【完整源码+数据集+部署教程】石材实例分割系统源码和数据集:改进yolo11-CA-HSFPN
研究背景与意义
研究背景与意义
随着计算机视觉技术的快速发展,实例分割作为其中一个重要的研究方向,逐渐在多个领域中展现出其独特的应用价值。实例分割不仅能够对图像中的物体进行识别,还能精确地划分出每个物体的轮廓,这在许多实际应用中都具有重要意义。例如,在建筑行业中,石材的识别与分割对于材料的管理、施工进度的监控以及成本控制等方面都起着至关重要的作用。因此,开发一个高效的石材实例分割系统,能够有效提升相关行业的自动化水平和工作效率。
本研究旨在基于改进的YOLOv11模型,构建一个针对石材的实例分割系统。YOLO(You Only Look Once)系列模型以其快速的检测速度和良好的准确性而闻名,然而,针对特定应用场景的改进仍然是提升模型性能的关键。本项目将利用1300张石材图像的数据集,进行模型的训练与优化。该数据集的单一类别特性,虽然在某种程度上限制了模型的泛化能力,但也为专注于石材实例分割提供了良好的基础。
通过对YOLOv11模型的改进,我们期望在石材实例分割的精度和速度上实现显著提升。具体而言,改进将集中在特征提取网络的优化、损失函数的调整以及后处理策略的创新等方面。这些改进不仅有助于提高模型在石材分割任务中的表现,还将为其他相似的实例分割任务提供参考。
综上所述,基于改进YOLOv11的石材实例分割系统的研究,不仅能够推动计算机视觉技术在建筑材料管理中的应用,还将为相关领域的智能化发展提供有力支持。通过本项目的实施,我们期望为行业提供一种高效、准确的解决方案,助力于实现更高水平的自动化与智能化。
图片演示
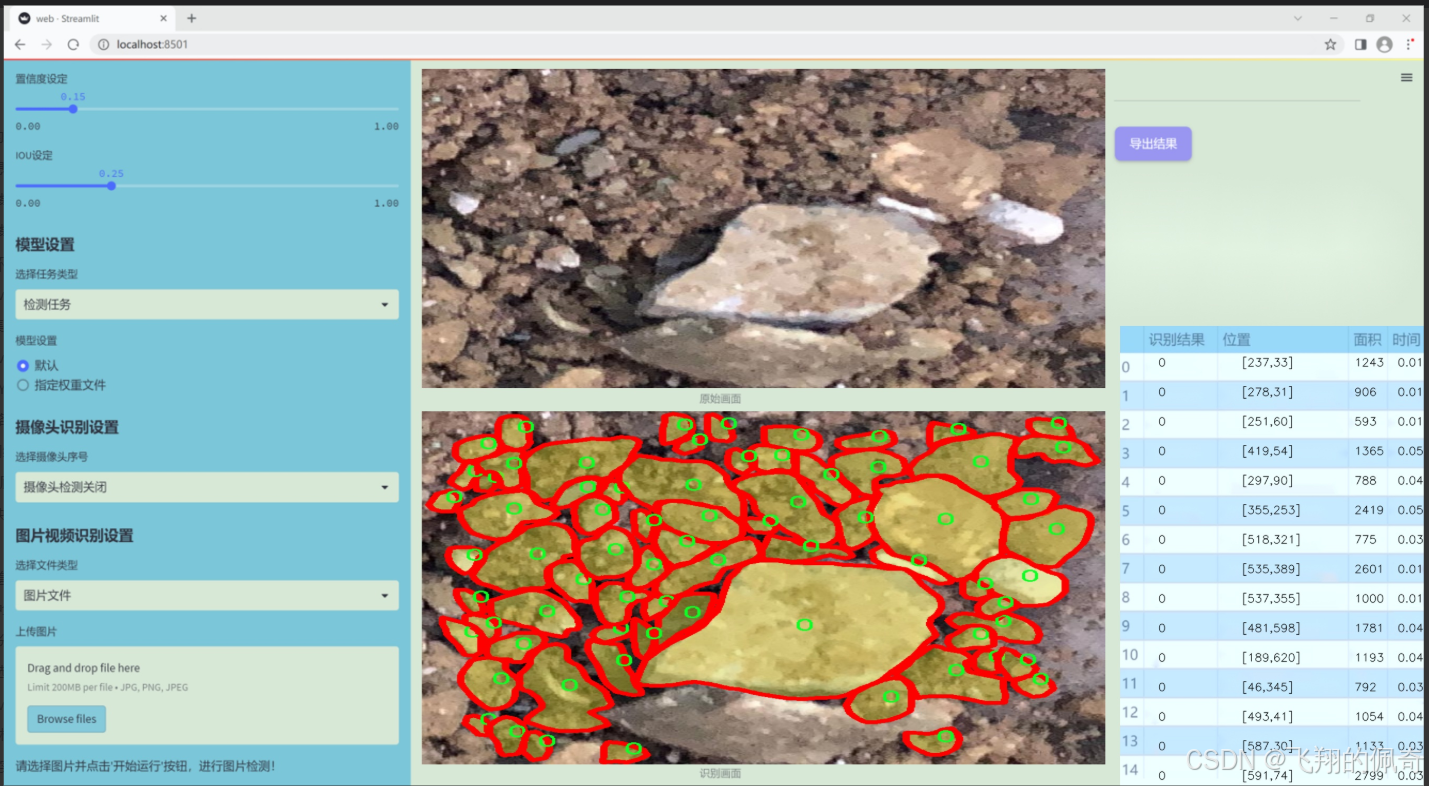
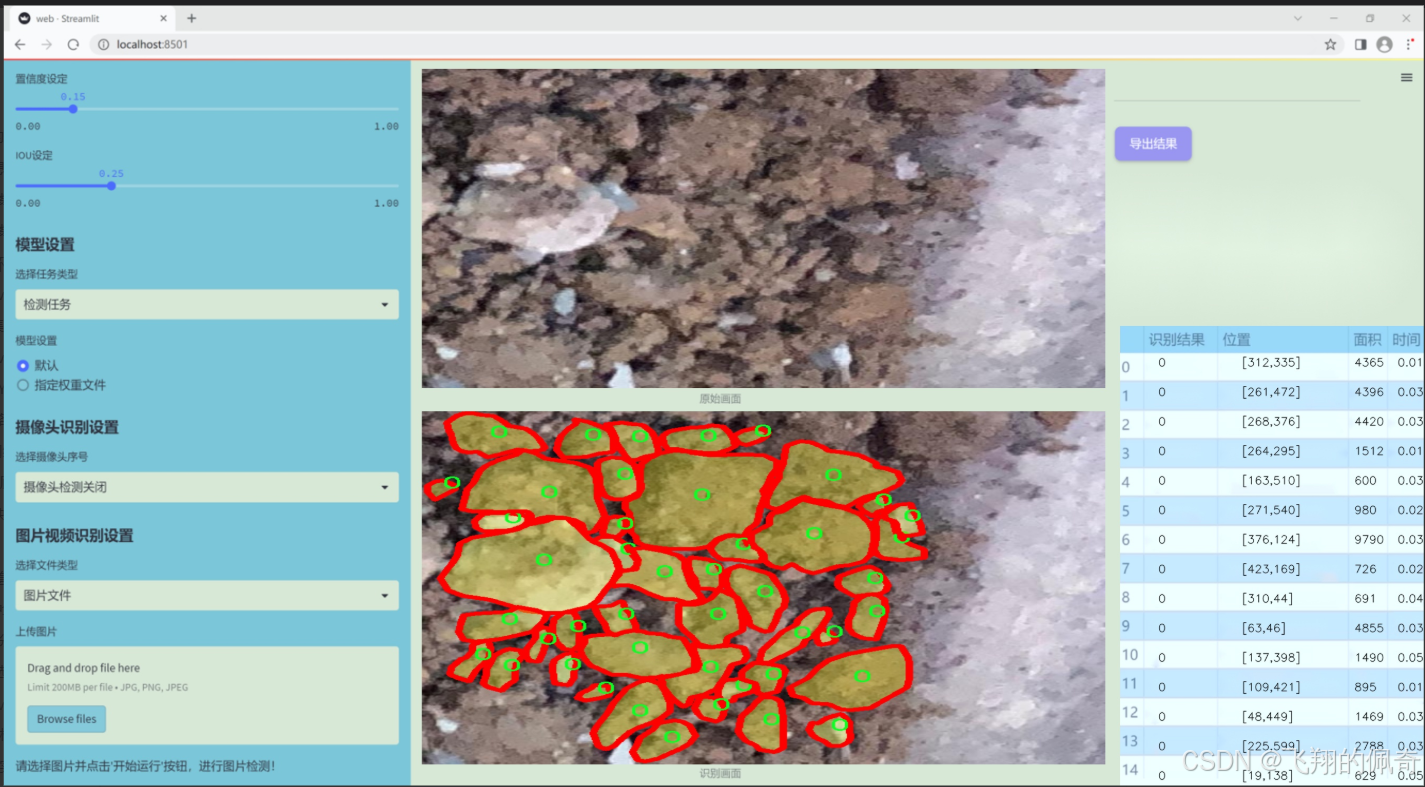
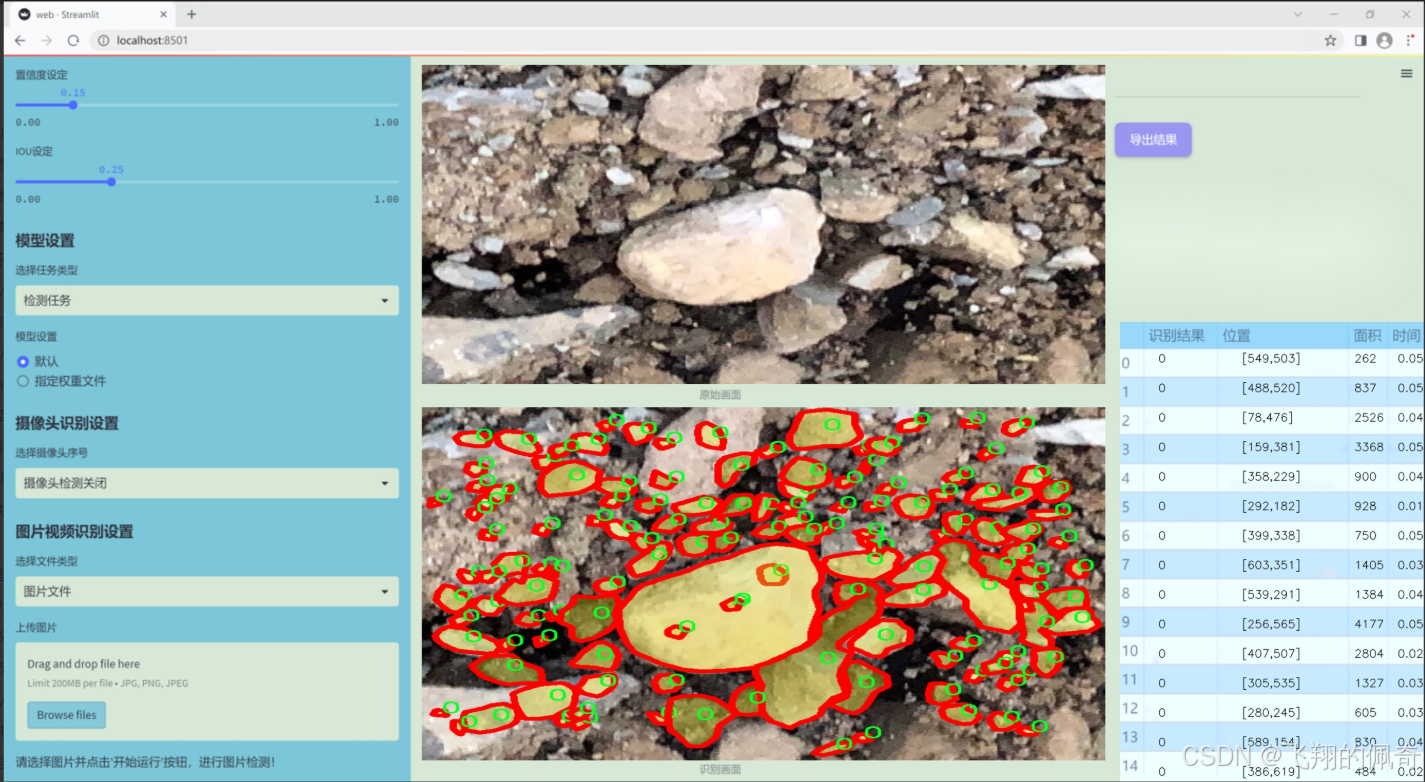
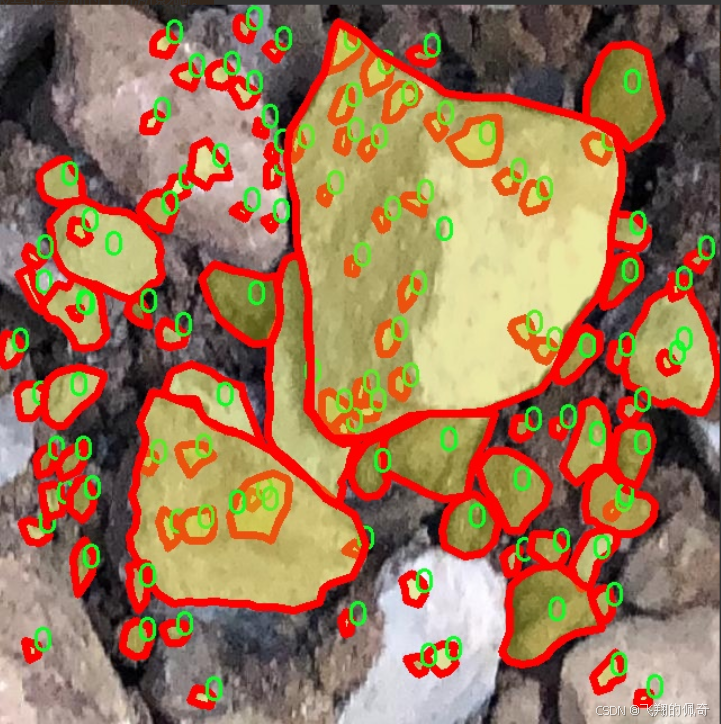
数据集信息展示
本项目数据集信息介绍
本项目所使用的数据集专注于“stone”这一主题,旨在为改进YOLOv11的石材实例分割系统提供高质量的训练数据。该数据集的设计充分考虑了石材的多样性和复杂性,涵盖了不同类型、形状和纹理的石材实例,以确保模型在实际应用中的鲁棒性和准确性。数据集中包含的类别数量为1,具体类别标记为“0”,这意味着所有的石材实例均被归入同一类别,便于模型专注于学习石材的特征而不被其他类别的干扰所影响。
为了构建这个数据集,我们从多个来源收集了大量的石材图像,确保样本的多样性和代表性。这些图像包括不同光照条件下的石材、不同角度拍摄的石材,以及不同背景下的石材实例。这种多样化的样本选择有助于提高模型的泛化能力,使其能够在各种环境中有效识别和分割石材。
在数据标注方面,我们采用了精细的实例分割标注技术,为每一张图像中的石材实例提供了准确的边界框和掩膜。这种高质量的标注不仅提升了数据集的价值,也为模型的训练提供了可靠的基础。通过使用这一数据集,我们期望能够显著提升YOLOv11在石材实例分割任务中的性能,使其在实际应用中能够更准确地识别和处理石材对象,从而推动相关领域的技术进步和应用拓展。




项目核心源码讲解(再也不用担心看不懂代码逻辑)
