新疆大学具身导航新范式!DOPE:基于双重对象感知增强网络的视觉语言导航

-
作者: Yinfeng Yu, Dongsheng Yang
-
单位:新疆大学计算机科学与技术学院
-
论文标题:DOPE: Dual Object Perception-Enhancement Network for Vision-and-Language Navigation
-
论文链接:https://arxiv.org/pdf/2505.00743
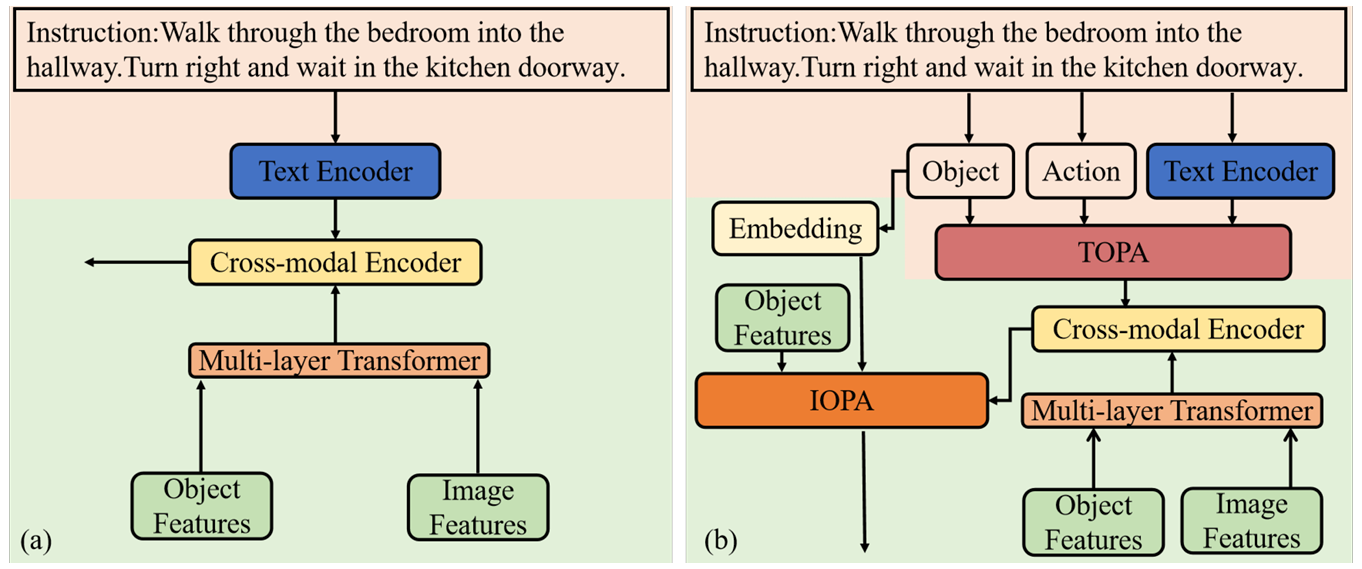
主要贡献
-
提出了一个双重对象感知增强网络(DOPE),用于提升视觉语言导航(VLN)任务中的语言理解能力和多模态对象关系建模能力。
-
设计了文本语义提取(TSE)和文本对象感知增强(TOPA)模块,通过细粒度的语言处理增强指令中关键信息的利用。
-
引入了图像对象感知增强(IOPA)模块,利用跨模态编码器深入挖掘文本和视觉信息之间的对象关系,提升导航决策的准确性和鲁棒性。
-
在R2R和REVERIE数据集上进行了广泛的实验验证,结果表明DOPE在多个指标上优于现有方法。
研究背景
-
视觉语言导航(VLN)任务要求智能体根据自然语言指令在陌生环境中导航。
