分割任意组织:用于医学图像分割的单样本参考引导免训练自动点提示方法|文献速递-深度学习医疗AI最新文献
Title
题目
Segment Any Tissue: One-shot reference guided training-free automaticpoint prompting for medical image segmentation
分割任意组织:用于医学图像分割的单样本参考引导免训练自动点提示方法
01
文献速递介绍
医学图像分割仍是包括诊断、制定治疗策略和预测预后在内的各种临床应用的前提。近年来,针对不同医学场景中各种组织分割的研究激增(Qureshi等人,2023)。然而,主流医学图像分割方法存在一定局限性。一方面,医学影像的专业性使得获取大量高质量、专家标注的医学图像面临重大挑战。另一方面,来自各种数字模态的医学图像可能存在领域差异。当前方法需要在特定数据集上训练以针对给定领域优化模型参数,这往往会加剧领域偏移。这一限制阻碍了医学图像分割在任务和领域间的可迁移性。因此,迫切需要开发一种类不可知模型,能够自动分割各种场景下医学图像中的组织,从而减少对大量标注和训练工作的依赖。 近年来,自然语言处理(NLP)领域基础模型的研究正逐步影响计算机视觉(CV)领域(Radford等人,2021;Jia等人,2021)。特别是DINOv2(Oquab等人,2023)仅依靠原始图像数据,通过全面捕捉图像和像素级的复杂信息来获取广义视觉特征。这使模型能够学习通用视觉特征,确保对下游任务的强大零样本迁移能力。同时,分割一切模型(SAM)(Kirillov等人,2023)已展现出卓越的零样本分割性能,在开放世界图像感知中显示出巨大潜力。视觉基础模型的发展已将医学图像分割任务从数据驱动的训练和测试范式转向基于提示工程的类不可知分割方法。尽管基础模型在计算机视觉中显示出巨大潜力,但将其应用于医学图像分割仍面临两个重大挑战(Xu等人,2023): 弥合医学图像与自然图像之间的领域差距。像SAM这样的主流视觉基础模型通常在包含数十亿自然图像和标注掩码的大规模数据集上训练。这些海量数据确保了SAM在自然图像上的出色泛化能力。然而,医学图像往往具有复杂背景和边界模糊的组织。因此,直接将SAM应用于医学图像可能无法产生令人满意的分割性能(Mazurowski等人,2023)。 自动生成高质量提示以协助SAM进行有效的医学图像分割。SAM作为交互式分割模型,依赖提示来实现所需的分割结果(Ji等人,2023)。鉴于医学数据的专业性,临床应用中的手动提示不切实际。因此,需要高效的自动提示流程来协助SAM进行自动分割。然而,由于医学图像的复杂性,更优化的提示方案对获得满意的分割结果至关重要。因此,缺乏有效的自动提示方法来协助SAM进行医学场景的分割。 基于上述启发并旨在解决上述挑战,我们引入了Segment Any Tissue (SAT),这是一种免训练模型,利用单张参考图像即可准确分割多个医学领域的组织。为了最大化视觉基础模型的协同效应,我们在特征空间和物理空间中开发了一系列自动提示生成技术。此外,我们为提示方案建立了评估标准,能够针对每张图像自动选择最佳参数,从而提高跨任务和跨领域的可迁移性。 此外,我们通过整合多幅参考图像扩展了单样本框架,构建了集成SAT,进一步提升分割性能。我们在六个公共和私有数据集上验证了SAT,包括超参数选择和消融研究,证实了各组件的有效性。对比实验表明,SAT不仅性能可与全监督分割网络相当,还超越了其他近期提出的最先进单样本方法。此外,我们进一步评估了集成SAT的性能,并进行了全面的运行时分析以评估其计算效率。 本研究的主要贡献总结如下: - 仅使用单张参考图像,我们构建了SAT,其无需任何训练过程即可高效分割多种医学场景中的组织。 - 我们在特征空间和物理空间中开发了一系列新颖的点提示工程技术,为医学图像分割中的SAM自动生成优化提示。 - 我们定义了提示方案的评估指标,并利用每张图像的提示分数在提示工程中自动选择超参数,进一步增强任务和领域的可迁移性。 这项工作是我们MICCAI论文(Liu等人,2024b)的重大扩展。在方法上,我们设计了一个包含超参数库和提示方案评估机制的循环反馈模块。该模块为每个目标图像动态选择最合适的超参数,从而处理不同尺度的类内和类间结构。此外,我们通过聚合多幅参考图像扩展了单样本框架,构建了集成SAT,证明加入少量额外参考图像可进一步提升分割性能。在实验上,我们将方法扩展到多个公共和私有数据集,涵盖从微观到宏观的尺度,并验证了其有效性。此外,我们进行了全面的超参数选择实验、消融研究、鲁棒性分析和运行时评估。 本文其余部分的结构概述如下。第2节介绍相关工作概述。第3节详细介绍所提出的框架。实验结果在第4节呈现。第5节进行讨论,第6节给出结论。
Abatract
摘要
Medical image segmentation frequently encounters high annotation costs and challenges in task adaptation. While visual foundation models have shown promise in natural image segmentation, automaticallygenerating high-quality prompts for class-agnostic segmentation of medical images remains a significantpractical challenge. To address these challenges, we present Segment Any Tissue (SAT), an innovative,training-free framework designed to automatically prompt the class-agnostic visual foundation model for thesegmentation of medical images with only a one-shot reference. SAT leverages the robust feature-matchingcapabilities of a pretrained foundation model to construct distance metrics in the feature space. By integratingthese with distance metrics in the physical space, SAT establishes a dual-space