Fish Speech:开源多语言语音合成的革命性突破
一、项目概述
Fish Speech 是由 FishAudio 团队开发的高性能文本转语音(TTS)引擎,主打 多语言支持、低门槛部署 和 个性化语音克隆。核心亮点包括:
- 模型轻量化:亿级参数规模,支持消费级显卡(最低 4GB 显存)运行 。
- 零样本克隆:仅需 10–30 秒语音样本,即可生成个性化音色。
- 多语言覆盖:支持中、英、日、韩等 13 种语言,跨语言合成无需切换模型。
典型应用:有声书制作、虚拟助手、无障碍阅读、实时交互系统。
二、核心技术解析
- 模型架构
Fish Speech 融合三大先进技术:- Transformer 骨干网络:处理长序列文本,捕捉上下文依赖。
- VQ-VAE(向量量化变分自编码器):压缩语音特征为离散向量,提升合成效率。
- VITS 端到端合成:直接生成高保真波形,跳过传统声码器环节 。
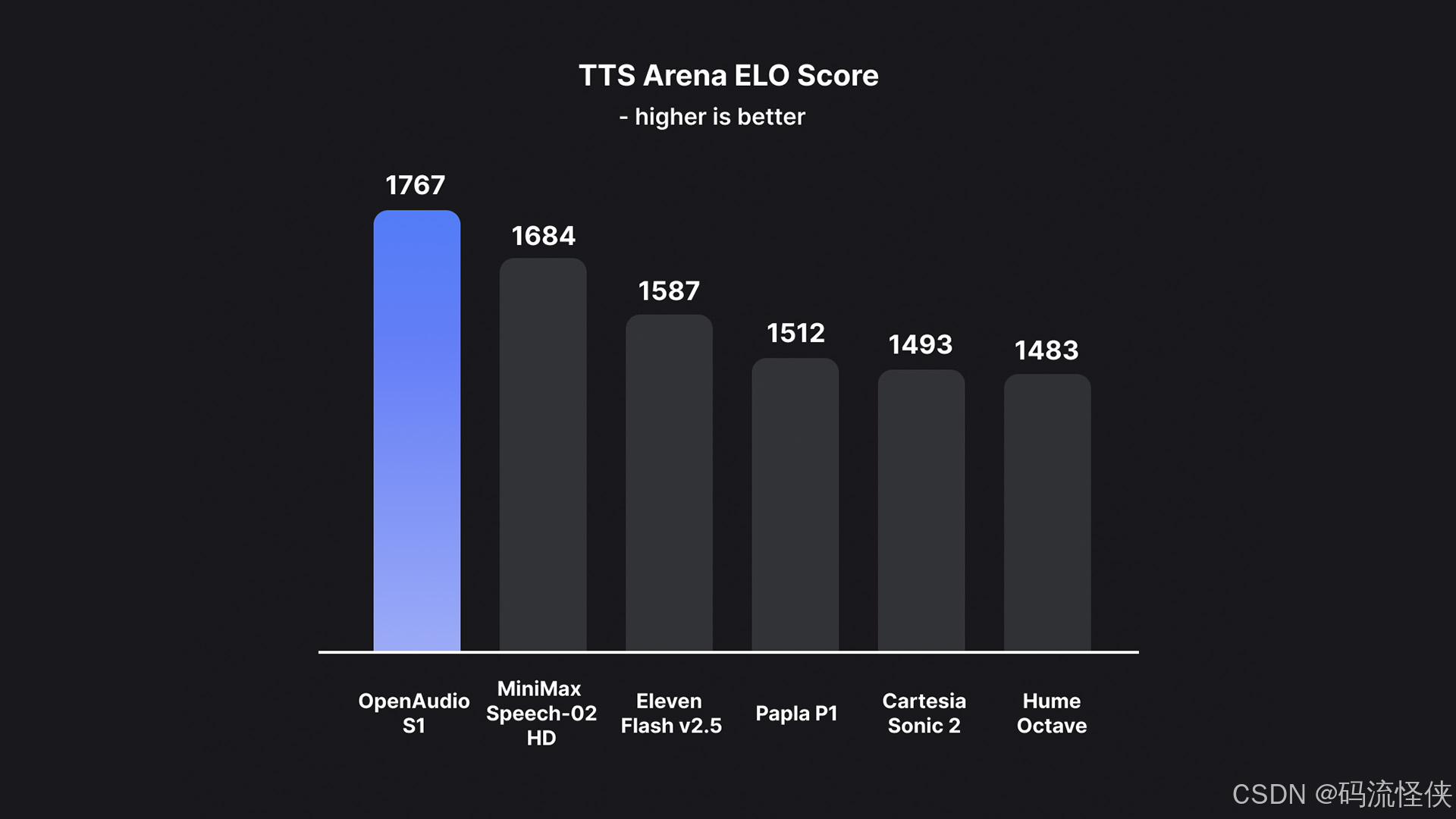
- 关键性能指标
| 指标 | 表现 | 对比优势 |
|---|---|---|
| 实时因子(RTF) | RTX 4090 达 1:15 | 超实时合成 |
| 错误率 | CER/WER <2%(5分钟英文文本) | 行业领先 |
| 延迟 | <150ms(语音克隆场景) | 支持实时对话 |
三、实战部署指南
-
快速体验(Web版)
访问 Fish Speech 官网:- 选择预设音色(明星/原生人物)或上传样本生成定制音色 。
- 输入文本 → 调整语言参数 → 生成并下载音频。
-
本地化部署
步骤概览:克隆代码库 git clone https://github.com/fishaudio/fish-speech 创建Python环境 conda create -n fish-speech python=3.10 conda activate fish-speech安装依赖 & 下载预训练模型 pip install -r requirements.txt wget https://huggingface.co/fishaudio/models/resolve/main/vqgan_model.pth
关键配置:
- 硬件要求:GPU(≥4GB显存)或 CPU(推理速度较慢)。
- 推理方式:
- 命令行生成:
fish speech synthesize --text "Hello World" --output out.wav - API 服务:启动 Gradio WebUI 或 HTTP 服务 。
- 命令行生成:
💡 贴士:使用
--half参数启用半精度推理,显存占用降低 40% 。
四、进阶应用场景
-
教育领域
- 多语言教材朗读:自动生成英/日/韩语听力材料 。
- 发音辅助:对比学习者录音与合成语音,纠正发音偏差 。
-
无障碍服务
- 视障辅助工具:浏览器插件实时朗读网页文本(支持流式输出)。
-
媒体创作
- 影视配音:基于角色音色克隆,批量生成多语种配音 。
- AI 播客:结合 GPT 生成脚本 + Fish Speech 自动播报。
五、局限性及优化方向
| 挑战 | 应对方案 |
|---|---|
| 小语种合成质量波动 | 添加领域数据微调 |
| 长文本韵律连贯性不足 | 分段合成 + 后期音频拼接 |
| 情感表达偏机械 | 融合 Prosody 建模(未来版本规划) |
六、结语
Fish Speech 以 开源免费、低部署门槛 和 工业级性能,正成为 TTS 领域的标杆工具。其设计理念契合开发者与中小企业的需求,尤其适合快速构建多语言语音交互系统。随着 V1.5 版本引入实时对话支持 ,Fish Speech 有望进一步打破语音合成的应用边界。
资源导航:
- 官方代码库:fishaudio/fish-speech
- 在线体验:https://fish.audio/
- 进阶教程:模型微调指南