深度信念网络 (DBN, Deep Belief Network)
也是深度伯努利网络, 是一种深度概率生成模型,由多个受限玻尔兹曼机堆叠而成的深度神经网络结构。 由 Geoffrey Hinton 团队在 2006 年前后推动发展,通过贪婪分层无监督预训练策略,有效解决了训练深度网络时的梯度消失/爆炸问题,实现了从浅层学习到深度学习的跨越。
一 核心思想
DBN是一种由多层随机潜在变量组成的概率生成模型,由多个受限玻尔兹曼机(RBM)堆叠而成:顶层:无向连接(RBM形式),下层:有向连接(生成方向)
核心创新: 贪婪逐层无监督预训练 + 有监督微调,解决了深度网络训练难的问题。
无监督预训练:利用大量未标记数据,自底向上逐层训练其基本构件——受限玻尔兹曼机,学习数据的分层特征表示。
有监督微调:在预训练好的网络顶部添加输出层,利用少量标记数据和反向传播对整个网络进行微调,优化目标任务性能。
关键目标: 学习训练数据的联合概率分布 P(v, h₁, h₂, ..., hₙ),其中 v 是观测数据, h1 到 hₙ 是不同层次的隐藏特征。(因此是生成模型)
二 受限玻尔兹曼机(RBM)
2.1 RBM结构
两层结构:
一个可见层 (visible layer) (观测数据)
一个隐藏层 (hidden layer)
受限连接 (Restricted Connectivity): 可见单元之间、隐藏单元之间没有连接;可见层与隐藏层之间是全连接,无向连接。
能量函数定义系统状态 :
:可见单元
的偏置
:隐藏单元
的偏置
:
和
之间的连接权重
2.2 概率分布
联合概率分布:
为配分函数:
条件概率(得益于层内无连接):
为sigmoid函数
三 DBN架构
3.1 网络结构
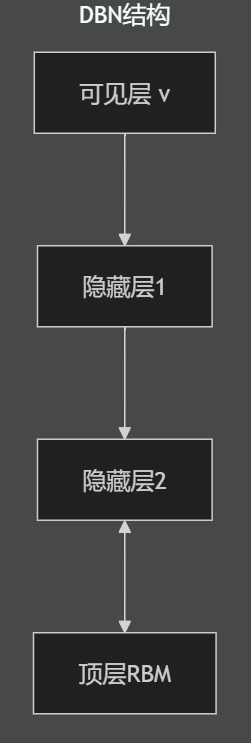
底层RBM(↔
):接受原始输入
中层RBM(↔
):前一层输出作为输入
顶层RBM(↔
):无向连接
3.2 概率模型
联合概率分布:
其中:
:顶层RBM的联合分布
:有向条件分布(
时
)
生成过程:
顶层RBM吉布斯采样:
自上而下采样:
生成观测:
四 训练策略
4.1 无监督预训练(核心创新)
贪婪分层训练过程:
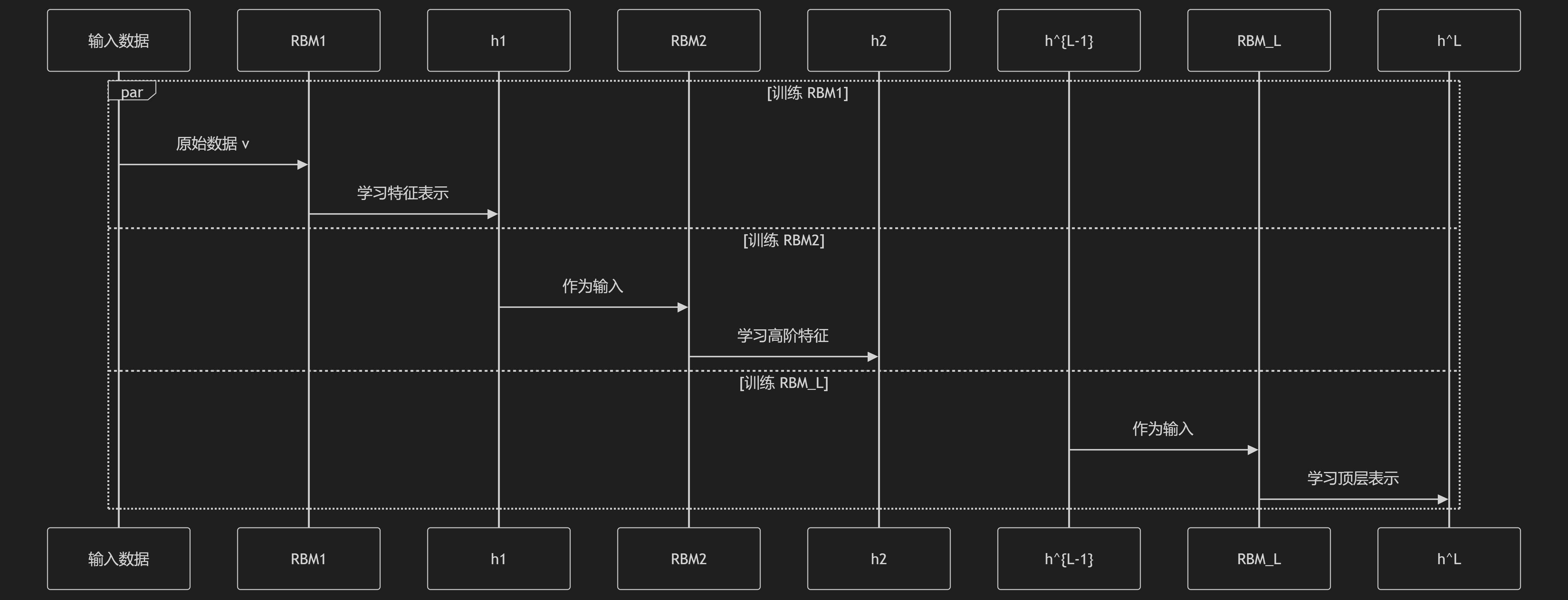
关键优势:
解决梯度消失问题
初始化网络到良好区域
利用未标记数据学习分层特征
4.2 有监督微调
网络转换:原始DBN + softmax层 → 深度神经网络
微调过程:
前向传播:
计算损失:
反向传播:
五 特性分析
5.1 核心优势
| 优势 | 说明 |
|---|---|
| 分层特征学习 | 自动提取低层到高层的抽象特征 |
| 生成能力 | 可从高层表示生成数据样本 |
| 半监督学习 | 有效利用大量未标记数据 |