cyclic prompt engineeringapproach for automatic prompt generation, optimization, and evaluation. Subsequently, SAT utilizes a classagnostic foundation segmentation model with the generated prompt scheme to obtain segmentation results.Additionally, we extend the one-shot framework by incorporating multiple reference images to constructan ensemble SAT, further enhancing segmentation performance. SAT has been validated on six public andprivate medical segmentation tasks, capturing both macroscopic and microscopic perspectives across multipledimensions. In the ablation experiments, automatic prompt selection enabled SAT to effectively handle tissuesof various sizes, while also validating the effectiveness of each component. The comparative experiments showthat SAT is comparable to, or even exceeds, some fully supervised methods. It also demonstrates superiorperformance compared to existing one-shot methods. In summary, SAT requires only a single pixel-levelannotated reference image to perform tissue segmentation across various medical images in a training-freemanner. This not only significantly reduces the annotation costs of applying foundational models to the medicalfield but also enhances task transferability, providing a foundation for the clinical application of intelligentmedicine.
医学图像分割常常面临高昂的标注成本和任务适配挑战。尽管视觉基础模型在自然图像分割中展现出潜力,但为医学图像的类不可知分割自动生成高质量点提示仍是一个重大实际挑战。为解决这些挑战,我们提出了Segment Any Tissue (SAT),这是一种创新的免训练框架,旨在仅通过单样本参考自动提示类不可知视觉基础模型进行医学图像分割。SAT利用预训练基础模型强大的特征匹配能力,在特征空间中构建距离度量,并将其与物理空间的距离度量相结合,建立了用于自动点提示生成、优化和评估的双空间循环点提示工程方法。随后,SAT利用类不可知基础分割模型和生成的点提示方案获取分割结果。此外,我们通过整合多幅参考图像扩展了单样本框架,构建了集成SAT,进一步提升分割性能。SAT已在六个公共和私有医学分割任务上得到验证,涵盖多个维度的宏观和微观视角。在消融实验中,自动点提示选择使SAT能够有效处理各种大小的组织,并验证了各组件的有效性。对比实验表明,SAT的性能可与某些全监督方法相当甚至超越,且相比现有单样本方法表现更优。总之,SAT仅需一张像素级标注的参考图像,即可通过免训练方式对各种医学图像进行组织分割。这不仅显著降低了基础模型在医学领域应用的标注成本,还增强了任务迁移能力,为智能医学的临床应用提供了基础。
Method
方法
This section introduces our training-free approach, SAT, designedfor the segmentation of any tissue in images from different medical scenarios with a one-shot reference. The overview of SAT is illustrated inFig. 1. Our framework comprises three components: patch-level featureextraction, automatic prompt scheme generation, and class-agnosticsegmentation. Specifically, given a target image 𝑥𝑡 and a one-shotreference image 𝑥𝑟 , we divide both into patches 𝑝𝑡 and 𝑝𝑟 . Firstly,the patch-level feature extraction generates a correspondence matrix𝑀𝑠* by calculating the similarity between 𝑝𝑡 and 𝑝𝑟 . Subsequently, weutilize 𝑀𝑠 to design automatic dual-space point prompt engineeringfor obtaining optimal positive and negative prompt points. Finally,the final prompt scheme is used as inputs to SAM, facilitating thegeneration of mask proposals. In the following subsections, we willdescribe these components in detail
