2025年SEVC SCI2区,基于强化学习的改进算术优化算法QL-REP-AOA+全局优化,深度解析+性能实测
目录
- 1.摘要
- 2.算术优化算法AOA原理
- 3.Q-learning算法
- 4.基于Q-learning和随机精英池策略的算法优化算法
- 5.结果展示
- 6.参考文献
- 7.代码获取
- 8.算法辅导·应用定制·读者交流

1.摘要
为克服算术优化算法(AOA)在解的精度和收敛速度方面的不足,本文提出了一种基于强化 Q 学习和随机精英池策略改进算法(QL-REP-AOA),该算法基于迭代过程构建状态空间,并设计了具有阶段自适应性的非线性奖励函数。通过这一设计,算法能够根据优化问题不同阶段的特征,动态选择最优的搜索策略。此外,引入了随机精英池策略,通过多种搜索算子的协同作用,增强了种群的多样性和搜索效率。
2.算术优化算法AOA原理
【智能算法】算术优化算法(AOA)原理及实现
3.Q-learning算法
Q学习是一种用于马尔可夫决策过程(MDP)的无模型强化学习方法,其核心基于贝尔曼方程,通过刻画当前状态与其后继状态的价值关系,逐步逼近最优策略。Q学习的基本思想是通过迭代更新Q值,近似最优价值函数,从而实现最优决策。核心更新公式:
Q ( s t + 1 , a t + 1 ) = Q ( s t , a t ) + α [ r t + 1 + γ max a Q ( s t + 1 , a ) − Q ( s t , a t ) ] Q(s_{t+1},a_{t+1})=Q(s_t,a_t)+\alpha\left[r_{t+1}+\gamma\max_aQ(s_{t+1},a)-Q(s_t,a_t)\right] Q(st+1,at+1)=Q(st,at)+α[rt+1+γamaxQ(st+1,a)−Q(st,at)]
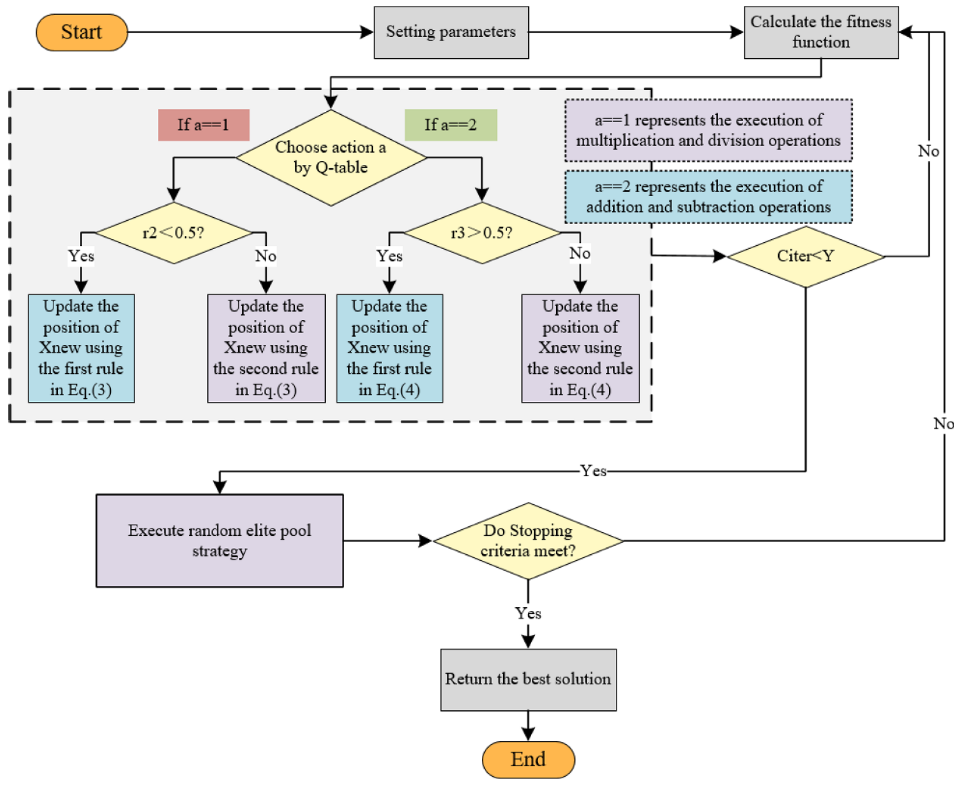
4.基于Q-learning和随机精英池策略的算法优化算法
状态空间和动作空间的设计
状态空间的设计在强化学习中至关重要,它直接关系到智能体的决策效果及Q学习算法的收敛性。本文基于迭代次数构建状态空间,将每一次迭代定义为一个状态;动作空间由两类搜索策略组成:乘除法与加减法。通过Q学习机制,在每一状态下动态选择最优策略,以实现阶段适应性搜索。
奖励函数
奖励函数是Q学习中的核心组成部分,直接决定了智能体的学习方向与策略选择。它通过反馈引导智能体向目标不断逼近,从而提升整体优化性能。当算法在相邻两个阶段之间取得优化结果的提升时,给予智能体相应的正向奖励;提升幅度越大,奖励越高;若连续阶段未见提升甚至出现退步,则施加惩罚。为增强算法在后期跳出局部最优的能力,QL-AOA中特别设定了阶段性奖励策略:在后期迭代中,一旦适应度值有所提升,即给予更高奖励。
r t + 1 = { ω × t × ∣ log ( B e s t t + 1 ) − log ( B e s t t ) ∣ , B e s t t + 1 > B e s t t − 0.5 , B e s t t + 1 = B e s t t \left.r_{t+1}=\left\{ \begin{array} {c}\omega\times t\times\left|\log(Best_{t+1})-\log(Best_t)\right|,Best_{t+1}>Best_t \\ -0.5,Best_{t+1}=Best_t \end{array}\right.\right. rt+1={ω×t×∣log(Bestt+1)−log(Bestt)∣,Bestt+1>Bestt−0.5,Bestt+1=Bestt