以下是经过简化并附有详细中文注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Mlp(nn.Module):
“”" 多层感知机(MLP)模块。“”"
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_features # 输出特征数hidden_features = hidden_features or in_features # 隐藏层特征数self.fc1 = nn.Linear(in_features, hidden_features) # 第一层线性变换self.act = act_layer() # 激活函数self.fc2 = nn.Linear(hidden_features, out_features) # 第二层线性变换self.drop = nn.Dropout(drop) # Dropout层def forward(self, x):""" 前向传播函数。"""x = self.fc1(x) # 线性变换x = self.act(x) # 激活x = self.drop(x) # Dropoutx = self.fc2(x) # 线性变换x = self.drop(x) # Dropoutreturn x
class WindowAttention(nn.Module):
“”" 基于窗口的多头自注意力模块。“”"
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dim # 输入通道数self.window_size = window_size # 窗口大小self.num_heads = num_heads # 注意力头数head_dim = dim // num_heads # 每个头的维度self.scale = head_dim ** -0.5 # 缩放因子# 定义相对位置偏置参数self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))# 计算相对位置索引coords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 生成坐标网格coords_flatten = torch.flatten(coords, 1) # 展平坐标relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 计算相对坐标relative_coords = relative_coords.permute(1, 2, 0).contiguous() # 重新排列维度relative_coords[:, :, 0] += self.window_size[0] - 1 # 归一化relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1) # 计算相对位置索引self.register_buffer("relative_position_index", relative_position_index) # 