本节介绍我们设计的免训练方法SAT,该方法用于通过单样本参考对不同医学场景图像中的任意组织进行分割。SAT的概述如图1所示。我们的框架包含三个组件:补丁级特征提取、自动提示方案生成和类不可知分割。具体而言,给定目标图像 (x_t) 和单样本参考图像 (x_r),我们将两者均划分为补丁 (p_t) 和 (p_r)。首先,补丁级特征提取通过计算 (p_t) 和 (p_r) 之间的相似度生成对应矩阵 (M_s)。随后,我们利用 (M_s) 设计自动双空间点提示工程,以获取最优的正负提示点。最后,将最终的提示方案作为输入提供给SAM,以辅助生成掩码建议。在以下子部分中,我们将详细描述这些组件。
Conclusion
结论
In this study, we introduce SAT, a training-free model designed tosegment any tissue in images from various medical scenes using onlya one-shot reference. The proposed framework harnesses the robustfeature matching capabilities inherent in a universal feature extractionmodel to define the patch-level feature distances in both the reference and target images. By combining feature distances with physicaldistances, we construct a prompt engineering method for automaticprompt scheme generation through a cyclic feedback loop. This promptengineering approach automatically selects hyperparameters and generates optimizations to output the final prompt scheme. The optimizedprompt is then input into a class-agnostic segmentation model, resultingin the final segmentation outcome. Intensive experiments across multiple datasets, including ablation studies and comparison experiments,show that the performance of SAT is comparable to fully supervisedmethods and surpasses other recently proposed state-of-the-art one-shotmethods. In the future, we aim to extend SAT to multi-objective segmentation of medical images and explore medical image segmentationin the few-shot paradigm to further improve segmentation performanceand enhance its reliability for clinical deployment.
在本研究中,我们介绍了SAT——一种免训练模型,其设计目的是仅使用单样本参考图像,对各种医学场景图像中的任意组织进行分割。所提出的框架利用通用特征提取模型中固有的强大特征匹配能力,来定义参考图像和目标图像中的补丁级特征距离。通过将特征距离与物理距离相结合,我们构建了一种提示工程方法,通过循环反馈回路自动生成提示方案。这种提示工程方法会自动选择超参数并生成优化方案,以输出最终的提示方案。随后,将优化后的提示输入到类不可知分割模型中,从而得到最终的分割结果。在多个数据集上进行的大量实验(包括消融实验和对比实验)表明,SAT的性能可与全监督方法相媲美,并且超越了其他近期提出的最先进单样本方法。未来,我们旨在将SAT扩展到医学图像的多目标分割领域,并探索少样本范式下的医学图像分割,以进一步提升分割性能,并增强其在临床部署中的可靠性。
Results
结果
Extensive experiments are conducted to verify the effectivenessof the proposed SAT on six public or private medical segmentationtasks from varied image modalities, capturing both macroscopic andmicroscopic perspectives across multiple dimensions: ISIC (Codellaet al., 2019), JSRT (Shiraishi et al., 2000), Kvasir (Jha et al., 2020),FLARE (Ma et al., 2023), MSTSD (Liu et al., 2024c), and GBMSD.Examples are shown in Fig. 3. In each dataset, only one of theseimages is served as the reference, while the remaining are employedto evaluate the model’s performance. More details are described asfollows:
ISIC: The ISIC 2018 dataset, released by the International SkinImaging Collaboration (ISIC), is a large-scale collection of dermatoscopic images. Task 1 of this dataset focuses on lesion segmentationchallenges and comprises 2594 images. The ground truth mask imagesare generated using various techniques and meticulously curated byprofessional dermatologists.
