20250718-5-Kubernetes 调度-Pod对象:重启策略+健康检查_笔记
一、Pod对象管理命令
1. 创建Pod
- 两种创建方式:
- 通过YAML文件:kubectl apply -f pod.yaml
- 直接使用命令:kubectl run nginx --image=nginx
- 命令创建示例:
- 创建busybox测试容器:kubectl run busybox --image=nginx -- sleep 24h
- 带参数运行:kubectl run nginx --image=nginx -- <arg1> <arg2>
- 自定义命令:kubectl run nginx --image=nginx --command -- <cmd> <arg1>
2. 查看Pod
- 基础查看:
- 列表查看:kubectl get pods
- 详细信息:kubectl describe pod <Pod名称>
- 详细说明:
- 通过describe可查看Pod分配的节点、使用的镜像等完整信息
- 对于多容器Pod,describe会显示每个容器的独立状态
3. 查看日志
- 基本命令:
- 查看日志:kubectl logs <Pod名称> [-c CONTAINER]
- 实时跟踪:kubectl logs <Pod名称> [-c CONTAINER] -f
- 多容器处理:
- 必须使用-c指定容器名称(对应YAML中定义的name)
- 示例:kubectl logs pod-web -c web查看主容器日志
4. 进入容器终端
- 进入方式:
- 基础命令:kubectl exec <Pod名称> [-c CONTAINER] -it bash
- 示例:kubectl exec -it pod-web2 -c bs -- sh
- 注意事项:
- 多容器Pod必须指定-c参数
- 容器内必须有bash/sh等shell环境才能交互
5. 删除Pod
- 删除方式:
- 直接删除:kubectl delete pod <Pod名称>
- 通过文件删除:kubectl delete -f pod.yaml
- 删除特性:
- 删除操作会有平滑终止期(grace period)
- 删除后可通过kubectl get pods验证状态
6. 总结
- 完整YAML示例:
apiVersion: v1 kind: Pod metadata:name: my-pod spec:containers:- name: container1image: nginx- name: container2 image: centos
- 关键要点:
- 多容器Pod操作必须指定容器名称
- 日志和终端访问是故障排查的重要工具
- 删除操作不是即时生效,有优雅终止过程
二、重启策略&健康检查
1. 重启策略
1)重启策略概述

- 核心机制: 通过restartPolicy字段控制容器退出后的行为,默认值为Always
- 状态码判断: 基于容器退出状态码(0为正常,非0为异常)决定是否触发重启
- 策略联动: 与健康检查机制协同工作,共同保障应用可用性
2)Always策略
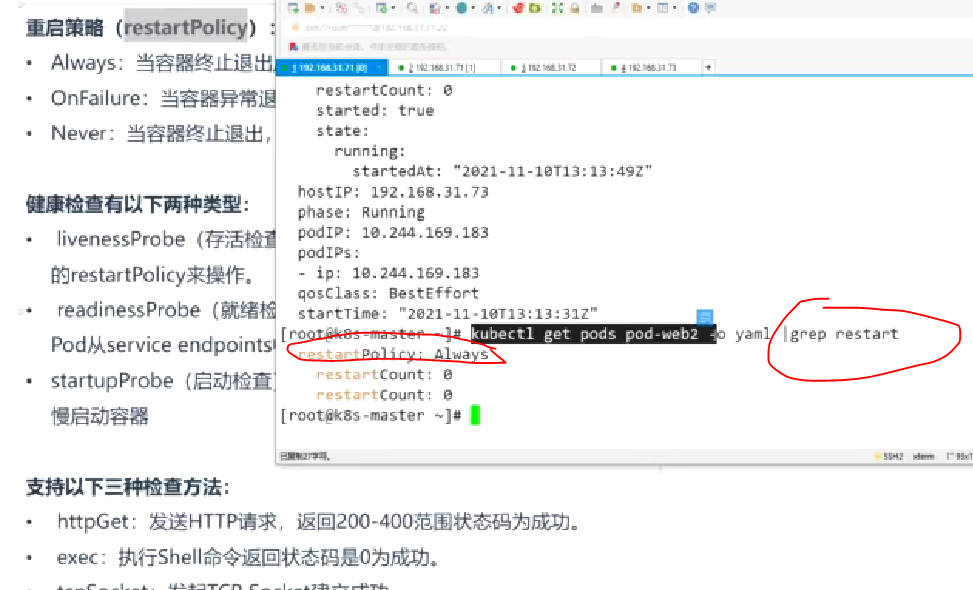
- 触发条件: 当容器终止退出(无论状态码)时立即重启
- 默认配置: 未显式声明restartPolicy时自动启用
- 典型场景: Web服务(Nginx)、数据库(MySQL)、缓存服务(Redis)等需要持续运行的应用
- 检查方法: 可通过kubectl get pods <pod-name> -o yaml | grep restart验证配置
3)OnFailure策略
- 触发条件: 仅当容器异常退出(状态码非0)时重启
- 应用设计: 需在应用程序中显式返回非零状态码(如数据库备份脚本使用exit 6表示失败)
- 典型案例:
- 数据库备份任务(失败时自动重试)
- 系统巡检程序(异常时重新执行)
- 循环控制: 常配合while循环使用,示例:
4)Never策略
- 核心规则: 容器终止后绝不重启(无论正常/异常退出)
- 特殊要求: 需要人工介入处理故障场景
- 风险控制: 防止数据处理类任务重复执行导致数据污染
5)应用场景
- 持续性运行应用
- 代表服务: Nginx、MySQL、Redis等7×24小时服务
- 策略选择: Always(默认策略)
- 设计考量: 故障后快速自动恢复,最小化服务中断时间
- 周期性运行应用
- 典型场景: 数据库备份(每日)、系统巡检(每小时)
- 策略配置: OnFailure
- 异常处理: 通过状态码控制重试,如备份失败返回exit 6
- 一次性运行应用
