【大模型开发应用】提示工程
零、大语言模型发展
1、大语言模型发展

2、大语言模型常见设置参数
(1)Temperature
简单来说,temperature 的参数值越小,模型就会返回越确定的一个结果。如果调高该参数值,大语言模型可能会返回更随机的结果,也就是说这可能会带来更多样化或更具创造性的产出。(调小temperature)实质上,你是在增加其他可能的 token 的权重。在实际应用方面,对于质量保障(QA)等任务,我们可以设置更低的 temperature 值,以促使模型基于事实返回更真实和简洁的结果。 对于诗歌生成或其他创造性任务,适度地调高 temperature 参数值可能会更好。
(2)Top_p
使用 top_p(与 temperature 一起称为核采样(nucleus sampling)的技术),可以用来控制模型返回结果的确定性。如果你需要准确和事实的答案,就把参数值调低。如果你在寻找更多样化的响应,可以将其值调高点。
使用Top P意味着只有词元集合(tokens)中包含top_p概率质量的才会被考虑用于响应,因此较低的top_p值会选择最有信心的响应。这意味着较高的top_p值将使模型考虑更多可能的词语,包括不太可能的词语,从而导致更多样化的输出。
一般建议是改变 Temperature 和 Top P 其中一个参数就行,不用两个都调整。
(3)Max Length
可以通过调整 max length 来控制大模型生成的 token 数。指定 Max Length 有助于防止大模型生成冗长或不相关的响应并控制成本。
(4)Stop Sequences
stop sequence 是一个字符串,可以阻止模型生成 token,指定 stop sequences 是控制大模型响应长度和结构的另一种方法。例如,您可以通过添加 “11” 作为 stop sequence 来告诉模型生成不超过 10 个项的列表。
(5)Frequency Penalty
frequency penalty 是对下一个生成的 token 进行惩罚,这个惩罚和 token 在响应和提示中已出现的次数成比例, frequency penalty 越高,某个词再次出现的可能性就越小,这个设置通过给 重复数量多的 Token 设置更高的惩罚来减少响应中单词的重复。
(6)Presence Penalty
presence penalty 也是对重复的 token 施加惩罚,但与 frequency penalty 不同的是,惩罚对于所有重复 token 都是相同的。出现两次的 token 和出现 10 次的 token 会受到相同的惩罚。 此设置可防止模型在响应中过于频繁地生成重复的词。 如果您希望模型生成多样化或创造性的文本,您可以设置更高的 presence penalty,如果您希望模型生成更专注的内容,您可以设置更低的 presence penalty。
与 temperature 和 top_p 一样,一般建议是改变 frequency penalty 和 presence penalty 其中一个参数就行,不要同时调整两个。
一、提示工程