4.1 数据集描述 我们在六个来自不同成像模态的公共或私有医学分割任务上进行了广泛实验,以验证所提出的SAT的有效性,这些任务涵盖多个维度的宏观和微观视角:ISIC(Codella等人,2019)、JSRT(Shiraishi等人,2000)、Kvasir(Jha等人,2020)、FLARE(Ma等人,2023)、MSTSD(Liu等人,2024c)和GBMSD。示例见图3。在每个数据集中,仅将其中一张图像用作参考,其余图像用于评估模型性能。更多细节如下: ISIC数据集:ISIC 2018数据集由国际皮肤成像协作组织(ISIC)发布,是一个大规模的皮肤镜图像集合。该数据集的任务1聚焦于病变分割挑战,包含2594张图像。其真实掩码图像通过多种技术生成,并由专业皮肤科医生精心整理。
Figure
图
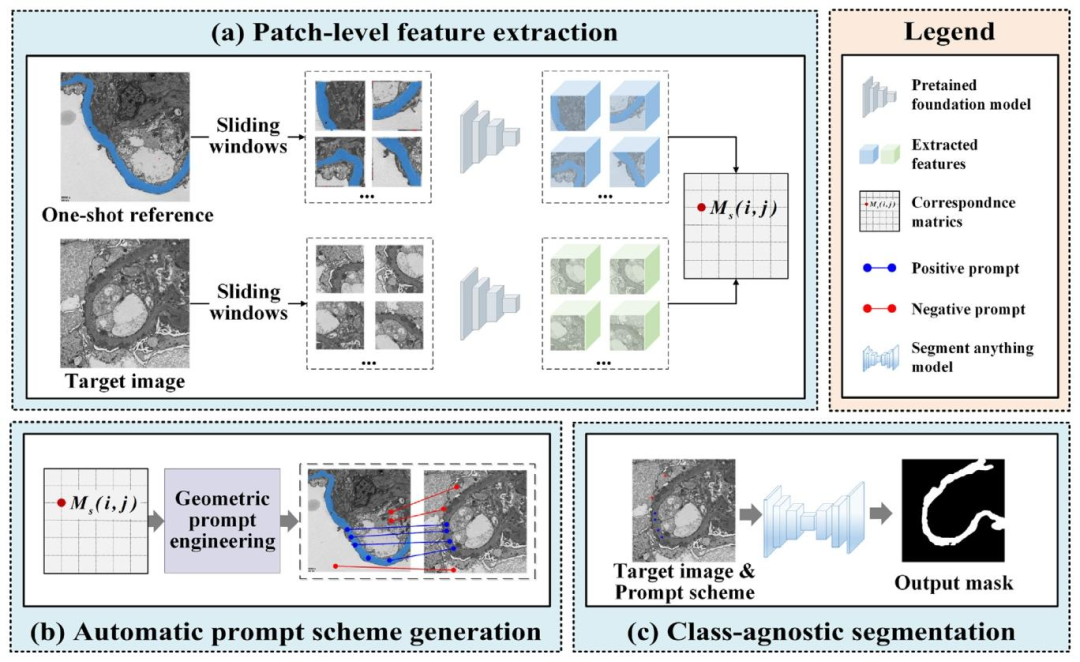
Fig. 1. A workflow for SAT, the one-shot reference-guided training-free framework, automatizes the medical image segmentation through three key components: patch-level featureextraction, automatic prompt scheme generation, and class-agnostic segmentation.
