LLMs之RL之GRPO:《Magistral》的翻译与解读
LLMs之RL之GRPO:《Magistral》的翻译与解读
导读:该论文详细介绍了Mistral公司从零开始构建其首个推理模型Magistral的完整技术栈和方法论。通过对强化学习算法(GRPO)的深度优化、精巧的多维度奖励设计,以及高效的异步分布式训练架构,该研究成功证明了“纯强化学习”是打造顶级推理模型的一条可行且强大的路径,摆脱了对外部模型蒸馏数据的依赖。更重要的是,论文揭示了文本推理能力的提升能“免费”泛化到多模态等其他领域,并分享了大量宝贵的实践经验与失败教训,为社区构建更强大、更通用的AI系统提供了清晰的路线图和坚实的开源基础。
>> 背景痛点
● 依赖现有实现与框架的局限:许多研究在进行强化学习(RL)时,依赖于已有的实现或框架,这可能限制了探索的灵活性和对底层机制的深入理解。
● “冷启动”数据依赖问题:创建强大的推理模型通常需要通过“知识蒸馏”的方式,即使用一个更强大的“教师模型”(如GPT-4)生成大量的推理轨迹(SFT数据)来进行初步训练(冷启动)。这种方法不仅成本高昂,而且使得模型的性能上限受限于教师模型。
● 推理语言不可控问题:在多语言环境中,仅对数学和代码问题进行强化学习,常常导致模型在推理过程中(即“思考链”)出现多种语言混杂的情况(如英语、中文、俄语混合),这从用户体验角度来看是不可取的。
● RL对模型原有能力的影响未知:在对一个基础模型(尤其是多模态模型)进行纯文本领域的强化学习后,其原有的其他能力(如多模态理解、指令遵循、工具调用)是否会退化,是一个普遍存在的担忧。
>> 具体的解决方案
● 推出Magistral系列模型:Mistral公司发布了其首个推理模型系列Magistral,包括完全通过纯强化学习训练的Magistral Medium,以及结合了SFT和RL训练并已开源的Magistral Small。
● 自研端到端的可扩展RL训练栈:团队从零开始,完全依靠自家的模型和基础设施,构建了一套完整的、可扩展的强化学习(RL)训练系统,摆脱了对外部模型和框架的依赖。
● 提出简洁的多语言推理控制策略:通过在训练数据中加入少量翻译样本,并设计一个简单的语言一致性奖励,成功地引导模型在思考和回答时,都使用与用户提问相同的语言。
● 纯文本RL训练:论文证明,仅在文本数据上进行强化学习,不仅不会损害模型原有的多模态等能力,甚至还能带来意想不到的提升。
>> 核心思路步骤
● 第一步:高质量可验证数据的精细筛选:论文对数学和代码这两类有可验证答案的数据进行了严格筛选。特别是对数学问题,采用了“两阶段难度过滤”策略:首先用一个中等强度的模型过滤掉太简单或太难的问题,然后用这个初步RL训练出的更强模型,再次对整个数据集进行筛选,以保留那些“恰到好处”(Goldilocks)难度的、最有价值的训练样本。
● 第二步:改进的强化学习算法(GRPO):论文采用了无“评论家模型”(critic-less)的GRPO算法,并做出了多项关键改进以提升稳定性和探索效率,包括:
●● 移除KL散度惩罚:以降低计算成本。
●● 放宽信任区域上界(Clip-Higher):允许模型探索罕见但有价值的推理路径,防止“熵崩溃”。
●● 过滤零优势批次:剔除那些所有生成结果都全对或全错的分组,以减少梯度噪声。
●● 优势标准化:在每个小批次(minibatch)内对优势(advantage)进行标准化。
● 第三步:精巧的奖励机制设计(Reward Shaping):为了有效引导模型,设计了一个复合奖励函数,从四个维度进行评估:
●● 格式奖励:要求模型遵循特定的输出格式(如使用<think>标签),否则奖励为0。
●● 正确性奖励:如果答案正确,则给予一个高额奖励(0.9)。
●● 长度惩罚:当生成长度接近上限时,施加一个温和的惩罚,以引导模型生成更简洁有效的答案。
●● 语言一致性奖励:使用fastText分类器检测问题、思考过程和答案的语言是否一致,一致则给予额外奖励(0.1)。
● 第四步:高效的异步分布式训练架构:设计了一套包含生成器(Generators)、训练器(Trainers)和验证器(Verifiers)的分布式系统。其核心是异步生成机制,生成器持续不断地工作,训练器在收到足够数据后进行梯度更新,并立即将新权重广播给生成器,整个过程无需等待,极大地提升了GPU利用率和训练效率。
>> 优势
● 强大的纯RL性能提升:证明了仅通过强化学习,无需任何来自其他模型的蒸馏数据,就能在大型基础模型上实现巨大的性能飞跃。例如,Magistral Medium在AIME-24测试集上的pass@1准确率提升了近50%。