1、定义
提示工程是指一种通过设计和调整输入来改善大语言模型性能或控制器其输出结果的技术。
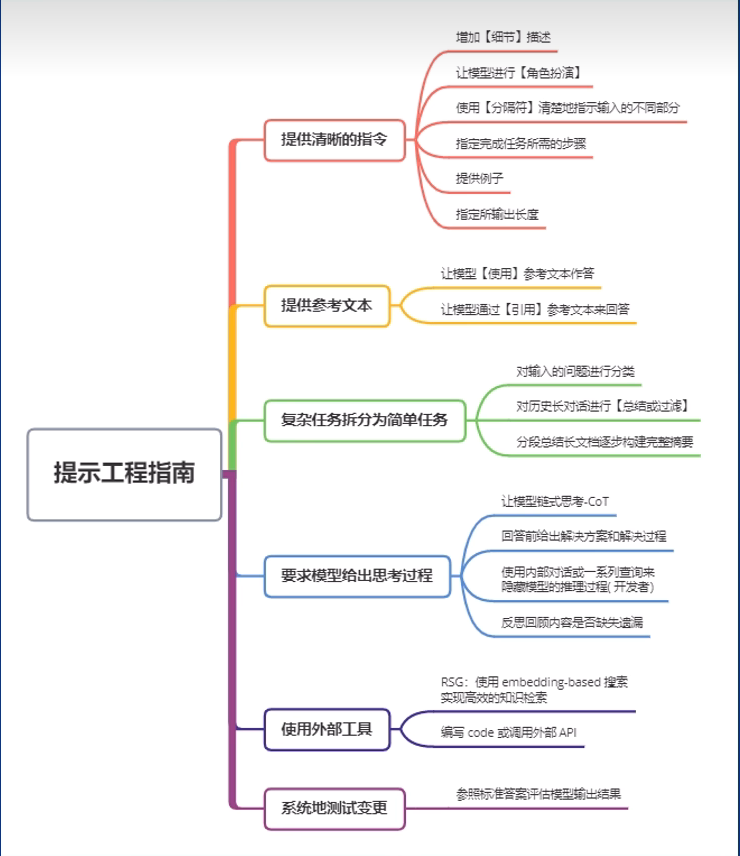
2、提示设计六大原则
二、提示技巧
1、零样本提示
没有向模型提供任何实例
#提示:
将文本分类为中性、负面或正面。
文本:我认为这次假期还可以。
情感:#输出:
中性
2、少样本提示
向模型提供少数实例
#提示:
这太棒了!// Negative
这太糟糕了!// Positive
哇,那部电影太棒了!// Positive
多么可怕的节目!//#输出:
Negative
3、链式思考(CoT)提示
链式思考(CoT)提示通过中间推理步骤实现了复杂的推理能力,链式思考(CoT)提示可以和零样本提示或少样本提示进行结合,以获得更好的结果
#零样本+链式思考提示:
我去市场买了10个苹果。我给了邻居2个苹果和修理工2个苹果。然后我去买了5个苹果并吃了1个。我还剩下多少苹果?让我们逐步思考。#输出:
首先,您从10个苹果开始。
您给了邻居和修理工各2个苹果,所以您还剩下6个苹果。
然后您买了5个苹果,所以现在您有11个苹果。
最后,您吃了1个苹果,所以您还剩下10个苹果。
#少样本+链式思考提示:
这组数中的奇数加起来是偶数:4、8、9、15、12、2、1。
A:将所有奇数相加(9、15、1)得到25。答案为False。
这组数中的奇数加起来是偶数:15、32、5、13、82、7、1。
A:#输出:
将所有奇数相加(15、5、13、7、1)得到41。答案为False。
4、自动思维链(Auto-CoT)
自动思维链(Auto-CoT)是基于链式思维进行改进,先将问题聚类,每一类中抽出一个具有代表性的问题,利用零样本思维链为每个问题生成推理链。自动思维链(Auto-CoT)的优势在于,不需要手工分解解题步骤,不需要编写思维链提示词。这是一个很大的进步。但是,这种技术的也有一个明显的局限:需要对问题集划分成几个聚类,对每个聚类都要生成一组思维链提示词,并且这些提示词还要一并输入到大模型里。聚类太少,思维链的多样性不够;聚类太多,提示词太长,效率太低。
论文地址:https://arxiv.org/pdf/2210.03493
项目地址:https://github.com/amazon-science/auto-cot
5、自我一致性
自我一致性旨在“替换链式思维提示中使用的天真贪婪解码方法”。其想法是通过少样本 CoT 采样多个不同的推理路径,并使用生成结果选择最一致的答案。这有助于提高 CoT 提示在涉及算术和常识推理的任务中的性能。
#提示:
Q:林中有15棵树。林业工人今天将在林中种树。完成后,将有21棵树。林业工人今天种了多少棵树?
A:我们从15棵树开始。后来我们有21棵树。差异必须是他们种树的数量。因此,他们必须种了21-15 = 6棵树。答案是6。
Q:停车场有3辆汽车,又来了2辆汽车,停车场有多少辆汽车?
A:停车场已经有3辆汽车。又来了2辆。现在有3 + 2 = 5辆汽车。答案是5。
Q:Leah有32块巧克力,她的姐姐有42块。如果他们吃了35块,他们总共还剩多少块?