- 业务特征: 数据离线处理、批量计算任务
- 策略选择: Never
- 关键原因: 避免重复执行导致计算结果异常或数据损坏
2. 健康检查
1)livenessProbe(存活检查)
- 核心功能: 检测应用存活状态,失败时杀死容器并触发重启策略
- 执行时机: 容器运行期间持续监控
- 联动机制: 与restartPolicy协同,如Always策略会立即重启被终止的容器
2)readinessProbe(就绪检查)
- 服务治理: 将异常Pod从Service的Endpoints列表中移除
- 流量控制: 确保请求只会被转发到健康的Pod实例
- 恢复机制: 检查通过后自动重新加入服务负载均衡池
3)startupProbe(启动检查)
- 特殊场景: 针对慢启动应用(启动耗时超过1分钟)
- 工作流程: 成功后才移交控制权给livenessProbe
- 保护机制: 避免在应用初始化期间误判为故障
4)健康检查方法
- HTTP检查:
- 协议: 发送HTTP GET请求
- 成功标准: 状态码200-400
- 适用场景: Web服务(Nginx、Tomcat等)
- 命令检查:
- 方式: 执行Shell命令
- 判断依据: 返回状态码0为成功
- 示例: ls /var/run/nginx.pid检查进程文件
- 优势: 可自定义复杂检查逻辑
- TCP检查:
- 原理: 建立TCP三次握手
- 局限: 仅验证端口可连接,不保证服务完全就绪
- 通用性: 适合非HTTP协议的服务(如Redis、MySQL)
- 选择策略:
- Web服务优先选HTTP检查(精确)
- 有明确启动特征的应用用命令检查
- 通用服务可考虑TCP检查(快速但不够精确)
3. 应用案例
1)健康检查配置方法

- 三种检查方式:
- TCP端口探测:通过tcpSocket检查指定端口是否存活
- 执行Shell命令:通过exec执行命令,返回0表示成功
- HTTP请求:通过httpGet发送HTTP请求检查路径
- 关键参数:
- initialDelaySeconds:容器启动后延迟检查时间(如Nginx设为3秒,Java应用建议30秒)
- periodSeconds:后续检查间隔时间(建议10-30秒)
- timeoutSeconds/failureThreshold:超时时间和失败阈值
- 检查类型区别:
- 存活检查(livenessProbe):失败会杀死容器,根据restartPolicy重启
- 就绪检查(readinessProbe):失败会将Pod从Service endpoints中剔除
- 启动检查(startupProbe):保护慢启动容器,成功后才会进行其他检查
2)配置实践演示
- HTTP检查配置要点:
- 路径配置:常用首页路径如/index.html
- 端口匹配:必须与容器暴露端口一致(如80)
- 请求头:可通过httpHeaders添加自定义头(如身份验证头)
- 官方文档参考:
- 建议搜索"probe"获取官方示例
- 前两个搜索结果通常包含最相关的配置示例
- 重启策略:
- Always:总是重启(默认策略)
- OnFailure:仅异常退出时重启
- Never:从不重启
- 实践技巧:
- 快速测试时可先配置为Always观察行为
- 生产环境建议结合应用特性选择OnFailure或Always
三、知识小结
知识点 | 核心内容 | 关键操作/配置 | 应用场景 |
Pod创建与管理 | 通过命令行或YAML文件创建Pod,支持导出配置模板 | kubectl create/apply/delete 命令操作 -o yaml 导出配置 -c 指定多容器场景 | 容器化应用部署 测试环境快速搭建 |
日志与终端访问 | 查看容器日志和进入容器终端的方法 | kubectl logs -f 实时日志 kubectl exec -it 进入终端 多容器需用-c指定 | 故障排查 应用调试 |
健康检查机制 | Liveness/Readiness/Startup三种探针类型 | HTTP Get/Exec命令/TCP Socket三种检查方式 initialDelaySeconds启动延迟 periodSeconds检查间隔 | 服务可用性保障 慢启动应用保护 |
重启策略 | Always/OnFailure/Never三种策略 | restartPolicy字段配置 Always为默认策略 | 持久化服务(Always) 批处理任务(OnFailure/Never) |
YAML配置示例 | HTTP健康检查完整配置模板 | livenessProbe存活检查 readinessProbe就绪检查 端口/路径/请求头配置 | Web服务健康监测 服务流量调度 |