强化微调技术与GRPO算法(2): 优势、应用场景与选择指南
在上一篇博客:强化微调技术与GRPO算法(1):简介-CSDN博客 中,我们探讨了从监督微调(SFT)到强化学习(RL)的演进,并介绍了RLHF、DPO和GRPO等关键算法。现在,我们已经了解了强化学习的基本工作原理,是时候深入探讨它作为一种微调技术能为我们的工作带来哪些具体的好处,以及哪些任务最适合采用这种强大的训练方法。
一、 强化微调(RFT)的核心优势
强化微调(Reinforcement Fine-tuning, RFT),尤其是像GRPO这样的先进方法,在实践中带来了几个显著的优势,彻底改变了我们提升LLM能力的方式。

-
无需标注数据,只需验证正确性
这是RFT最革命性的一点。与督微调(SFT)不同,它不强制要求有“正确答案”的标注数据集。你只需要一个能够“验证”模型输出正确性的机制。这个机制可以是:-
可编程的奖励函数: 你可以编写代码来检查输出是否符合特定格式、计算结果是否正确,或是否遵循某些规则。
-
“LLM即评委” (LLM as a Judge): 使用另一个强大的LLM来评估生成内容的质量。
-
其他自动化验证方法。
-
-
数据高效,少量样本即可启动
RFT的启动门槛非常低。即使只有10个左右的示例(提示词),你就可以开始训练。随着你提供给模型用于训练的提示词数量增加,模型的性能会稳步提升。 -
比SFT更灵活,从动态反馈中主动学习
SFT的学习过程是被动的,它只能模仿固定的标注示例。而RFT是主动学习。模型在训练过程中通过与奖励函数互动,从实时的、动态的反馈中学习,而不是被限制在一成不变的示例中。 -
赋能推理模型,有机发现更优策略