● 高效且可扩展的自研训练系统:自研的异步RL架构非常高效,即使对于大型模型,权重更新的时间也低于5秒,并且通过优化的批处理策略减少了19%的填充(padding),展示了其工业级的可扩展性。
● 实现了可控的多语言推理能力:通过简单的奖励机制,成功解决了RL训练中常见的语言混杂问题,使模型能够根据用户语言进行连贯的思考和回答,同时在多语言基准测试中保持了强大的性能。
● 意外的能力泛化与保持(“免费午餐”):研究发现,在纯文本上进行RL训练后,模型原有的多模态推理能力、工具调用能力和指令遵循能力不仅没有下降,反而得到了保持甚至增强。这证明了推理能力的提升具有很强的通用性。
● 开源贡献:团队开源了24B参数的Magistral Small模型及其训练方法,为社区提供了强大的轻量级推理模型和宝贵的实践经验。
>> 结论和观点 (侧重经验与建议)
● 小模型同样能从纯RL中获得巨大收益:与先前一些研究认为小模型难以单靠RL获得提升的观点相反,本研究发现,即使是24B的模型,在纯RL训练后也能达到与通过大型模型蒸馏(SFT)相当的性能,并且在SFT的基础上再进行RL,性能还能进一步大幅提升。
● RL训练对批次大小(Batch Size)的设置敏感:实验表明,为了保证训练稳定,批次大小(nbatch)需要足够大,并且最好让小批次大小(nminibatch)等于批次大小。如果一个大批次被拆分成太多的小批次进行更新,性能会显著下降。
● 纯文本RL训练能“免费”提升多模态等其他能力:这是一个非常重要的发现。对文本推理能力的强化,其效果可以泛化到需要视觉信息和文本结合进行推理的多模态任务上,这为构建更通用的AI系统提供了新的思路。
● 部分直觉上有效的方法并未成功(失败经验分享):
●● 代码任务的部分奖励:尝试根据代码通过测试用例的比例给予部分奖励,虽然加快了训练速度,但最终模型性能反而略有下降。这表明,对于需要高度严谨性的任务,稀疏但准确的二元奖励(全对/全错)可能比密集的“虚假信号”更有效。
●● 熵奖励项不稳定:尝试使用传统的熵奖励来控制模型的探索行为,发现在不同数据集上效果差异巨大,非常不稳定。最终发现,通过调整GRPO算法中的ε_high参数来控制探索是更有效且稳定的方法。
● 推理长度是提升性能的关键驱动力:通过对模型权重演化过程的PCA分析发现,RL训练过程中的权重变化存在一个明显的“长度方向”。随着模型在这个方向上移动,其生成的平均长度和任务奖励(在触及长度惩罚前)同步增长,且奖励与输出长度的对数成正比。
目录
《Magistral》的翻译与解读
Abstract
1、Introduction
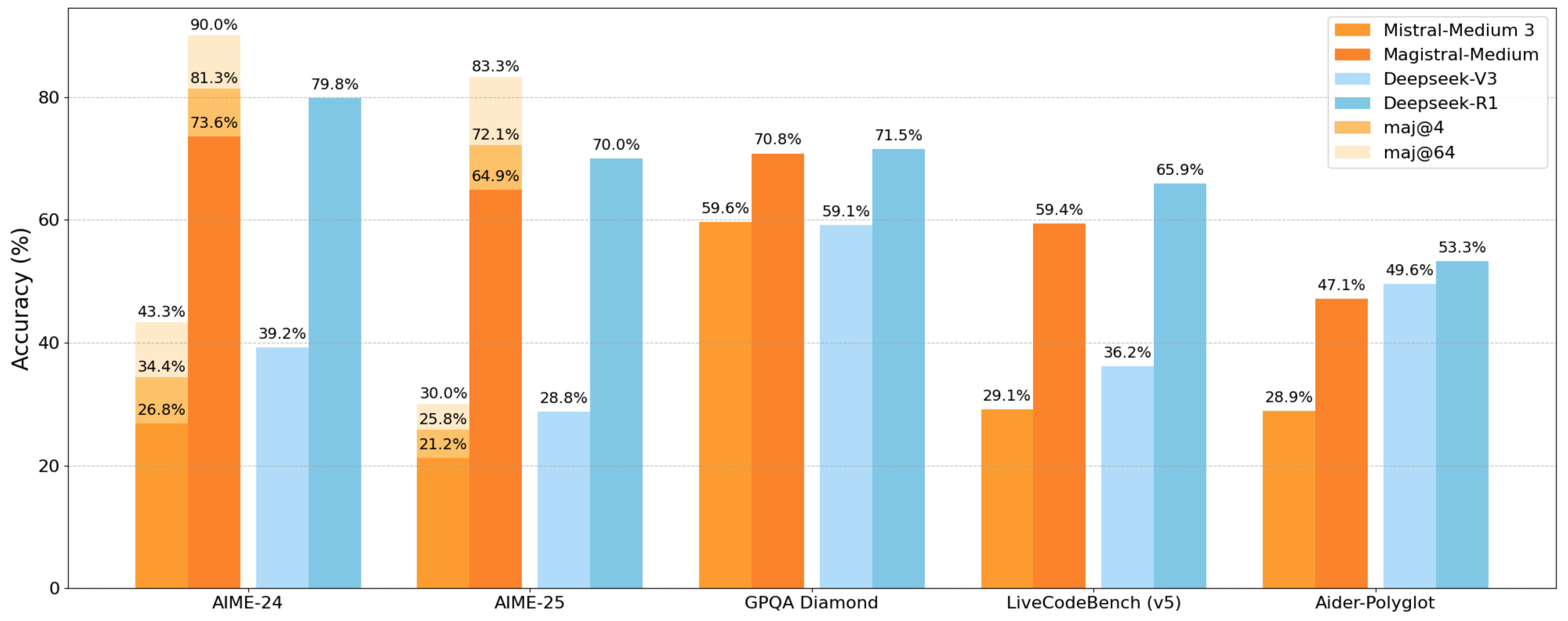
Figure 1: Performance of Magistral Medium on common reasoning benchmarks. We highlight the strength of our proposed RLVR framework, which yields a 50% increase in AIME-24 (pass@1) over the initial Mistral Medium 3 checkpoint, without any cold-start reasoning traces. We compare against analogous results from [DeepSeek-AI et al., 2025], which show RL improvements from DeepSeek-v3 to DeepSeek-R1 (January 25). Magistral Medium reaches 90% accuracy on AIME-24 with majority voting.图 1:Magistral Medium 在常见推理基准测试中的表现。我们突出了所提出的 RLVR 框架的优势,它在 AIME-24(pass@1)上比初始的 Mistral Medium 3 检查点提高了 50%,且无需任何冷启动推理痕迹。我们将其与 [DeepSeek-AI 等人,2025] 中类似的结果进行了比较,该结果展示了从 DeepSeek-v3 到 DeepSeek-R1(1 月 25 日)的强化学习改进。Magistral Medium 在 AIME-24 上通过多数投票达到了 90% 的准确率。
Conclusion
《Magistral》的翻译与解读
| 地址 | https://arxiv.org/abs/2506.10910 |