图1. SAT工作流程示意图 SAT是一种单样本参考引导的免训练框架,通过三个关键组件实现医学图像分割的自动化:补丁级特征提取、自动提示方案生成和类不可知分割。
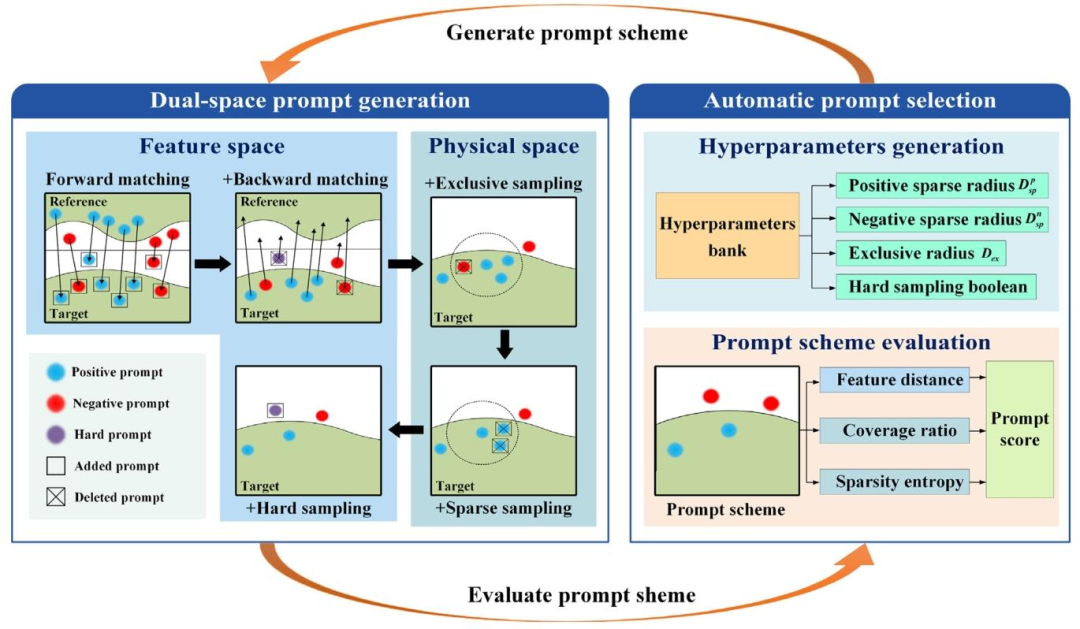
Fig. 2. A process for automatic dual-space prompt scheme generation, which includes a feedback loop between the automatic dual-space prompt scheme generation module andautomatic prompt selection.
图2. 自动双空间提示方案生成流程 该流程包含自动双空间提示方案生成模块与自动提示选择之间的反馈循环机制。
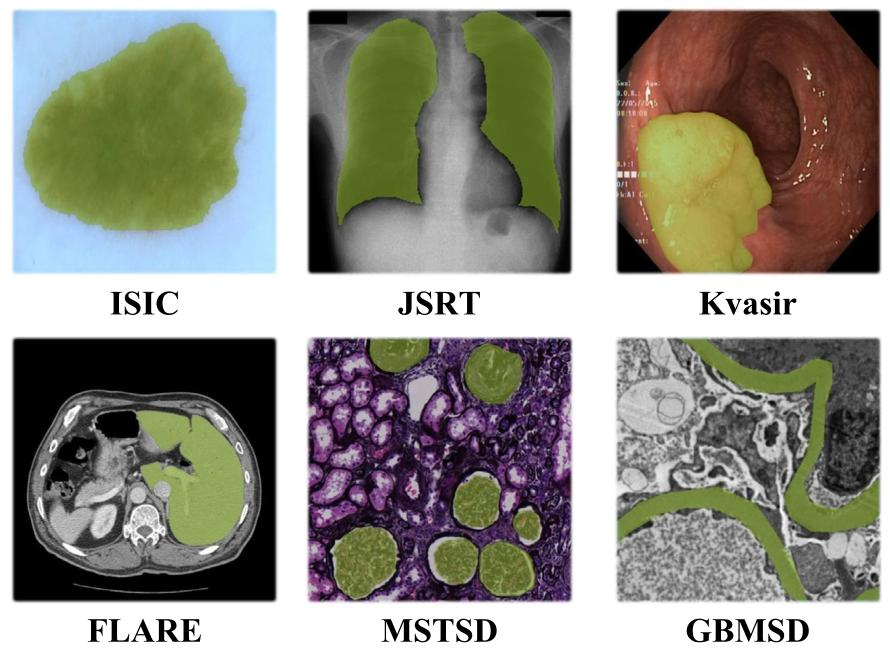
Fig. 3. Examples from the utilized datasets. The highlighted zones are the RoIs of different medical scenes.