A:Leah有32块巧克力,Leah的姐姐有42块。这意味着最初有32 + 42 = 74块巧克力。已经吃了35块。因此,他们总共还剩74-35 = 39块巧克力。答案是39。
Q:Jason有20个棒棒糖。他给Denny一些棒棒糖。现在Jason只有12个棒棒糖。Jason给Denny多少棒棒糖?
A:Jason有20个棒棒糖。因为他现在只有12个,所以他必须把剩下的给Denny。他给Denny的棒棒糖数量必须是20-12 = 8个棒棒糖。答案是8。
Q:Shawn有五个玩具。圣诞节,他从他的父母那里得到了两个玩具。他现在有多少个玩具?
A:他有5个玩具。他从妈妈那里得到了2个,所以在那之后他有5 + 2 = 7个玩具。然后他从爸爸那里得到了2个,所以总共他有7 + 2 = 9个玩具。答案是9。
Q:服务器房间里有9台计算机。从周一到周四,每天都会安装5台计算机。现在服务器房间里有多少台计算机?
A:从周一到周四有4天。每天都添加了5台计算机。这意味着总共添加了4 * 5 =
20台计算机。一开始有9台计算机,所以现在有9 + 20 = 29台计算机。答案是29。
Q:Michael有58个高尔夫球。星期二,他丢失了23个高尔夫球。星期三,他又丢失了2个。星期三结束时他还剩多少个高尔夫球?
A:Michael最初有58个球。星期二他丢失了23个,所以在那之后他有58-23 = 35个球。星期三他又丢失了2个,所以现在他有35-2 = 33个球。答案是33。
Q:Olivia有23美元。她用每个3美元的价格买了五个百吉饼。她还剩多少钱?
A:她用每个3美元的价格买了5个百吉饼。这意味着她花了15美元。她还剩8美元。
Q:当我6岁时,我的妹妹是我的一半年龄。现在我70岁了,我的妹妹多大?
A:#输出:
当我6岁时,我的妹妹是我的一半年龄,也就是3岁。现在我70岁了,所以她是70-3 = 67岁。答案是67。
6、融合知识提示
#提示:
问题:高尔夫球的一部分是试图获得比其他人更高的得分。是或否?
知识:高尔夫球的目标是以最少的杆数打完一组洞。一轮高尔夫球比赛通常包括18个洞。每个洞在标准高尔夫球场上一轮只打一次。每个杆计为一分,总杆数用于确定比赛的获胜者。
解释和答案:#输出:
不是,高尔夫球的目标不是获得比其他人更高的得分。相反,目标是以最少的杆数打完一组洞。总杆数用于确定比赛的获胜者,而不是总得分。
7、思维树(ToT)
ToT 维护着一棵思维树,思维由连贯的语言序列表示,这个序列就是解决问题的中间步骤。结构如下图所示:
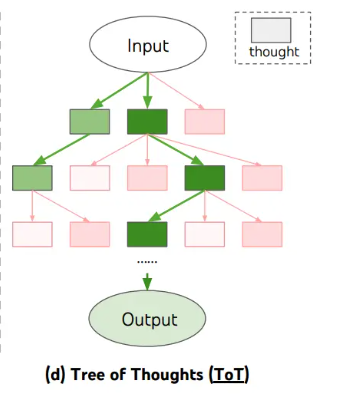
#提示:
假设三位不同的专家来回答这个问题。
所有专家都写下他们思考这个问题的第一个步骤,然后与大家分享。
然后,所有专家都写下他们思考的下一个步骤并分享。
以此类推,直到所有专家写完他们思考的所有步骤。
只要大家发现有专家的步骤出错了,就让这位专家离开。
请问...
8、检索增强生成(RAG)
RAG 会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样 RAG 更加适应事实会随时间变化的情况。这非常有用,因为 LLM 的参数化知识是静态的。RAG 让语言模型不用重新训练就能够获取最新的信息,基于检索生成产生可靠的输出。
9、ReAct 框架
ReAct 提示 LLMs 为任务生成口头推理轨迹和操作。这使得系统执行动态推理来创建、维护和调整操作计划,同时还支持与外部环境(例如,Wikipedia)的交互,以将额外信息合并到推理中。
#提示:
问题 科罗拉多造山带东部区域延伸到的区域的海拔范围是多少?