注册为缓冲区self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # QKV线性变换self.attn_drop = nn.Dropout(attn_drop) # 注意力Dropoutself.proj = nn.Linear(dim, dim) # 输出线性变换self.proj_drop = nn.Dropout(proj_drop) # 输出Dropoutself.softmax = nn.Softmax(dim=-1) # Softmax层def forward(self, x, mask=None):""" 前向传播函数。"""B_, N, C = x.shape # B: 批量大小, N: 序列长度, C: 通道数qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # 分离Q, K, Vq = q * self.scale # 缩放Qattn = (q @ k.transpose(-2, -1)) # 计算注意力分数# 添加相对位置偏置relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # 重新排列attn = attn + relative_position_bias.unsqueeze(0) # 加入偏置attn = self.softmax(attn) # 归一化attn = self.attn_drop(attn) # Dropoutx = (attn @ v).transpose(1, 2).reshape(B_, N, C) # 计算输出x = self.proj(x) # 输出线性变换x = self.proj_drop(x) # Dropoutreturn x
class SwinTransformer(nn.Module):
“”" Swin Transformer主干网络。“”"
def __init__(self, patch_size=4, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24]):super().__init__()self.patch_embed = PatchEmbed(patch_size=patch_size, in_chans=3, embed_dim=embed_dim) # 图像分块嵌入self.layers = nn.ModuleList() # 存储各层# 构建每一层for i_layer in range(len(depths)):layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=7) # 窗口大小self.layers.append(layer)def forward(self, x):""" 前向传播函数。"""x = self.patch_embed(x) # 图像分块嵌入for layer in self.layers:x = layer(x) # 逐层前向传播return x # 返回最终输出
def SwinTransformer_Tiny(weights=‘’):
“”" 创建Swin Transformer Tiny模型。“”"
