统计学习—有监督part
回归:

分类:

一,基本概念:

1,model评估标准:
(1)回归:
训练集以及测试集上的MSE:


train集:单调递减
test集:U形曲线
(2)分类:
错分率:

(3)贝叶斯分类器:
分给最有可能的类别,所以会有一个p的max,其实可以类别决策树中第m个区域也就是第m个叶节点,如果是分类树的话,输出的就是类别的众数;
根据贝叶斯定理,计算给定预测变量值下每个类别的条件概率,将观测值分配到条件概率最大的类别
——》在理论上能够达到最低的测试错误率



(4)KNN分类器:
根据训练数据中与待分类点最近的𝐾个点的类别信息,通过多数投票等方式确定待分类点的类别

(5)贝叶斯分类器 vs KNN分类器
2,偏差-方差分解:
主要是从测试集上的MSE进行数学期望分析的时候,
将测试集上的MSE分解为方差、偏差平方和不可约误差3部分,以回归为例进行分析

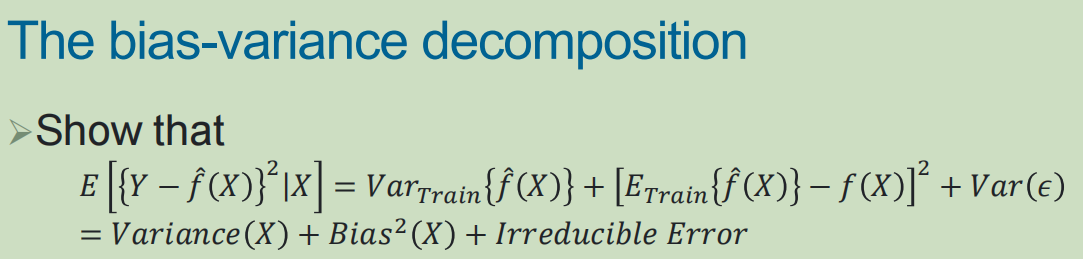


偏差:model对data拟合程度
方差:model对data敏感程度(对不同数据集拟合的波动,响应,抗噪声noise)
二,回归
| 对比项目 | 简单线性回归 | 多元线性回归 |
|---|---|---|
| 模型形式 | 𝑌=𝛽₀+𝛽₁𝑋+𝜖 | 𝑌=𝛽₀+𝛽₁𝑋₁+𝛽₂𝑋₂+…+𝛽𝑝𝑋𝑝+𝜖 |
| 系数解释 | 𝛽₁ 表示 𝑋 每增加一个单位,𝑌 平均增加的量 | 𝛽𝑗 表示在其他预测变量固定的情况下,𝑋𝑗 每增加一个单位,𝑌 平均增加的量 |
| 系数估计方法 | 最小二乘法,使 RSS 最小 | 最小二乘法,使 RSS 最小 |
| 适用场景 | 一个自变量和一个因变量之间的线性关系分析 | 多个自变量和一个因变量之间的线性关系分析 |
| 模型假设 | 线性、独立性、正态性、等方差 | 线性、独立性、正态性、等方差,此外还假设自变量之间不完全相关(无完全共线性) |
| 优点 | 简单易懂,计算方便,对数据要求较低 | 能够同时考虑多个自变量对因变量的影响,模型更全面 |
| 缺点 | 只能分析一个自变量对因变量的影响,无法考虑多个自变量的综合影响 | 模型复杂度增加,对数据要求较高,存在多重共线性问题可能导致模型不稳定,系数解释困难 |
| 模型比较方法 | 主要通过 R²、t 检验等判断模型的显著性和拟合优度 | 除了 R²、t 检验外,还需要进行 F 检验判断整体模型的显著性,同时需要关注多重共线性等问题 |
| 预测能力 | 若自变量与因变量的线性关系明显,则预测能力较好,否则可能偏差较大 | 能够利用多个自变量的信息进行预测,预测能力可能更强,但如果自变量之间存在共线性等问题,可能会影响预测的准确性 |
1,简单线性回归:

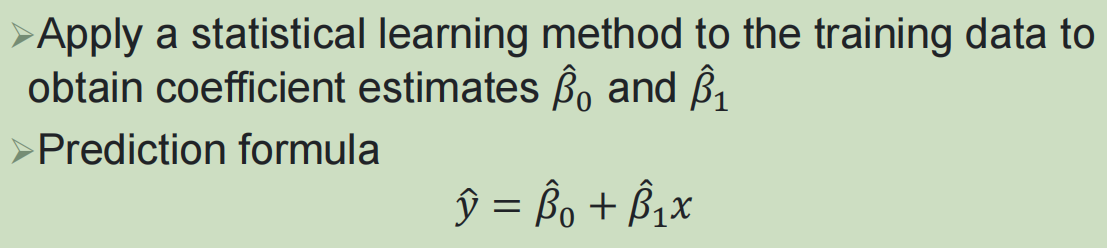



系数估计是无偏估计:
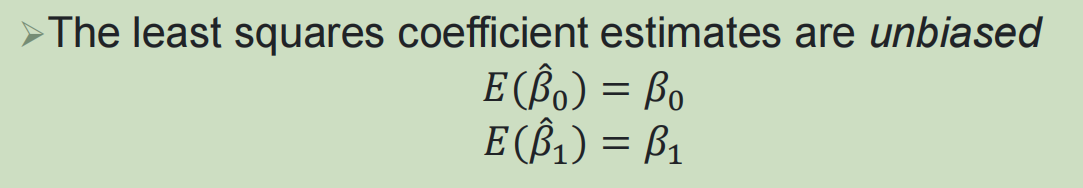
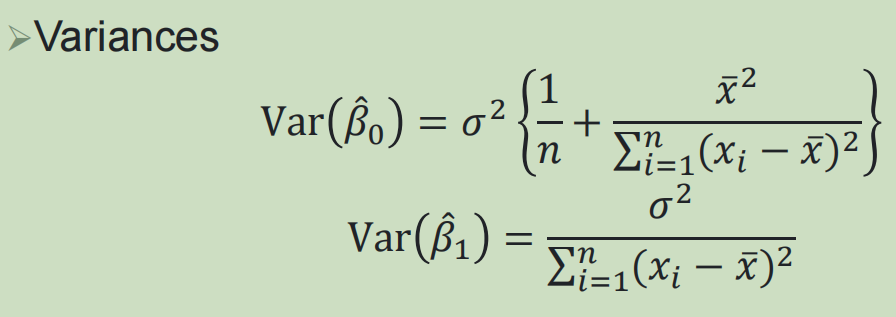
观测值与拟合值之间的标准差:残差标准差RSE

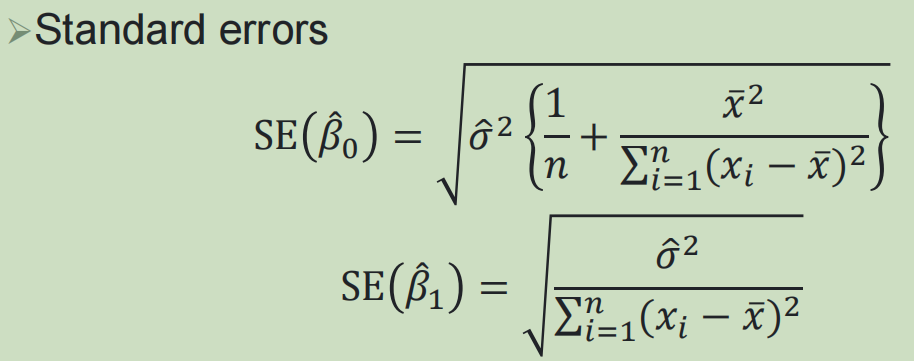
估计参数范围:
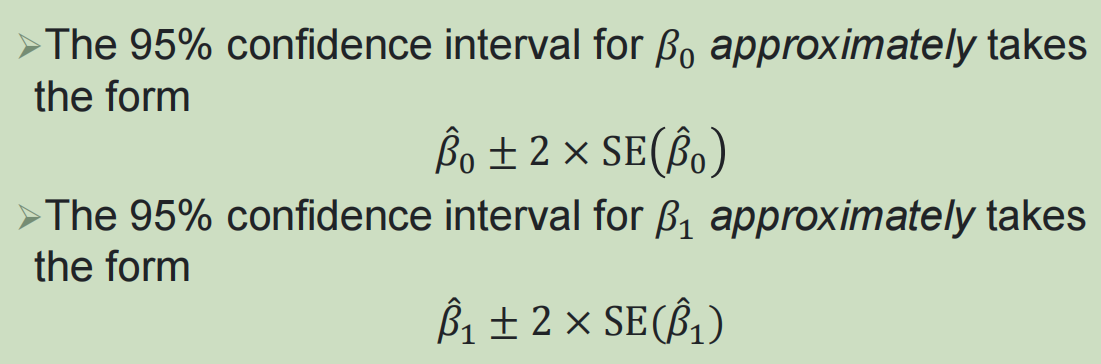
2,简单线性回归中的假设检验:
通过t检验判断自变量和因变量之间是否存在关系

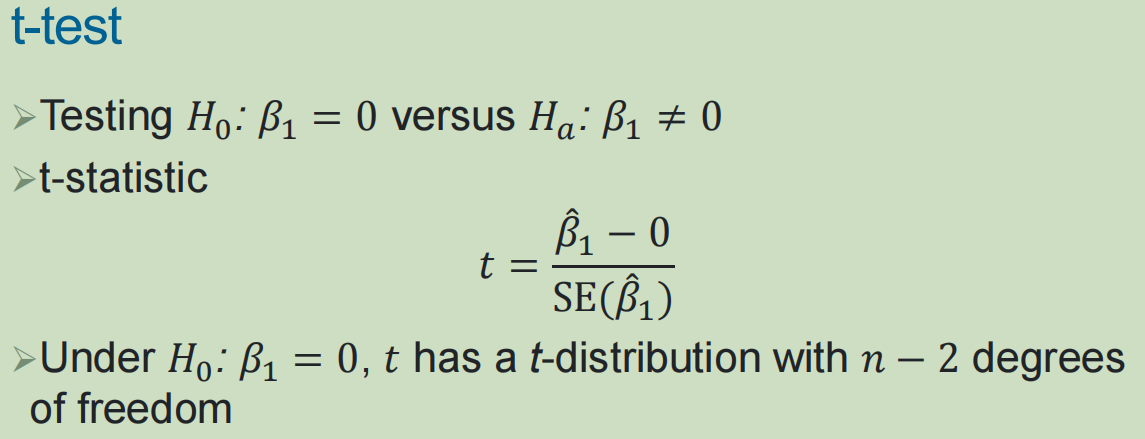

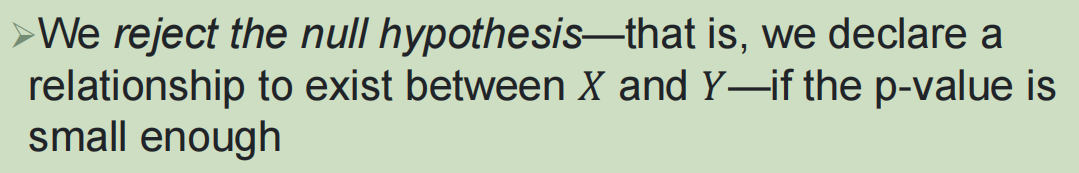
3,最小二乘法拟合的评估:

残差标准误:

决定系数:衡量模型对数据的拟合程度,表示因变量的变异中可由自变量解释的部分

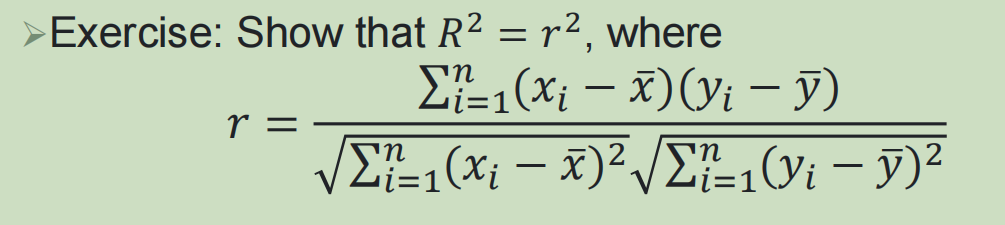
4,多元线性回归:

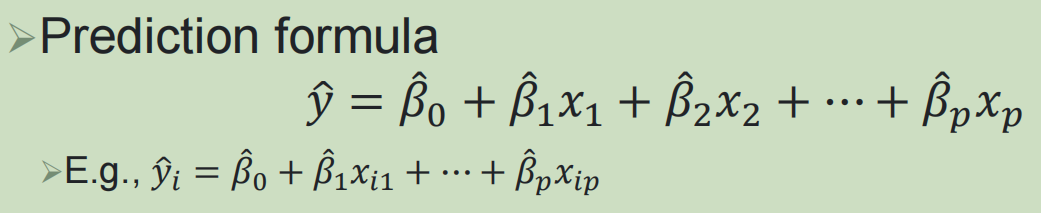
还是最小化RSS,使用最小二乘法估计系数
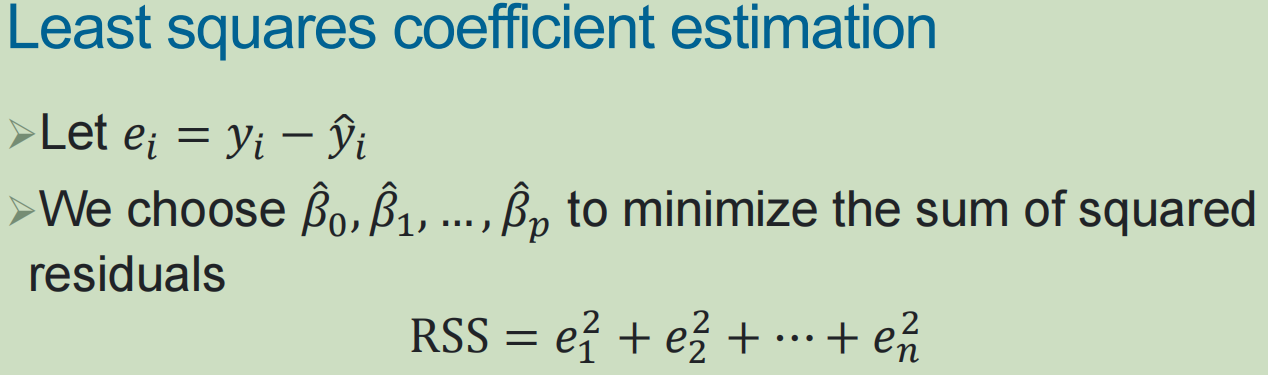
5,多元线性回归中的假设检验:


实际上就是特征特征筛选部分:
检验模型中一部分系数是否为零,这有助于我们确定哪些预测变量对响应变量有显著影响,从而进行变量选择和模型简化(假设有q个子集的预测变量的系数为0)
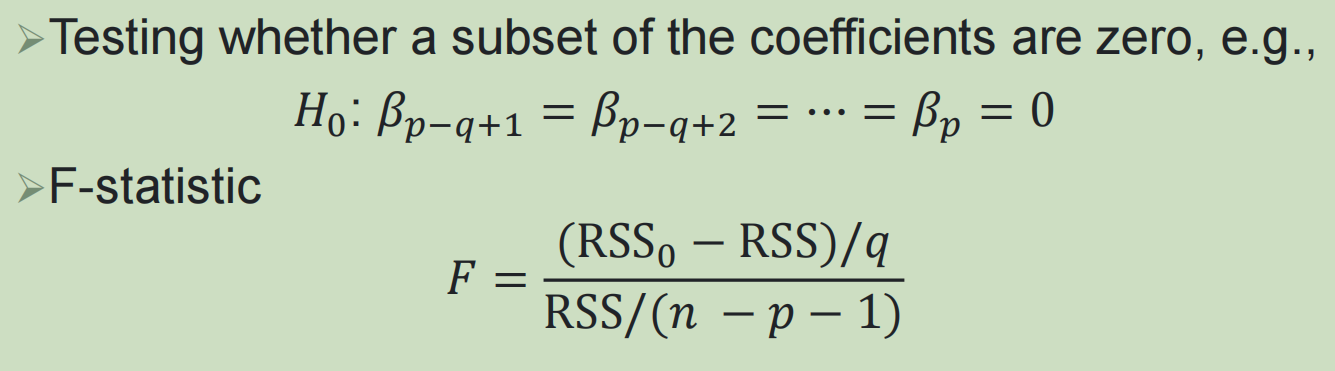

6,个体p值与整体F统计量的重要性:
使用 F 统计量检验是否所有系数都为零,判断模型的整体显著性。同时指出,即使个别变量的 p 值较大,整体模型也可能显著,因此需要综合考虑整体 F 检验和个体 t 检验的结果



7,拟合评估:模型拟合优度
同样使用 R² 统计量和残差标准误差衡量模型拟合程度,但指出 R² 的值会随着变量数量的增加而增加,即使新加入的变量并不显著

8,多元线性回归中的决定系数的性质证明:




9,预测区域与置信区间之间的差异:

预测的区间会更宽一点,因为包含了不可约误差?????????????????????
10,线性回归 vs KNN
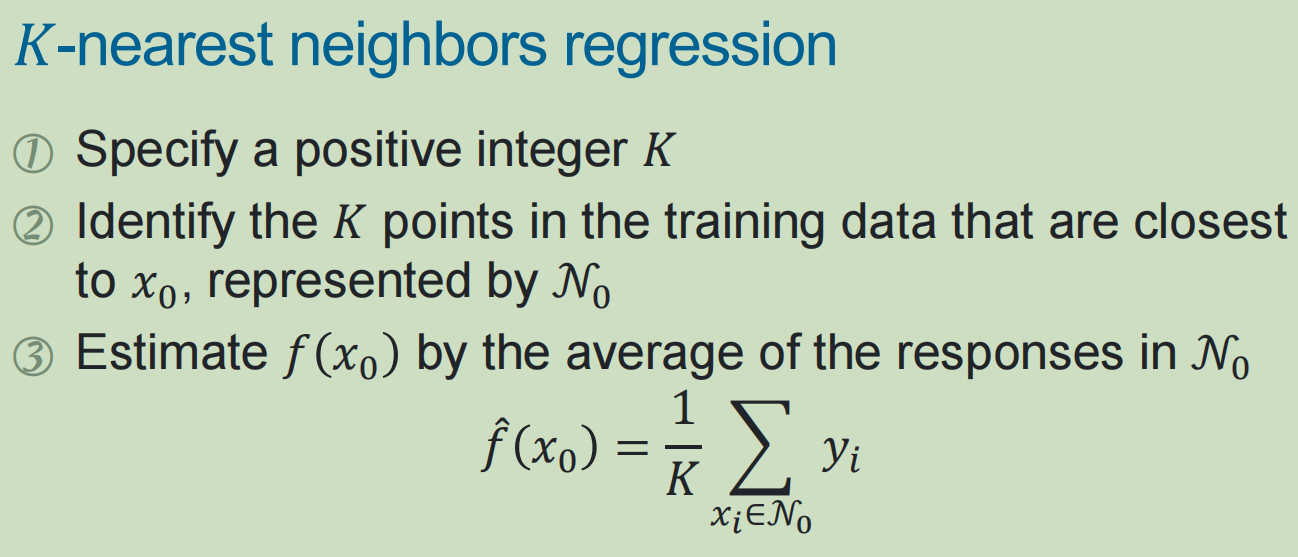
KNN回归:分类的话就多数投票,输出class的众数;
回归的话,就是取领域中的响应值的均值。
线性回归拓展

11,定性预测变量:
如何将定性预测变量(如房屋拥有情况、地区等)转化为虚拟变量,使其能够在线性回归模型中使用。例如,对于二水平的定性变量,可以用 0 和 1 表示两个水平;对于多水平的定性变量,需要创建多个虚拟变量。

12,线性模型的扩展:
去除加性假设:引入交互项


13,回归诊断:


基本假设:
响应变量与预测变量之间不存在非线性关系——》残差图
误差项之间不相关(独立)——》残差的自相关图
误差项的方差恒定——》残差图
离群点:实际响应与模型预测相差较大
高杠杆点:预测变量不寻常,杠杆统计量

