定时线程池失效问题引发的思考
最近在做的一个新功能,在结果探测的时候使用了定时线程池和普通线程池结合,定时线程池周期性创建子任务并往普通线程池提交任务。
问题:
在昨天测试老师发现,业务实际上已经成功了,但是页面还是一直显示进行中。
收到问题后,首先是去查看日志,确认下探测任务是否还在执行,结合日志和待探测任务的缓存数据发现,待探测任务队列是有数据的,但是探测任务一整天都没有执行了。那么可以初步确定问题是定时任务停止了,导致探测任务没有执行,所以业务虽然成功了,但是状态还是进行中。
因为之前遇到过定时线程池停止的问题,所以首先就怀疑是因为定时任务提交任务的时候,因为某种原因抛出了异常,导致定时线程池停止执行。如何验证呢?找遍了日志也没有找到相关的错误日志,于是通过arthas的trace方法监控该方法是否执行,经过了多个定时周期后,发现没有堆栈打印,说明定时线程池确实停止了执行,至此问题已经实锤。
没有日志,所以没法直接判断到底是什么异常导致的问题,分析代码和待探测任务队列发现,探测任务很多,达到了50个,但是我的线程池设置的参数如下(稍微了解线程池调度机制的应该都可以从参数设置上看出问题了):
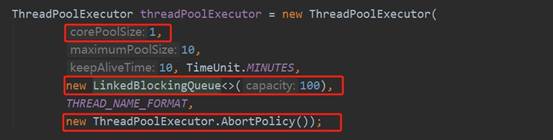
个人初步分析:由于队列设置太小,任务太多,且大多数任务实际上非常耗时的(20s左右),且线程池提交的拒绝策略设置为了AbortPlicy,所以当线程池达到最大线程池数量以及队列满的情况下,新接收到提交的任务后,便会直接抛出异常,刚好这里没有异常捕获机制,导致了定时线程池的调度停止。
![]()
进一步的,我们需要结合代码逻辑看下需要增加哪些手段确保定时线程池不会因为异常停止,有以下几个手段:
1、兜底策略:增加捕获异常,防止定时线程池因为执行任务过程中抛出的异常导致停止
2、针对框架的策略:修改普通线程池的拒绝策略,使得在队列满和达到最大线程池数的情况下,提交任务也不会导致异常
3、针对业务上的策略:当前任务较多的原因是没有做业务校验,使得很多的不需要探测的数据进入了缓存,这里通过监听业务释放消息去掉部分数据
通过以上修改,替换到测试环境,观察问题暂时被解决了。但是观察到一个异常的现象,那就是发现任务执行的比较慢,感觉是在串行,没有达到想象中的并发执行。
于是每次提交任务时候,打印了线程池的activeCount、poolSize和queueSize三个数据,发现activeCount始终是1。那么问题就很明显了,说明线程池一直只有核心线程在执行,没有新开非核心线程。
到这里才恍然大悟,原来问题的根本在于线程池核心线程数的设置不对,导致任务一直往等待队列中堆积,等到队列满后,线程池扩容,但因为很多任务都是慢任务导致线程池处理速度小于任务提交速度,最终在线程和队列达到最高负荷时,再提交任务抛出异常,该异常导致了定时线程池停止。
该问题的核心还是对于线程池的参数设置以及线程池的执行流程理解不够,核心在于线程池的扩容机制:提交任务到线程池后,首先是放入等待队列,只有等待队列满了之后,才会创建非核心线程!!!
当达到最大线程(无空闲线程)以及队列满了之后,再提交任务时就会默认抛出中止异常(即AbortPolicy策略)。
总结:
1、使用定时线程池一定要使用try-catch语句,保证不会因为任务执行时候业务抛出异常,停止后续的任务
2、注意线程池的构造参数
1)一般来说核心线程数不要设置为1,因为我们使用线程池的目的一般有两个,一是让任务异步执行,二是让多个任务可以不并行执行。至于通过堆积任务排队执行实际上并不是大部分业务想要的特性。
那么如果把核心线程池设置为1,那么如果任务数量增加,但是没有达到队列上限,就会导致任务始终在排队执行,实际上就是串行,这和我们的目的相悖。
2)设置合理的任务等待队列长度,如果太长会导致无法触发非核心线程的创建,如果太短会导致经常触发线程池拒绝策略
3)如果担心核心线程过多,可以设置合适的线程销毁时间,并允许核心线程销毁
4)设置合理的提交拒绝策略,默认是中止策略(AbortPolicy),另外三种是主线程执行(CallerRunsPolicy)、丢弃策略(DiscardPolicy)、和丢弃最旧的任务策略(DiscardOldestPolicy)
推荐使用方法是使用中止策略,并在提交任务时增加try-catch语句,如果提交任务时报错,则打印提交失败的任务或丢到补偿机制的逻辑中。
5)特别是在使用定时线程池时,应该形成肌肉记忆和条件反射,首要注意点就是防止任务停止执行,所以一定要增加异常捕获机制