第三章:langchain加载word文档构建RAG检索教程(基于FAISS库为例)
文章目录
- 前言
- 一、载入文档(word)
- 1、文档载入代码
- 2、文档载入数据解读(Docx2txtLoader方法)
- 输入数据
- 输出文本内容
- 3、Docx2txtLoader底层代码文档读取解读
- Docx2txtLoader底层源码示例文档读取
- 输出结果
- 二、文本分割
- 1、文本分割代码
- 2、底层代码
- 1、文档输入内容
- 2、split_documents函数源码解读
- 3、create_documents函数源码解读
- split_text函数源码解读
- _split_text_with_regex函数源码解读
- _merge_splits函数源码解读
- 三、文本向量化存储(以faiss库示例)
- 1、使用faiss实现本地向量化代码
- 2、faiss类源码解读
- FAISS类注释翻译
- FAISS类的示意结构
- FAISS类结构示意图
- 3、VectorStore类源码解读
- 四、构建一个完整RAG实现检索的代码Demo
前言
如果你已有了向量embed模型,该如何构建一个检索方法呢?本节就是一个完整的构建教程,使用word文档载入到分块再到向量化,并利用数据库进行检索。我们使用FAISS库来实现这个功能,依然使用langchain款就爱来完成。该代码实现是比较简单的,但这仅仅是给初学者学习的。我们会进一步从底层源码进行解读,给出更深入讲解。
一、载入文档(word)
构建rag需要将现有知识知识转向量化。在此之前需要载入文档,这里将使用word作为列子来载入。而后期你想载入不同模态数据,需要使用不同方式来实现。
1、文档载入代码
我们给出了word文档载入内容,其代码如下:
# 加载Word文档
from langchain_community.document_loaders import Docx2txtLoader
def load_word_document(file_path):# 创建一个Docx2txtLoader对象,用于加载指定路径的Word文档loader = Docx2txtLoader(file_path)# 调用loader对象的load方法,加载文档内容并返回return loader.load()
使用上面代码即可完成。
2、文档载入数据解读(Docx2txtLoader方法)
输入数据
输入数据包含文字,图片,公式以及文档嵌入的公式与页眉。我们需要了解langchain自带文档库Docx2txtLoader解析。我们重点关注其有回车键地方与有公式地方。
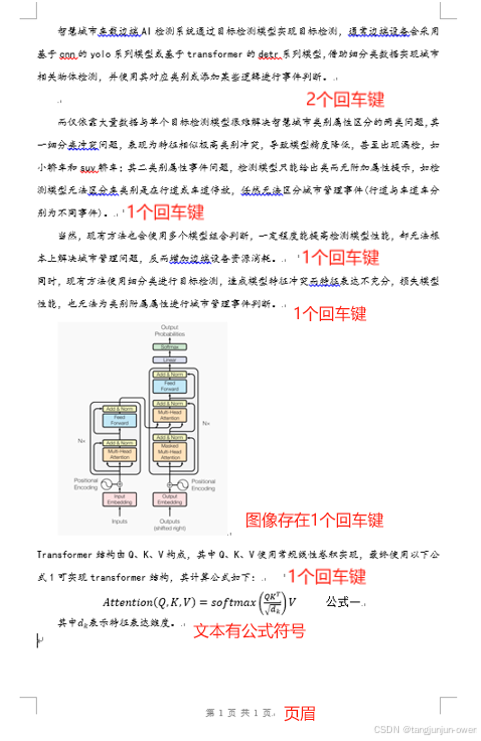
输出文本内容
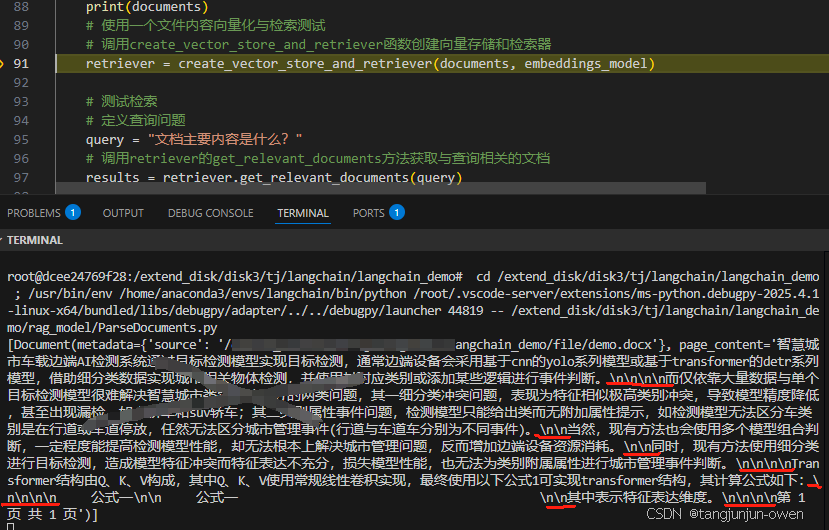
以下就是文本输出内容,我们可以发现,每一个回车键就会有个/n/n表示,所以多少个回车键就有多少个,而且我们可以发现这个不能
3、Docx2txtLoader底层代码文档读取解读
随后,我们根据from langchain_community.document_loaders import Docx2txtLoader其源码不断挖掘,深入到底层逻辑,我们将其源码重要内容摘出来构建了一个示例代码。
Docx2txtLoader底层源码示例文档读取
你会发现实际是用python自带方法进行解析的,而且是xml方式来解析。我将其代码构成了一个示例,如下代码:
import argparse
import re
import xml.etree.ElementTree as ET
import zipfile
import os
import sysnsmap = {'w': 'http://schemas.openxmlformats.org/wordprocessingml/2006/main'}
def qn(tag):"""Stands for 'qualified name', a utility function to turn a namespaceprefixed tag name into a Clark-notation qualified tag name for lxml. Forexample, ``qn('p:cSld')`` returns ``'{http://schemas.../main}cSld'``.Source: https://github.com/python-openxml/python-docx/"""prefix, tagroot = tag.split(':')uri = nsmap[prefix]return '{{{}}}{}'.format(uri, tagroot)def xml2text(xml):"""A string representing the textual content of this run, with contentchild elements like ``<w:tab/>`` translated to their Pythonequivalent.Adapted from: https://github.com/python-openxml/python-docx/"""text = u''root = ET.fromstring(xml)for child in root.iter():if child.tag == qn('w:t'):t_text = child.texttext += t_text if t_text is not None else ''elif child.tag == qn('w:tab'):text += '\t'elif child.tag in (qn('w:br'), qn('w:cr')):text += '\n'elif child.tag == qn("w:p"):text += '\n\n'return textdef process(docx, img_dir=None):text = u''# unzip the docx in memoryzipf = zipfile.ZipFile(docx)filelist = zipf.namelist()# get header text# there can be 3 header files in the zipheader_xmls = 'word/header[0-9]*.xml'for fname in filelist:if re.match(header_xmls, fname):text += xml2text(zipf.read(fname))# get main textdoc_xml = 'word/document.xml'text += xml2text(zipf.read(doc_xml))# get footer text# there can be 3 footer files in the zipfooter_xmls = 'word/footer[0-9]*.xml'for fname in filelist:if re.match(footer_xmls, fname):text += xml2text(zipf.read(fname))if img_dir is not None:# extract imagesfor fname in filelist:_, extension = os.path.splitext(fname)if extension in [".jpg", ".jpeg", ".png", ".bmp"]:dst_fname = os.path.join(img_dir, os.path.basename(fname))with open(dst_fname, "wb") as dst_f:dst_f.write(zipf.read(fname))zipf.close()return text.strip()if __name__ == '__main__':text = process("/extend_disk/disk3/tj/langchain/langchain_demo/file/demo.docx")# sys.stdout.write(text.encode('utf-8'))print(text)pass而源码真正底层位置如下图:
注:之所以摘出来,是告诉读者,你可以任意修改!并给出word本质内容。
输出结果
使用上面代码得到输出结果如下,这个结果和Docx2txtLoader是一样的,如下:
'智慧城市车载边端AI检测系统通过目标检测模型实现目标检测,通常边端设备会采用基于cnn的yolo系列模型或基于transformer的detr系列模型,借助细分类数据实现城市相关物体检测,并使用其对应类别或添加某些逻辑进行事件判断。\n\n\n\n而仅依靠大量数据与单个目标检测模型很难解决智慧城市类别属性区分的两类问题,其一细分类冲突问题,表现为特征相似极高类别冲突,导致模型精度降低,甚至出现漏检,如小轿车和suv轿车;其二类别属性事件问题,检测模型只能给出类而无附加属性提示,如检测模型无法区分车类别是在行道或车道停放,任然无法区分城市管理事件(行道与车道车分别为不同事件)。\n\n当然,现有方法也会使用多个模型组合判断,一定程度能提高检测模型性能,却无法根本上解决城市管理问题,反而增加边端设备资源消耗。\n\n同时,现有方法使用细分类进行目标检测,造成模型特征冲突而特征表达不充分,损失模型性能,也无法为类别附属属性进行城市管理事件判断。\n\n\n\nTransformer结构由Q、K、V构成,其中Q、K、V使用常规线性卷积实现,最终使用以下公式1可实现transformer结构,其计算公式如下:\n\n\n\n 公式一\n\n 公式一 \n\n其中表示特征表达维度。\n\n\n\n第 1 页 共 1 页'
二、文本分割
对于读取的文档,转成了text格式内容,我们需要进行文本分割。也就是将一个大文本切分成不同小块的文本,这样才能更方便的存入数据库中。大多情况都是纯文本进行分割。
1、文本分割代码
我们采用别人方法来调用分割文本split。我们给出了from langchain.text_splitter import CharacterTextSplitter方法的文本分割方法,其代码如下:
from langchain.text_splitter import CharacterTextSplitter
# 初始化文本分割器
def init_text_splitter(**kwargs):# separator="\n", chunk_size=1000, chunk_overlap=200separator,chunk_size,chunk_overlap = kwargs.get("separator","\n"),kwargs.get("chunk_size",1000),kwargs.get("chunk_overlap",200)text_splitter = CharacterTextSplitter(separator=separator, chunk_size=chunk_size, chunk_overlap=chunk_overlap)return text_splitter# 创建向量存储并初始化检索器
def get_texts_split(documents, **kwargs):# 定义一个函数,用于将文档列表分割成文本片段# 参数documents是一个包含多个文档的列表# 参数kwargs是一个关键字参数字典,用于传递给文本分割器的初始化函数text_splitter = init_text_splitter(**kwargs)# 调用init_text_splitter函数,传入kwargs参数字典,初始化一个文本分割器对象split_texts = text_splitter.split_documents(documents)# split_documents方法的具体实现也不在当前代码中,它可能是用于将文档分割成多个文本片段的方法return split_texts
自然结果也是列表,每个元素是Document的类,最主要是包含metadata与page_content内容,其结果如下:
而元素内容如下:
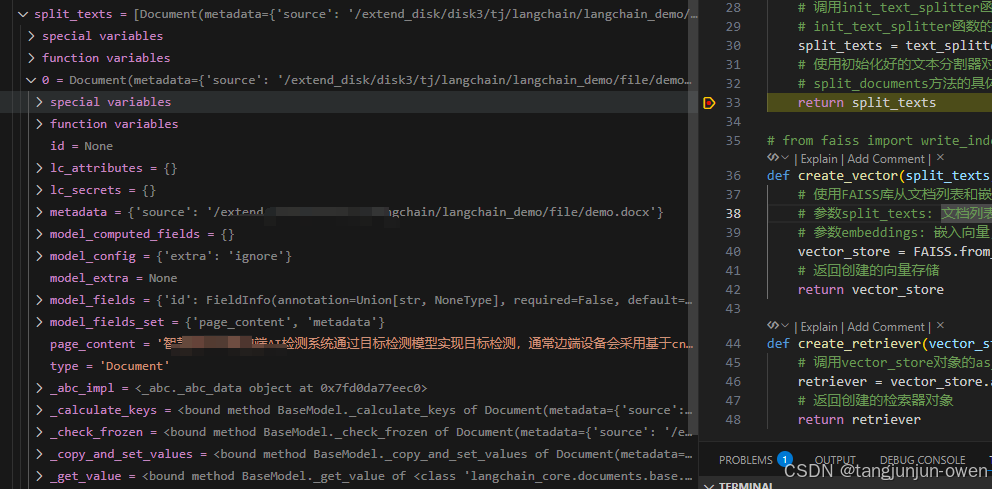
2、底层代码
上面代码给出了文本分割内容,紧接着我们从底层代码来讲解其运行机理。我们看到text_splitter.split_documents(documents)调用,我们来解释split_documents方法。
1、文档输入内容
我们首先知道documents输入是一个列表,而列表的元素是Document类(如下源码所示)。显然metadata与page_content很重要,前者是个字典,主要附加来源等信息,后这是内容。
class BaseMedia(Serializable):id: Optional[str] = Nonemetadata: dict = Field(default_factory=dict)"""Arbitrary metadata associated with the content."""@field_validator("id", mode="before")def cast_id_to_str(cls, id_value: Any) -> Optional[str]:if id_value is not None:return str(id_value)else:return id_valueclass Document(BaseMedia):page_content: str"""String text."""type: Literal["Document"] = "Document"def __init__(self, page_content: str, **kwargs: Any) -> None:super().__init__(page_content=page_content, **kwargs) # type: ignore[call-arg]@classmethoddef is_lc_serializable(cls) -> bool:"""Return whether this class is serializable."""return True@classmethoddef get_lc_namespace(cls) -> list[str]:"""Get the namespace of the langchain object."""return ["langchain", "schema", "document"]def __str__(self) -> str:if self.metadata:return f"page_content='{self.page_content}' metadata={self.metadata}"else:return f"page_content='{self.page_content}'"
page_content内容如下:
'智慧城市车载边端AI检测系统通过目标检测模型实现目标检测,通常边端设备会采用基于cnn的yolo系列模型或基于transformer的detr系列模型,借助细分类数据实现城市相关物体检测,并使用其对应类别或添加某些逻辑进行事件判断。\n\n\n\n而仅依靠大量数据与单个目标检测模型很难解决智慧城市类别属性区分的两类问题,其一细分类冲突问题,表现为特征相似极高类别冲突,导致模型精度降低,甚至出现漏检,如小轿车和suv轿车;其二类别属性事件问题,检测模型只能给出类而无附加属性提示,如检测模型无法区分车类别是在行道或车道停放,任然无法区分城市管理事件(行道与车道车分别为不同事件)。\n\n当然,现有方法也会使用多个模型组合判断,一定程度能提高检测模型性能,却无法根本上解决城市管理问题,反而增加边端设备资源消耗。\n\n同时,现有方法使用细分类进行目标检测,造成模型特征冲突而特征表达不充分,损失模型性能,也无法为类别附属属性进行城市管理事件判断。\n\n\n\nTransformer结构由Q、K、V构成,其中Q、K、V使用常规线性卷积实现,最终使用以下公式1可实现transformer结构,其计算公式如下:\n\n\n\n 公式一\n\n 公式一 \n\n其中表示特征表达维度。\n\n\n\n第 1 页 共 1 页'
metadata内容如下:
{'source': '/langchain_demo/file/demo.docx'}
具体而言,如下图:
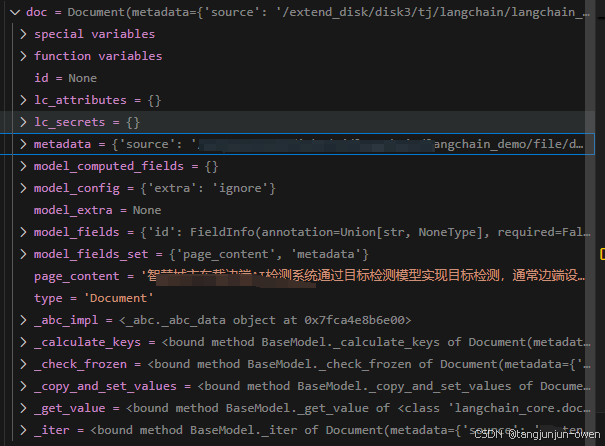
2、split_documents函数源码解读
documents经过下面函数将其内容给到texts, metadatas列表,保存内容如上所示。然后进入self.create_documents(texts, metadatas=metadatas)代码。
def split_documents(self, documents: Iterable[Document]) -> List[Document]:"""Split documents."""texts, metadatas = [], []for doc in documents:texts.append(doc.page_content)metadatas.append(doc.metadata)return self.create_documents(texts, metadatas=metadatas)
3、create_documents函数源码解读
随后定义了一个documents空列表,再进行text循环,首先是进入split_text函数,该函数是一个切割再合并方式。切割是基于某个字符标志进行,一般以/n作为切割,可以将一个文本切割多个文本列表;合并是将切割列表按照chunk size作为依据进行合并,一般若未超过chunk size则合并成一整段文本,而合并连接是使用separate变量内容,而超过chunk size则进行文本分段,可能返回为多个元素的列表。最后,返回chunk size会被保存到Document类中,若被切割就会依次保存,再将所有内容都会保存到documents列表中(其代码)。其代码如下:
def create_documents(self, texts: List[str], metadatas: Optional[List[dict]] = None
) -> List[Document]:"""Create documents from a list of texts."""_metadatas = metadatas or [{}] * len(texts)documents = []for i, text in enumerate(texts):index = 0previous_chunk_len = 0for chunk in self.split_text(text):metadata = copy.deepcopy(_metadatas[i])if self._add_start_index:offset = index + previous_chunk_len - self._chunk_overlapindex = text.find(chunk, max(0, offset))metadata["start_index"] = indexprevious_chunk_len = len(chunk)new_doc = Document(page_content=chunk, metadata=metadata)documents.append(new_doc)return documents
注:使用了2个for循环,第一个是texts文本的,第二个是条件chunk size进行的切割for循环。
split_text函数源码解读
这个函数主要是对每个text元素进行分割,首先使用separator的分割符号进行分割,这里默认是/n符号,这个再初始化地方设置。
def split_text(self, text: str) -> List[str]:"""Split incoming text and return chunks."""# First we naively split the large input into a bunch of smaller ones.separator = (self._separator if self._is_separator_regex else re.escape(self._separator))splits = _split_text_with_regex(text, separator, self._keep_separator)_separator = "" if self._keep_separator else self._separatorreturn self._merge_splits(splits, _separator)
使用分割符号分割结果如下:
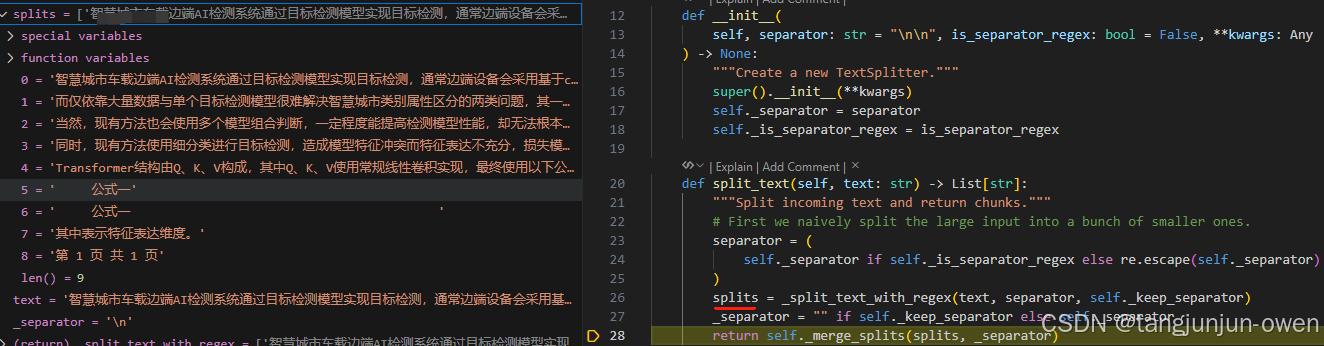
_split_text_with_regex函数源码解读
不说了,这个是separator符号来切割的,而实现这个功能就是下面代码,如下:
def _split_text_with_regex(text: str, separator: str, keep_separator: Union[bool, Literal["start", "end"]]
) -> List[str]:# Now that we have the separator, split the textif separator:if keep_separator:# The parentheses in the pattern keep the delimiters in the result._splits = re.split(f"({separator})", text)splits = (([_splits[i] + _splits[i + 1] for i in range(0, len(_splits) - 1, 2)])if keep_separator == "end"else ([_splits[i] + _splits[i + 1] for i in range(1, len(_splits), 2)]))if len(_splits) % 2 == 0:splits += _splits[-1:]splits = ((splits + [_splits[-1]])if keep_separator == "end"else ([_splits[0]] + splits))else:splits = re.split(separator, text)else:splits = list(text)return [s for s in splits if s != ""]