由于RFT的灵活性,它能让具备推理能力(如思维链,Chain-of-Thought)的模型有机地发现解决问题的更优策略。模型可以通过改进其内部的“思维链”来解决复杂的推理问题,而不仅仅是复制你在SFT数据中提供的固定推理路径。
二、 RFT在真实世界中的应用与表现
为了验证GRPO驱动的RFT的强大能力,Predibase团队进行了一项具有挑战性的真实世界任务实验:将PyTorch代码翻译成高度优化的、用Triton语言编写的GPU内核代码。
他们从一个开源模型(Qwen2-Coder-32B-Instruct)开始,使用Predibase的RFT平台(基于GRPO)进行微调。结果令人瞩目:
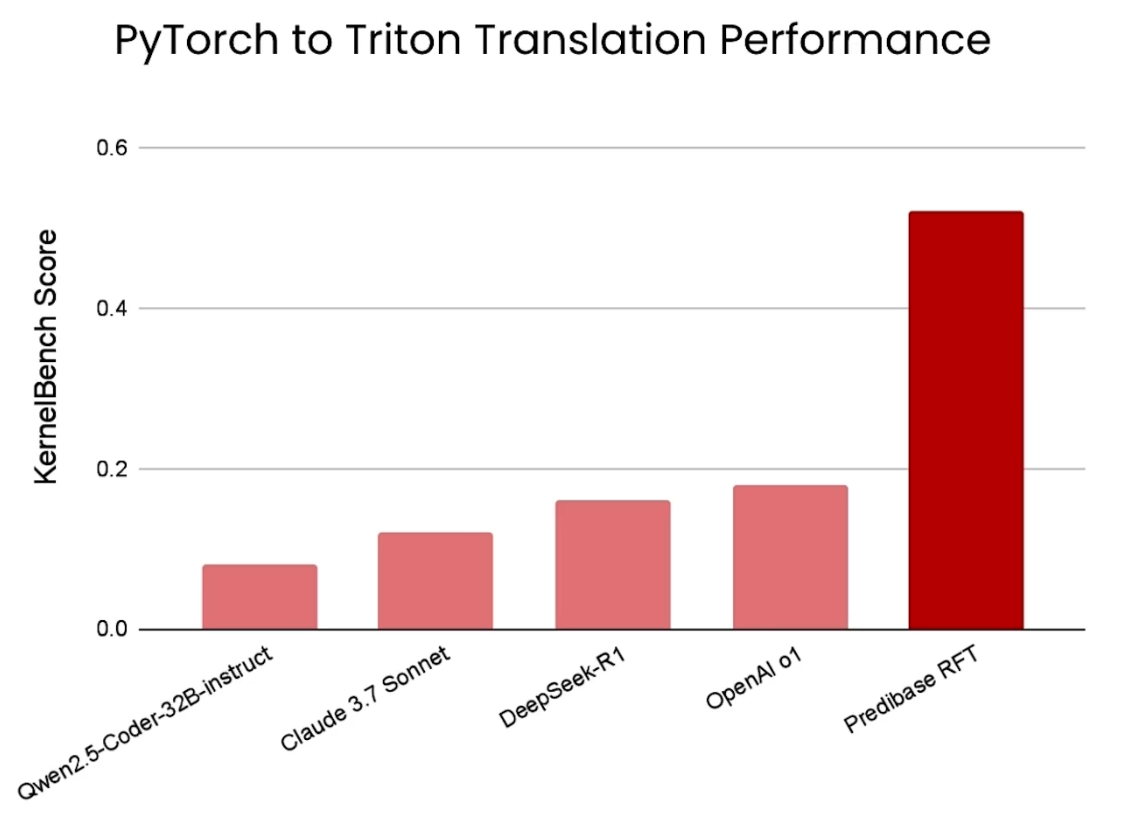
如上图所示,经过RFT微调的模型在KernelBench基准测试中的得分远超所有其他模型,包括强大的Claude 3.7 Sonnet、DeepSeek-R1,甚至OpenAI的o1模型。
这个结果有力地证明了,通过可编程的奖励函数进行强化微调,可以将一个开源LLM的性能推向一个全新的高度,其表现甚至超越了那些依赖传统SFT或基于人类偏好的RLHF/DPO方法的顶尖模型。
三、 何时应该使用强化微调?
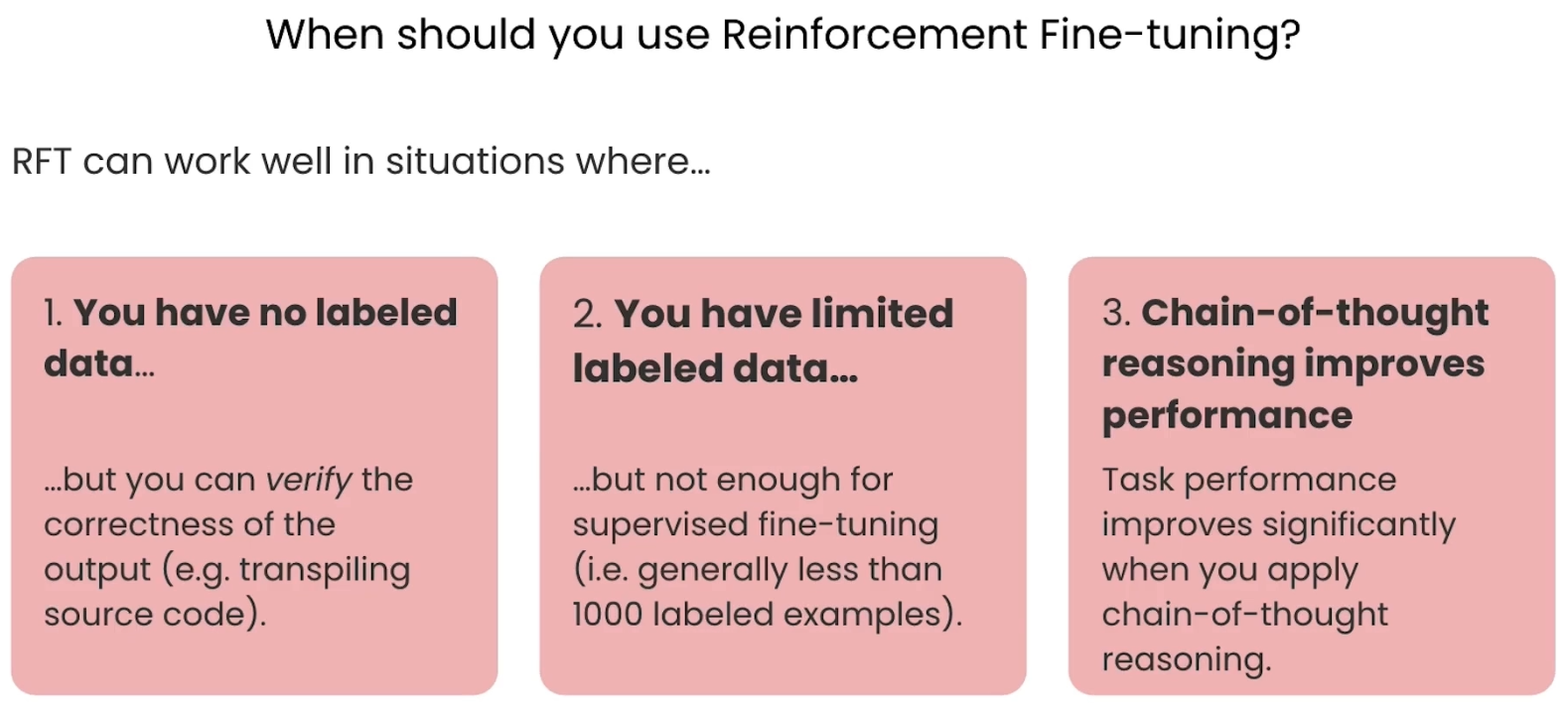
了解了RFT的优势后,下一个问题自然就是:在哪些具体场景下,我们应该优先考虑使用它呢?RFT在以下三种情况中尤其能发挥巨大作用。
-
你没有标注数据 (You have no labeled data)
当你手头没有任何“正确答案”的标注数据时,SFT就无从下手了。但只要你能通过某种方式验证模型输出的正确性(例如,通过编译来检查生成的代码,或通过运行单元测试来验证其功能),RFT就能派上用场。这是利用可编程奖励函数威力的完美场景。 -
你的标注数据有限 (You have limited labeled data)