图3. 所用数据集示例 图中高亮区域为不同医学场景的感兴趣区域(RoIs)。
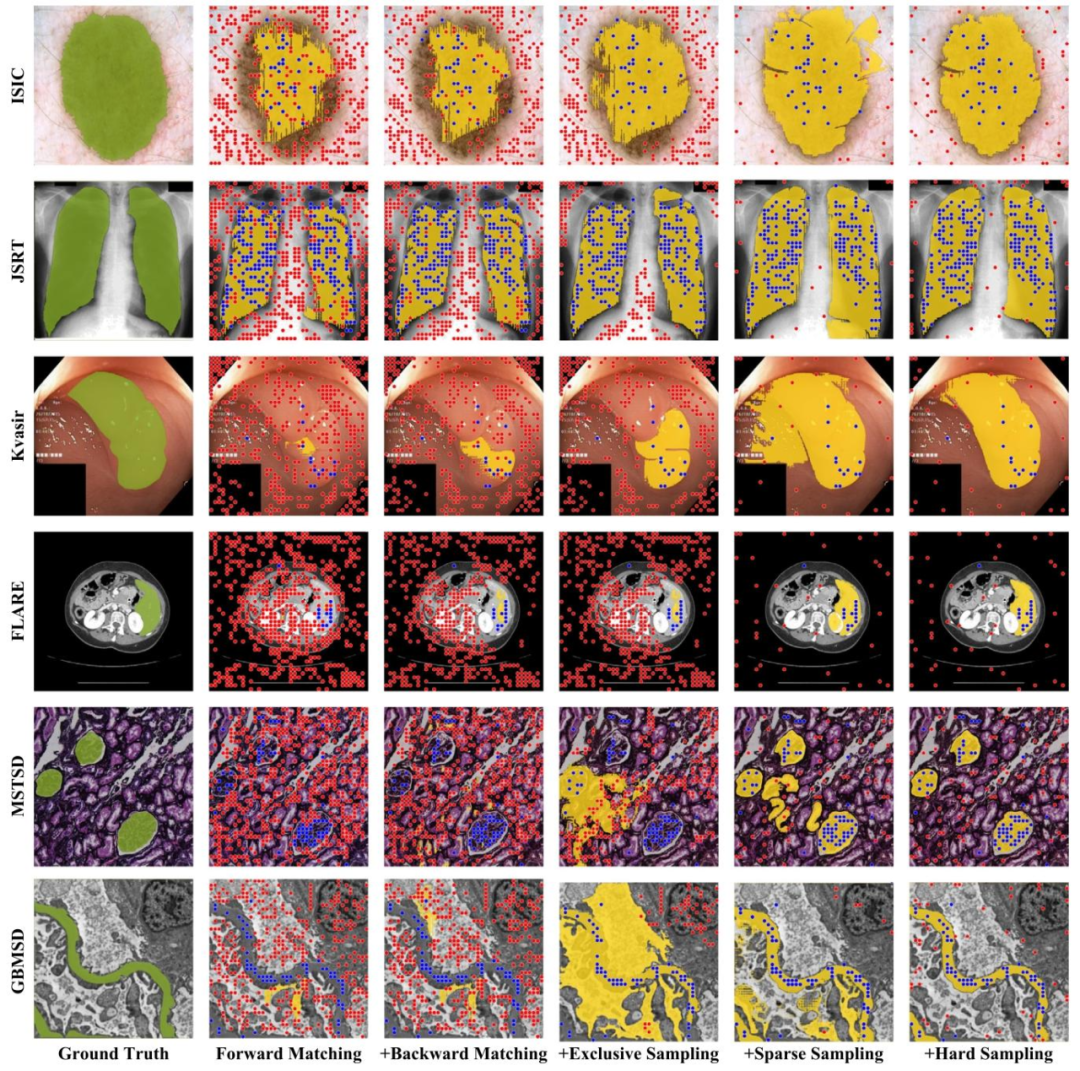
Fig. 4. Different stages of automatic prompt engineering yield different prompt schemes, along with their corresponding segmentation results. Blue dots represent positive promptpoints, whereas red dots signify negative ones. Notably, as the components of prompt engineering are refined, the segmentation results steadily converge towards the ground truth.
