SDXL 和 SDXL-Turbo 的区别
(1) SDXL(Stable Diffusion XL)
-
标准扩散模型,基于传统的多步去噪(通常 20~50 步)。
-
训练充分,特征更稳定,适合用于特征提取、方向学习(如 LoRA、SAE)。
-
计算成本高,推理速度较慢。
(2) SDXL-Turbo
-
基于蒸馏(Adversarial Diffusion Distillation, ADD)的快速模型,只需 1~4 步就能生成高质量图像。
-
推理速度极快(接近实时),但特征空间可能不如 SDXL 稳定。
-
更适合实际应用部署,如实时生成、交互式编辑。
2. 为什么训练用 SDXL,推理用 SDXL-Turbo?
(1) 训练阶段需要稳定的特征
-
SDXL 的多步去噪过程能提供更平滑的 latent space,适合训练 SAE(Sparse Autoencoder)、LoRA 等适配器。
-
SDXL-Turbo 的蒸馏过程导致 latent 分布可能更“压缩”,直接训练可能不稳定。
(2) 推理阶段需要速度
-
SDXL-Turbo 的 1~4 步推理比 SDXL 快 10~50 倍,适合实际应用。
-
只要训练的特征方向(Δe)在 SDXL-Turbo 的 latent space 仍然有效,就可以直接迁移使用。
(3) 论文中的例子
在论文的 Real Image Editing(Fig. 8)部分:
-
训练 Δe(属性方向)用的是 SDXL(因为需要稳定的特征学习)。
-
推理(编辑真实图像)用的是 SDXL-Turbo + ReNoise(因为需要快速生成)。
3. SDXL 和 SDXL-Turbo 的兼容性
(1) 共享相同的 CLIP 文本编码器
-
两者都使用 OpenAI CLIP-ViT/L + OpenCLIP-ViT/bigG,所以文本嵌入(text embeddings)是兼容的。
-
论文的方法(修改 token embedding)在这两个模型上都能直接使用。
(2) U-Net 的潜在空间相似
-
SDXL-Turbo 是 SDXL 的蒸馏版本,latent space 结构基本一致,只是优化了推理路径。
-
学习到的 Δe(如“年龄方向”)在两者之间可以迁移,但可能需要调整强度(λ)。
(3) 可能的调整
-
由于 SDXL-Turbo 的 latent 更“紧凑”,相同的 Δe 可能需要较小的 λ(比如 SDXL 用 λ=2,SDXL-Turbo 用 λ=1)。
-
如果直接迁移效果不好,可以在 SDXL-Turbo 上微调 Δe(但论文发现零样本迁移通常足够)。
4. 为什么不全用 SDXL-Turbo?
-
训练阶段:SDXL-Turbo 的 latent 动态范围较小,训练 SAE/LoRA 可能不如 SDXL 稳定。
-
特征学习:SDXL 的多步去噪能更好地捕捉语义方向,而 SDXL-Turbo 的快速推理可能丢失一些细节。
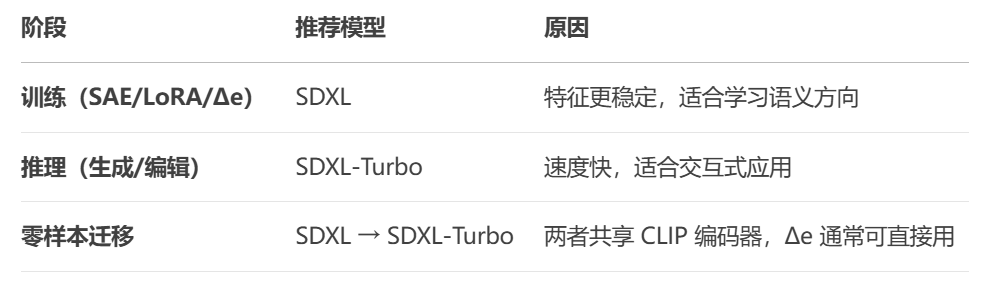
结论:
-
混用是合理的,因为 SDXL 适合训练,SDXL-Turbo 适合推理。
-
只要文本编码器一致,学习到的 Δe 可以跨模型使用,但可能需要调整 λ。
-
如果追求最佳效果,可以在目标模型(如 SDXL-Turbo)上微调 Δe,但论文表明零样本迁移通常足够。