为增强精英池个体的多样性并提升算法的全局搜索能力,本文引入了四种互补的搜索策略,用来协同探索解空间。通过融合不同特性的策略,算法能更全面地覆盖搜索区域,提升发现潜在最优解的概率。
搜索策略1
X 1 ( c + 1 ) = X b e s t ( c ) × ( 1 − c T ) + ( X M ( c ) − X b e s t ( c ) × r a n d ) X_1(c+1)=X_{best}(c)\times\left(1-\frac{c}{T}\right)+(X_M(c)-X_{best}(c)\times rand) X1(c+1)=Xbest(c)×(1−Tc)+(XM(c)−Xbest(c)×rand)
搜索策略2
X 2 ( c + 1 ) = ( X b e s t ( c ) − X M ( c ) ) × 0.1 − r a n d + ( ( U B − L B ) × r a n d + L B ) × 0.1 X_2(c+1)=(X_{best}(c)-X_M(c))\times0.1-rand+((UB-LB)\times rand+LB)\times0.1 X2(c+1)=(Xbest(c)−XM(c))×0.1−rand+((UB−LB)×rand+LB)×0.1
搜索策略3
X 3 ( c + 1 ) = X b e s t ( c ) × L F ( D ) + X R ( c ) + ( r × ( sin ( θ ) − cos ( θ ) ) ) × r a n d X_3(c+1)=X_{best}(c)\times LF(D)+X_R(c)+(r\times(\sin(\theta)-\cos(\theta)))\times rand X3(c+1)=Xbest(c)×LF(D)+XR(c)+(r×(sin(θ)−cos(θ)))×rand
搜索策略4
X 4 ( c + 1 ) = X b e s t ( c ) + ( X b e s t ( c ) − X i ( c ) ) + tan ( ( a × r a n d − a ) × r a n d ) X_4(c+1)=X_{best}(c)+(X_{best}(c)-X_i(c))+\tan((a\times rand-a)\times rand) X4(c+1)=Xbest(c)+(Xbest(c)−Xi(c))+tan((a×rand−a)×rand)
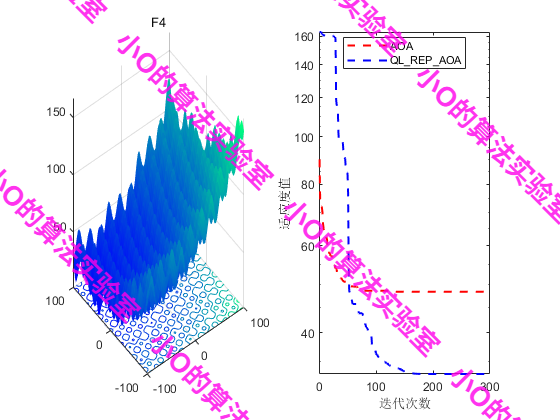
5.结果展示
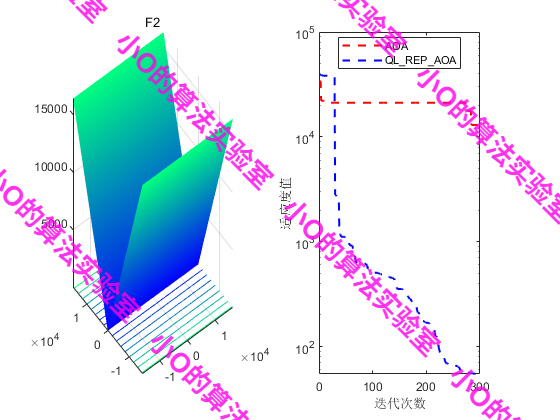
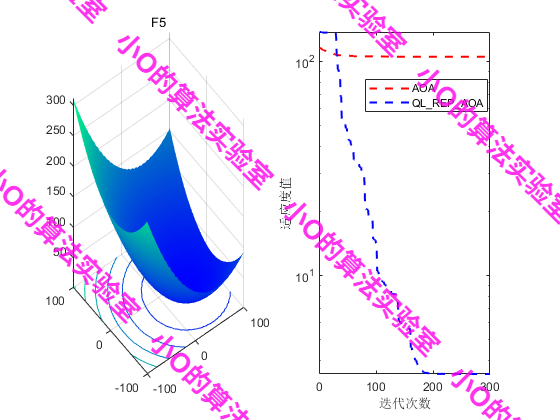
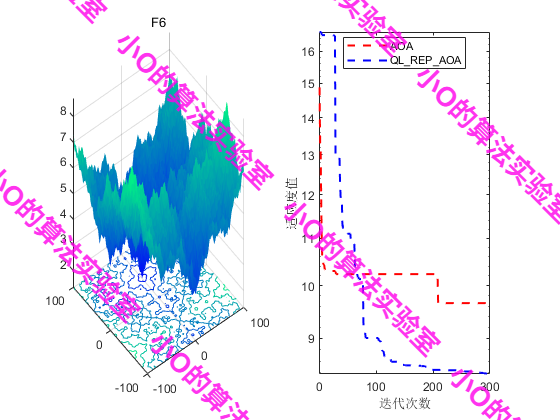
6.参考文献
[1] Liu H, Chen Z, Zhang X, et al. An improved arithmetic optimization algorithm based on reinforcement learning for global optimization and engineering design problems[J]. Swarm and Evolutionary Computation, 2025, 96: 101985.
7.代码获取
xx