_merge_splits函数源码解读
这个函数我看了半天,不是特别明白。但大致逻辑是对splits列表文本进行合并,但超过既定的chunk_size尺寸,就会被切割。而合并句子使用separator作为连接符号,该代码如下所示:
def _merge_splits(self, splits: Iterable[str], separator: str) -> List[str]:# We now want to combine these smaller pieces into medium size# chunks to send to the LLM.separator_len = self._length_function(separator)docs = []current_doc: List[str] = []total = 0for d in splits:_len = self._length_function(d)if (total + _len + (separator_len if len(current_doc) > 0 else 0)> self._chunk_size):if total > self._chunk_size:logger.warning(f"Created a chunk of size {total}, "f"which is longer than the specified {self._chunk_size}")if len(current_doc) > 0:doc = self._join_docs(current_doc, separator)if doc is not None:docs.append(doc)# Keep on popping if:# - we have a larger chunk than in the chunk overlap# - or if we still have any chunks and the length is longwhile total > self._chunk_overlap or (total + _len + (separator_len if len(current_doc) > 0 else 0)> self._chunk_sizeand total > 0):total -= self._length_function(current_doc[0]) + (separator_len if len(current_doc) > 1 else 0)current_doc = current_doc[1:]current_doc.append(d)total += _len + (separator_len if len(current_doc) > 1 else 0)doc = self._join_docs(current_doc, separator)if doc is not None:docs.append(doc)return docs
三、文本向量化存储(以faiss库示例)
FAISS类源码位置:home > anaconda3 > envs > langchain > lib > python3.10 > site-packages > langchain_community > vectorstores > .faiss.py > FAISS
vectorstores类源码位置: home > anaconda3 > envs > langchain > lib > python3.10 > site-packages > langchain_core > vectorstores > .base.py > VectorStore
1、使用faiss实现本地向量化代码
我们看到,这个用库实际是比较简单的,而split_texts的元素是document类,内容也是这样做了处理的。
其完整代码如下:
def create_vector(split_texts, embeddings):# 使用FAISS库从文档列表和嵌入向量创建一个向量存储# 参数split_texts: 文档列表,每个文档已经被分割成单独的文本片段# 参数embeddings: 嵌入向量,用于将文本片段转换为向量表示vector_store = FAISS.from_documents(split_texts, embeddings)# 返回创建的向量存储return vector_storedef create_retriever(vector_store): # 调用vector_store对象的as_retriever方法,将vector_store转换为一个检索器retriever = vector_store.as_retriever()# 返回创建的检索器对象return retriever
使用上面方法就可以实现向量本地化方法。然而,这样的调用并不能让我们理解其内部原理。为此,我接下来就是对这个进行解释。
2、faiss类源码解读
首先我给出faiss类的源码示意结构,尽管内容有些多,但你想明白更深原理,可以大致看一下。这个类有实现各种方法的原理。如何embed、查询等内容,基本囊括了向量所有操作内容。而该方法是继承VectorStore,我也会给出讲解。现在我想给出FAISS类的解释,然后在给出源码示意。
FAISS类注释翻译
这部分来源faiss的注解,翻译成中文如下:
FAISS 向量存储集成。参见 [FAISS 库](https://arxiv.org/pdf/2401.08281) 论文。安装:安装 ``langchain_community`` 和 ``faiss-cpu`` Python 包。.. code-block:: bashpip install -qU langchain_community faiss-cpu主要初始化参数 —— 索引参数:embedding_function: Embeddings使用的嵌入函数。主要初始化参数 —— 客户端参数:index: Any使用的 FAISS 索引。docstore: Docstore使用的文档存储。index_to_docstore_id: Dict[int, str]索引到文档存储 ID 的映射。初始化:.. code-block:: pythonimport faissfrom langchain_community.vectorstores import FAISSfrom langchain_community.docstore.in_memory import InMemoryDocstorefrom langchain_openai import OpenAIEmbeddingsindex = faiss.IndexFlatL2(len(OpenAIEmbeddings().embed_query("hello world")))vector_store = FAISS(embedding_function=OpenAIEmbeddings(),index=index,docstore=InMemoryDocstore(),index_to_docstore_id={})添加文档:.. code-block:: pythonfrom langchain_core.documents import Documentdocument_1 = Document(page_content="foo", metadata={"baz": "bar"})document_2 = Document(page_content="thud", metadata={"bar": "baz"})document_3 = Document(page_content="我将被删除 :(")documents = [document_1, document_2, document_3]ids = ["1", "2", "3"]vector_store.add_documents(documents=documents, ids=ids)删除文档:.. code-block:: pythonvector_store.delete(ids=["3"])搜索:.. code-block:: pythonresults = vector_store.similarity_search(query="thud", k=1)for doc in results:print(f"* {doc.page_content} [{doc.metadata}]").. code-block:: python* thud [{'bar': 'baz'}]带过滤条件的搜索:.. code-block:: pythonresults = vector_store.similarity_search(query="thud", k=1, filter={"bar": "baz"})for doc in results:print(f"* {doc.page_content} [{doc.metadata}]").. code-block:: python* thud [{'bar': 'baz'}]带分数的搜索:.. code-block:: pythonresults = vector_store.similarity_search_with_score(query="qux", k=1)for doc, score in results:print(f"* [SIM={score:3f}] {doc.page_content} [{doc.metadata}]").. code-block:: python* [SIM=0.335304] foo [{'baz': 'bar'}]异步操作:.. code-block:: python# 添加文档# await vector_store.aadd_documents(documents=documents, ids=ids)# 删除文档# await vector_store.adelete(ids=["3"])# 搜索# results = vector_store.asimilarity_search(query="thud", k=1)# 带分数的搜索results = await vector_store.asimilarity_search_with_score(query="qux", k=1)for doc, score in results:print(f"* [SIM={score:3f}] {doc.page_content} [{doc.metadata}]").. code-block:: python* [SIM=0.335304] foo [{'baz': 'bar'}]用作检索器:.. code-block:: pythonretriever = vector_store.as_retriever(search_type="mmr",search_kwargs={"k": 1, "fetch_k": 2, "lambda_mult": 0.5},)retriever.invoke("thud").. code-block:: python[Document(metadata={'bar': 'baz'}, page_content='thud')]
FAISS类的示意结构
特别关注FAISS继承了VectorStore类。
class FAISS(VectorStore):def __init__(self,embedding_function: Union[Callable[[str], List[float]],Embeddings,],index: Any,docstore: Docstore,index_to_docstore_id: Dict[int, str],relevance_score_fn: Optional[Callable[[float], float]] = None,normalize_L2: bool = False,distance_strategy: DistanceStrategy = DistanceStrategy.EUCLIDEAN_DISTANCE,):...@propertydef embeddings(self) -> Optional[Embeddings]:...def _embed_documents(self, texts: List[str]) -> List[List[float]]:...async def _aembed_documents(self, texts: List[str]) -> List[List[float]]:...def _embed_query(self, text: str) -> List[float]:...def __add(self,texts: Iterable[str],embeddings: Iterable[List[float]],metadatas: Optional[Iterable[dict]] = None,ids: Optional[List[str]] = None,) -> List[str]:...def add_texts(self,texts: Iterable[str],metadatas: Optional[List[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> List[str]:...async def aadd_texts(self,texts: Iterable[str],metadatas: Optional[List[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> List[str]:...def add_embeddings(self,text_embeddings: Iterable[Tuple[str, List[float]]],metadatas: Optional[List[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> List[str]:...def similarity_search_with_score_by_vector(self,embedding: List[float],k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...async def asimilarity_search_with_score_by_vector(self,embedding: List[float],k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...def similarity_search_with_score(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...async