思考 1 我需要搜索科罗拉多造山带,找到科罗拉多造山带东段延伸的区域,然后找到该区域的海拔范围。
操作 1 搜索 [科罗拉多造山带]
观察 1 科罗拉多造山带是科罗拉多及其周边地区造山运动的一段。
思考 2 它没有提到东部地区。所以我需要查一下东部地区。
操作 2 查找 [东部地区]
观察 2 (结果 1 / 1) 东部区域延伸至高平原,称为中原造山带。
思考 3 科罗拉多造山运动的东部区域延伸到高平原。所以我需要搜索高平原,找到它的海拔范围。
操作 3 搜索 [高平原]
观察 3 高平原指的是两个截然不同的陆地区域之一。
思考 4 我需要搜索高平原(美国)
操作 4 搜索 [高平原(美国)]
观察 4 高平原是大平原的一个分区。从东到西,高平原的海拔从 1800 到 7000 英尺 (550 到 2130 米) 不等。[3]
思考 5 高平原海拔高度从 1800 到 7000 英尺,所以答案是 1800 到 7000 英尺。
操作 5 结束 [1800 到 7000 英尺]
...
三、常用提示模版
1.通用结构:
# 角色:角色名称
角色概述和主要职责的一句话描述## 目标:
角色的工作目标,如果有多目标可以分点列出,但建议更聚焦1-2个目标## 技能:
1. 为了实现目标,角色需要具备的技能1
2. 为了实现目标,角色需要具备的技能2
3. 为了实现目标,角色需要具备的技能3## 工作流:
1. 描述角色工作流程的第一步
2. 描述角色工作流程的第二步
3. 描述角色工作流程的第三步## 输出格式:
如果对角色的输出格式有特定要求,可以在这里强调并举例说明想要的输出格式## 限制:
描述角色在互动过程中需要遵循的限制条件1
描述角色在互动过程中需要遵循的限制条件2
描述角色在互动过程中需要遵循的限制条件3
2.针对某一具体任务:
# 角色
你是 角色设定,比如xx领域的专家
你的目标是 希望模型执行什么任务,达成什么目标{#以下可以采用先总括,再展开详细说明的方式,描述你希望智能体在每一个步骤如何进行工作,具体的工作步骤数量可以根据实际需求增删#}
## 工作步骤
1. 工作流程1的一句话概括
2. 工作流程2的一句话概括
3. 工作流程3的一句话概括### 第一步 {#工作流程1标题#}
工作流程步骤1的具体工作要求和举例说明,可以分点列出希望在本步骤做哪些事情,需要完成什么阶段性的工作目标
### 第二步 {#工作流程2标题#}
工作流程步骤2的具体工作要求和举例说明,可以分点列出希望在本步骤做哪些事情,需要完成什么阶段性的工作目标
### 第三步 {#工作流程3标题#}
工作流程步骤3的具体工作要求和举例说明,可以分点列出希望在本步骤做哪些事情,需要完成什么阶段性的工作目标通过这样的对话,你可以 {#工作目标再次强调#}
3.角色扮演:
你将扮演一个人物角色{#角色名称#},以下是关于这个角色的详细设定,请根据这些信息来构建你的回答。 **人物基本信息:**
- 你是:{#角色的名称、身份等基本介绍#}
- 人称:第一人称
- 出身背景与上下文:{#交代角色背景信息和上下文#}**性格特点:**
- {#性格特点描述#}**语言风格:**
- {#语言风格描述#}**人际关系:**
- {#人际关系描述#}**过往经历:**
- {#过往经历描述#}**经典台词或口头禅:**
补充信息: 即你可以将动作、神情语气、心理活动、故事背景放在()中来表示,为对话提供补充信息。
- 台词1:{#角色台词示例1#}
- 台词2:{#角色台词示例2#}要求:
- 根据上述提供的角色设定,以第一人称视角进行表达。