- 该任务的核心挑战在于如何有效地整合语言指令和视觉信息,以做出准确的导航决策。尽管近年来在该领域取得了显著进展,但仍存在以下两个主要问题:
-
现有方法直接将完整的语言指令输入到多层Transformer网络中,未能充分利用指令中的细节信息,限制了智能体对语言的理解能力。
-
当前方法在建模不同模态间对象关系时存在不足,未能有效利用对象间的潜在线索,影响了导航决策的准确性和鲁棒性。
-
研究方法
本文提出的DOPE网络由三个关键模块组成:文本语义提取(TSE)、文本对象感知增强(TOPA)和图像对象感知增强(IOPA)。
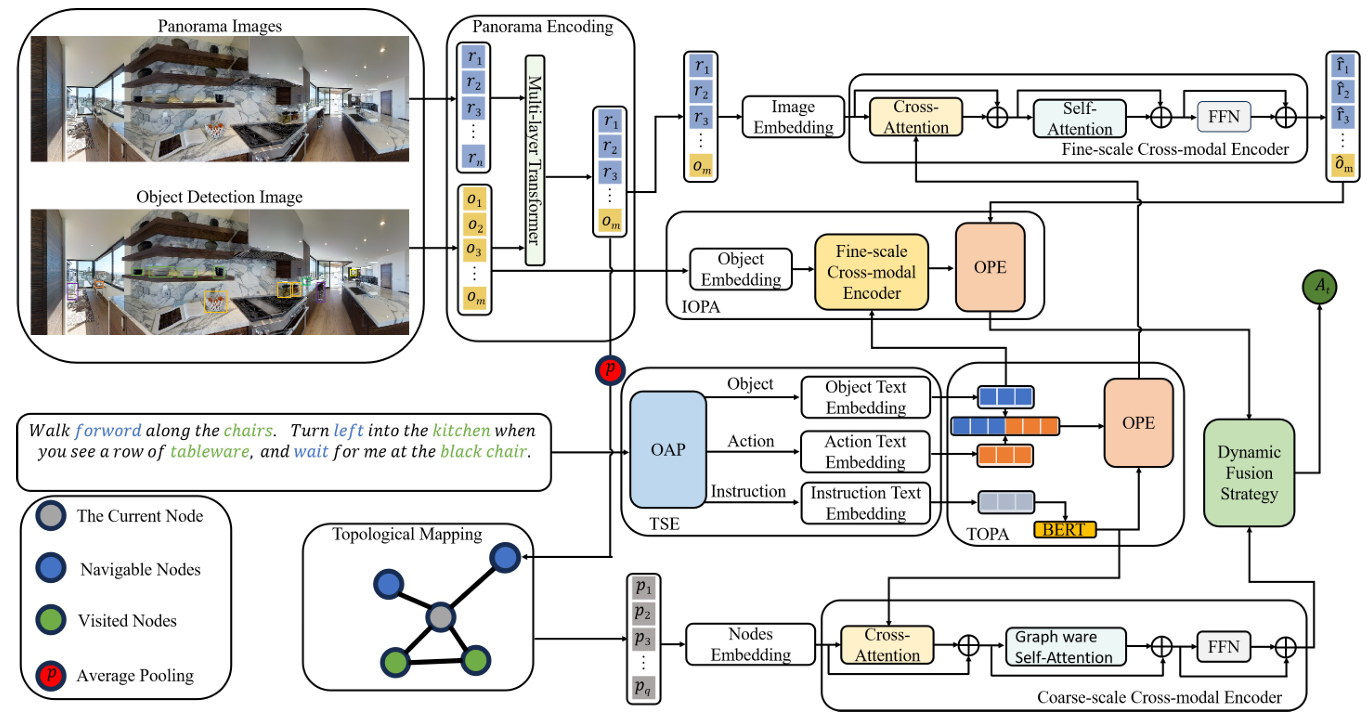
文本语义提取(TSE)
-
通过预训练的DistilBERT分词器和spaCy语言模型对自然语言指令进行分词和词性标注。
-
提取指令中的动作词和目标对象名词,生成对象短语和动作短语,并将这些短语嵌入到768维向量空间中。
-
通过位置嵌入保留单词的序列信息。

文本对象感知增强(TOPA)
-
将动作嵌入和对象嵌入与原始指令嵌入进行拼接。
-
使用预训练的BERT模型对指令中的单词进行编码,获取上下文语言特征。
-
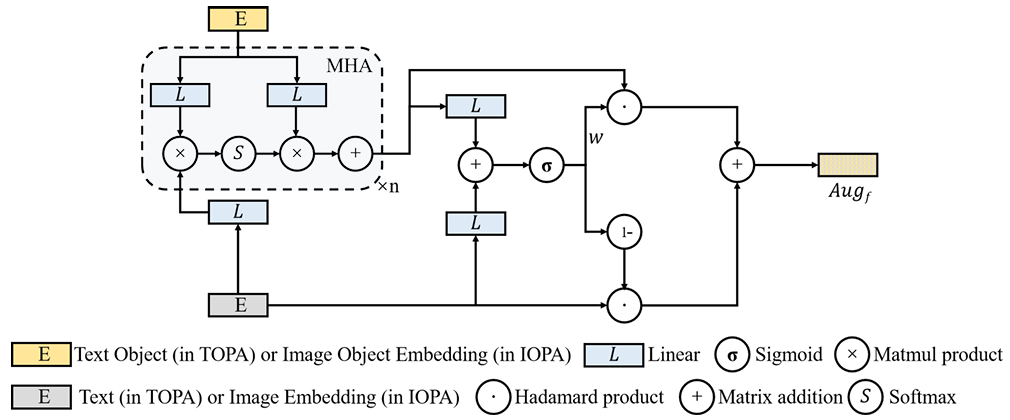