model = SwinTransformer(depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24]) # 创建模型
if weights:
model.load_state_dict(torch.load(weights)[‘model’]) # 加载权重
return model
代码说明:
Mlp类:实现了一个简单的多层感知机,包含两个线性层和一个激活函数,支持Dropout。
WindowAttention类:实现了窗口自注意力机制,计算Q、K、V并加入相对位置偏置。
SwinTransformer类:构建了Swin Transformer的主干网络,包含图像分块嵌入和多个Transformer层。
SwinTransformer_Tiny函数:用于创建一个小型的Swin Transformer模型,并可选择加载预训练权重。
此代码为Swin Transformer的核心部分,包含了主要的结构和计算逻辑。
这个程序文件实现了Swin Transformer模型,主要用于计算机视觉任务。Swin Transformer是一种层次化的视觉Transformer,采用了窗口注意力机制,通过分块处理图像来提高计算效率。以下是对代码的详细说明。
首先,导入了必要的库,包括PyTorch和一些辅助函数。接着定义了一个多层感知机(Mlp)类,它包含两个全连接层和一个激活函数(默认为GELU),并在每个层之间使用了Dropout以防止过拟合。
接下来,定义了窗口分割和窗口逆转的函数。window_partition函数将输入特征图分割成多个窗口,而window_reverse函数则将这些窗口合并回原来的特征图。这种窗口操作是Swin Transformer的核心思想之一。
然后,定义了WindowAttention类,这是窗口基础的多头自注意力模块。它支持相对位置偏置,并可以处理移动窗口(shifted window)和非移动窗口的情况。这个模块通过线性变换生成查询、键和值,并计算注意力权重,最后通过线性变换输出结果。
接着,定义了SwinTransformerBlock类,它是Swin Transformer的基本构建块。每个块包含一个窗口注意力层和一个前馈网络(FFN),并使用残差连接和层归一化。该块还支持窗口的循环移动,以便在不同的块之间共享信息。
PatchMerging类用于将特征图的块合并,减少空间维度并增加通道数。它通过线性变换实现特征的降维。
BasicLayer类表示Swin Transformer中的一个基本层,包含多个Swin Transformer块。它还负责计算SW-MSA的注意力掩码,并在必要时进行下采样。
PatchEmbed类用于将输入图像分割成不重叠的块,并通过卷积层将其嵌入到高维空间中。它还可以选择性地对嵌入进行归一化。
SwinTransformer类是整个模型的主类,负责构建Swin Transformer的各个层。它支持绝对位置嵌入、随机深度、归一化等功能,并在前向传播中依次通过各个层。
最后,定义了一个update_weight函数,用于更新模型的权重,并定义了一个SwinTransformer_Tiny函数,用于创建一个小型的Swin Transformer模型实例,并加载预训练权重(如果提供)。
