7. Ext系列文件系统
1.理解硬件
• 机械磁盘是计算机中唯⼀的⼀个机械设备
• 磁盘--- 外设
• 慢
• 容量⼤,价格便宜1.1磁盘的物理结构
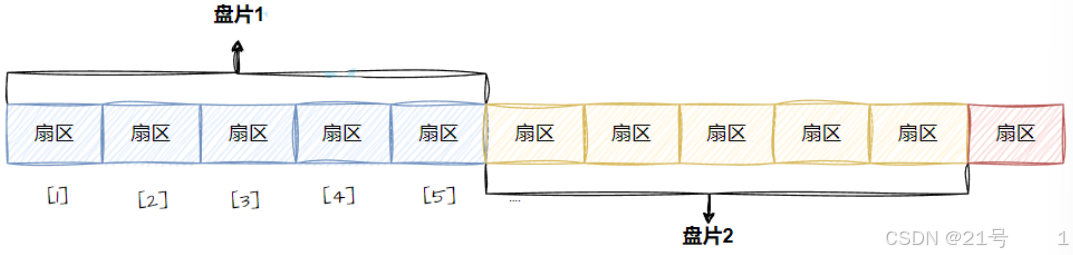
扇区:是磁盘存储数据的基本单位,512字节,块设备


如何定位一个扇区呢?
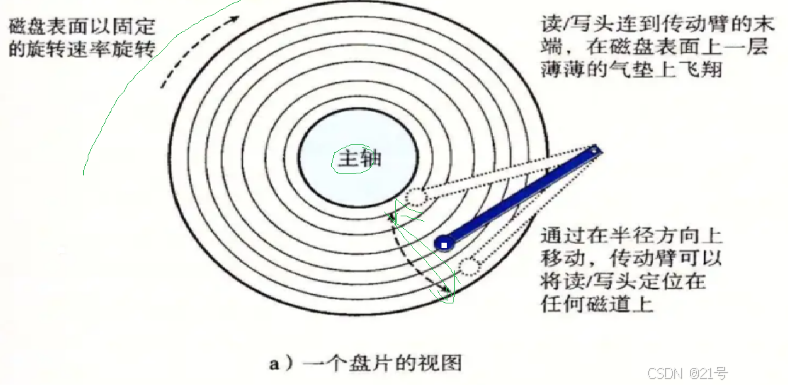
1.先定位磁头(header)
2.确定磁头要访问哪一个柱面(磁道) (cylinder)
3.定位一个扇区(sector)
总结:CHS地址定位
磁头左右摆动,本质是在定位哪一个磁道(柱面);磁盘旋转的本质:是确定了哪一个磁道(柱面),定位该磁道(柱面上)的哪一个扇区。
• 扇区是从磁盘读出和写⼊信息的最⼩单位,通常⼤⼩为 512 字节。
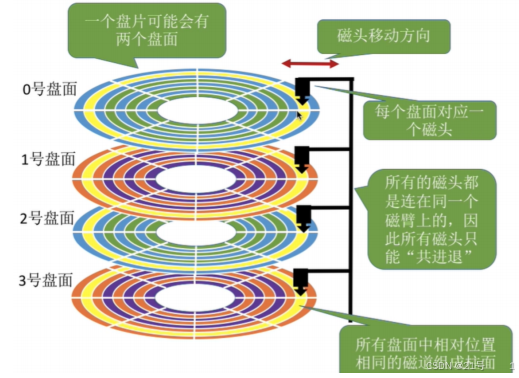
• 磁头(head)数:每个盘⽚⼀般有上下两⾯,分别对应1个磁头,共2个磁头
• 磁道(track)数:磁道是从盘⽚外圈往内圈编号0磁道,1磁道...,靠近主轴的同⼼圆⽤于停靠磁
头,不存储数据
• 柱⾯(cylinder)数:磁道构成柱⾯,数量上等同于磁道个数
• 扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同
• 圆盘(platter)数:就是盘⽚的数量
• 磁盘容量=磁头数 × 磁道(柱⾯)数 × 每道扇区数 × 每扇区字节数
• 细节:传动臂上的磁头是共进退的1.2 磁盘的逻辑结构

磁带上⾯可以存储数据,我们可以把磁带“拉直”,形成线性结构


1.某⼀盘⾯的某⼀个磁道展开:(即一维数组)

2.整个磁盘所有盘⾯的同⼀个磁道,即柱⾯展开:(即二维数组)
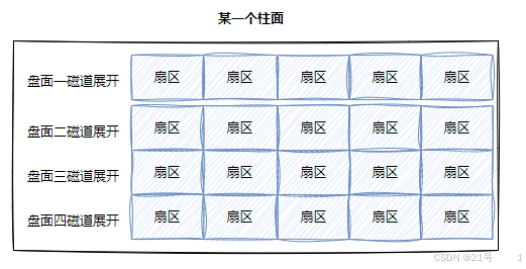
3. 整盘:(三维数组!!!)(想山楂卷一下就懂了)

所以如何在磁盘上定位任意个扇区??-》C,H,S-》就是三维数组的下标!
而在C,C++中抽象的三维数组其实是一块块的一维数组,所以LBA本质是:一维数组的下标,转换成为三个数字!