| 解决深度训练难题 | 预训练克服梯度消失问题 |
5.2 局限性与挑战
| 局限性/挑战 | 说明 | 对应用的影响 |
|---|---|---|
| 计算复杂度高 | RBM训练需要吉布斯采样(对比散度算法),参数更新涉及多次数据重建 | 训练时间和资源消耗大,难以扩展到超大规模数据集 |
| 生成质量限制 | 相比GAN/VAE等现代生成模型,DBN的样本生成质量较低 | 图像/音频生成任务中表现较差,边缘模糊、细节缺失 |
| 训练流程复杂 | 需分阶段:逐层RBM预训练 → 堆叠 → 整体微调 | 实施难度大,调试过程繁杂,超参数配置敏感 |
| 推断效率低下 | 生成采样需执行多步吉布斯采样(通常>100次迭代) | 实时应用(如在线推荐系统)响应速度受限 |
| 局部最优风险 | 贪婪逐层训练可能导致网络陷入局部最优解 | 网络可能无法充分挖掘数据的全局特征关系 |
| 连续数据处理难 | 基础RBM设计针对二值数据,需改进处理连续变量 | 直接处理图像/语音等连续数据需高斯RBM或额外归一化 |
| 可解释性差 | 深层特征表示高度抽象,决策逻辑不透明 | 医疗/金融等高风险领域应用受限 |
| 梯度问题残存 | 虽缓解但未完全消除深度网络的梯度消失现象 | 超过8层的超深度网络训练依然困难 |
解决方案:
| 问题类型 | 传统DBN方案 | 现代替代方案 |
|---|---|---|
| 计算效率 | 分布式CD算法 | GPU并行化训练 |
| 生成质量 | 调整隐含单元数 | 转用VAE/GAN架构 |
| 连续数据处理 | 高斯-伯努利RBM | 卷积自动编码器 |
| 深度优化 | 监督微调 | 残差连接/批量归一化 |
| 参数调优 | 网格搜索 | 贝叶斯优化/自动化ML |
后续深度学习架构的发展:
前馈网络革新:ReLU/残差连接解决梯度问题
端到端训练:抛弃分阶段训练(如Transformer)
专用处理器:GPU/TPU加速矩阵运算
正则化技术:Dropout/批量归一化提升泛化能力
对比:
| 特性 | DBN | 现代深度网络(CNN/Transformer) |
|---|---|---|
| 训练策略 | 预训练+微调 | 端到端训练 |
| 数据依赖 | 大量未标记数据 | 大规模标记数据 |
| 优势领域 | 生成模型,特征学习 | 判别任务,模式识别 |
| 计算效率 | 较低(CD采样) | 较高(矩阵运算) |
六 总结
DBN的革命性贡献在于:
(1)提出贪婪分层预训练策略,解决深度网络训练难题
(2)建立概率生成框架,统一生成与判别学习
(3)开发RBM高效训练算法(对比散度)
虽然现代深度学习更多使用端到端训练,DBN的使用以经较少了。但DBN的核心思想仍在自编码器、迁移学习等领域延续。其在概率生成模型、小样本学习等场景仍有独特价值。