【Spring WebFlux】什么是响应式编程
想象一下这样的场景:
“双十一” 零点,你守在手机前抢购心仪的商品。当倒计时结束,你疯狂点击下单按钮,屏幕却一直转圈,最后弹出 “系统繁忙”—— 这就是传统编程模式在高并发下的典型困境。而响应式编程,正是解决这类问题的 “高铁技术”,让系统在海量请求下依然能保持流畅。
本文将用最通俗的语言,带新手朋友们理解什么是响应式编程,以及它为何能成为现代 Java 开发的必备技能。
一、传统编程的 “堵车困境”
1.1 一个请求一条 “车道”:Thread per Request 模型
我们先从最基础的 Web 服务说起。当你用浏览器访问一个 Java Web 应用时,传统的处理方式就像城市道路系统 —— 每个请求都需要专属的 “车道”(线程)。
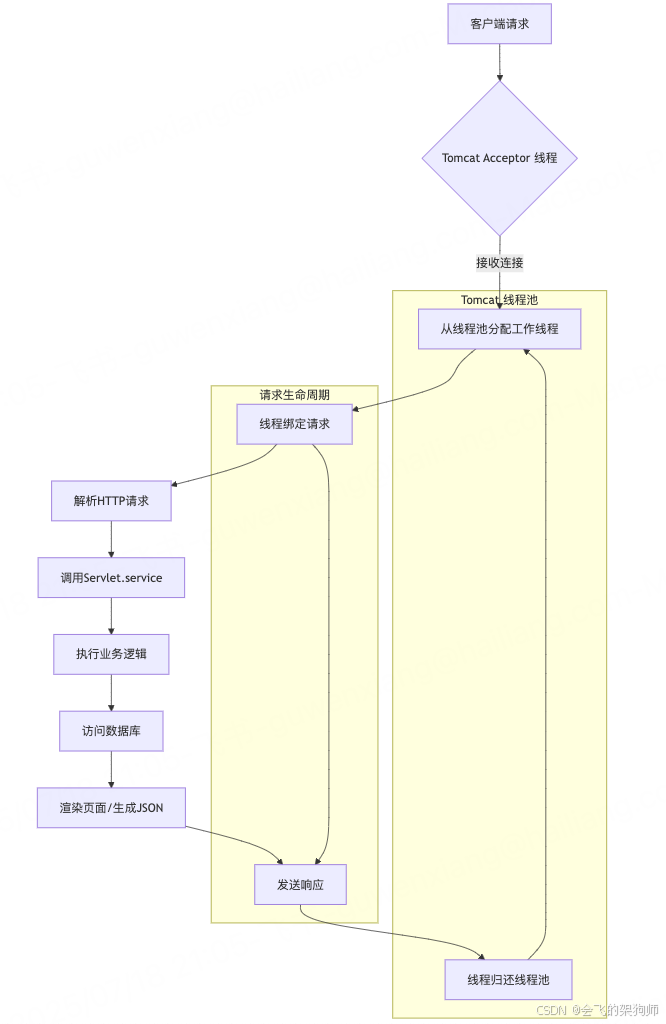
如上图所示,Tomcat 等 Servlet 容器会维护一个线程池,每个请求进来就分配一个线程全程处理。这个线程会陪着请求走完 “接收参数→调用数据库→渲染页面→返回结果” 的全过程,直到请求完成才会回到线程池。
这种模式的问题很明显:
-
线程池大小就是系统能同时处理的最大请求数(比如线程池设为 200,第 201 个请求就得排队)
-
每个线程要占用约 1MB 内存,200 个线程就是 200MB,1000 个线程就需要 1GB 内存
-
遇到数据库查询、文件读取等操作时,线程会 “停车等待”(阻塞),宝贵的 “车道” 就这样空着
1.2 堵车的根源:等待 I/O 的 “空驶成本”
传统编程中最浪费资源的场景,莫过于线程等待 I/O 操作的时刻。
假设我们的程序要完成以下任务:
-
从数据库查询用户信息(耗时 50ms)
-
读取本地配置文件(耗时 30ms)
-
调用第三方接口获取天气数据(耗时 100ms)
在传统模式下,处理线程会:
-
发起数据库查询→停车等待 50ms→继续执行
-
发起文件读取→停车等待 30ms→继续执行
-
发起接口调用→停车等待 100ms→继续执行
这 180ms 里,线程完全处于 “空驶” 状态,既不能处理新请求,又占用着系统资源。就像快递员送货时,每次敲门后都站在门口一动不动等业主开门,期间什么也干不了。
1.3 微服务时代的 “连环堵车”
在微服务架构中,一个请求往往需要多个服务协作完成:
用户下单请求 → 订单服务 → 支付服务 → 库存服务 → 用户服务
每个服务调用都可能让线程阻塞等待,如果有 5 个服务调用,每个耗时 100ms,总阻塞时间就会累积到 500ms。更糟的是,每个服务都有自己的线程池,整个调用链会占用大量线程资源,就像多段高速公路连环堵车,疏通难度呈指数级增长。
二、响应式编程:给系统装上 “高铁轨道”
响应式编程不是新技术,而是一种新的 “交通规划理念”—— 通过异步非阻塞的方式,让少量线程就能高效处理海量请求,就像高铁用更少的轨道实现了更高的运输效率。
2.1 核心思想:事件驱动的 “流水线”
响应式编程采用 “事件驱动” 模式,把请求处理拆分成一系列事件:
-
收到请求(onNext 事件)
-
处理完成(onComplete 事件)
-
发生错误(onError 事件)
就像工厂流水线,每个工人(线程)只负责特定环节,完成后把工件传给下一个环节,自己立刻处理新的工件。线程不再等待 I/O 操作,而是在收到结果通知后再继续处理。