1.3 CHS && LBA地址
CHS转成LBA:
• 磁头数*每磁道扇区数 = 单个柱⾯的扇区总数
• LBA = 柱⾯号C*单个柱⾯的扇区总数 + 磁头号H*每磁道扇区数 + 扇区号S - 1
• 即:LBA = 柱⾯号C*(磁头数*每磁道扇区数) + 磁头号H*每磁道扇区数 + 扇区号S - 1
• 扇区号通常是从1开始的,⽽在LBA中,地址是从0开始的
• 柱⾯和磁道都是从0开始编号的
• 总柱⾯,磁道个数,扇区总数等信息,在磁盘内部会⾃动维护,上层开机的时候,会获取到这些参
数。
LBA转成CHS:
• 柱⾯号C = LBA // (磁头数*每磁道扇区数)【就是单个柱⾯的扇区总数】
• 磁头号H = (LBA % (磁头数*每磁道扇区数)) // 每磁道扇区数
• 扇区号S = (LBA % 每磁道扇区数) + 1
• "//": 表⽰除取整
所以:从此往后,在磁盘使⽤者看来,根本就不关⼼CHS地址,⽽是直接使⽤LBA地址,磁盘内部⾃⼰
转换。所以:
从现在开始,磁盘就是⼀个 元素为扇区 的⼀维数组,数组的下标就是每⼀个扇区的LBA地址。OS使⽤
磁盘,就可以⽤⼀个数字访问磁盘扇区了。2.引入文件系统
2.1 块的概念
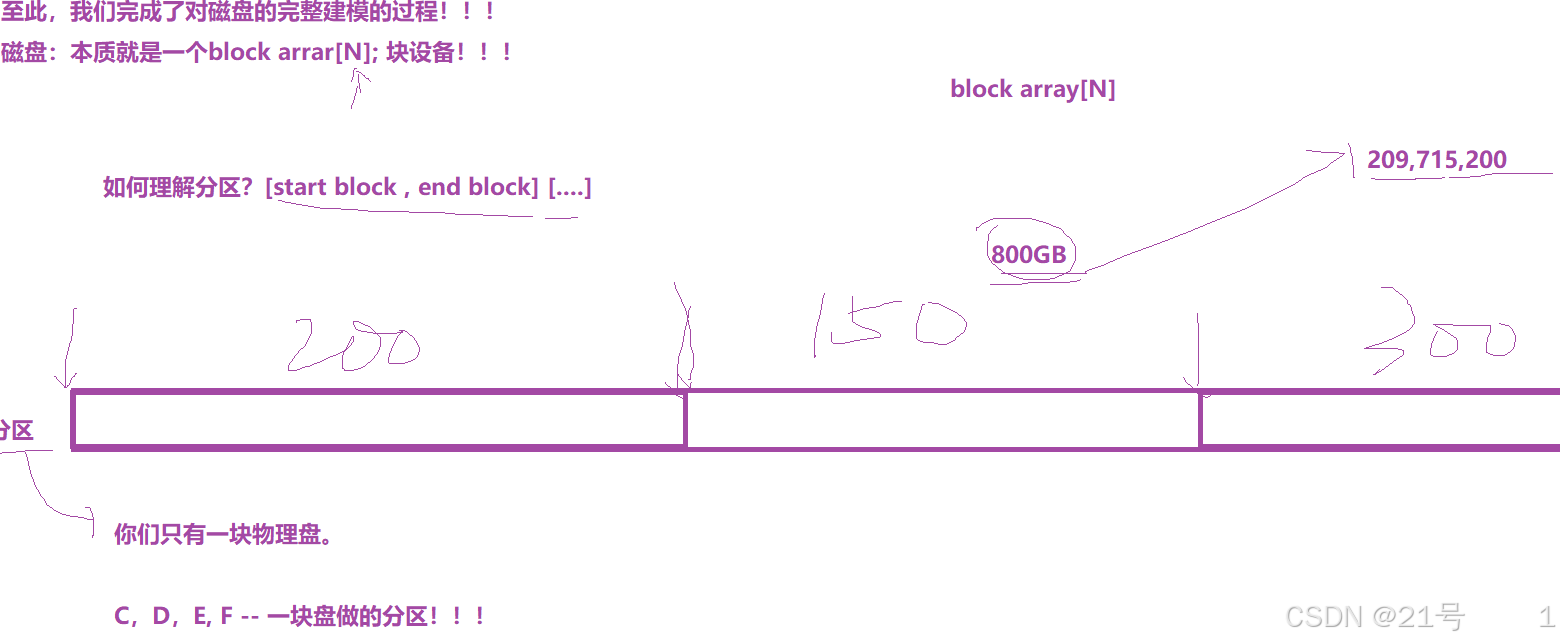
注意:
• 磁盘就是⼀个三维数组,我们把它看待成为⼀个"⼀维数组",数组下标就是LBA,每个元素都是扇
区
• 每个扇区都有LBA,那么8个扇区⼀个块,每⼀个块的地址我们也能算出来。