整体来看,这个文件实现了Swin Transformer的完整结构,提供了图像处理所需的各个组件,并通过模块化设计使得模型的构建和使用更加灵活。
10.3 head.py
以下是经过简化和注释的核心代码部分,主要集中在Detect_DyHead类及其forward方法的实现。这个类是YOLOv8检测模型的一个重要组成部分,负责处理输入特征并生成检测结果。
import torch
import torch.nn as nn
import math
class Detect_DyHead(nn.Module):
“”“YOLOv8 检测头,使用动态头(DyHead)进行目标检测。”“”
def __init__(self, nc=80, hidc=256, block_num=2, ch=()):"""初始化检测头的参数。参数:nc (int): 类别数量。hidc (int): 隐藏层通道数。block_num (int): 动态头块的数量。ch (tuple): 输入特征图的通道数。"""super().__init__()self.nc = nc # 类别数量self.nl = len(ch) # 检测层的数量self.reg_max = 16 # DFL通道数self.no = nc + self.reg_max * 4 # 每个锚点的输出数量self.stride = torch.zeros(self.nl) # 在构建过程中计算的步幅c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], self.nc) # 通道数# 定义卷积层self.conv = nn.ModuleList(nn.Sequential(Conv(x, hidc, 1)) for x in ch)self.dyhead = nn.Sequential(*[DyHeadBlock(hidc) for _ in range(block_num)]) # 动态头块self.cv2 = nn.ModuleList(nn.Sequential(Conv(hidc, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for _ in ch)self.cv3 = nn.ModuleList(nn.Sequential(nn.Sequential(DWConv(hidc, x, 3), Conv(x, c3, 1)),nn.Sequential(DWConv(c3, c3, 3), Conv(c3, c3, 1)),nn.Conv2d(c3, self.nc, 1),)for x in ch)self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity() # DFL层def forward(self, x):"""连接并返回预测的边界框和类别概率。"""