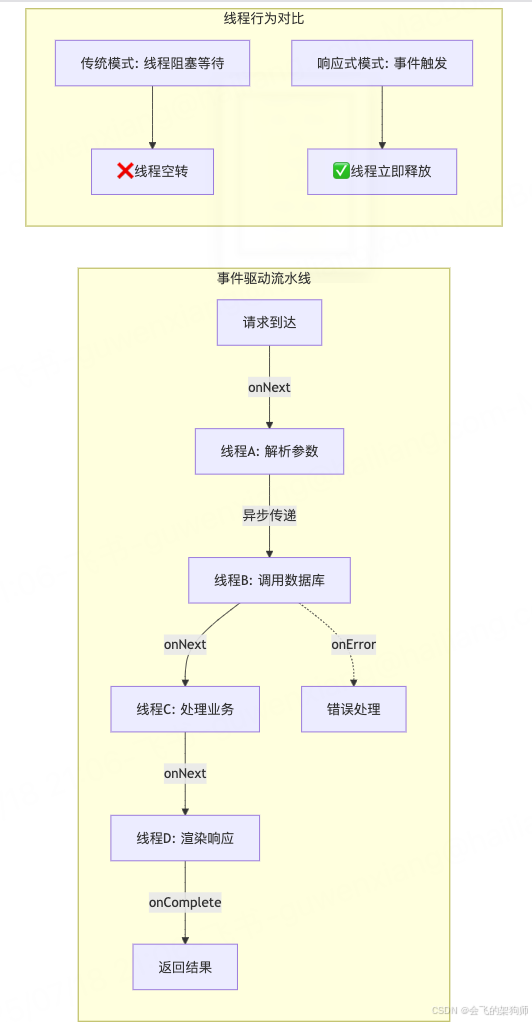
2.2 解决堵车的四大 “黑科技”
-
非阻塞 I/O:线程发起 I/O 请求后立即 “下班” 处理其他任务,I/O 完成后通过回调通知继续处理。就像快递员敲门后,通过门铃通知自己,期间可以去送其他快递。
-
少量线程高效复用:用 10 个线程就能处理 1000 个并发请求(传统模式需要 1000 个线程),内存占用降低 90% 以上。
-
并行处理无依赖任务:对于数据库查询、文件读取等无依赖的操作,可以像多核 CPU 一样并行处理,总耗时取最长任务的时间(而非总和)。比如之前的三个任务原本耗时 180ms,并行处理只需 100ms。
-
背压(Backpressure)机制:客户端可以告诉服务端 “我一次最多处理 10 条数据”,防止被海量数据冲垮。就像水杯告诉水龙头 “慢点,快满了”,实现供需平衡。
三、新手入门:响应式编程的 “红绿灯”
对于 Java 开发者,响应式编程主要通过两个库实现:
-
Project Reactor:Spring 生态默认响应式库
-
RxJava:更成熟的跨语言响应式库
它们的核心概念非常简单:
-
Flux:处理 0 到 N 个元素的数据流(比如查询多条记录)
-
Mono:处理 0 到 1 个元素的数据流(比如查询单条记录)
一个简单的响应式查询示例:
// 传统同步查询
User user = userDao.findById(1L);
Order order = orderDao.findByUserId(1L);// 响应式并行查询
Mono<User> userMono = userDao.findById(1L);
Mono<Order> orderMono = orderDao.findByUserId(1L);// 合并结果(并行执行,总耗时取最长操作)
Mono<Result> resultMono = Mono.zip(userMono, orderMono, (user, order) -> new Result(user, order));
这段代码中,用户查询和订单查询会并行执行,线程不会阻塞等待,而是在两个查询都完成后自动触发结果合并 —— 这就是响应式编程的魅力。
四、哪些场景适合响应式编程?
-
高并发 Web 服务(电商秒杀、直播互动)
-
I/O 密集型应用(频繁数据库操作、文件处理)
-
微服务间通信(减少服务调用的阻塞等待)
-
实时数据处理(物联网传感器数据、日志分析)
但响应式编程并非银弹,对于 CPU 密集型任务(如复杂计算),它的优势并不明显。
五、总结:从 “堵车” 到 “高铁” 的思维转变
响应式编程的本质,是让系统资源从 “独占式” 变为 “共享式”,从 “等待式” 变为 “通知式”。对于新手来说,理解它的关键不是记住 API,而是转变思维模式:
-
从 “我要等待结果” 到 “结果准备好了告诉我”
-
从 “一个线程干到底” 到 “多个环节协同完成”
-
从 “尽量多开线程” 到 “高效复用线程”
就像城市交通从 “拓宽马路” 到 “优化交通信号” 的演进,响应式编程正在改变我们构建高性能系统的方式。下一次当你遇到系统卡顿、内存飙升的问题时,不妨想想:这个场景能用响应式编程优化吗?