• 知道LBA:块号 = LBA/8
• 知道块号:LAB=块号*8 + n. (n是块内第⼏个扇区)2.2 “分区”概念
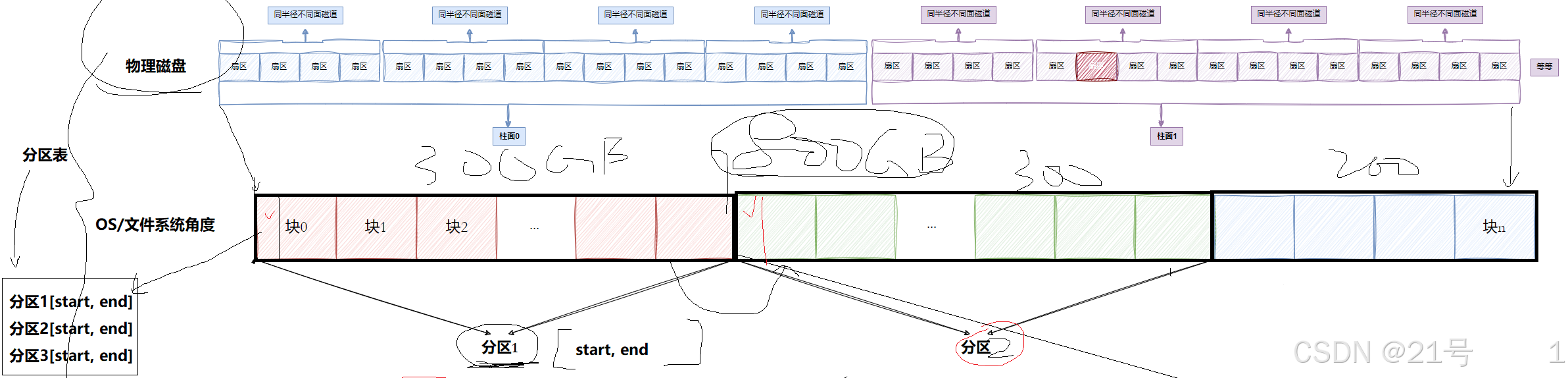
注意:
• 柱⾯⼤⼩⼀致,扇区个位⼀致,那么其实只要知道每个分区的起始和结束柱⾯号,知道每
⼀个柱⾯多少个扇区,那么该分区多⼤,其实和解释LBA是多少也就清楚了2.3 “inode”概念
ls -l读取存储在磁盘上的⽂件信息,然后显⽰出来
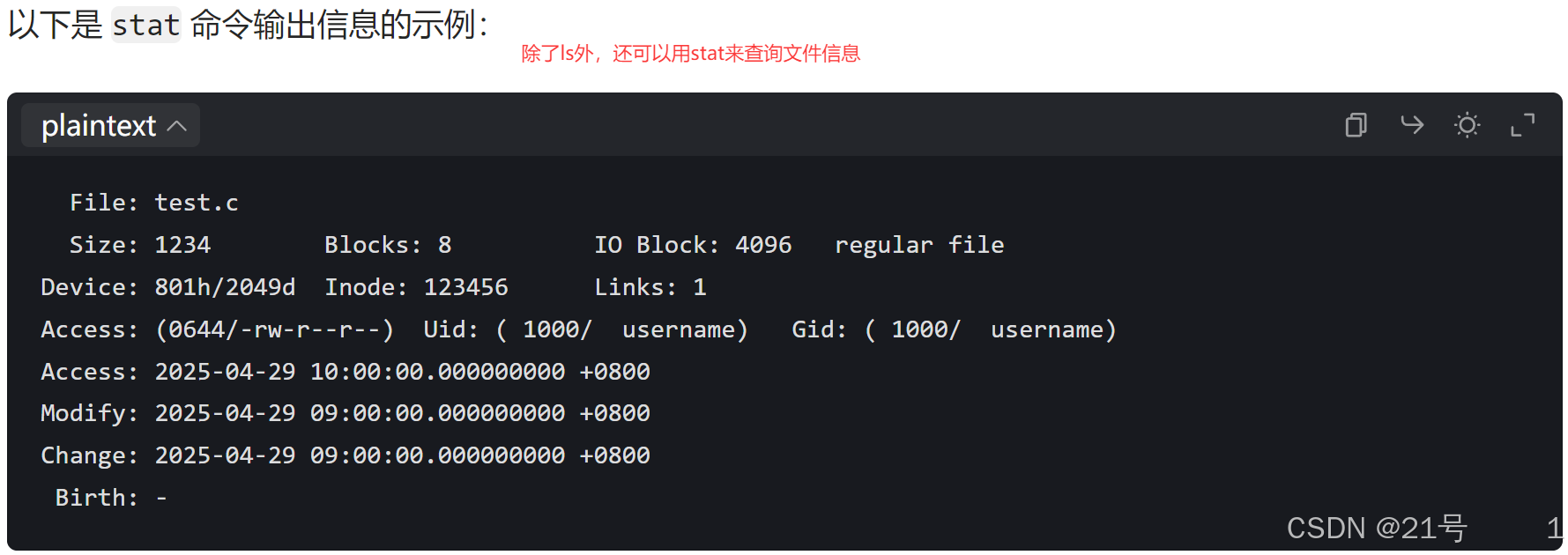 文件数据都存储在“块”中,那么很显然,我们还必须找到⼀个地⽅储存⽂件的元信息(属性信息),⽐如⽂件的创建者、⽂件的创建⽇期、⽂件的⼤⼩等等。这种储存⽂件元信息的区域就叫做inode,中⽂译名为”索引节点”。
文件数据都存储在“块”中,那么很显然,我们还必须找到⼀个地⽅储存⽂件的元信息(属性信息),⽐如⽂件的创建者、⽂件的创建⽇期、⽂件的⼤⼩等等。这种储存⽂件元信息的区域就叫做inode,中⽂译名为”索引节点”。
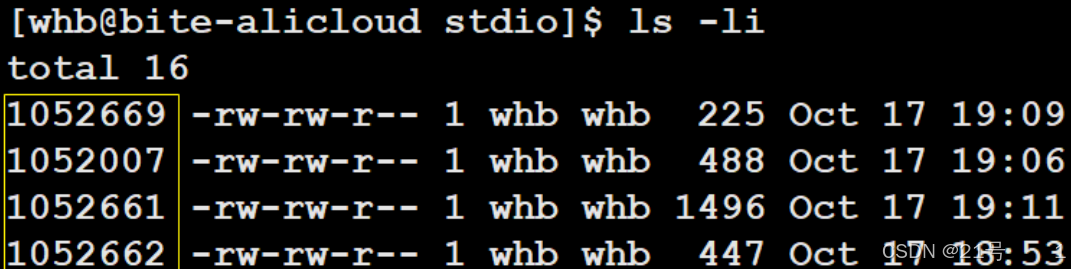
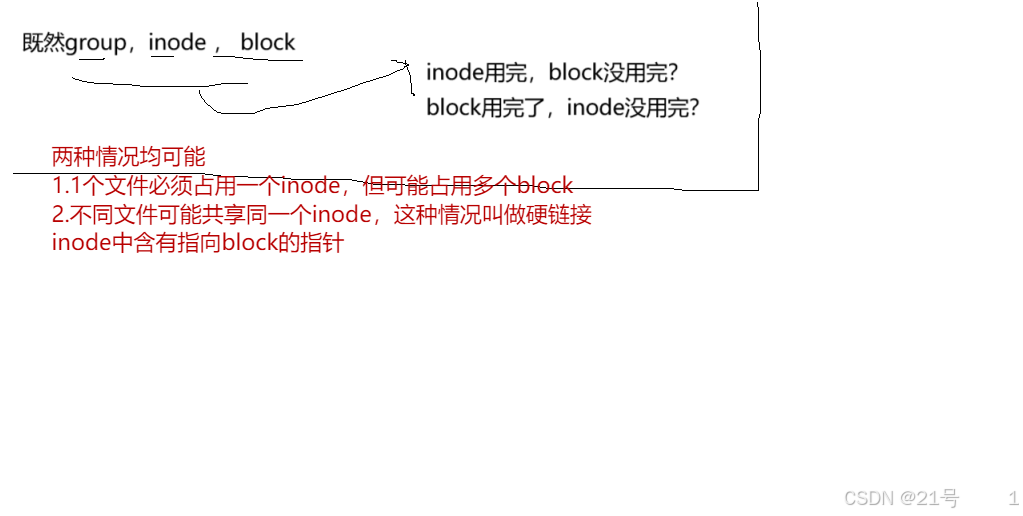
每⼀个⽂件都有对应的inode,⾥⾯包含了与该⽂件有关的⼀些信息。一个文件,可能对应0或多个data block,Linux中,文件名不能也不在inode中保存!!!