引入多头注意力机制(MHA),更新上下文特征与对象短语和动作短语之间的关系,增强语言理解能力。
-
使用门控结构动态平衡原始特征和增强特征的比例。
图像对象感知增强(IOPA)
-
使用CLIP模型提取全景图像和对象的特征。
-
通过Transformer架构建模图像和对象之间的空间关系。
-
引入两种位置嵌入:表示当前节点相对于起始节点的位置,以及邻近节点相对于当前节点的位置。
-
使用LXMERT模型作为跨模态编码器,建模图像对象特征和语言对象特征之间的关系,增强图像对象感知能力。
动态融合策略
-
在动作选择过程中,结合全局动作空间导航分数和局部动作分数,通过加权融合获得最终的动作预测概率。
实验
-
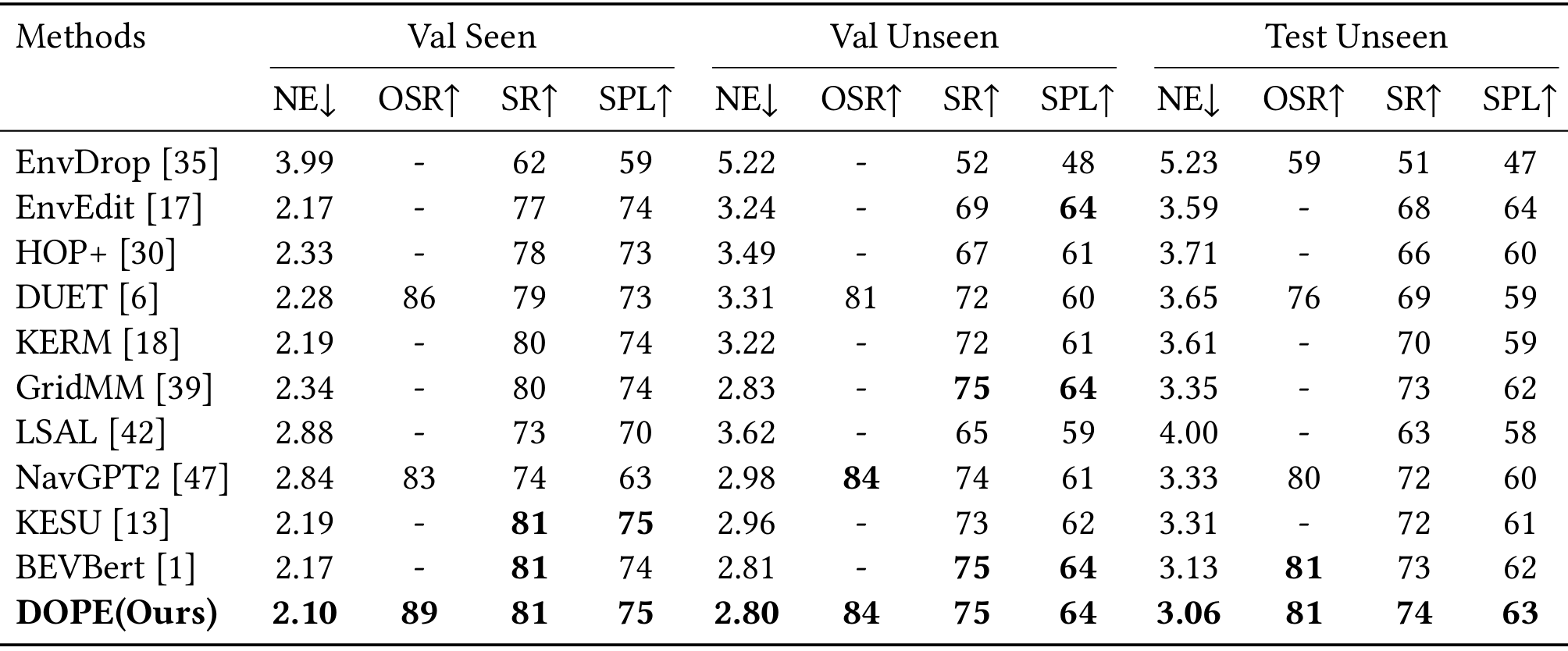
数据集:使用R2R和REVERIE数据集进行实验。R2R包含90个场景和21,567条导航指令;REVERIE包含21,702条描述目标位置的指令。
-
评估指标:在R2R数据集上使用导航误差(NE)、成功率(SR)、Oracle成功率(OSR)和路径长度加权成功率(SPL);在REVERIE数据集上额外使用远程目标定位成功率(RGS)和路径长度加权RGS(RGSPL)。
- 实验结果:
-