共线性:多个变量之间存在强相关性

通过检测方差膨胀因子检测

三,分类
1,逻辑回归:
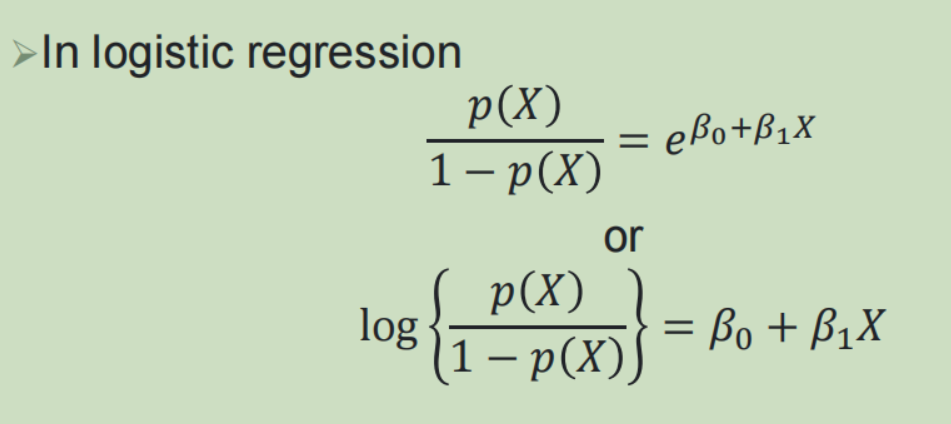


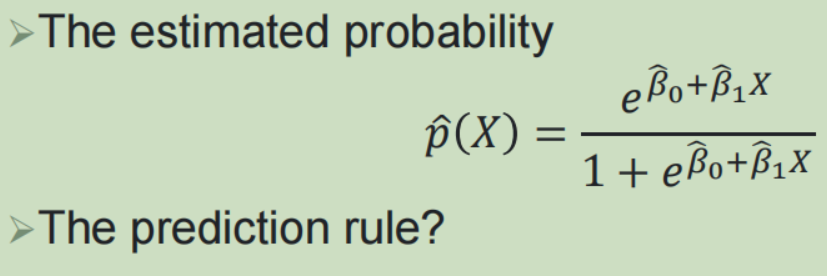
2,多项逻辑回归
3,概率生成model: (1)贝叶斯规则:依据观测值的预测值,将其分类给最可能的类
(1)贝叶斯规则:依据观测值的预测值,将其分类给最可能的类
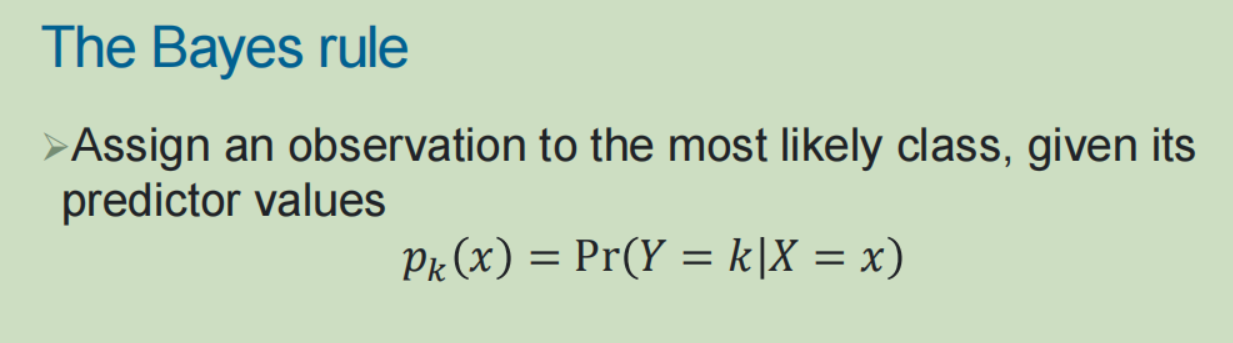
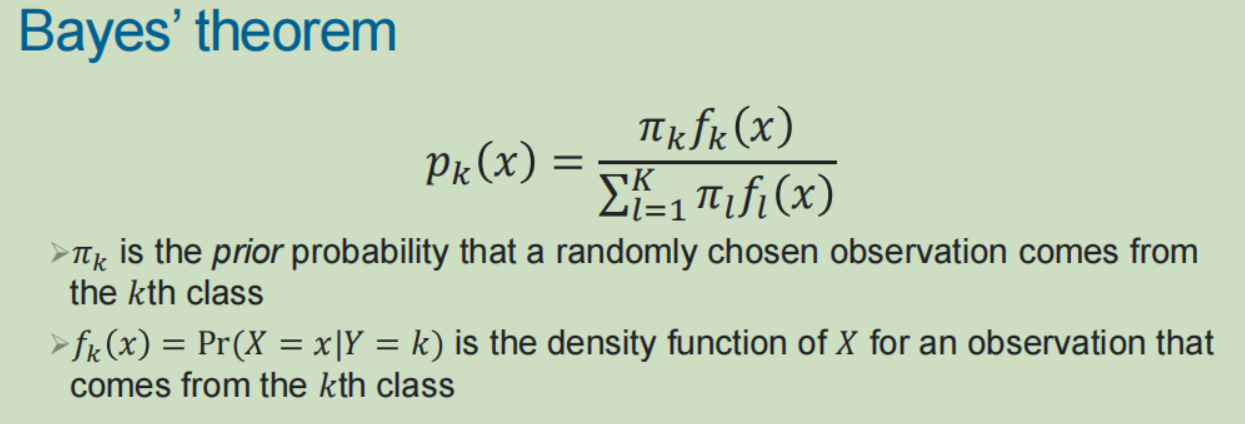
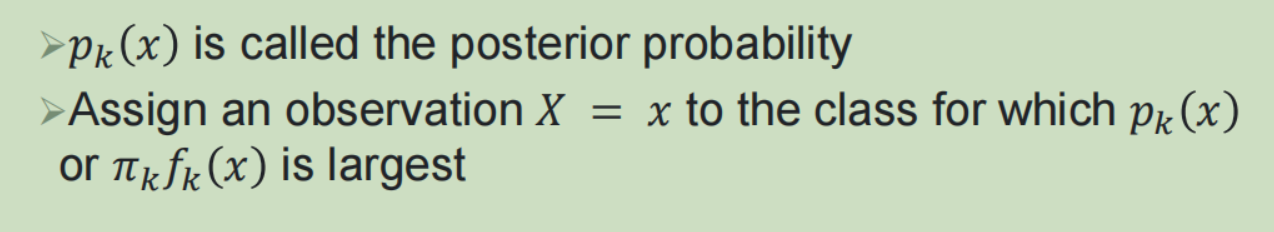
(2)线性判别分析:

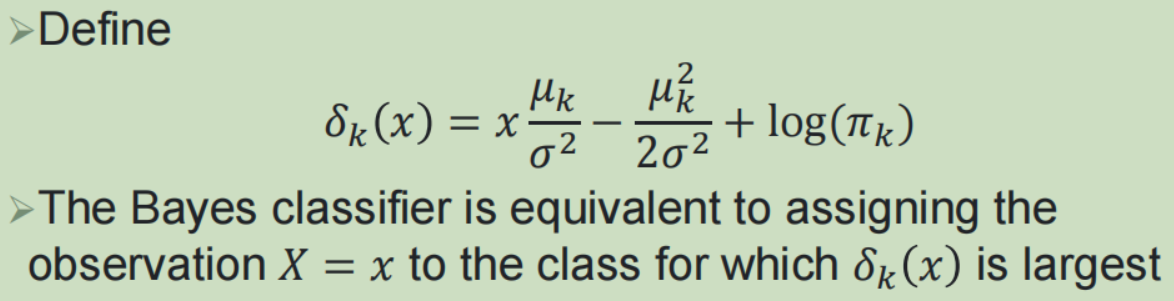

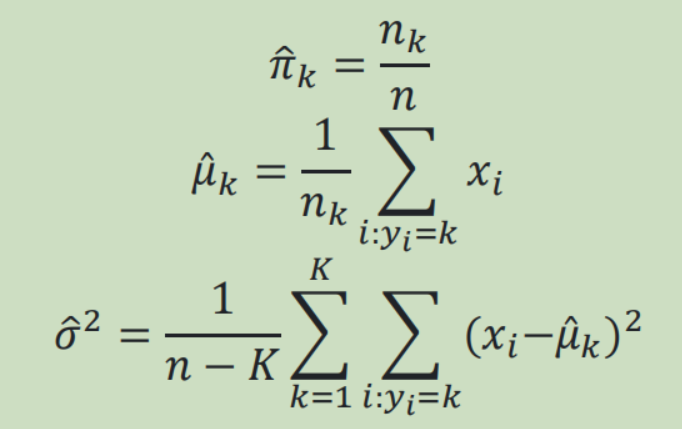
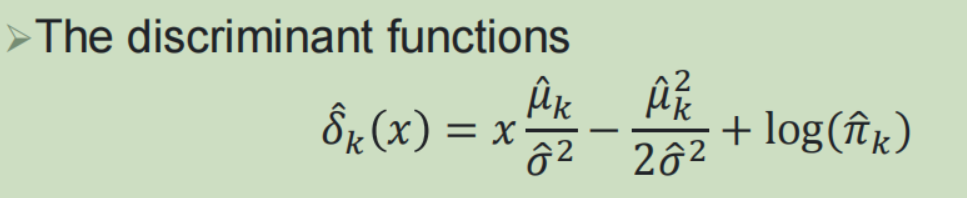