• Linux下⽂件的存储是属性和内容分离存储的
• Linux下,保存⽂件属性的集合叫做inode,⼀个⽂件,⼀个inode,inode内有⼀个唯⼀
的标识符,叫做inode号(int inode _number)/*
* Structure of an inode on the disk
*/
struct ext2_inode {__le16 i_mode; /* File mode */__le16 i_uid; /* Low 16 bits of Owner Uid */__le32 i_size; /* Size in bytes */__le32 i_atime; /* Access time */__le32 i_ctime; /* Creation time */__le32 i_mtime; /* Modification time */__le32 i_dtime; /* Deletion Time */__le16 i_gid; /* Low 16 bits of Group Id */__le16 i_links_count; /* Links count */__le32 i_blocks; /* Blocks count */__le32 i_flags; /* File flags */
union {struct {__le32 l_i_reserved1;} linux1;struct {__le32 h_i_translator;} hurd1;struct {__le32 m_i_reserved1;} masix1;} osd1; /* OS dependent 1 */
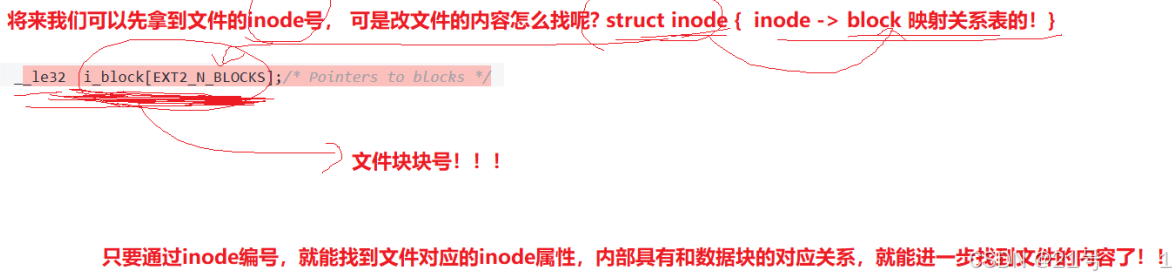
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl; /* File ACL */
__le32 i_dir_acl; /* Directory ACL */
__le32 i_faddr; /* Fragment address */
union {struct {__u8 l_i_frag; /* Fragment number */__u8 l_i_fsize; /* Fragment size */__u16 i_pad1;__le16 l_i_uid_high; /* these 2 fields */__le16 l_i_gid_high; /* were reserved2[0] */__u32 l_i_reserved2;} linux2;struct {__u8 h_i_frag; /* Fragment number */__u8 h_i_fsize; /* Fragment size */__le16 h_i_mode_high;__le16 h_i_uid_high;__le16 h_i_gid_high;__le32 h_i_author;} hurd2;struct {__u8 m_i_frag; /* Fragment number */__u8 m_i_fsize; /* Fragment size */__u16 m_pad1;__u32 m_i_reserved2[2];} masix2;} osd2; /* OS dependent 2 */
};
/*
* Constants relative to the data blocks
*/
#define EXT2_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)
备注:EXT2_N_BLOCKS = 15注意:
• ⽂件名属性并未纳⼊到inode数据结构内部
• inode的⼤⼩⼀般是128字节或者256,我们后⾯统⼀128字节
• 任何⽂件的内容⼤⼩可以不同,但是属性⼤⼩⼀定是相同的1. 我们已经知道硬盘是典型的“块”设备,操作系统读取硬盘数据的时候,读取的基本单位 是”块”。“块”⼜是硬盘的每个分区下的结构,难道“块”是随意的在分区上排布的吗?那要怎么找到“块”呢?
3. ext2 文件系统
3.1 宏观认识
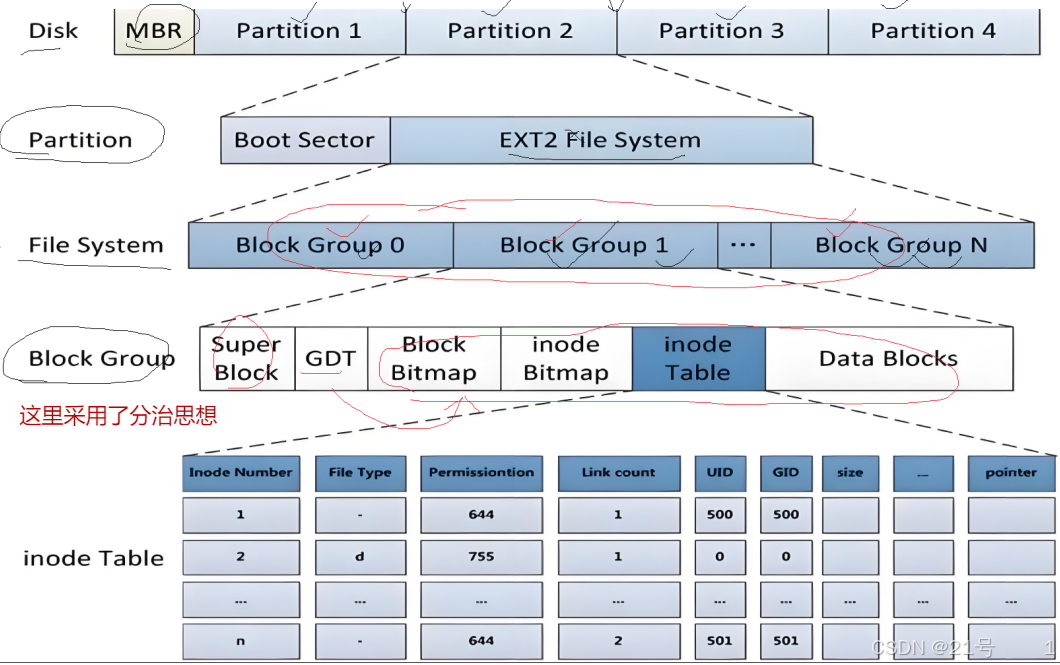
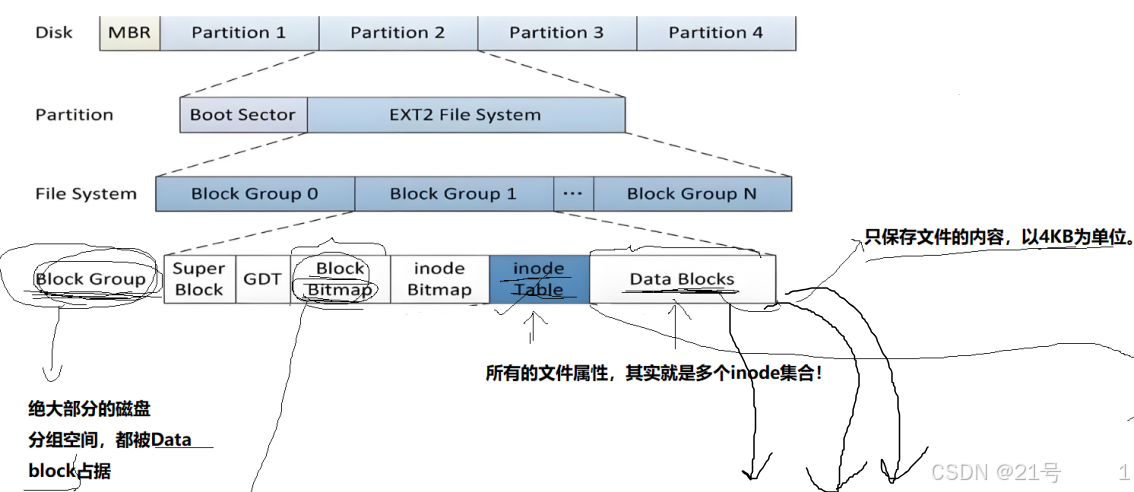
3.2 Block Group
3.3 块组内部构成
super block管理所有组;GDT管理一个组
3.3.1 超级块(Super Block)
1.Super Block,既然是描述一个分区的所有分组的整体情况。sb为什么会在一个块组中?