在R2R数据集上,DOPE在测试未见集上取得了最佳性能,与基线DUET相比,NE降低了0.59,OSR、SR和SPL分别提高了5%、5%和4%。
-
在REVERIE数据集上,DOPE在所有指标上均优于现有方法,与ACK相比,OSR、SR、SPL、RGS和RGSPL分别提高了4.09%、4.41%、3.98%、3.07%和2.28%。
-
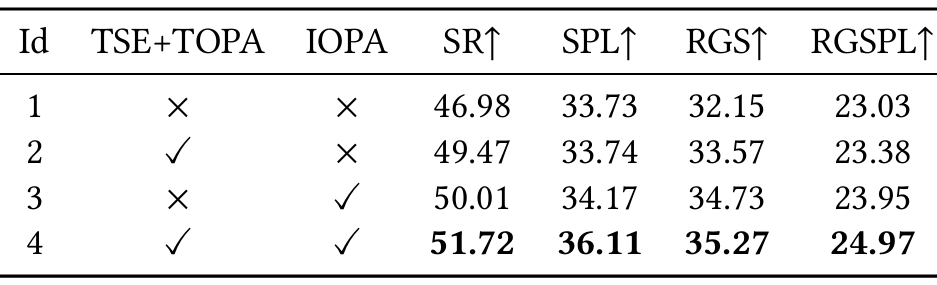
- 消融实验:
-
单独使用IOPA或TOPA模块时,模型性能均优于基线模型;同时使用两个模块时,性能提升更为显著。
-
在IOPA和TOPA模块中引入对象感知增强(OPE)模块后,模型性能进一步提升,表明OPE在增强对象感知方面发挥了重要作用。
-
结论与未来工作
- 结论:
-
DOPE通过增强语言理解和视觉感知能力,在VLN任务中取得了优于现有方法的性能。
-
通过TSE、TOPA和IOPA模块的协同作用,模型能够更有效地整合语言和视觉信息,提升导航决策的准确性和鲁棒性。
-
- 未来工作:
-
可以进一步探索如何更好地建模跨模态对象关系,以及如何在更大规模的数据集上验证模型的泛化能力。
-
此外,结合其他辅助任务(如目标检测、语义分割)可能会进一步提升模型的性能。
-