| 时间 | 2025年6月12日 |
| 作者 | Mistral |
Abstract
| We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium. | 我们推出 Magistral,这是 Mistral 的首个推理模型,也是我们自己的可扩展强化学习(RL)流水线。我们没有依赖现有的实现和从先前模型中提取的 RL 跟踪,而是采取了从头开始的方法,完全依靠我们自己的模型和基础设施。值得注意的是,我们展示了一个使我们能够探索纯 RL 训练 LLM 极限的堆栈,提出了一种简单的方法来强制模型的推理语言,并表明仅在文本数据上进行 RL 就能保持初始检查点的大部分能力。我们发现仅在文本上进行 RL 能够保持或提高多模态理解、指令遵循和函数调用的能力。我们推出了 Magistral Medium,它是在 Mistral Medium 3 之上仅通过 RL 进行推理训练的,我们还开源了 Magistral Small(Apache 2.0),它进一步包含了来自 Magistral Medium 的冷启动数据。 |
1、Introduction
| Enhancing the reasoning abilities of large language models (LLMs) has emerged as a key frontier in modern AI research. Reasoning models such as o1 [Jaech et al., 2024] differ widely from classic chatbots, leveraging longer chains-of-thought to improve performance on complex tasks. The seminal work by DeepSeek-AI et al. [2025] gave the community crucial insights on the Reinforcement Learning from Verifiable Rewards (RLVR) recipe, for creating reasoning models at scale. | 提升大型语言模型(LLM)的推理能力已成为现代人工智能研究的关键前沿领域。诸如 o1 [Jaech 等人,2024] 这样的推理模型与传统的聊天机器人有很大不同,它们通过更长的思维链来提高复杂任务的性能。DeepSeek-AI 等人 [2025] 的开创性工作为社区提供了关于从可验证奖励中进行强化学习(RLVR)的配方的重要见解,用于大规模创建推理模型。 |
| In this paper, we introduce Mistral’s first reasoning models: Magistral Small and Magistral Medium, based on the Mistral Small 3 and Mistral Medium 3 models respectively, and outline our proposed RLVR framework in detail. The key contributions of our paper are the following: >> We present in detail how we trained Magistral Medium with RL alone, with no distillation from pre-existing reasoning models, yielding a nearly 50% boost in AIME-24 (pass@1). >> We discuss in depth the infrastructure and design choices that enable large-scale online RL. Our asynchronous system enables fast, continuous RL training by updating generators frequently without interrupting them, balancing efficiency with on-policyness. >> We present a simple yet effective strategy to make the model multilingual, where both the chain-of-thought