super block,不仅仅在一个组里,可能会同时存在在多个block group!不一定所有的组都有super block,但是几乎多个组会同时存在同样的sb(出于冗余备份和可靠性考虑)
2.新建一个分区:sb,gdt一定是有效数据!bitmap,block -> 0
给特定分区,写入管理信息,即写入文件系统和分区分组相关的管理数据,文件数据可以暂时不要(这就是格式化的过程);要使用一块硬盘1.分区 2.格式化(给当前分区,写入文件系统)
3.访问一个文件,在分区内,标示该文件的唯一性:inode编号!#删除一个文件(只改位图 -> 计算机删除数据,只要设置数据无效,就可以了),这也是为什么我们删除一个文件后,仍能通过某些手段将该文件找回,因为文件内容根本没删,只是把位图删除了。所以若误删数据了,怎么办?啥都别做,尤其是编译操作。
4.关于inode编号和datablock编号。inode是全分区统一分配的,不是只在分组内有效。inode不能跨区域,一个分区,一个文件系统,互相独立!


6.同一个目录下,文件名不能重复?在指定目录下,新建文件的本质:文件名->inode(把文件名理解为键值)写入当前目录的data block里面 -》这就是为什么在当前目录下新建文件,需要该目录具有w权限了(对目录设置rw本质是约束用户,访问目录的datablock)
超级块在每个块组的开头都有⼀份拷⻉(第⼀个块组必须有,后⾯的块组可以没有)。 为了保证⽂
件系统在磁盘部分扇区出现物理问题的情况下还能正常⼯作,就必须保证⽂件系统的super block信
息在这种情况下也能正常访问。所以⼀个⽂件系统的super block会在多个block group中进⾏备份,
这些super block区域的数据保持⼀致。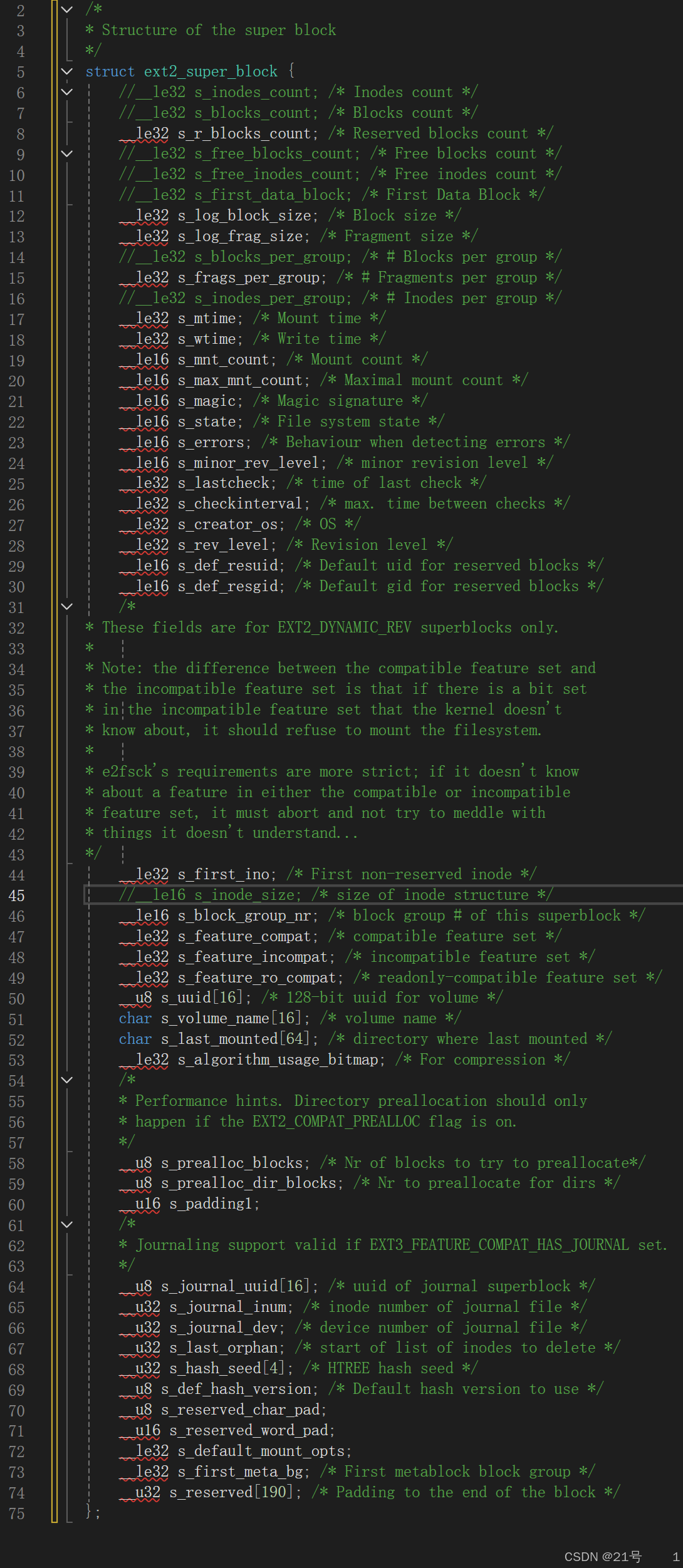
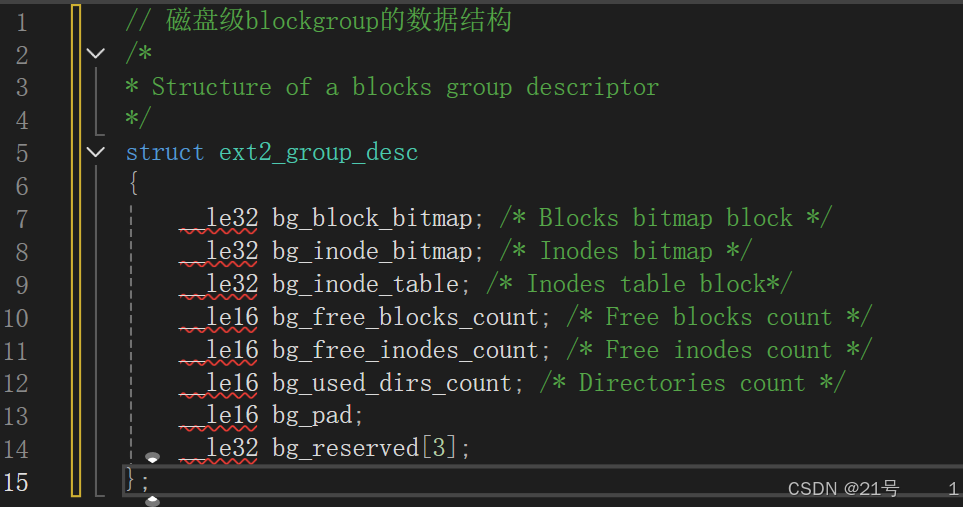
3.3.2 GDT (Group Descriptor Table)
块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储⼀个块组 的描述信息,如在这个块组中从哪⾥开始是inode Table,从哪⾥开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有⼀份拷⻉。
3.3.3 块位图(Block Bitmap)(一个4KB)

3.3.4 inode位图(inode Bitmap)

3.3.5 i节点表(inode Table)
3.3.6 Data Block
数据区:存放⽂件内容,也就是⼀个⼀个的Block。根据不同的⽂件类型有以下⼏种情况:
• 对于普通⽂件,⽂件的数据存储在数据块中。
• 对于⽬录,该⽬录下的所有⽂件名和⽬录名存储在所在⽬录的数据块中,除了⽂件名外,ls -l命令
看到的其它信息保存在该⽂件的inode中。
• Block 号按照分区划分,不可跨分区3.4 inode和datablock映射(弱化)
3.5 目录与文件名
1.我们访问⽂件,都是⽤的⽂件名,没⽤过inode号啊? -》 ⽬录也是⽂件,但是磁盘上没有⽬录的概念,只有⽂件属性+⽂件内容的概念。
2.⽬录是⽂件吗?如何理解? -》 ⽬录的属性不⽤多说,内容保存的是:⽂件名和Inode号的映射关系。
所以,访问⽂件,必须打开当前⽬录,根据⽂件名,获得对应的inode号,然后进⾏⽂件访问
所以,访问⽂件必须要知道当前⼯作⽬录,本质是必须能打开当前⼯作⽬录⽂件,查看⽬录⽂件的
内容!3.6 路径解析

注意:
• 所以,我们知道了:访问⽂件必须要有⽬录+⽂件名=路径的原因
• 根⽬录固定⽂件名,inode号,⽆需查找,系统开机之后就必须知道可是路径谁提供?