# 对每个检测层应用卷积for i in range(self.nl):x[i] = self.conv[i](x[i])# 通过动态头处理特征x = self.dyhead(x)shape = x[0].shape # BCHW# 将每个检测层的输出连接在一起for i in range(self.nl):x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)# 如果在训练模式下,直接返回if self.training:return x# 动态模式或形状变化时,更新锚点和步幅self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))self.shape = shape# 将所有输出连接成一个张量x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)# 分割边界框和类别box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)# 解码边界框dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides# 返回最终的输出return torch.cat((dbox, cls.sigmoid()), 1)def bias_init(self):"""初始化检测头的偏置,警告:需要步幅可用。"""for a, b, s in zip(self.cv2, self.cv3, self.stride):a[-1].bias.data[:] = 1.0 # 边界框偏置b[-1].bias.data[:self.nc] = math.log(5 / self.nc / (640 / s) ** 2) # 类别偏置
代码说明:
类的定义:Detect_DyHead类是YOLOv8模型中的一个检测头,负责处理输入特征并生成检测结果。
初始化方法:在__init__方法中,定义了模型的各个参数,包括类别数量、隐藏层通道数、动态头块的数量等,并构建了必要的卷积层。
前向传播方法:forward方法实现了特征的处理流程,包括卷积操作、动态头的应用、输出的连接和最终的边界框与类别的解码。
偏置初始化:bias_init方法用于初始化模型中的偏置参数,以提高模型的收敛速度和性能。
这个代码片段展示了YOLOv8检测头的核心功能,适合用于目标检测任务。
这个文件 head.py 是一个用于 YOLOv8(You Only Look Once 第八版)目标检测模型的实现,主要包含多个检测头的定义。文件中使用了 PyTorch 框架,并引入了一些常用的深度学习模块和函数。以下是对文件内容的详细说明。
首先,文件导入了一些必要的库,包括数学库、深度学习库 PyTorch 及其相关模块。接着,文件定义了多个类,每个类代表一种特定的检测头,负责处理输入特征图并输出目标检测的结果。
Detect_DyHead 类是一个动态头部的实现,适用于目标检测模型。它的构造函数初始化了一些参数,包括类别数量、隐藏通道数、块的数量等。该类的 forward 方法实现了前向传播,处理输入特征图并返回预测的边界框和类别概率。
接下来的类 Detect_DyHeadWithDCNV3 和 Detect_DyHeadWithDCNV4 继承自 Detect_DyHead,并使用不同的动态头块。这些类提供了不同的网络结构,以适应不同的检测需求。