图4. 自动提示工程不同阶段的提示方案及对应分割结果 自动提示工程的不同阶段会产生不同的提示方案及其对应的分割结果。蓝色点表示正提示点,红色点表示负提示点。值得注意的是,随着提示工程组件的优化,分割结果逐渐向真实标签收敛。

Fig. 5. Qualitative segmentation results of recently proposed methods and proposed SAT in different medical segmentation datasets
图 5. 近期提出的方法与本文 SAT 在不同医学分割数据集上的定性分割结果
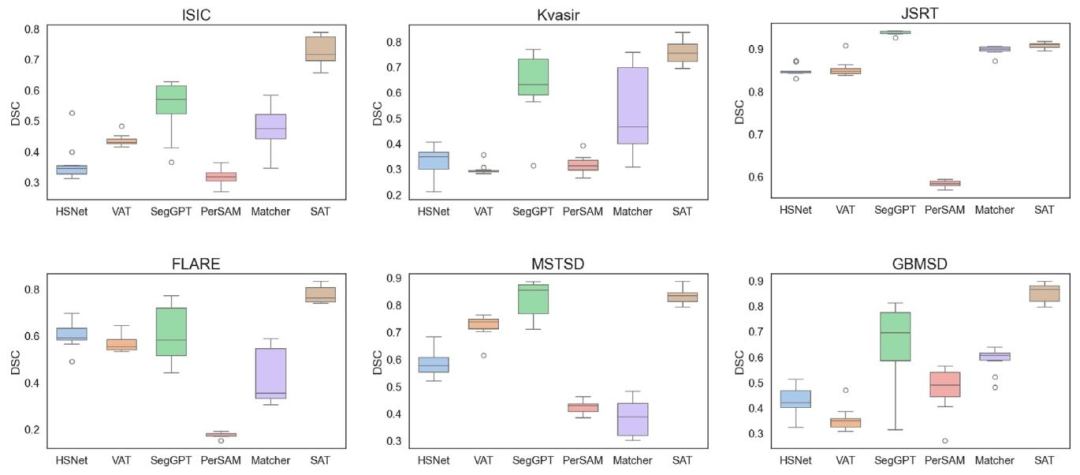
Fig. 6. Robustness analysis of various methods across different datasets.