• 你访问⽂件,都是指令/⼯具访问,本质是进程访问,进程有CWD!进程提供路径。
• 你open⽂件,提供了路径
可是最开始的路径从哪⾥来?
• 所以Linux为什么要有根⽬录, 根⽬录下为什么要有那么多缺省⽬录?
• 你为什么要有家⽬录,你⾃⼰可以新建⽬录?
• 上⾯所有⾏为:本质就是在磁盘⽂件系统中,新建⽬录⽂件。⽽你新建的任何⽂件,都在你或者系
统指定的⽬录下新建,这不就是天然就有路径了嘛!
• 系统+⽤⼾共同构建Linux路径结构.3.7 路径缓存
问题1:Linux磁盘中,存在真正的⽬录吗?
答案:不存在,只有⽂件。只保存⽂件属性+⽂件内容
问题2:访问任何⽂件,都要从/⽬录开始进⾏路径解析?
答案:原则上是,但是这样太慢,所以Linux会缓存历史路径结构
问题3:Linux⽬录的概念,怎么产⽣的?
答案:打开的⽂件是⽬录的话,由OS⾃⼰在内存中进⾏路径维护linux下访问文件,都必须带路径(无论显示的还是隐式的)这样很慢啊!而且在linux系统里,我们确实看到了目录树??linux系统中,当用户访问指定路径下的文件(包括路上目录,最终的目标文件在内),linux会在你进行路径解析的过程中,在内核中形成目录树和路径缓存!! --目录结构是内存级的!!
linux中,在内核中维护树状路径结构的内核结构体叫做: struct dentry
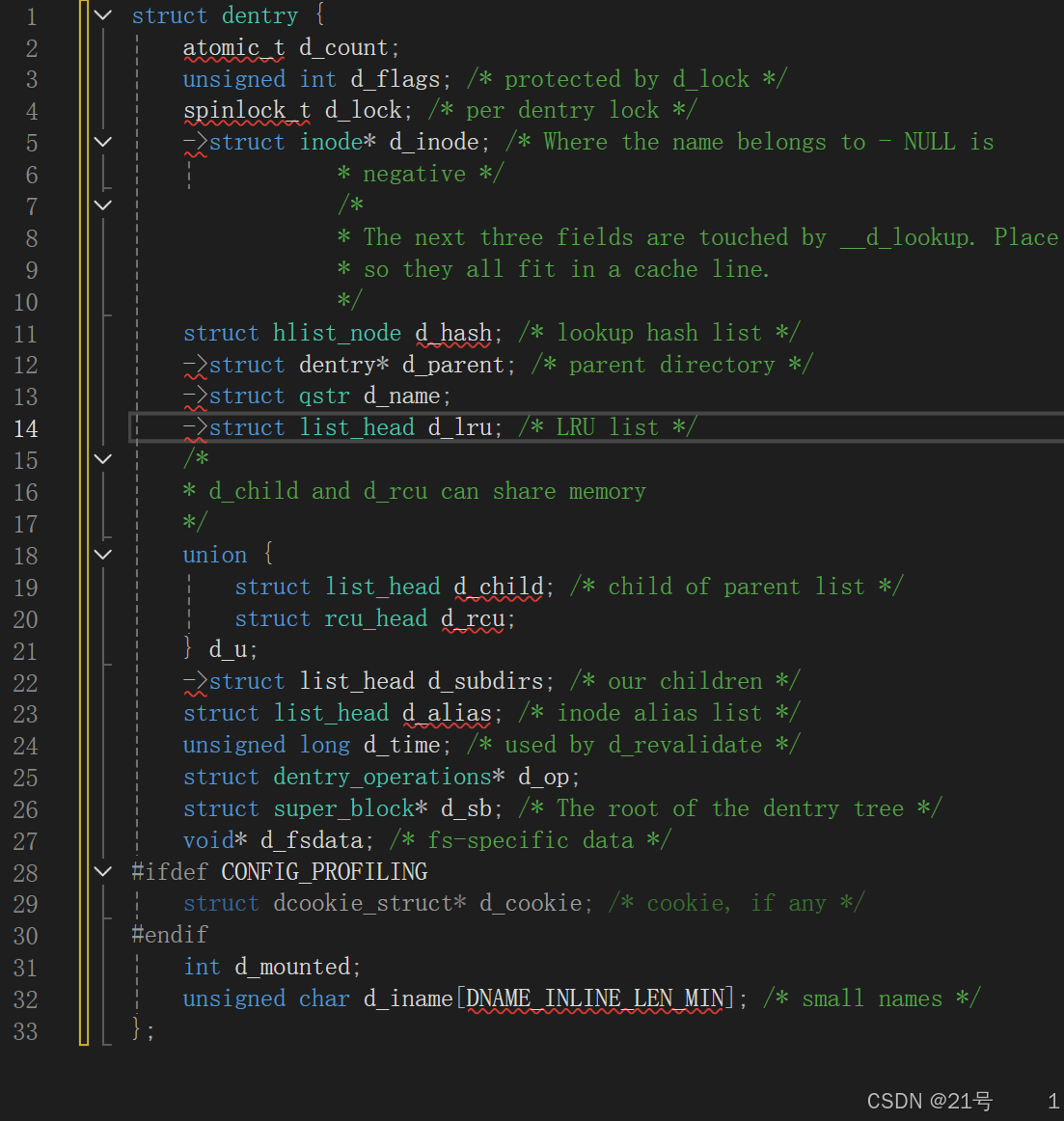
注意:
• 每个⽂件其实都要有对应的dentry结构,包括普通⽂件。这样所有被打开的⽂件,就可以在内存中
形成整个树形结构
• 整个树形节点也同时会⾪属于LRU(Least Recently Used,最近最少使⽤)结构中,进⾏节点淘汰
• 整个树形节点也同时会⾪属于Hash,⽅便快速查找
• 更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何⽂件,都在先在这
棵树下根据路径进⾏查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry
结构,缓存新路径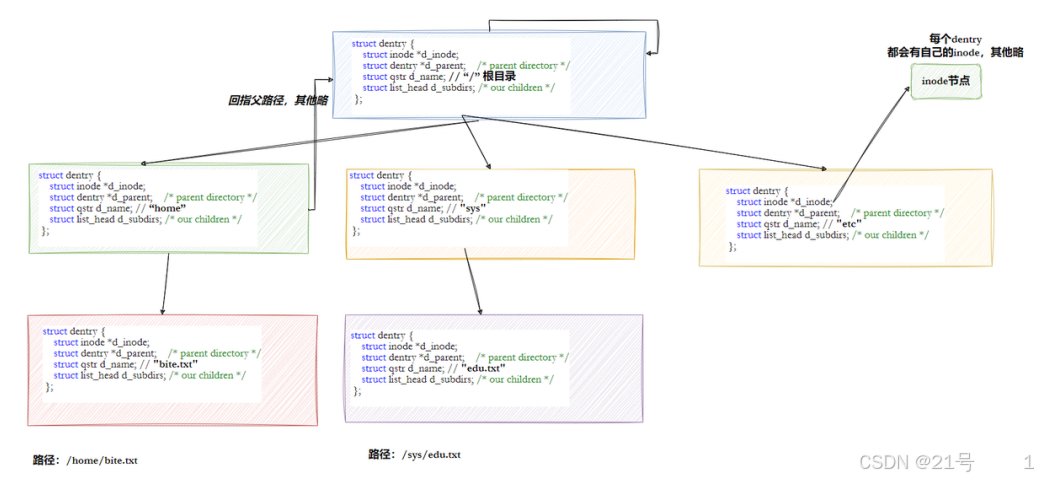
所以,你在做路径解析时,只有第一次是慢的,第二次的时候,第n次的时候,路径解析时,优先会从dentry树结构中进行解析;普通文件和空目录,就是叶子节点!!
3.8 挂载分区
• 分区写⼊⽂件系统,⽆法直接使⽤,需要和指定的⽬录关联,进⾏挂载才能使⽤。
• 所以,可以根据访问⽬标⽂件的"路径前缀"准确判断我在哪⼀个分区。还有一张实验图片
一个磁盘,必须分区格式化,才能具有使用的前提
一个分区,要被真正的使用,必须挂载到指定的目录下才可以
3.9 总结
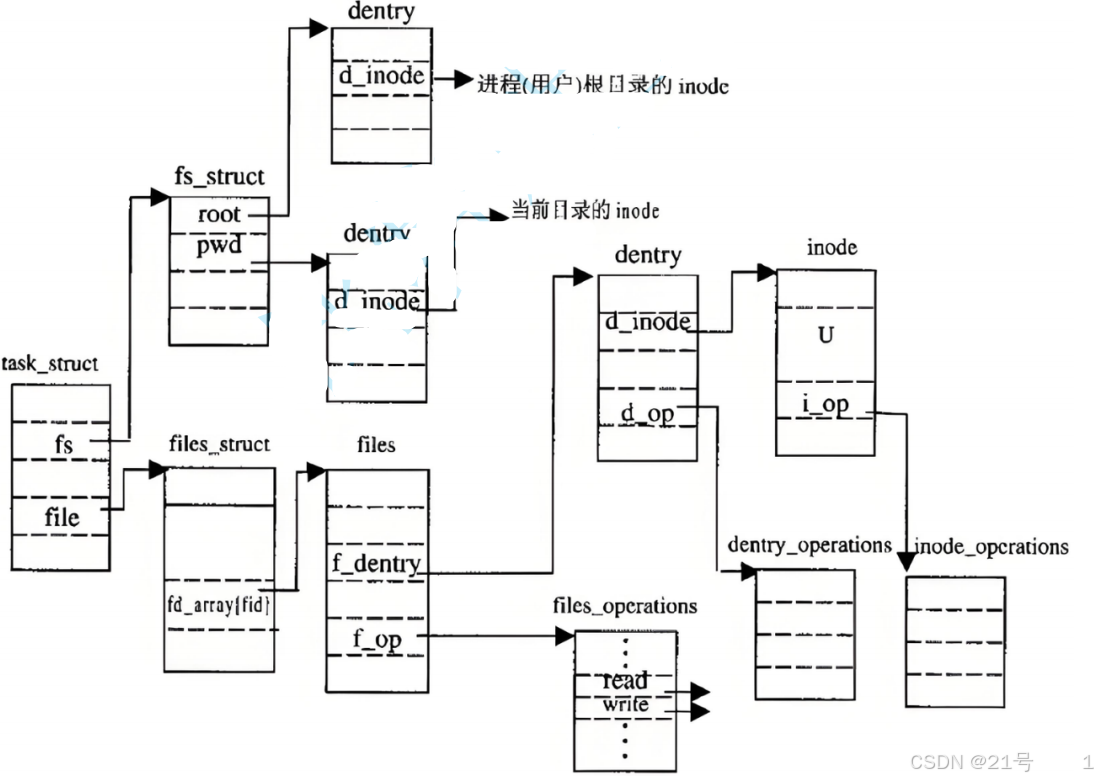
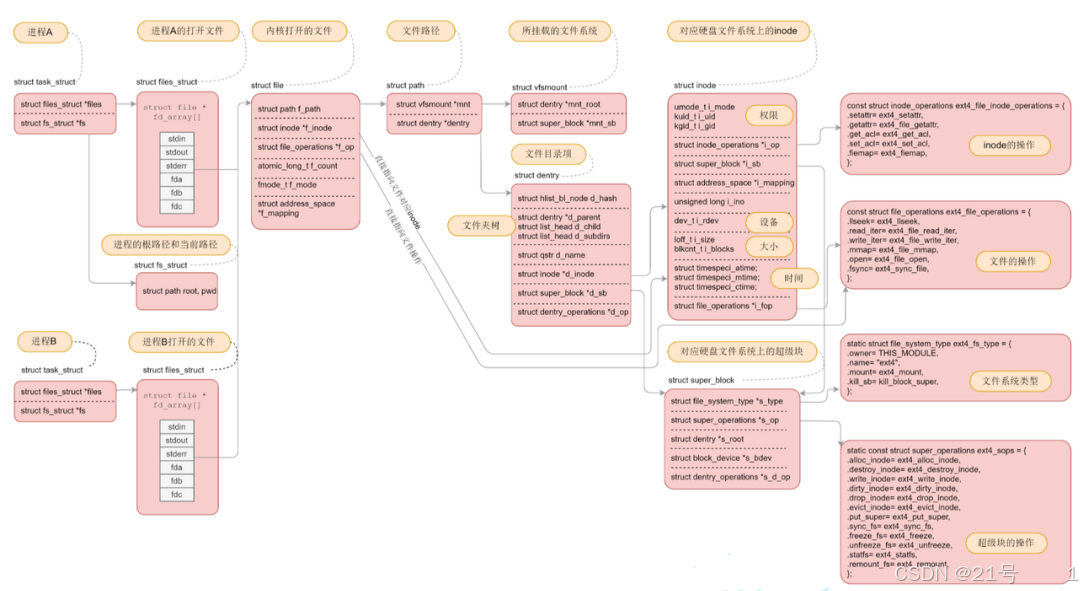
4.软硬链接
4.1 区别 原理
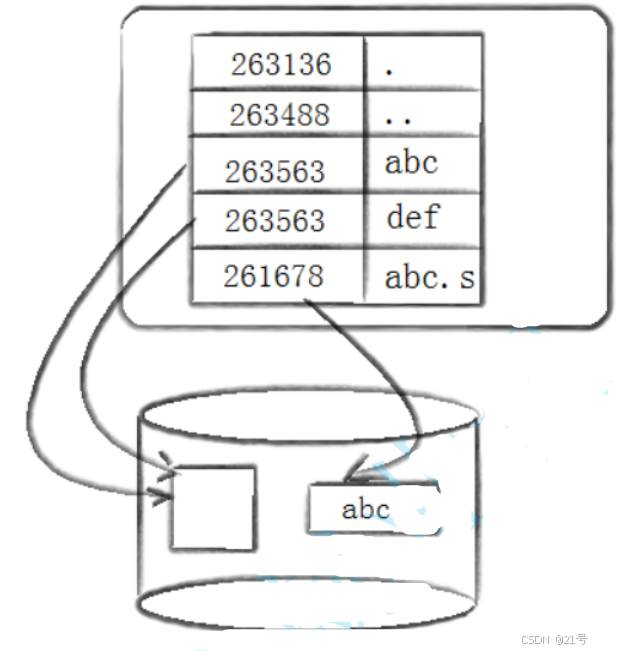