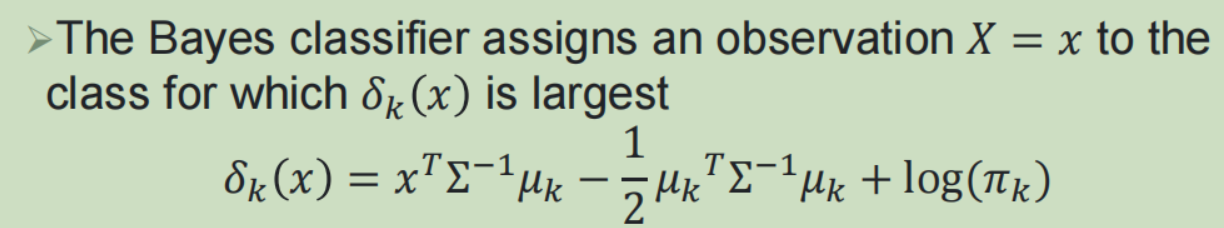
(3)敏感性与特异性:
(4)二次判别分析:
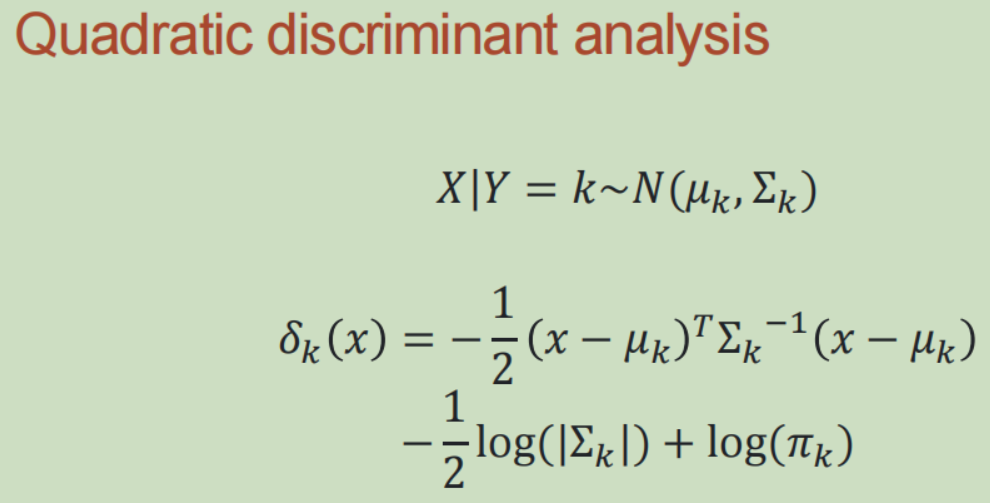
(5)朴素贝叶斯:
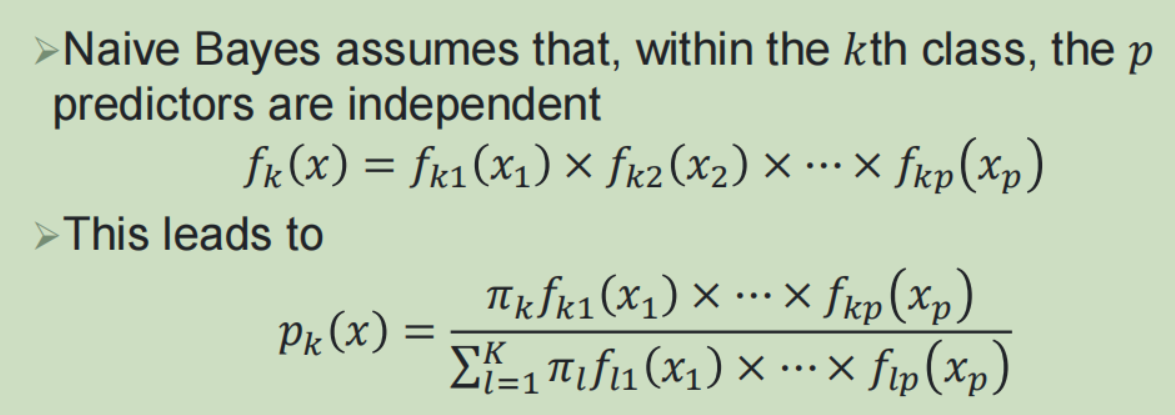

4,分类模型比较:

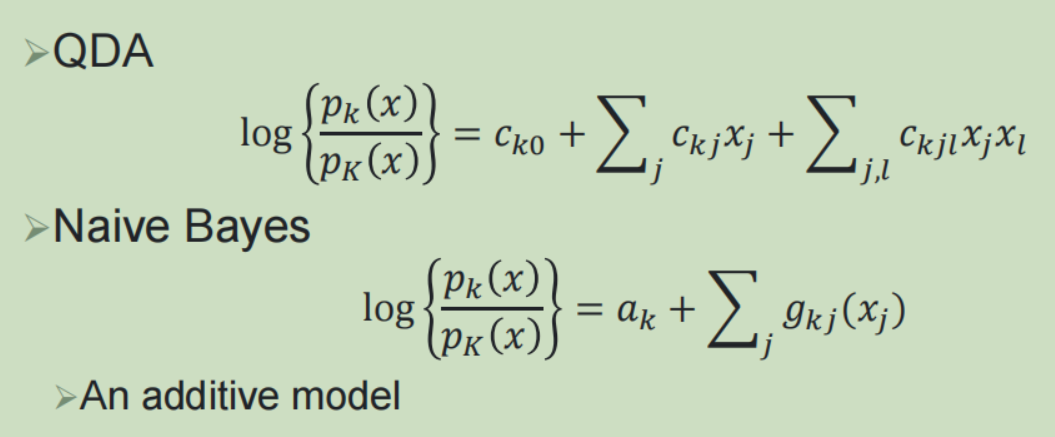
5,广义线性模型:
泊松回归:

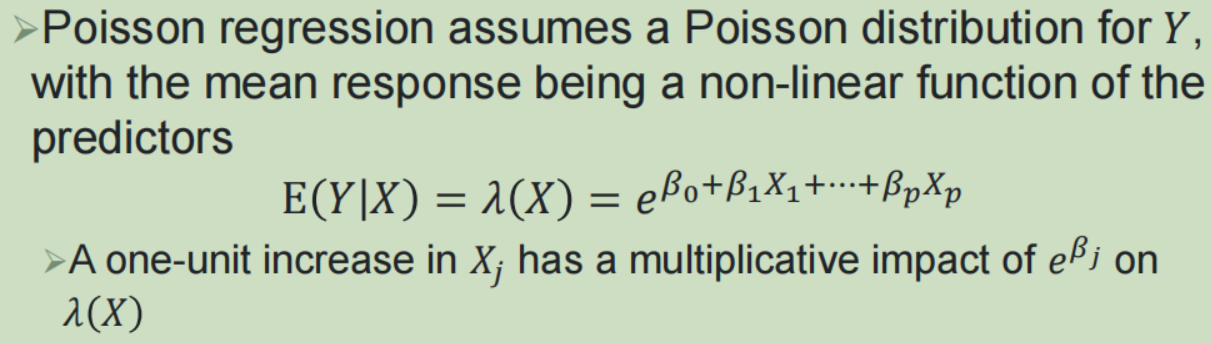
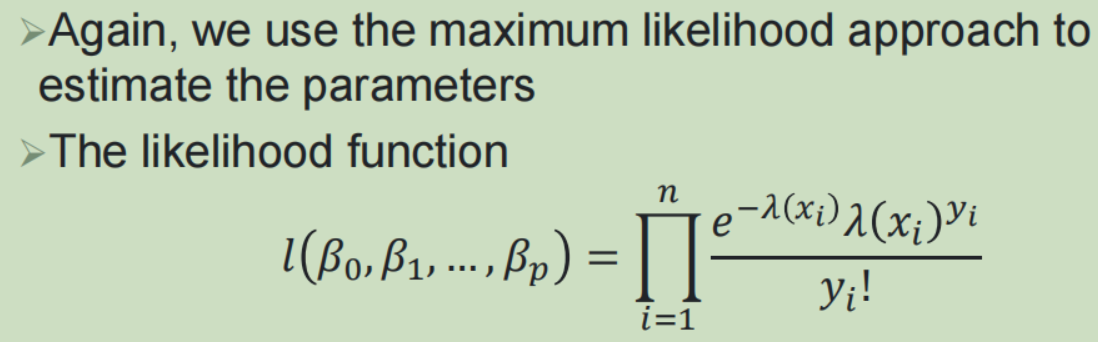
广义线性模型:



响应均值的函数,与预测变量之间的关系——》link函数
四,重采样方法:

1,交叉验证:
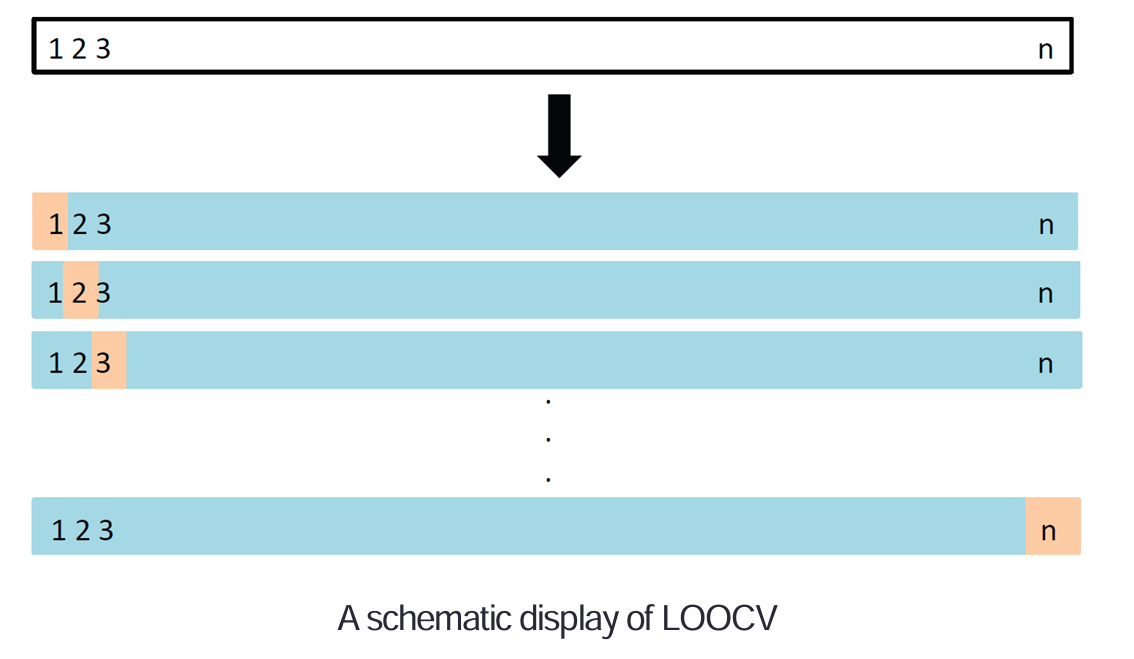
留一法交叉验证:


2,K折交叉验证:

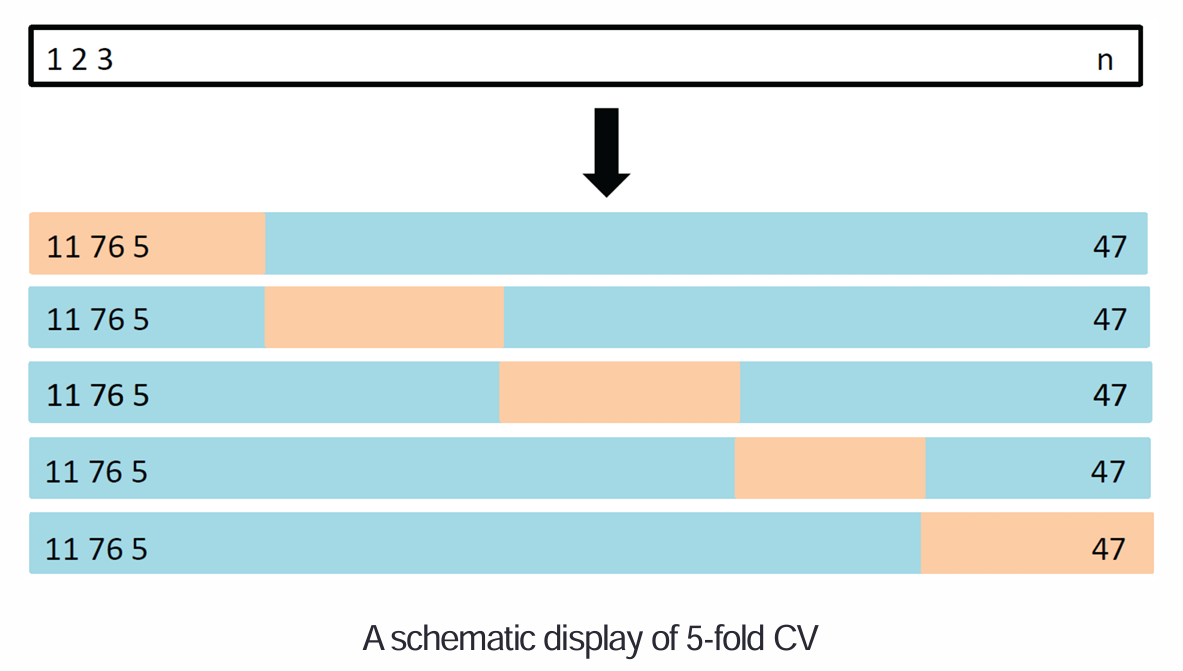


回归问题就是MSE,分类问题就是错分率
3,bootstrap自助抽样
从给定训练集中有放回的均匀抽样
一个例子:




五,线性模型选择与正则化:

特征筛选,特征系数缩减

1,特征数目p远大于样本数目n:

2,最优子集选择:
从p个特征中选k个特征,有多少种组合,可以构建多少种model:


偏差是看model与数据的拟合程度,方差是看model对数据的敏感程度;
如果是直接选择k个特征的话,可能性有2的p次方,计算效率低;
3,逐步选择:

所以选择使用逐步选择;
前向逐步选择:



后向逐步选择:


4,怎么样评估上述模型的测试集上的误差?

通过在训练集的RSS的矫正:

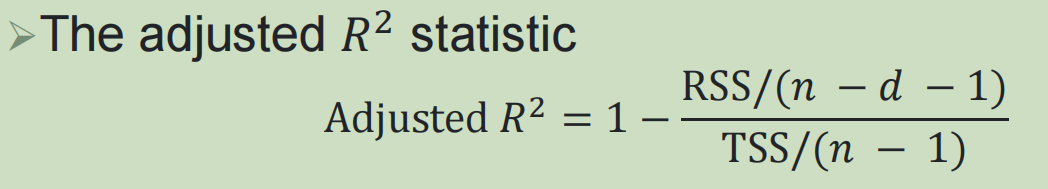
5,shrinkage方法:缩放方法
(1)岭回归:

(2)lasso:
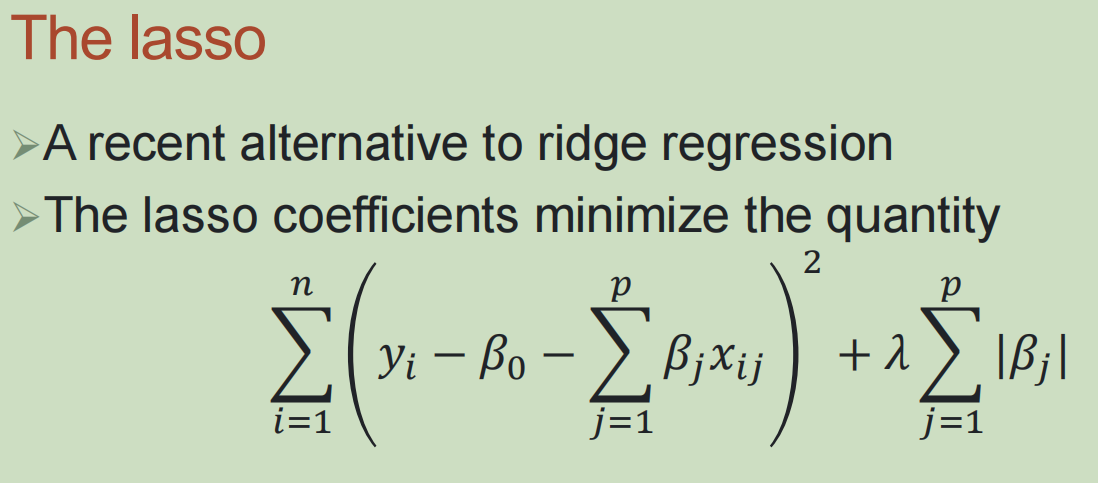

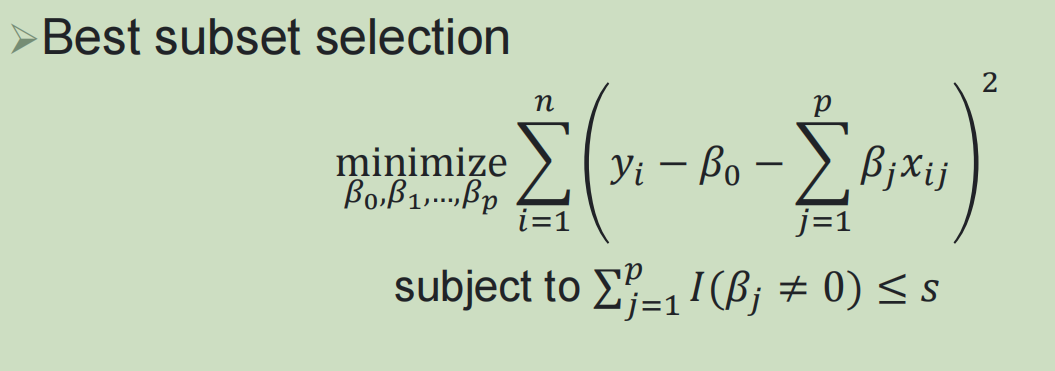
六,模型选择与正则化:

1,主成分回归:
目的和前面一样,都是为了减少feature特征的数目,从而优化模型,提高计算效率;

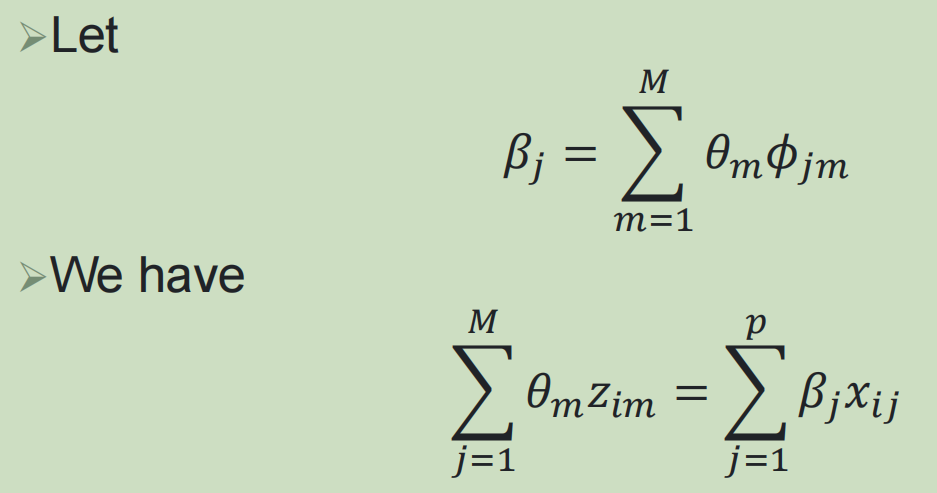
主成分本来就是一种降维方法,相当于是将原来的p个feature,通过线性组合,将数目减少到了m个特征;

通过碎石图,选择前M个feature,作为最终线性回归建模的feature
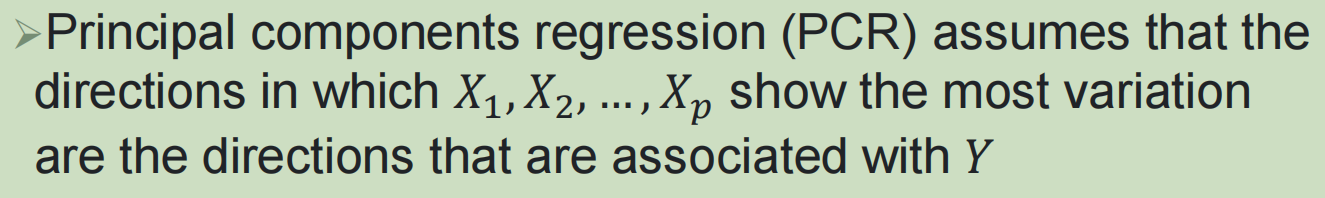
其实学过PCA的都知道,我们在做PCA的时候实际上是只用到了x的数据,我们找到的各种主成分实际上是表征预测变量也就是因变量方差最大的方向(坐标),所以实际上这种组合之后的特征与真正可以预测响应变量之间的特征是没有直接的关联推导的。
主成分回归假设预测变量显示最大变化的方向是与响应变量相关的方向

当然,构建model重要的一步在于feature筛选,也就是特征工程一部分,
但是PCR中的feature筛选其实没有一定的依据,所以严格意义上来说不能算作是特征筛选方法,但是选降到几维倒是可以通过CV;
2,偏最小二乘法:
一种监督式的降维方法,试图找到既能解释响应变量又能解释预测变量的方向
基本算法与原理:通过迭代过程计算PLS方向,使用最小二乘法拟合线性模型来预测响应变量



同样也不是一个有特征选择的方法;
3,高维问题:

特征feature的数量级和样本数据点n数量级之间的关系;

如果样本数据远远小于特征数目,可能会导致过拟合;(过拟合的话,实际上就是model太灵活了,也就是bias小而var方差大);
七,非线性方法1:

1,多项式回归:
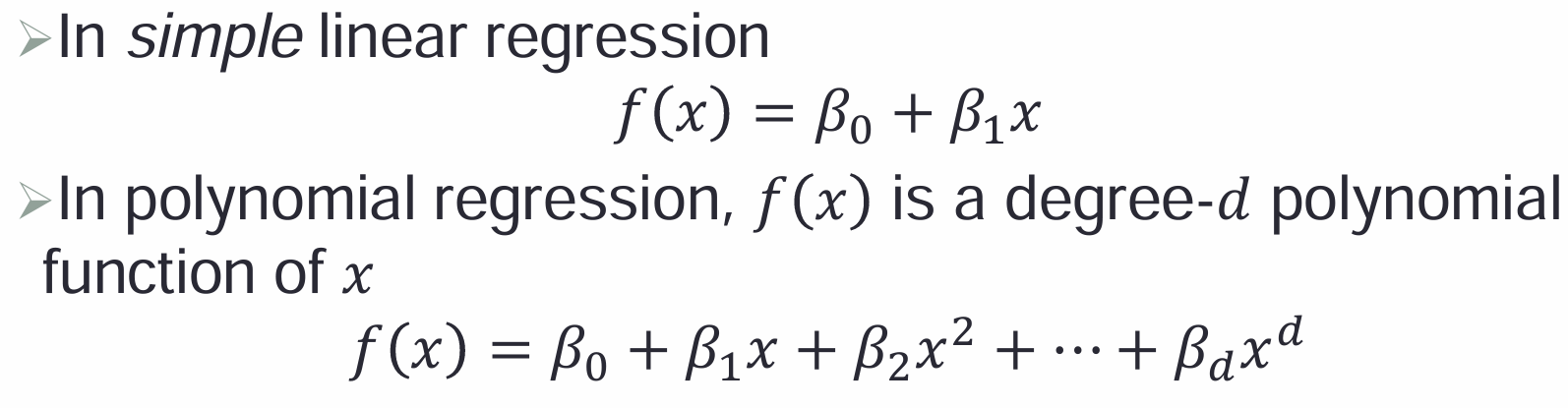
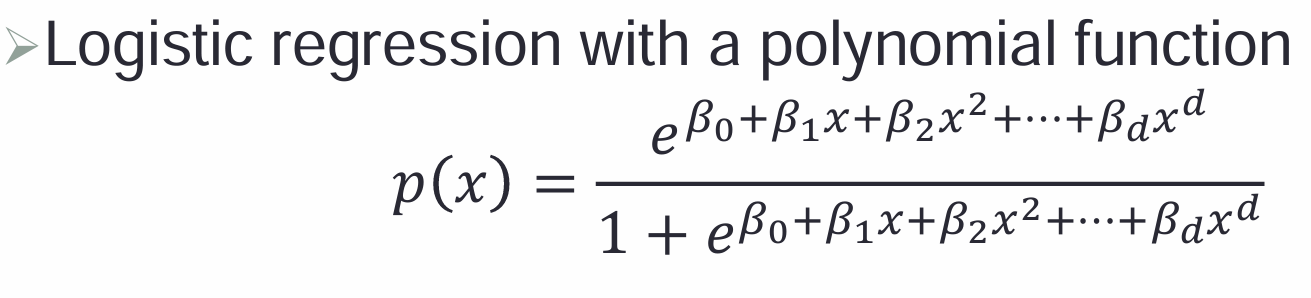
- 通过增加预测变量的高次项来扩展线性模型


2,step函数-阶梯函数:分段常数回归


3,基函数basis function
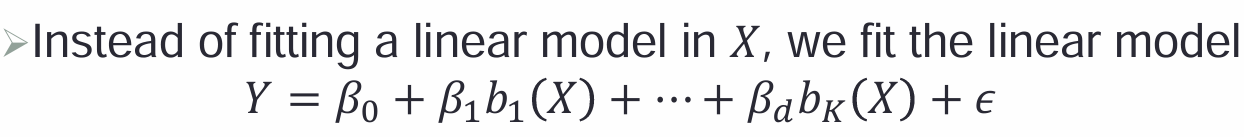
4,回归样条:
分段多项式回归
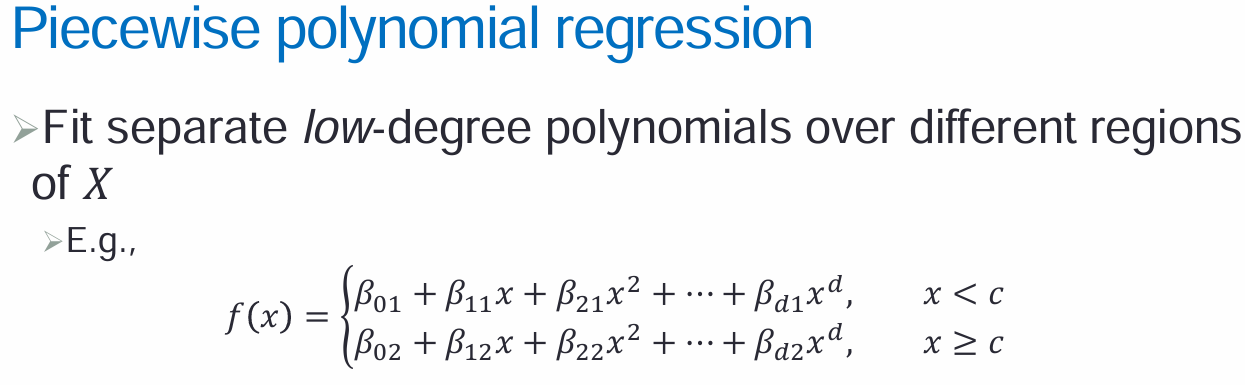


样条:d阶样条,即分段d阶多项式,在每个节点knot处d-1阶可导连续(比如说3次样条,3次多项式,1、2阶导连续)
5,用基函数来表征1个回归样条:
样条回归可以通过基函数展开表示,总参数数量:4 + K
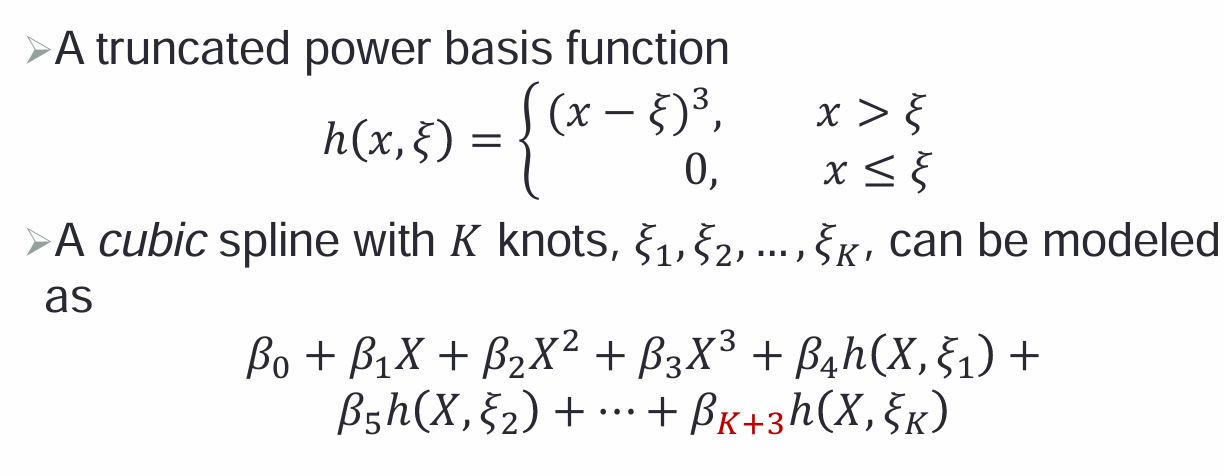 6,自然样条是具有额外边界约束的回归样条:它在边界处是线性的
6,自然样条是具有额外边界约束的回归样条:它在边界处是线性的
7,节点的数目和位置是超参、样条阶数:CV
八,非线性方法2:

1,光滑样条

平滑样条是一种非线性拟合方法,通过引入平滑参数 λ 来控制拟合的平滑程度。它在保持数据拟合度的同时,避免了过度拟合
2,局部回归

局部回归是一种基于局部数据的拟合方法,适用于数据分布不均匀的情况。它通过加权最小二乘法在局部区域内进行拟合,能够更好地捕捉数据的局部特征

3,广义可加模型:






4,模型比较:
| 方面 | 平滑样条 | 局部回归 | 广义可加模型 (GAMs) |
|---|---|---|---|
| 模型类型 | 非线性回归 | 非线性回归 | 非线性回归(扩展线性模型) |
| 拟合方式 | 全局优化,最小化残差平方和与平滑度的加权和 | 局部优化,基于目标点附近的加权最小二乘拟合 | 分解为多个单变量非线性函数的加性模型,逐个拟合每个变量 |
| 目标函数 | $ \sum_{i=1}^n (y_i - g(x_i))^2 + \lambda \int {g’'(t)}^2 dt $ | 加权最小二乘:$ \sum_{i=1}^n w_i (y_i - \hat{f}(x_i))^2 $ | $ Y = \beta_0 + f_1(X_1) + f_2(X_2) + \cdots + f_p(X_p) + \epsilon $ |
| 平滑参数选择 | 通过交叉验证(如LOOCV)选择 $ \lambda $ | 通过交叉验证选择跨度 $ s $ | 通过交叉验证选择每个非线性函数的平滑参数(如自由度) |
| 优点 | 灵活拟合非线性关系,通过 $ \lambda $ 控制复杂度 | 捕捉局部特征,适用于数据分布不均匀的情况 | 不需要手动变换变量,非线性拟合提高预测精度,可解释性强 |
| 缺点 | 计算复杂度高,对高维数据易受“维度的诅咒”影响 | 每次预测需要所有训练数据,计算效率低,对高维数据易受“维度的诅咒”影响 | 模型限制为加性,可能遗漏交互作用,对高维数据计算复杂度高 |
| 适用场景 | 数据量适中,需要全局平滑拟合 | 数据量适中,需要捕捉局部特征 | 多个预测变量,需要非线性拟合但保持模型可解释性 |
5,自然样条

九,决策树与树方法:
构建特征空间中的最终分类区域
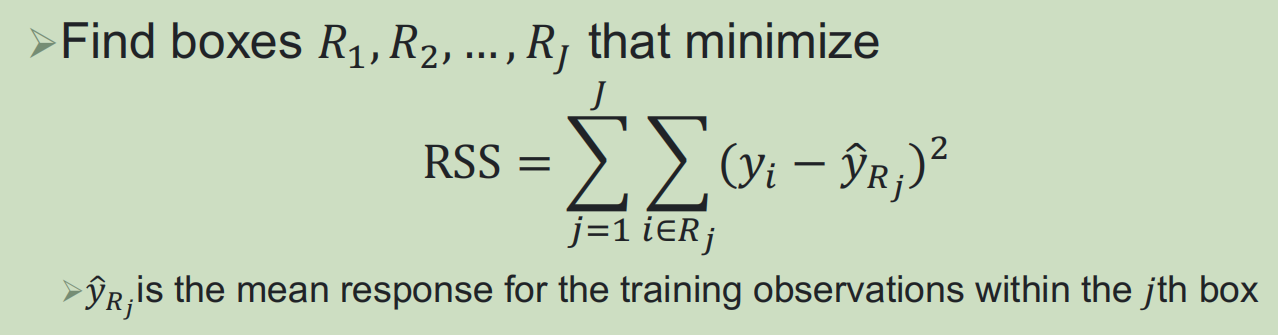
1,RBS递归二分

从树的根节点开始,不断对特征空间二分



2,代价复杂度剪枝:
经验损失函数+正则化项惩罚——》结构损失



3,构建回归树的方法:

4,分类树:
不能够使用RSS来分枝split,而是使用错分率,或者是Gini指数、或者是熵




所以1个是树的构建生成过程,1个是树的简化、剪枝过程;
树的构建过程split中使用的指标:

错分率=1-正确分类的比例(正确分类就是在第m个区域也就是第m个叶节点中出现频率最高的类别,然后这个比例可以被认为是正确分类的比例),所以1-正确的就是错误的;
总之符号上只有1个需要注意的,就是Pmk:指的就是在第m个区域也就是第m个叶节点中类别k的比例

这个值越低,表明第m个区域也就是第m个叶节点中某个类别占主导(这是我们分类想要的结果)

至于熵,可以联系低复杂度区域中的氨基酸组成的分析,如果低复杂度,表明类别组成越单一(这是我们分类想要的结果)

5,不同叶节点分类的值相同:


6,回归树与线性回归:



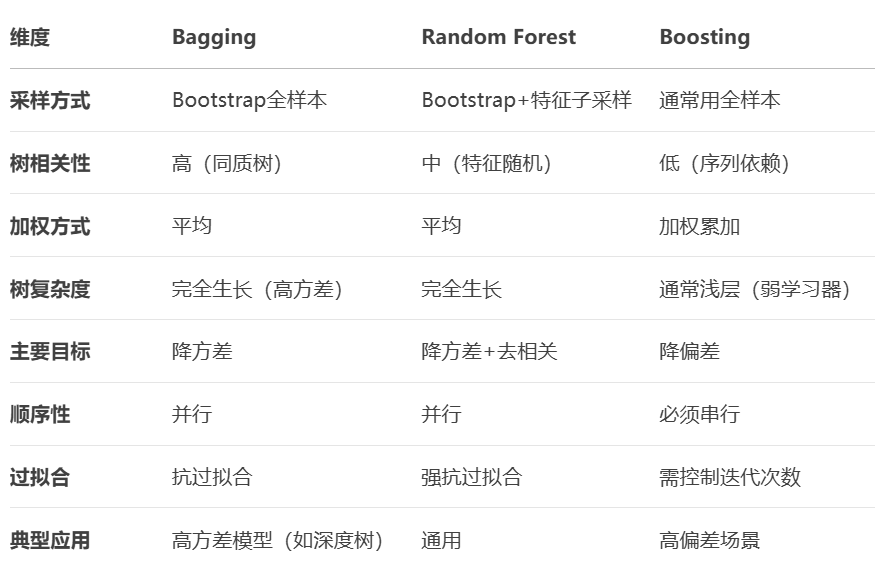
十,提升方法(基于树的集成学习)
1,bagging+boosting:

adaBoost:降低那些普通人给出意见(错分率高的弱分类器)的权重
Boosting:三个臭皮匠顶个诸葛亮
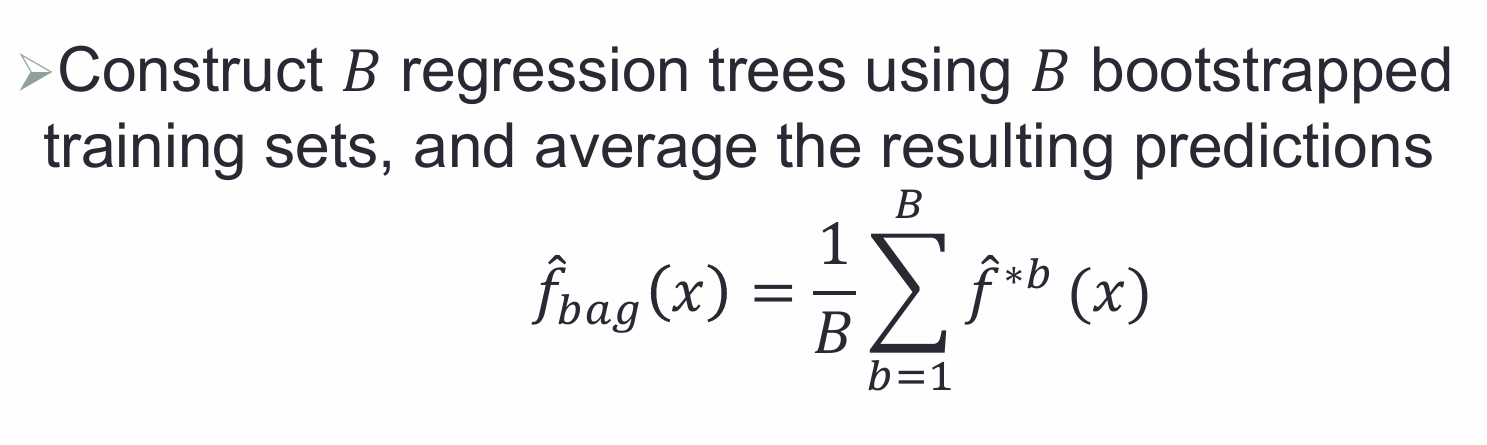
bagging( Bootstrap aggregation ):
进行多次bootstrap重采样,每次重采样的数据,构建1棵回归树,最后对这些回归树进行线性组合(加法模型)
——》如果是回归树的组合:对预测的响应变量做一个均值
——》如果是分类树的组合:多数投票,取投票频数最多的类别class
2,OOB:集成学习中的袋外误差评估



所以本质上:袋外误差其实就是验证集,源自于bootstrap有放回重采样导致每棵决策树都有一定比例原始样本(1/3左右)不会被选中,可以作为验证集
——》所以OOB,其实就是bootstrap中没抽到的一定比例的样本作为验证集的做法


就是作为测试集

这句话的意思其实很简单:
既然OOB的样本要作为验证集,那model当初训练的时候训练集上肯定不包含这个OOB样本,
就是验证要用对于当前model是OOB数据的样本来做验证集
——》验证集上每棵树都要计算验证的指标
回归计算MSE(残差/RSS)
分类计算错分率
3,装袋法bagging中的feature特征重要性评估:选重要的特征


装袋法中变量重要性的计算方法详解
核心概念解释
这段话描述的是在装袋法(Bagging)中如何计算**变量重要性(Variable Importance)**的两种方法:
- 回归树:基于残差平方和(RSS)的减少量
- 分类树:基于基尼指数(Gini Index)的减少量
这两种方法都是通过统计所有B棵树中,每个预测变量在分裂时带来的"纯度提升"总和,然后取平均得到的。
回归树中的RSS减少量计算
计算步骤:
- 对于每棵树:
- 记录每个分裂点使用的预测变量
- 计算该分裂导致的RSS减少量
- 对所有B棵树:
- 累加每个预测变量带来的RSS减少总量
- 取平均值得到最终重要性评分
实例说明:
假设我们预测房屋价格,有3个特征:[面积, 房龄, 学区]
树1的分裂过程:
- 第一次分裂:按"面积>100㎡"分裂
- 分裂前RSS = 1000
- 分裂后左节点RSS = 400,右节点RSS = 300
- RSS减少量 = 1000 - (400+300) = 300 → 记给"面积"
- 第二次分裂:右节点按"房龄>10年"分裂
- 分裂前RSS = 300
- 分裂后左RSS = 100,右RSS = 150
- RSS减少量 = 300 - (100+150) = 50 → 记给"房龄"
最终计算:
假设在100棵树中:
- "面积"总RSS减少=8000 → 平均重要性=80
- "房龄"总RSS减少=3000 → 平均重要性=30
- "学区"总RSS减少=1000 → 平均重要性=10
分类树中的基尼指数减少量计算
基尼指数公式:
Gini = 1 - Σ(p_i)²
其中p_i是第i类在节点中的比例
计算步骤:
- 对于每棵树:
- 记录每个分裂使用的预测变量
- 计算分裂前后的基尼指数差
- 对所有B棵树:
- 累加每个预测变量带来的基尼指数减少总量
- 取平均值得到最终重要性评分
实例说明:
假设我们预测客户是否购买[是/否],有3个特征:[年龄, 收入, 性别]
树1的分裂过程:
- 根节点(10个样本:6个"是",4个"否")
- 基尼 = 1 - (0.6² + 0.4²) = 0.48
- 按"收入>50k"分裂:
- 左节点(收入>50k):8样本(5是,3否) → 基尼=0.469
- 右节点:2样本(1是,1否) → 基尼=0.5
- 加权基尼 = (8/10)*0.469 + (2/10)*0.5 = 0.475
- 基尼减少量 = 0.48 - 0.475 = 0.005 → 记给"收入"
- 左节点再按"年龄>30岁"分裂:
- 分裂前基尼=0.469
- 分裂后左左节点:5样本(3是,2否) → 基尼=0.48
- 左右节点:3样本(2是,1否) → 基尼=0.444
- 加权基尼 = (5/8)*0.48 + (3/8)*0.444 = 0.466
- 基尼减少量 = 0.469 - 0.466 = 0.003 → 记给"年龄"
最终计算:
假设在100棵树中:
- "收入"总基尼减少=2.5 → 平均重要性=0.025
- "年龄"总基尼减少=1.8 → 平均重要性=0.018
- "性别"总基尼减少=0.7 → 平均重要性=0.007
关键理解要点
- 累积性:重要性是对所有树中该变量带来的"纯度提升"的总和
- 相对性:数值本身大小不重要,重要的是各变量间的相对大小
- 标准化:通常会将结果标准化,使最大重要性为100
实际应用意义
- 特征选择:可以识别最重要的预测变量
- 模型解释:理解模型依赖的主要因素
- 诊断工具:发现潜在的数据问题(如某个变量重要性异常高可能预示数据泄漏)
与单棵树的区别
单决策树中我们只能看到有限的几次分裂,而装袋法通过聚合多棵树的结果:
- 更全面地评估变量重要性
- 减少因单棵树随机性带来的偏差
- 能发现变量间的交互作用
这种基于多棵树聚合的重要性评估方法,比单棵树的结果更加稳健可靠。
4,随机森林RF:
随机森林就是以bagging为特色的一种典型的集成学习方法
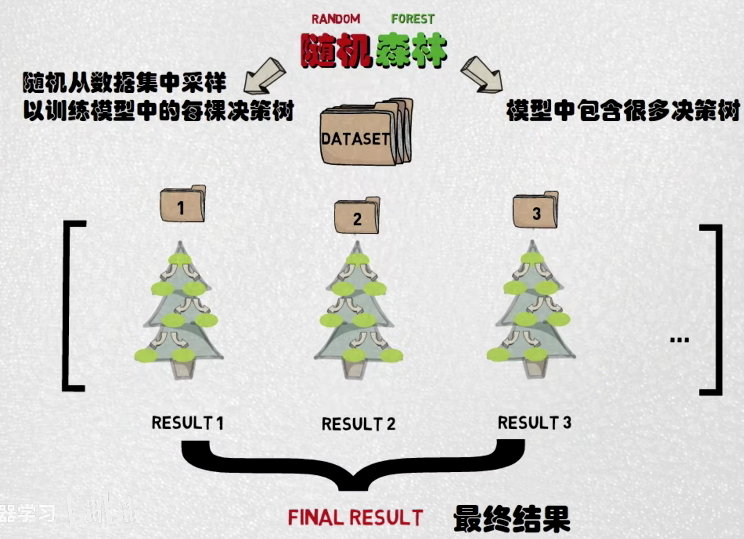
我们来拆字:
森林:意味着这是一个集成学习模型,里面有很多弱监督模块(弱学习器),也就是有很多决策树
随机:指的是每一棵决策树的训练都是随机采样样本进行训练的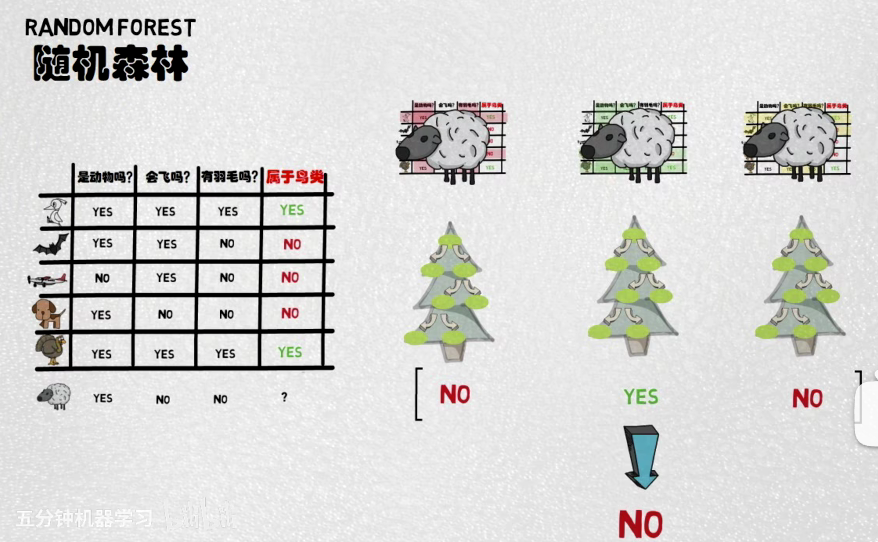
看问题的角度不一样
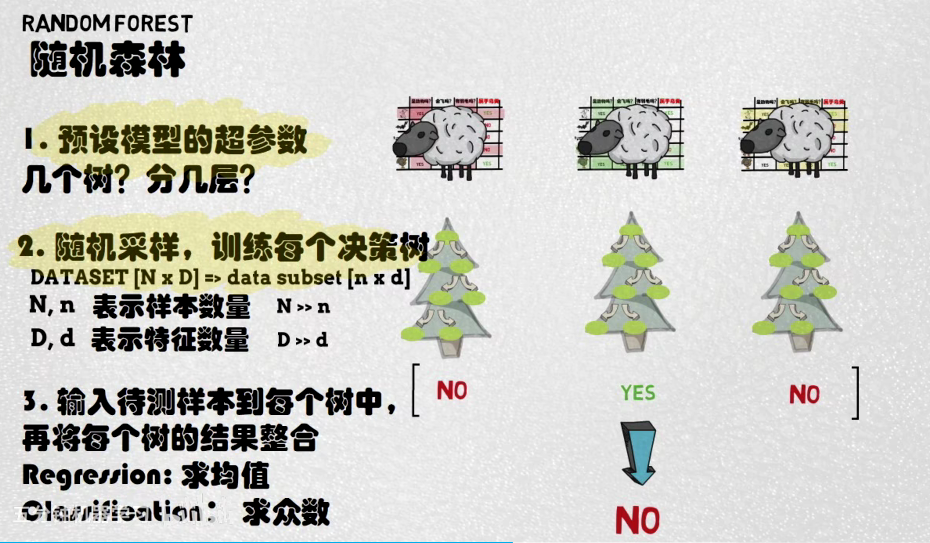