图 6. 不同方法在各类数据集上的鲁棒性分析
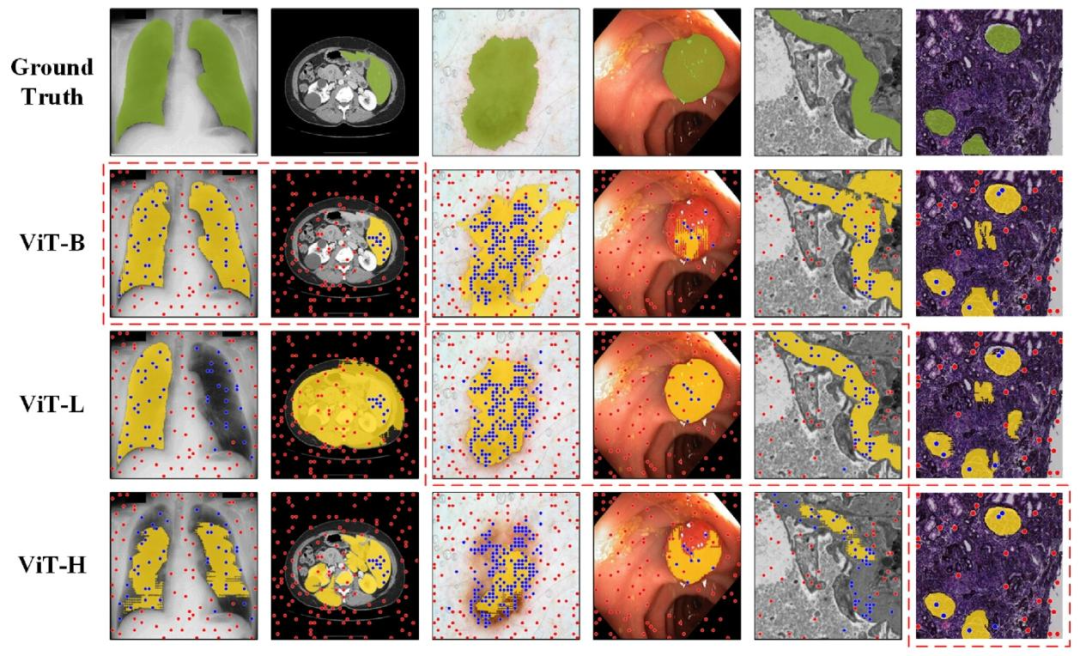
Fig. 7. Qualitative segmentation results of SAM with different backbones under the same prompts, the dashed box highlights the optimal results.
图 7. 相同提示下不同主干网络的 SAM 定性分割结果
Table
表

Table 1The performance comparison of different structures
表1 不同结构的性能对比
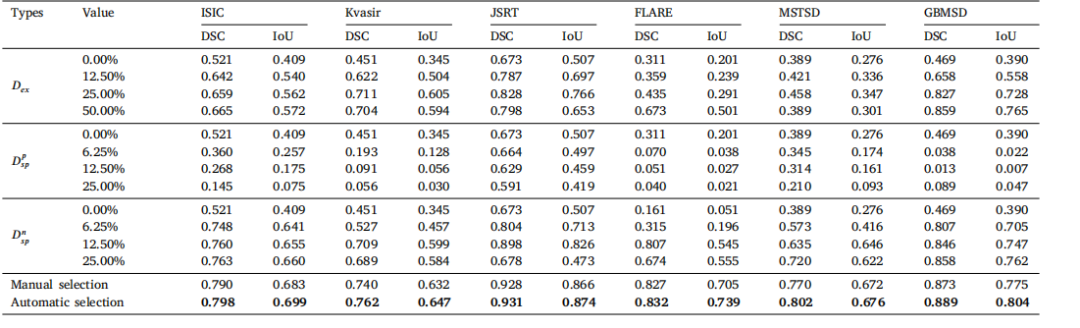
Table 2Comparative results of different hyperparameter
表2 不同超参数的对比结果

Table 3Comparative results of SAM utilizing different backbones
表3 采用不同主干网络的SAM对比结果

Table 4The performance comparison with fully supervised segmentation methods
表 4 与全监督分割方法的性能对比

Table 5The performance comparison with one-shot methods.
表 5 与单样本方法的性能对比

Table 6Comparative results of SAM utilizing different reference counts.
表6 采用不同参考图像数量的SAM对比结果
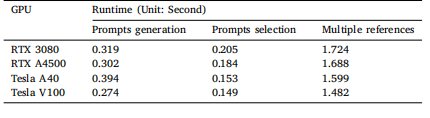
Table 7Runtime for different GPUs.
表 7 不同 GPU 的运行时间