and the final response are written in the user’s language. >> We contribute insights that add to, or contradict, existing RLVR literature, for example on whether RL can improve upon the distillation SFT baseline for small models. We also show that multimodal reasoning capabilities emerge with online RL with textual data on top of a multimodal model. We share the results of our unsuccessful experiments. >> We release the weights of Magistral Small (24B) under the Apache 2 license1. | 在本文中,我们介绍了 Mistral 的首批推理模型:Magistral Small 和 Magistral Medium,它们分别基于 Mistral Small 3 和 Mistral Medium 3 模型,并详细阐述了我们提出的 RLVR 框架。本文的主要贡献如下: >> 我们详细介绍了如何仅通过强化学习训练 Magistral Medium,而无需从现有的推理模型中进行蒸馏,从而在 AIME-24(pass@1)上实现了近 50% 的性能提升。 >> 我们深入探讨了支持大规模在线强化学习的基础设施和设计选择。我们的异步系统通过频繁更新生成器而不中断它们,实现了快速、连续的强化学习训练,在效率和策略一致性之间取得了平衡。我们提出了一种简单却有效的策略,使模型实现多语言支持,其中链式思维和最终响应均以用户的语言呈现。 我们贡献了一些见解,这些见解补充或反驳了现有的 RLVR 文献,例如关于强化学习能否在小型模型上超越蒸馏 SFT 基线的问题。我们还展示了在多模态模型之上使用文本数据进行在线强化学习时,多模态推理能力是如何出现的。我们分享了未成功的实验结果。 我们以 Apache 2 许可证发布 Magistral Small(24B)的权重。 |
| The paper is organized as follows: Section 2 details the RL algorithm we used, along with the design choices implemented to guide the reasoning models in terms of language and format; Section 3 presents our scalable infrastructure that supports efficient training on a large cluster of GPUs; Section 4 discusses the data selection process we employed for efficient and effective training; Section 5 presents the performance of Magistral on reasoning and multilingual benchmarks; Section 6 shows the ablations done to motivate the training choices; Section 7 presents a PCA-based study of the model weights’ trajectory during RL, demonstrates that RL on text data preserves or even improves multimodal capabilities, and includes methods that worked poorly for Magistral; Section 8 shows that one can train a model to perform on par with R1 with distillation followed by RL, which we did not use for Magistral Medium; Finally, we conclude with some future directions in Section 9. | 本文的组织结构如下:第 2 节详细介绍了我们使用的强化学习算法,以及为引导推理模型在语言和格式方面所做的设计选择;第 3 节介绍了我们的可扩展基础设施,该基础设施支持在大型 GPU 集群上进行高效训练;第 4 节讨论了我们用于高效和有效训练的数据选择过程;第 5 节展示了 Magistral 在推理和多语言基准测试中的性能;第 6 节展示了为说明训练选择所做的消融实验。