相比bagging:训练多棵树,样本随机(但feature一致),算法一致
随机森林:训练多棵树,样本随机、特征也随机,算法一致
m是选取的特征数,p是所有的特征数

所以说是随机取不同的样本,但重点在于关注的特征不同(类似于CNN中的不同感受野,关注不同像素区域的特征)
5,boosting:
[初始残差=y] → [拟合残差] → [更新模型] → [新残差]
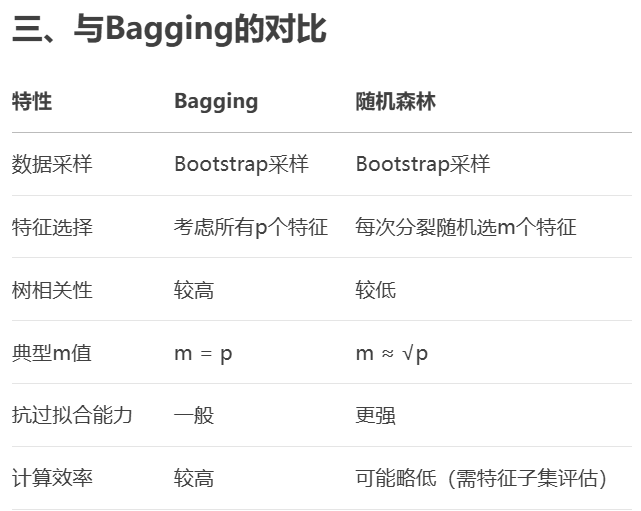
6,基于树的集成学习方法比较:

bagging vs random forests vs boosting




十一,支持向量机
1,分离超平面:


2,最优分离超平面:最大间隔超平面
间隔最大化:
支持向量到分离平面的距离为间隔,离得最近的点要分得开(离得最近的点要有足够的确信度分开,也就是离分离超平面的距离要在所有的感知机分离超平面中最大)

3,支持向量
4,目标函数:
最小函数间隔,最大化
函数间隔与几何间隔:函数间隔和几何间隔,在于分母上超平面法向量的L2范数,如果调整为1(也就是系数β),即无差别;
线性可分支持向量机:硬间隔分类器
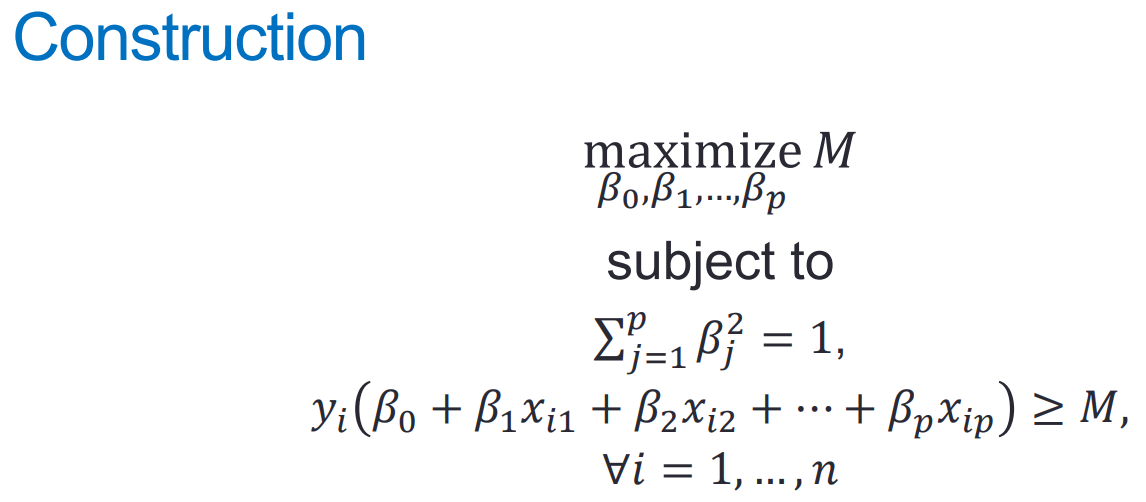

线性支持向量机:软间隔分类器





其中M是间隔宽度(单侧),松弛变量用于分类情况的判断:分类正确,在分离超平面与边界间隔之间,在分离超平面另外一侧;
至于C,可以联系函数距离的意义(因为松弛向量本质上也是函数距离,确信度与分类正确与否),其实就是对应松弛向量的数目,本质上是一个正则化惩罚项
——》边界间隔(marginS)上+内的点现在都是支持向量


线性支持向量机学习等价于最小化二阶范数正则化的合页函数
5,非线性支持向量机:


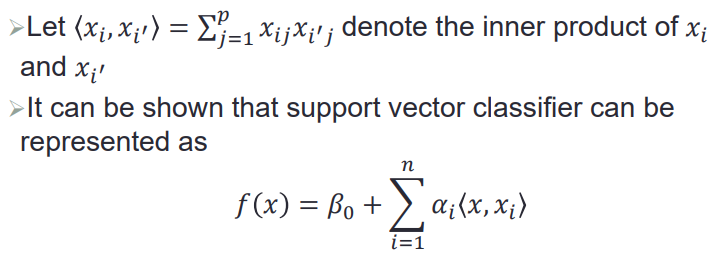

 构建SVM过程仅涉及到观测数据之间的内积
构建SVM过程仅涉及到观测数据之间的内积

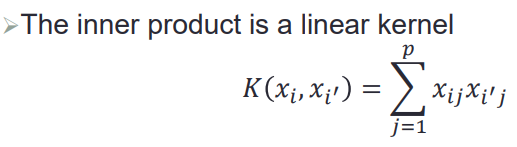

核函数:对内积形式的推广
——》因为目标函数(要优化的loss,其实就在对偶问题中)以及分类决策函数中实际上都涉及到输入空间中样本点示例与示例的内积点乘,
本来我们学习1个SVM,首先是要将数据样本从输入空间映射到特征空间中,再在特征空间中对映射之后的内积形式的loss,学习一个分类器;
问题是要映射到怎么样的高维特征空间是一个比较困难的问题,我们在这里不显式定义映射函数,而是直接定义映射在高维空间中的内积,这样就省去了在映射+计算内积两步
6,函数间隔与几何间隔

线性可分支持向量机利用间隔最大化求最优分离超平面,这时,解是唯一的。

 几何间隔就是在函数间隔的基础上除以L2范数(法向量模长),几何间隔是最符合高中解析几何中点到直线的距离的,yi只是个label(改变符号而已);
几何间隔就是在函数间隔的基础上除以L2范数(法向量模长),几何间隔是最符合高中解析几何中点到直线的距离的,yi只是个label(改变符号而已);
样本点的间隔和数据集的间隔(所有样本点中的min的那个)