def asimilarity_search_with_score(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...def similarity_search_by_vector(self,embedding: List[float],k: int = 4,filter: Optional[Dict[str, Any]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Document]:...async def asimilarity_search_by_vector(self,embedding: List[float],k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Document]:...def similarity_search(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Document]:...async def asimilarity_search(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Document]:...def max_marginal_relevance_search_with_score_by_vector(self,embedding: List[float],*,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,) -> List[Tuple[Document, float]]:...async def amax_marginal_relevance_search_with_score_by_vector(self,embedding: List[float],*,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,) -> List[Tuple[Document, float]]:...def max_marginal_relevance_search_by_vector(self,embedding: List[float],k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,**kwargs: Any,) -> List[Document]:...async def amax_marginal_relevance_search_by_vector(self,embedding: List[float],k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,**kwargs: Any,) -> List[Document]:...def max_marginal_relevance_search(self,query: str,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,**kwargs: Any,) -> List[Document]:...async def amax_marginal_relevance_search(self,query: str,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,**kwargs: Any,) -> List[Document]:...def delete(self, ids: Optional[List[str]] = None, **kwargs: Any) -> Optional[bool]:...def merge_from(self, target: FAISS) -> None:...@classmethoddef __from(cls,texts: Iterable[str],embeddings: List[List[float]],embedding: Embeddings,metadatas: Optional[Iterable[dict]] = None,ids: Optional[List[str]] = None,normalize_L2: bool = False,distance_strategy: DistanceStrategy = DistanceStrategy.EUCLIDEAN_DISTANCE,**kwargs: Any,) -> FAISS:...@classmethoddef from_texts(cls,texts: List[str],embedding: Embeddings,metadatas: Optional[List[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> FAISS:...@classmethodasync def afrom_texts(cls,texts: list[str],embedding: Embeddings,metadatas: Optional[List[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> FAISS:...@classmethoddef from_embeddings(cls,text_embeddings: Iterable[Tuple[str, List[float]]],embedding: Embeddings,metadatas: Optional[Iterable[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> FAISS:...@classmethodasync def afrom_embeddings(cls,text_embeddings: Iterable[Tuple[str, List[float]]],embedding: Embeddings,metadatas: Optional[Iterable[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> FAISS:...def save_local(self, folder_path: str, index_name: str = "index") -> None:...@classmethoddef load_local(cls,folder_path: str,embeddings: Embeddings,index_name: str = "index",*,allow_dangerous_deserialization: bool = False,**kwargs: Any,) -> FAISS:...def serialize_to_bytes(self) -> bytes:"""Serialize FAISS index, docstore, and index_to_docstore_id to bytes."""return pickle.dumps((self.index, self.docstore, self.index_to_docstore_id))@classmethoddef deserialize_from_bytes(cls,serialized: bytes,embeddings: Embeddings,*,allow_dangerous_deserialization: bool = False,**kwargs: Any,) -> FAISS:...def _select_relevance_score_fn(self) -> Callable[[float], float]:...def _similarity_search_with_relevance_scores(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...async def _asimilarity_search_with_relevance_scores(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...