓冲区大小 | 固定为BUFSIZ | 可自定义 |
| 自动分配缓冲 | 不支持 | 支持(当buf为NULL时) |
| 返回值 | 无 | 有(可检测错误) |
| 灵活性 | 低 | 高 |
5、标准流
C程序启动时自动打开三个标准流:
FILE *stdin; // 标准输入
FILE *stdout; // 标准输出
FILE *stderr; // 标准错误6、注意事项
-
错误检查:每次文件操作后都应检查是否成功
-
资源释放:使用fclose()关闭文件释放资源
-
缓冲同步:fflush()可以强制将缓冲区内容写入文件
-
线程安全:在多线程环境中需要注意文件操作的同步
7、底层实现
在Unix-like系统中,FILE*通常封装了文件描述符和缓冲机制。例如:
struct _IO_FILE {int _flags; /* High-order word is _IO_MAGIC; rest is flags. */char* _IO_read_ptr; /* Current read pointer */char* _IO_read_end; /* End of get area. */char* _IO_read_base; /* Start of putback+get area. */char* _IO_write_base; /* Start of put area. */char* _IO_write_ptr; /* Current put pointer. */char* _IO_write_end; /* End of put area. */char* _IO_buf_base; /* Start of reserve area. */char* _IO_buf_end; /* End of reserve area. */int _fileno; /* File descriptor */// ... 其他成员
};Windows系统中的实现会有所不同,但概念类似。
8、性能考虑
-
减少频繁的小量I/O操作,使用缓冲机制
-
考虑适当的缓冲区大小
-
在需要时使用无缓冲I/O
FILE* 提供了比底层文件描述符更高级、更方便的接口,适合大多数应用程序的文件操作需求。
七、文件描述符与内核文件管理机制解析
进程在运行时需要打开文件,进程通过执行open系统调用与文件建立关联,每个进程可能同时打开多个文件。由于系统中同时运行着大量进程,因此任何时候都可能存在数量可观的已打开文件。
为了高效管理这些已打开的文件,操作系统会为每个文件创建对应的struct file结构体,并通过双向链表将这些结构体组织起来。这样,操作系统对文件的管理就转化为对该链表的增删查改等操作。
此外,为了明确哪些打开的文件属于特定进程,还需要建立进程与文件之间的对应关系。
1、进程和文件之间的对应关系是如何建立的?