Detect_AFPN_P345 和 Detect_AFPN_P345_Custom 类实现了带有自适应特征金字塔网络(AFPN)的检测头。AFPN 通过多层特征融合来提高检测精度。这些类的 forward 方法类似于前面的检测头,但使用了 AFPN 结构。
Detect_Efficient 类实现了一个高效的检测头,旨在减少计算量并提高速度。它使用了分组卷积和其他技术来优化性能。
DetectAux 类实现了一个带有辅助头的检测头,用于同时进行主任务和辅助任务的学习。它在 forward 方法中处理主任务和辅助任务的特征图。
Detect_SEAM 和 Detect_MultiSEAM 类实现了基于 SEAM(Squeeze-and-Excitation Attention Module)和 Multi-SEAM 的检测头。这些模块通过引入注意力机制来增强特征图的表达能力。
Detect_DyHead_Prune 类实现了一个经过剪枝的动态头部,旨在减少模型的复杂性和计算量。
Detect_LSCD 和 Detect_LSCSBD 类实现了轻量级共享卷积检测头,采用共享卷积和分离批归一化的策略来提高效率。
Detect_LADH 类实现了一个带有深度可分离卷积的检测头,旨在提高模型的效率和准确性。
Detect_NMSFree 类实现了一个无非极大值抑制(NMS)的检测头,适用于需要更高精度的场景。
最后,文件中还定义了一些辅助类和函数,如 Scale、Conv_GN、TaskDecomposition 等,这些类和函数用于实现特定的功能,如可学习的缩放参数、标准卷积层、任务分解等。
整体来看,这个文件是 YOLOv8 模型中检测头的实现,包含了多种不同的检测头结构,以适应不同的应用场景和需求。每个类的设计都考虑到了性能和准确性之间的平衡,使用了现代深度学习技术来提高模型的表现。
10.4 predict.py
以下是代码中最核心的部分,并附上详细的中文注释:
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
“”"
DetectionPredictor类,继承自BasePredictor类,用于基于检测模型进行预测。
“”"
def postprocess(self, preds, img, orig_imgs):"""对预测结果进行后处理,并返回Results对象的列表。参数:preds: 模型的预测结果img: 输入图像orig_imgs: 原始图像列表或张量返回:results: 包含处理后结果的Results对象列表"""# 应用非极大值抑制(NMS)来过滤重叠的检测框preds = ops.non_max_suppression(preds,self.args.conf, # 置信度阈值self.args.iou, # IOU阈值agnostic=self.args.agnostic_nms, # 是否使用类别无关的NMSmax_det=self.args.max_det, # 最大检测框数量classes=self.args.classes, # 需要检测的类别)# 如果输入的原始图像不是列表,说明是一个torch.Tensor,需要转换为numpy数组if not isinstance(orig_imgs, list):orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)results = [] # 存储结果的列表for i, pred in enumerate(preds):orig_img = orig_imgs[i] # 获取对应的原始图像# 将预测框的坐标缩放到原始图像的尺寸pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)img_path = self.batch[0][i] # 获取图像路径# 创建Results对象并添加到结果列表中results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))return results # 返回处理后的结果列表
代码说明:
类定义:DetectionPredictor 类继承自 BasePredictor,用于处理基于检测模型的预测。
后处理方法:postprocess 方法负责对模型的预测结果进行后处理,包括应用非极大值抑制(NMS)和调整预测框的坐标。
非极大值抑制:通过 ops.non_max_suppression 函数过滤掉重叠的检测框,以提高检测的准确性。
图像转换:如果原始图像不是列表格式,则将其转换为 NumPy 数组,以便后续处理。
结果存储:通过循环遍历每个预测结果,调整预测框坐标,并将每个结果存储为 Results 对象,最终返回所有结果的列表。
这个程序文件 predict.py 是一个用于目标检测的预测模块,基于 Ultralytics YOLO(You Only Look Once)模型。它通过继承 BasePredictor 类,扩展了预测功能,主要用于处理目标检测任务。
在文件的开头,导入了必要的模块,包括 BasePredictor、Results 和一些实用的操作函数 ops。这些模块提供了基础的预测功能、结果处理和一些图像操作。
DetectionPredictor 类是这个文件的核心,主要负责处理目标检测模型的预测。类中包含一个 postprocess 方法,该方法用于对模型的预测结果进行后处理,返回一个 Results 对象的列表。
在 postprocess 方法中,首先调用 ops.non_max_suppression 函数对预测结果进行非极大值抑制(NMS),以去除重复的检测框。这个过程使用了一些参数,如置信度阈值、IOU(Intersection over Union)阈值、是否使用类别无关的 NMS、最大检测框数量以及需要检测的类别。
接下来,方法检查输入的原始图像是否为列表,如果不是,则将其转换为 NumPy 数组格式,以便后续处理。然后,程序会遍历每个预测结果,并对每个预测框进行坐标缩放,以适应原始图像的尺寸。最终,使用 Results 类将处理后的结果(包括原始图像、图像路径、模型类别名称和预测框)封装起来,并将所有结果返回。
这个模块的使用示例展示了如何初始化 DetectionPredictor,并通过调用 predict_cli 方法进行预测。用户可以通过传入模型文件和数据源来执行目标检测任务。整体来看,这个文件提供了一个结构清晰、功能完整的目标检测预测实现。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