已知,真正找到磁盘上的文件的并不是文件名,而是inode。其实在linux中可以让多个文件名对应于同一个inode

1.可知软链接是一个独立的文件,因为他有独立的inode;软链接相当于windows中的快捷方式,链接文件类型;软链接指向的文件的路径字符串
文件 = 属性 + 内容
2.硬链接不是一个独立的文件,因为他没有独立的inode;他本质是在指定目录下,建立新的文件名和目标inode的映射关系,并没有在系统层面创建新的文件
4.2 应用场景
1.软链接的应用场景之一就是快捷方式,ra用户无感知的进行软件升级
2.硬链接的应用场景:对文件进行备份(重命名?)!!硬链接数本质是有几个文件名指向我们特定的inode(引用计数)
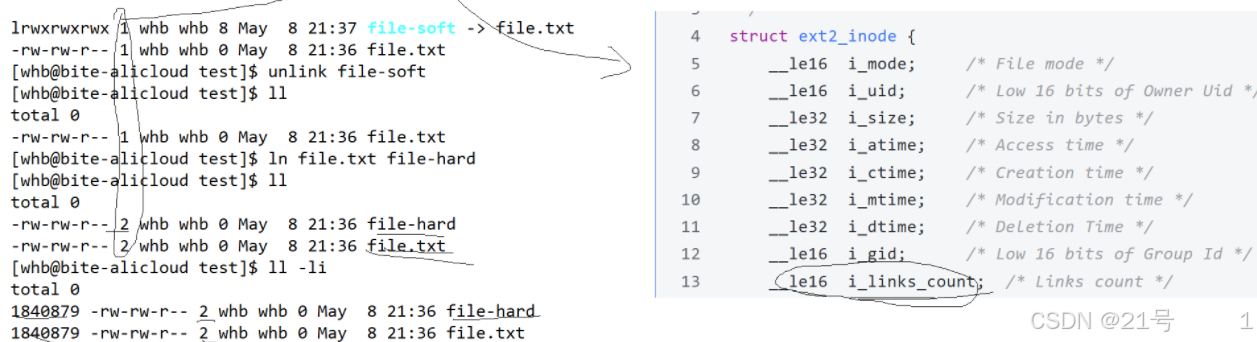
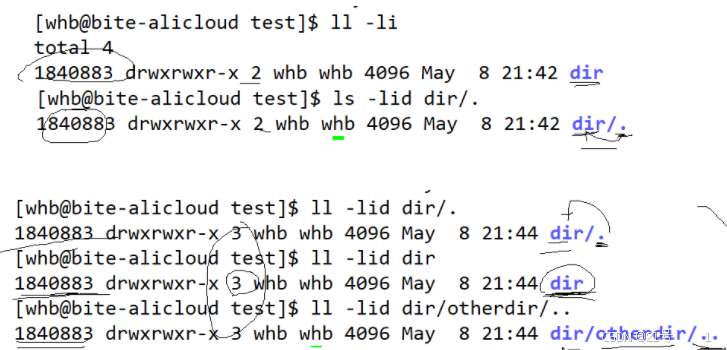 我们发现@1目录中的硬链接数是2,因为有目录本身1个,.也指向目录,总共两个;@2一个目录中含有子目录,则他的硬链接数+1,因为子目录中的..返回上一级目录,..也指向该目录。
我们发现@1目录中的硬链接数是2,因为有目录本身1个,.也指向目录,总共两个;@2一个目录中含有子目录,则他的硬链接数+1,因为子目录中的..返回上一级目录,..也指向该目录。
4.3 注意
我们可以给目录/普通文件设置软连接,但是硬链接,用户层面,不允许对目录设置硬链接!!