当程序启动运行时,操作系统会将其代码和数据载入内存,同时创建相应的task_struct、mm_struct和页表等数据结构,并通过页表建立虚拟内存到物理内存的映射关系:
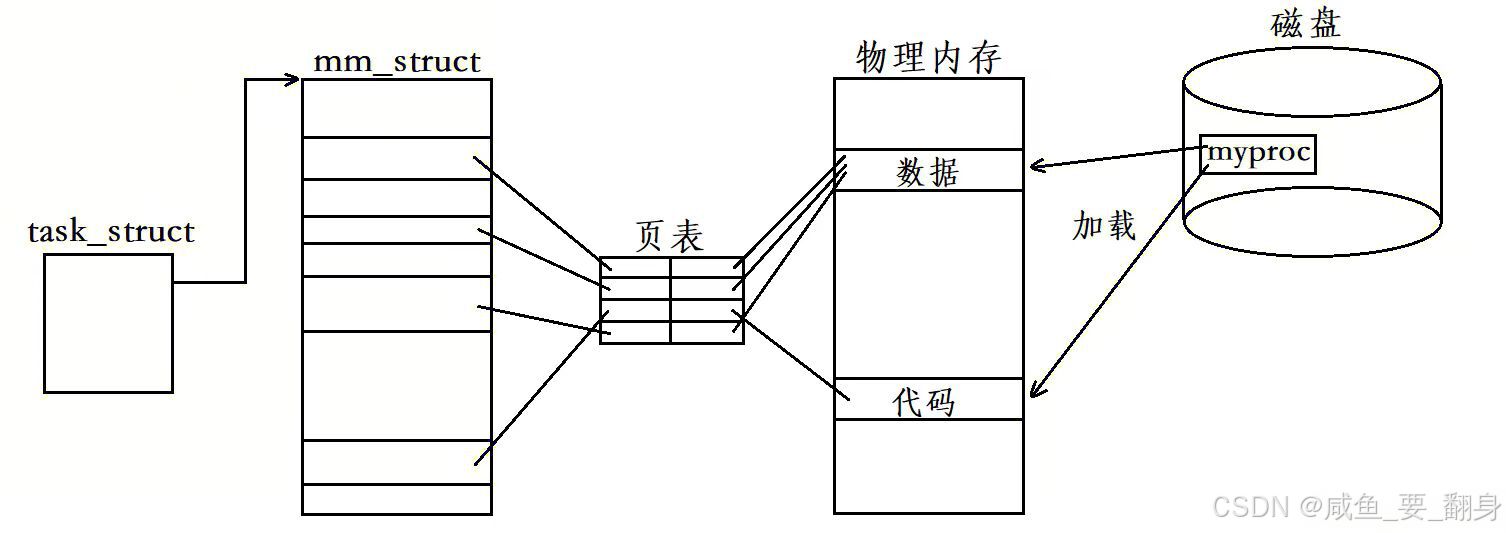
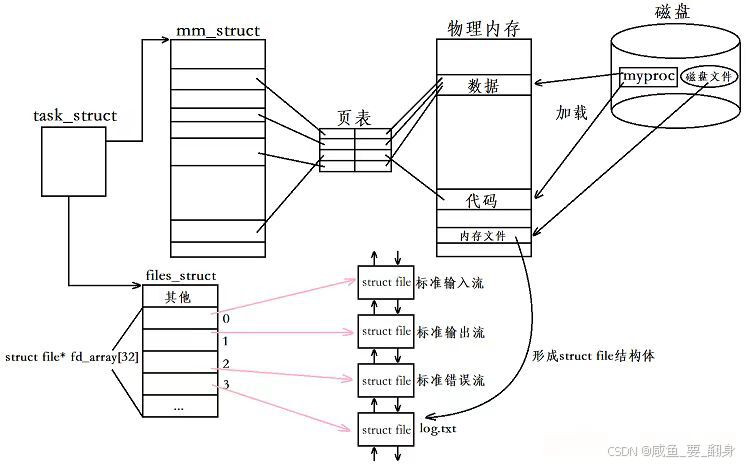
在task_struct结构中,存在一个指向files_struct结构体的指针。files_struct内部包含一个名为fd_array的指针数组,其数组下标就是我们所说的文件描述符。
当进程打开log.txt文件时,系统首先将该文件从磁盘加载到内存,生成对应的struct file结构。接着将这个struct file插入文件双链表,并将其首地址存入fd_array数组下标为3的位置。此时,fd_array[3]指针便指向了这个struct file,最终系统将文件描述符3返回给调用进程,因此,通过文件描述符就能找到对应的文件:
我们可以通过内核源码验证上述原理:
1、首先定位task_struct结构体在内核中的位置:/usr/src/kernels/3.10.0-1160.71.1.el7.x86_64/include/linux/sched.h (注:3.10.0-1160.71.1.el7.x86_64是内核版本,可通过uname -a查看服务器配置,由于该文件夹唯一,无需刻意分辨具体版本)

2、查看方法:
- 可直接使用VSCode在Windows下打开内核源代码,如果不行就使用这个网站查看源码对应的内核结构:sched.h - include/linux/sched.h - Linux source code v6.14.8 - Bootlin Elixir Cross Referencer
- 相关结构体位置:
- struct task_struct:/usr/src/kernels/3.10.0-1160.71.1.el7.x86_64/include/linux/sched.h
- struct files_struct:/usr/src/kernels/3.10.0-1160.71.1.el7.x86_64/include/linux/fdtable.h
- struct file:/usr/src/kernels/3.10.0-1160.71.1.el7.x86_64/include/linux/fs.h
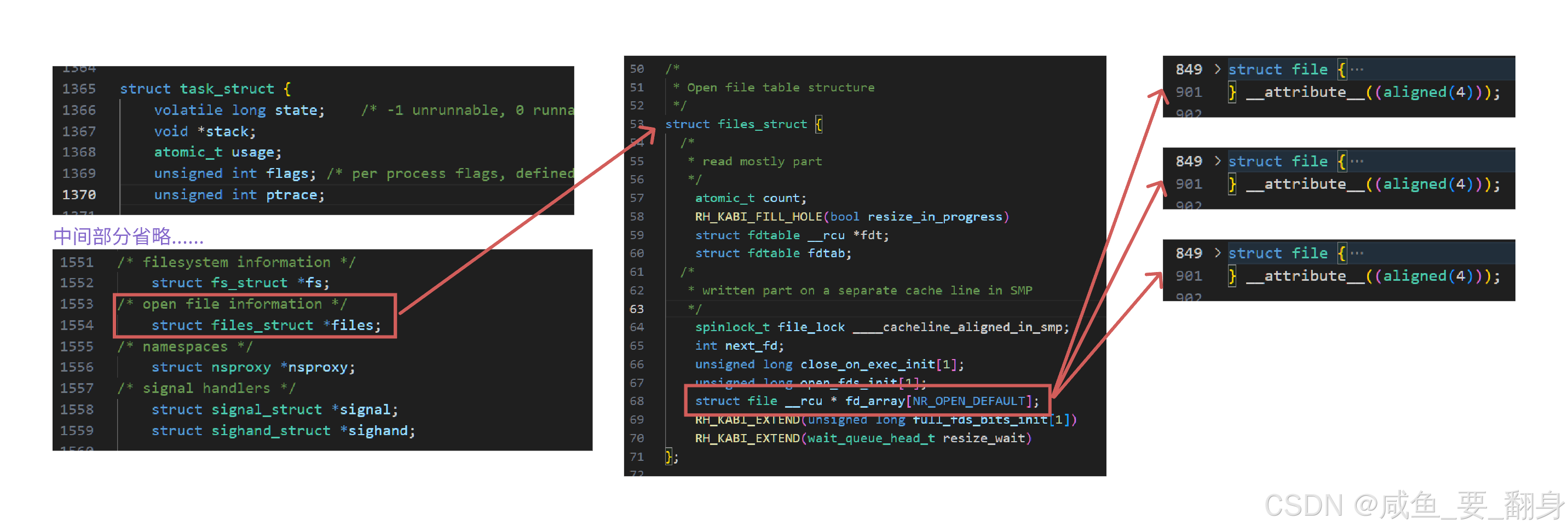
通过文件描述符,我们可以获取文件的相关信息,进而执行各类输入输出操作。
注意:文件写入操作会先将数据存入对应的文件缓冲区,之后才会定期将缓冲区数据同步到磁盘。
2、什么叫做进程创建的时候会默认打开0、1、2?
关于进程创建时默认打开的0、1、2描述符:
