论文略读:Large Language Models Assume People are More Rational than We Really are
ICLR 2025 5668
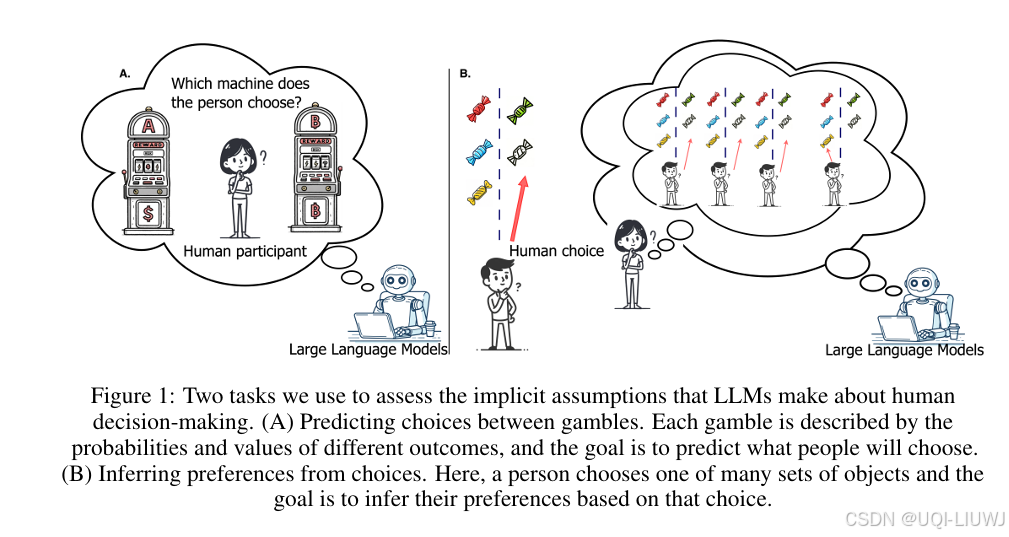
为了让 AI 系统能够有效地与人类沟通,它们必须理解人类是如何做决策的。然而,人类的决策并不总是理性的,因此大型语言模型(LLMs)中对人类决策过程的内隐建模必须能够捕捉这种非理性行为。
以往的一些实证研究似乎表明,LLMs 对人类行为的建模是准确的——它们在日常交互中表现得像我们预期中的人类。然而,本文通过将多种先进 LLM(如 GPT-4o、GPT-4 Turbo、LLaMA-3 8B 和 70B、Claude 3 Opus)在模拟和预测人类选择行为时的输出与一个大规模人类决策数据集进行系统比较,发现事实并非如此:
这些模型普遍高估了人类的理性程度,它们更倾向于依据经典的**期望值理论(expected value theory)**来预测行为,而不是符合真实人类的决策模式。
有趣的是,人类自己在解释他人行为时,也倾向于假设他人是理性的。因此,当进一步对比 LLM 与人类在另一个心理学数据集上对“他人决策”的推理结果时,研究发现两者的推理高度相关。
综上,LLM 所学习到的内隐决策模型,更接近于“人们如何期望别人决策”(理性),而非“人们实际是如何决策的”(非理性)。这一发现揭示了 LLM 与人类心理预期之间的微妙对齐,同时也暴露了它们在理解真实人类行为上的系统性偏差。