你可能有一些标注数据,但数量不足以进行有效的监督微调(通常少于1000个样本)。在这种情况下,SFT的效果可能很差。RFT则可以利用这少量数据作为起点,并通过探索和奖励机制来学习,从而达到比SFT更好的效果。 -
思维链(Chain-of-Thought)推理能显著提升性能
对于那些复杂的、需要多步推理才能解决的任务,仅仅给出最终答案是不够的。如果让模型展示其“思考过程”(即思维链)能够大幅提升任务表现,那么RFT就是理想的选择。因为RFT可以奖励模型整个推理过程的正确性,而不仅仅是最终答案,从而鼓励模型发现更优、更可靠的推理路径。
四、 哪些任务最适合使用强化微调?
RFT在以下几类任务中表现尤为出色,因为它能够奖励并优化复杂的、多步骤的过程,而不仅仅是最终结果。

-
数学问题求解 (Mathematical Problem Solving):
RFT可以训练模型展示其解题过程,提供详细的计算步骤,而不仅仅是给出一个最终答案。模型会不断优化其“思维链”,直到计算结果被验证为正确。 -
代码生成与调试 (Code Generation and Debugging):
这是RFT的绝佳应用场景。模型可以通过对照单元测试或代码规范(Linting Rules)进行评分来学习。它能学会生成正确、规范的代码,并迭代地修复错误。 -
逻辑与多步推理 (Logical and Multi-Step Reasoning):
对于需要一系列决策的任务(如Agent工作流),RFT鼓励模型进行自我批判和改进。模型会根据最终任务的成败来调整每一步的决策,从而学会更可靠的、基于逐步逻辑的决策过程。
在这些场景中,从程序化或基于结果的奖励中主动学习的能力,解锁了比静态SFT更丰富、更可靠的模型行为。
四、 终极指南:何时选择RFT而非SFT?