- 0代表标准输入流(stdin),对应键盘输入
- 1代表标准输出流(stdout),对应显示器输出
- 2代表标准错误流(stderr),同样对应显示器输出
由于键盘和显示器都是硬件设备,操作系统能够直接识别。当进程创建时,系统会:
- 为这三个设备创建对应的struct file结构体
- 将这些结构体链入文件双链表
- 将它们的地址分别存入fd_array数组的0、1、2位置,这样就完成了标准输入/输出/错误流的默认打开操作。
3、磁盘文件 VS 内存文件
- 文件存储在磁盘上时称为磁盘文件,加载到内存后则称为内存文件。
- 这种关系类似于程序与进程的关系:程序运行时成为进程,磁盘文件加载到内存则成为内存文件。
- 磁盘文件包含两个部分:文件内容和文件属性。文件内容指存储的实际数据,而文件属性则包括文件名、文件大小、创建时间等基本信息,这些属性也被称为元信息。
- 因为这些文件属性的元信息存在,所以即使文件中没有任何内容,该文件也是有大小的。
- 当文件被加载到内存时,系统通常先加载文件的属性信息。只有在需要进行读取、输入或输出等操作时,才会延迟加载文件的具体数据内容。
八、文件描述符的分配规则
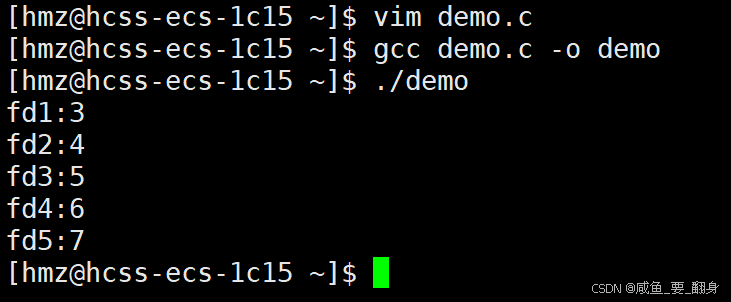
尝试连续打开五个文件,看看这五个打开后获取到的文件描述符:
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main()
{umask(0);int fd1 = open("log1.txt", O_RDONLY | O_CREAT, 0666);int fd2 = open("log2.txt", O_RDONLY | O_CREAT, 0666);int fd3 = open("log3.txt", O_RDONLY | O_CREAT, 0666);int fd4 = open("log4.txt", O_RDONLY | O_CREAT, 0666);int fd5 = open("log5.txt", O_RDONLY | O_CREAT, 0666);printf("fd1:%d\n", fd1);printf("fd2:%d\n", fd2);printf("fd3:%d\n", fd3);printf("fd4:%d\n", fd4);printf("fd5:%d\n", fd5);return 0;
}
这五个文件的文件描述符都是从3开始连续递增的,这是因为文件描述符本质上是数组索引。进程创建时会默认打开标准输入、标准输出和标准错误流,它们已经占用了0、1、2这三个位置,所以后续分配只能从3开始:
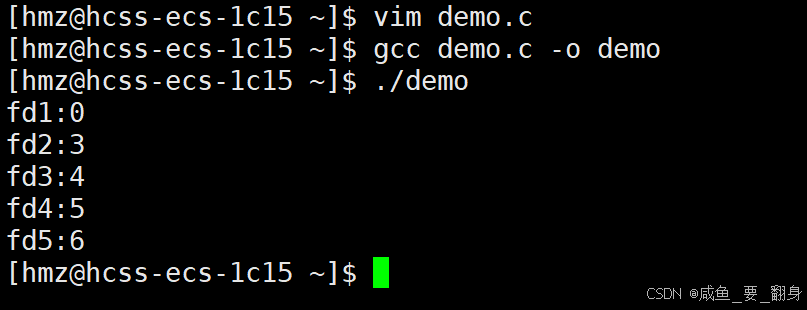
如果我们先关闭文件描述符0,再打开这五个文件,文件描述符的分配会如何变化?如下:
close(0);#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main()
{umask(0);close(0);int fd1 = open("log1.txt", O_RDONLY | O_CREAT, 0666);int fd2 = open("log2.txt", O_RDONLY | O_CREAT, 0666);int fd3 = open("log3.txt", O_RDONLY | O_CREAT, 0666);int fd4 = open("log4.txt", O_RDONLY | O_CREAT, 0666);int fd5 = open("log5.txt", O_RDONLY | O_CREAT, 0666);printf("fd1:%d\n", fd1);printf("fd2:%d\n", fd2);printf("fd3:%d\n", fd3);printf("fd4:%d\n", fd4);printf("fd5:%d\n", fd5);return 0;
}
可以看到,第一个打开的文件获取的文件描述符为0,而后续打开的文件描述符仍从3开始依次递增:
我们再尝试在打开这五个文件之前,先关闭文件描述符0和2(注意保留文件描述符1,因为关闭显示器文件会导致程序无法输出结果):
close(0);
close(2);
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main()
{umask(0);close(0);close(2);int fd1 = open("log1.txt", O_RDONLY | O_CREAT, 0666);int fd2 = open("log2.txt", O_RDONLY | O_CREAT, 0666);int fd3 = open("log3.txt", O_RDONLY | O_CREAT, 0666);int fd4 = open("log4.txt", O_RDONLY | O_CREAT, 0666);int fd5 = open("log5.txt", O_RDONLY | O_CREAT, 0666);printf("fd1:%d\n", fd1);printf("fd2:%d\n", fd2);printf("fd3:%d\n", fd3);printf("fd4:%d\n", fd4);printf("fd5:%d\n", fd5);return 0;
}
系统会优先分配较小的文件描述符,因此前两个打开的文件获取到0和2的标识符,后续打开的文件描述符则从3开始按顺序递增:
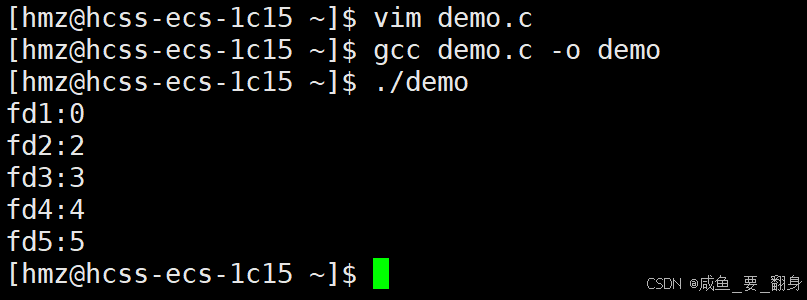
结论: 文件描述符会优先分配当前未被使用的最小fd_array数组下标。