第 7 节基于主成分分析(PCA)对强化学习(RL)过程中模型权重的轨迹进行了研究,表明在文本数据上进行强化学习能够保持甚至提升多模态能力,并介绍了对 Magistral 效果不佳的方法;第 8 节表明,通过蒸馏再进行强化学习,可以训练出与 R1 表现相当的模型,而我们并未在 Magistral Medium 中使用这种方法;最后,我们在第 9 节中提出了未来的一些研究方向。 |
Figure 1: Performance of Magistral Medium on common reasoning benchmarks. We highlight the strength of our proposed RLVR framework, which yields a 50% increase in AIME-24 (pass@1) over the initial Mistral Medium 3 checkpoint, without any cold-start reasoning traces. We compare against analogous results from [DeepSeek-AI et al., 2025], which show RL improvements from DeepSeek-v3 to DeepSeek-R1 (January 25). Magistral Medium reaches 90% accuracy on AIME-24 with majority voting.图 1:Magistral Medium 在常见推理基准测试中的表现。我们突出了所提出的 RLVR 框架的优势,它在 AIME-24(pass@1)上比初始的 Mistral Medium 3 检查点提高了 50%,且无需任何冷启动推理痕迹。我们将其与 [DeepSeek-AI 等人,2025] 中类似的结果进行了比较,该结果展示了从 DeepSeek-v3 到 DeepSeek-R1(1 月 25 日)的强化学习改进。Magistral Medium 在 AIME-24 上通过多数投票达到了 90% 的准确率。
Conclusion
| Magistral is our first step towards generally capable systems with reinforcement learning. We look forward to the next research problems ahead of us: what loss and optimization algorithms are the most appropriate, how much gain can be unlocked by bootstrapping a model on its own reasoning traces, or how to scale to the next order of magnitude of compute. Looking ahead, we are also excited to push the boundaries of RL across a whole range of applications, with tool-use, integrated multimodality, and agents. As we explore this frontier, we remain committed to contributing to science in a transparent and optimistic manner. | Magistral 是我们迈向具备通用能力的强化学习系统的第一步。我们期待着接下来的研究难题:什么样的损失和优化算法最为合适,通过在模型自身的推理轨迹上进行引导能释放出多少收益,或者如何将计算规模提升到下一个数量级。展望未来,我们还很兴奋能推动强化学习在工具使用、集成多模态和智能体等整个应用范围内的边界。在探索这一前沿领域时,我们始终致力于以透明和乐观的方式为科学做出贡献。 |