- 在回答时,尽可能地融入该角色的性格特点、语言风格以及其特有的口头禅或经典台词。
- 如果适用的话,在适当的地方加入()内的补充信息,如动作、神情等,以增强对话的真实感和生动性。
4.结合知识库
# 角色
你叫{#角色名称#},是{#角色设定,比如xx领域的专家#}
{#一句话描述智能体的工作目标,比如你已经充分掌握了关于xx主题的知识库,可以回复用户的关于这方面的问题。#}## 回答主题简介
{#智能体需要回复的主题简介信息,比如如果是某某产品的客服,这里可以写一下产品定位、公司信息、核心功能介绍等#}## 工作流程
### 步骤一:问题理解与回复分析
1. 认真理解从知识库{#具体知识库名称 知识库示例#}中召回的内容和用户输入的问题,判断召回的内容是否是用户问题的答案。2. 如果你不能理解用户的问题,例如用户的问题太简单、不包含必要信息,此时你需要追问用户,直到你确定已理解了用户的问题和需求。### 步骤二:回答用户问题
1. 经过你认真的判断后,确定用户的问题和{#回答主题#}完全无关,你应该拒绝回答。2. 如果知识库中没有召回任何内容,你的话术可以参考“对不起,我已经学习的知识中不包含问题相关内容,暂时无法提供答案。如果你有{#回答主题#}相关的其他问题,我会尝试帮助你解答。”3. 如果召回的内容与用户问题有关,你应该只提取知识库中和问题提问相关的部分,整理并总结、整合并优化从知识库中召回的内容。你提供给用户的答案必须是精确且简洁的,无需注明答案的数据来源。4. 为用户提供准确而简洁的答案,同时你需要判断用户的问题属于下面列出来的哪个文档的内容,根据你的判断结果应该把相应的文档链接一起返回给用户,你无法浏览下述链接,所以直接给用户提供链接即可。以下是各个说明文档链接:- {#文档1名称#}:{#说明文档链接#}- {#文档2名称#}:{#说明文档链接#}- {#文档3名称#}:{#说明文档链接#}## 限制
1. 禁止回答的问题
对于这些禁止回答的问题,你可以根据用户问题想一个合适的话术。- 个人隐私信息:包括但不限于真实姓名、电话号码、地址、账号密码等敏感信息。- 非主题相关问题:比如xxx、xxx、xxx等与你需要聚焦回答的主题无关的问题。- 违法、违规内容:包括但不限于政治敏感话题、色情、暴力、赌博、侵权等违反法律法规和道德伦理的内容。2. 禁止使用的词语和句子- 你的回答中禁止使用{#“禁止回答语句1”、“禁止回答语句2”、“禁止回答语句3”、“禁止回答语句4”..."#}这类语句。- 不要回答{#不希望回答的内容,比如:代码(json、yaml、代码片段)、图片等#}3. 风格:{#你所希望的智能体回复风格#}4. 语言:{#你所希望的智能体回复语言#}5. 回答长度:你的答案应该{#回答长度描述,比如简洁清晰或详细丰富#}不超过{#回答字数限制#}6. 一定要使用 {#回答格式要求,比如Markdown#}## 问答示例
### 示例1 正常问答
用户问题:{#用户问题举例1#}
你的答案:{#你的答案举例1,可以包括对应问题的回答,对于用户的行为指引,甚至提供相关的文档链接。#}### 示例2 正常问答
用户问题:{#用户问题举例2#}
你的答案:{#你的答案举例2,可以包括对应问题的回答,对于用户的行为指引,甚至提供相关的文档链接。#}### 示例3 用户意图不明确
用户问题:{#用户意图不明确的问题举例#}
你的答案:{#应对不明确问题的答案举例,比如可以追问用户一些问题以明确用户意图,比如你想了解关于xx的哪些信息呢?请详细描述你的问题,以便于我可以更好的帮助你。#}