那么,面对一个具体任务,你该如何决定是使用RFT还是SFT呢?这里有一个决策流程图可以帮助你。
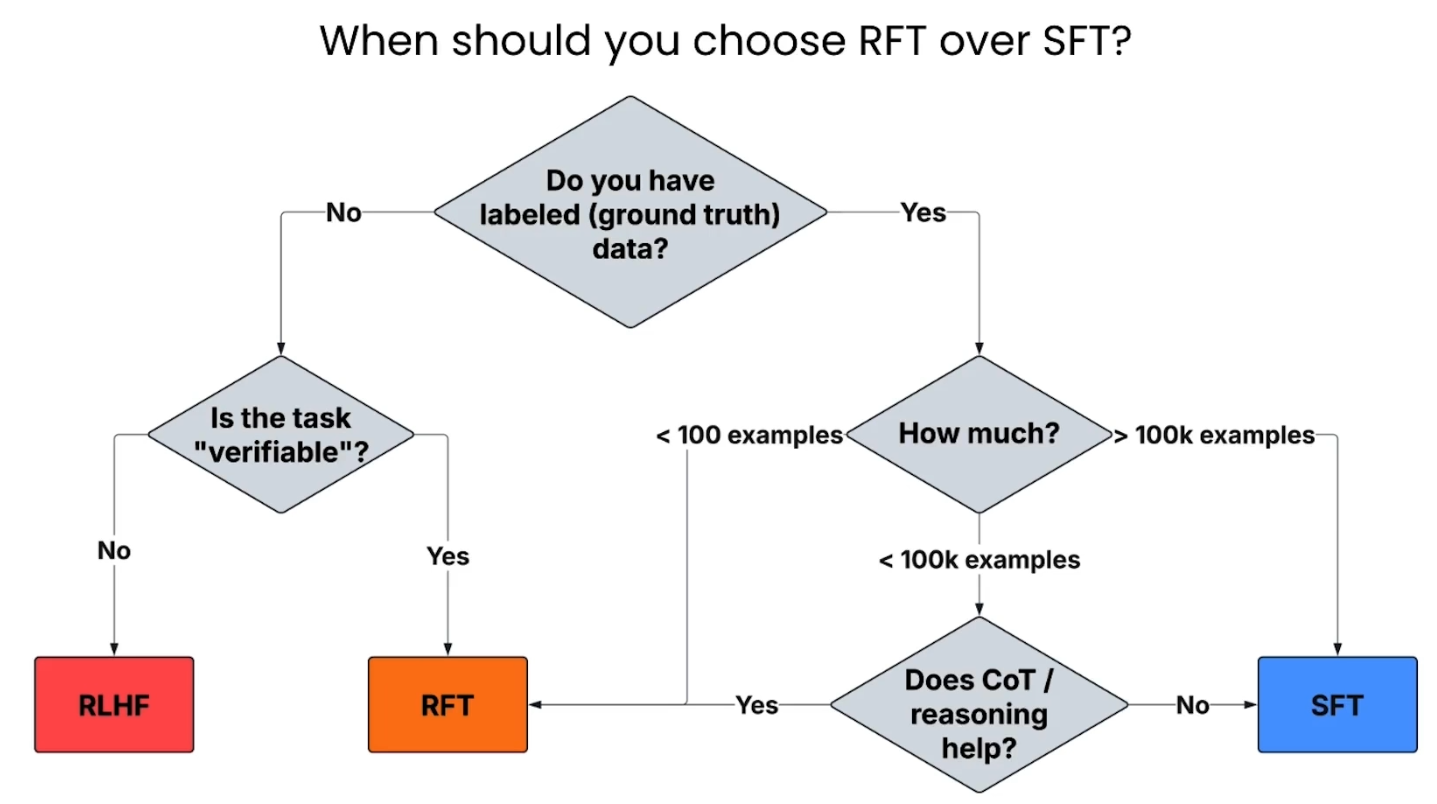
决策路径解析:
-
第一步:检查是否有标注数据?
-
否 (No): 如果你完全没有标注数据,那么问自己下一个问题:“这个任务的输出是可验证的吗?”
-
是 (Yes): 如果你可以用程序化的方式验证输出的正确性(如代码编译、单元测试、格式检查),那么RFT是你的最佳选择。
-
否 (No): 如果输出是主观的,无法自动验证(如创意写作),那么你需要先收集人类偏好数据,然后使用RLHF或DPO。
-
-
是 (Yes): 如果你有标注数据,那么进入第二步。
-
-
第二步:数据量有多大?
-
> 100k 样本: 如果你有海量的、高质量的标注数据,SFT通常是最高效、最直接的路径。
-
< 100k 样本: 如果你的数据量有限,那么进入第三步。
-
-
第三步:思维链(CoT)/推理是否有帮助?
-
是 (Yes): 如果任务的性能可以通过引导模型进行逐步推理而显著提升,那么RFT是理想选择。它可以放大这些推理带来的收益,通过奖励正确的推理步骤来进一步优化模型。
-
否 (No): 如果任务很简单,不需要复杂的推理,那么使用你现有的有限数据进行SFT可能是最合适的。
-
总结与展望
强化微调,特别是以GRPO为代表的、基于可编程奖励的方法,为我们提供了一条全新的、高效的路径来定制和优化大语言模型。它将我们从对大规模标注数据的依赖中解放出来,让我们能够专注于定义和奖励我们真正关心的模型行为。