@staticmethoddef _create_filter_func(filter: Optional[Union[Callable, Dict[str, Any]]],) -> Callable[[Dict[str, Any]], bool]:...def filter_func_cond(field: str, condition: Union[Dict[str, Any], List[Any], Any]) -> Callable[[Dict[str, Any]], bool]:...def filter_func(filter: Dict[str, Any]) -> Callable[[Dict[str, Any]], bool]:...def get_by_ids(self, ids: Sequence[str], /) -> list[Document]:docs = [self.docstore.search(id_) for id_ in ids]return [doc for doc in docs if isinstance(doc, Document)]
FAISS类结构示意图
home > anaconda3 > envs > langchain > lib > python3.10 > site-packages > langchain_community > vectorstores > .faiss.py > FAISS
3、VectorStore类源码解读
这是向量相关的基类,我们可以大致了解其基类的方法。这个也很重要。其代码示意结构如下:
class VectorStore(ABC):"""Interface for vector store."""def add_texts(self,texts: Iterable[str],metadatas: Optional[list[dict]] = None,*,ids: Optional[list[str]] = None,**kwargs: Any,) -> list[str]:@propertydef embeddings(self) -> Optional[Embeddings]:def delete(self, ids: Optional[list[str]] = None, **kwargs: Any) -> Optional[bool]:def get_by_ids(self, ids: Sequence[str], /) -> list[Document]:async def aget_by_ids(self, ids: Sequence[str], /) -> list[Document]:async def adelete(self, ids: Optional[list[str]] = None, **kwargs: Any) -> Optional[bool]:async def aadd_texts(self,texts: Iterable[str],metadatas: Optional[list[dict]] = None,*,ids: Optional[list[str]] = None,**kwargs: Any,) -> list[str]:def add_documents(self, documents: list[Document], **kwargs: Any) -> list[str]:async def aadd_documents(self, documents: list[Document], **kwargs: Any) -> list[str]:def search(self, query: str, search_type: str, **kwargs: Any) -> list[Document]:async def asearch(self, query: str, search_type: str, **kwargs: Any) -> list[Document]:@abstractmethoddef similarity_search(self, query: str, k: int = 4, **kwargs: Any) -> list[Document]:@staticmethoddef _euclidean_relevance_score_fn(distance: float) -> float:@staticmethoddef _cosine_relevance_score_fn(distance: float) -> float:"""Normalize the distance to a score on a scale [0, 1]."""return 1.0 - distance@staticmethoddef _max_inner_product_relevance_score_fn(distance: float) -> float:def _select_relevance_score_fn(self) -> Callable[[float], float]:def similarity_search_with_score(self, *args: Any, **kwargs: Any) -> list[tuple[Document, float]]:async def asimilarity_search_with_score(self, *args: Any, **kwargs: Any) -> list[tuple[Document, float]]:def _similarity_search_with_relevance_scores(self,query: str,k: int = 4,**kwargs: Any,) -> list[tuple[Document, float]]:async def _asimilarity_search_with_relevance_scores(self,query: str,k: int = 4,**kwargs: Any,) -> list[tuple[Document, float]]:def similarity_search_with_relevance_scores(self,query: str,k: int = 4,**kwargs: Any,) -> list[tuple[Document, float]]:async def asimilarity_search_with_relevance_scores(self,query: str,k: int = 4,**kwargs: Any,) -> list[tuple[Document, float]]:async def asimilarity_search(self, query: str, k: int = 4, **kwargs: Any) -> list[Document]:def similarity_search_by_vector(self, embedding: list[float], k: int = 4, **kwargs: Any) -> list[Document]: async def asimilarity_search_by_vector(self, embedding: list[float], k: int = 4, **kwargs: Any) -> list[Document]:def max_marginal_relevance_search(self,query: str,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,**kwargs: Any,) -> list[Document]: async def amax_marginal_relevance_search(self,query: str,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,**kwargs: Any,) -> list[Document]:def max_marginal_relevance_search_by_vector(self,embedding: list[float],k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,**kwargs: Any,) -> list[Document]:async def amax_marginal_relevance_search_by_vector(self,embedding: list[float],k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,**kwargs: Any,) -> list[Document]:@classmethoddef from_documents(cls: type[VST],documents: list[Document],embedding: Embeddings,**kwargs: Any,) -> VST:@classmethodasync def afrom_documents(cls: type[VST],documents: list[Document],embedding: Embeddings,**kwargs: Any,) -> VST:@classmethod@abstractmethoddef from_texts(cls: type[VST],texts: list[str],embedding: Embeddings,metadatas: Optional[list[dict]] = None,*,ids: Optional[list[str]] = None,**kwargs: Any,) -> VST:@classmethodasync def afrom_texts(cls: type[VST],texts: list[str],embedding: Embeddings,metadatas: Optional[list[dict]] = None,*,ids: Optional[list[str]] = None,**kwargs: Any,) -> VST:def _get_retriever_tags(self) -> list[str]:"""Get tags for retriever.""" def as_retriever(self, **kwargs: Any) -> VectorStoreRetriever:
其图像示意结构如下:
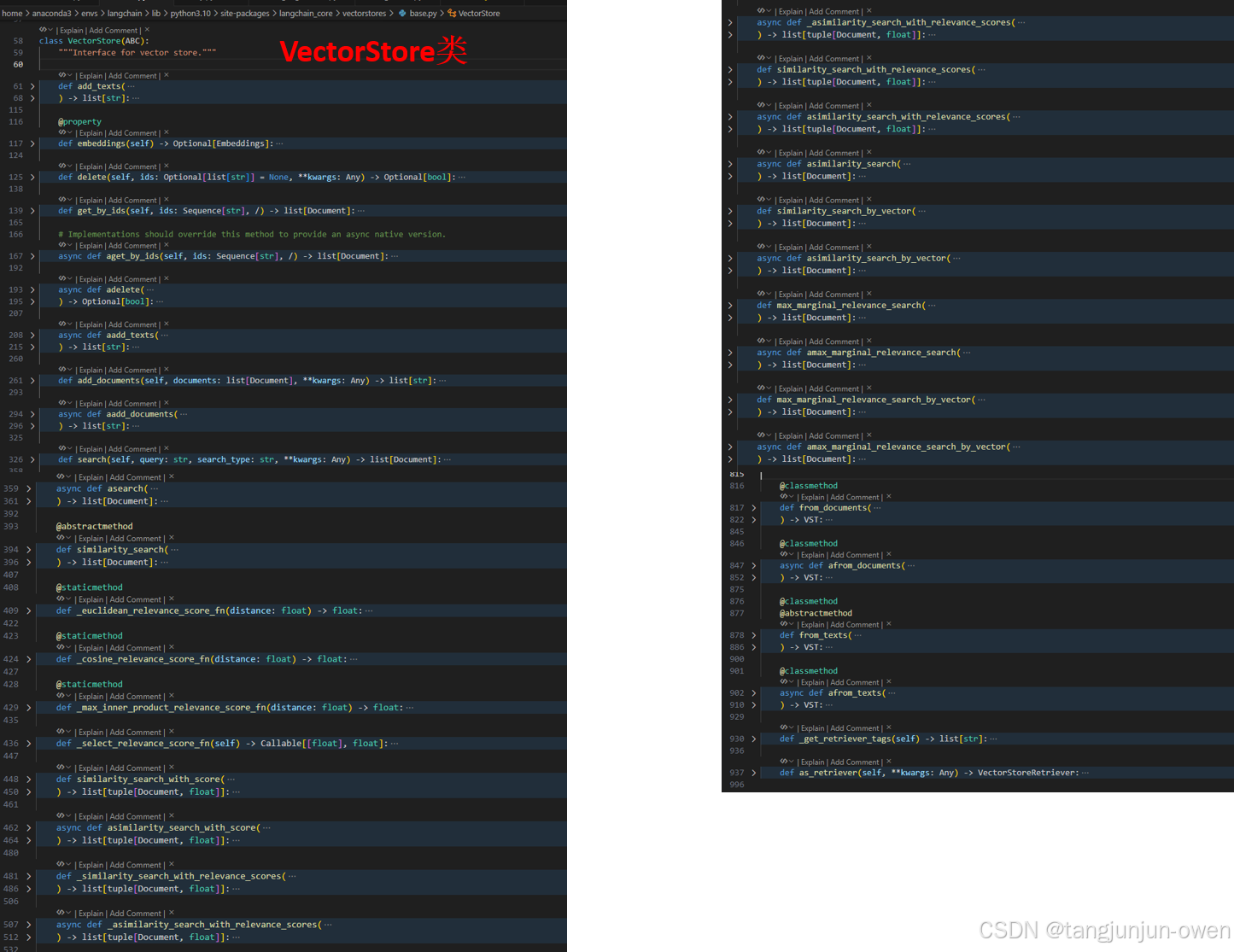
四、构建一个完整RAG实现检索的代码Demo
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import Docx2txtLoader
from langchain_community.vectorstores import FAISS# 加载Word文档
def load_word_document(file_path):# 创建一个Docx2txtLoader对象,用于加载指定路径的Word文档loader = Docx2txtLoader(file_path)# 调用loader对象的load方法,加载文档内容并返回return loader.load()# 初始化文本分割器
def init_text_splitter(**kwargs):# separator="\n", chunk_size=1000, chunk_overlap=200separator,chunk_size,chunk_overlap = kwargs.get("separator","\n"),kwargs.get("chunk_size",1000),kwargs.get("chunk_overlap",200)text_splitter = CharacterTextSplitter(separator=separator, chunk_size=chunk_size, chunk_overlap=chunk_overlap)return text_splitter# 创建向量存储并初始化检索器
def get_texts_split(documents, **kwargs):# 定义一个函数,用于将文档列表分割成文本片段# 参数documents是一个包含多个文档的列表# 参数kwargs是一个关键字参数字典,用于传递给文本分割器的初始化函数text_splitter = init_text_splitter(**kwargs)# 调用init_text_splitter函数,传入kwargs参数字典,初始化一个文本分割器对象# init_text_splitter函数的具体实现不在当前代码中,它可能是用于配置和创建文本分割器的函数split_texts = text_splitter.split_documents(documents)# 使用初始化好的文本分割器对象,调用其split_documents方法,将传入的文档列表进行分割# split_documents方法的具体实现也不在当前代码中,它可能是用于将文档分割成多个文本片段的方法return split_texts# from faiss import write_index, read_index
def create_vector(split_texts, embeddings):# 使用FAISS库从文档列表和嵌入向量创建一个向量存储# 参数split_texts: 文档列表,每个文档已经被分割成单独的文本片段# 参数embeddings: 嵌入向量,用于将文本片段转换为向量表示vector_store = FAISS.from_documents(split_texts, embeddings)# 返回创建的向量存储return vector_storedef create_retriever(vector_store): # 调用vector_store对象的as_retriever方法,将vector_store转换为一个检索器retriever = vector_store.as_retriever()# 返回创建的检索器对象return retriever
def save_vector_store(vector_store,save_path):# save_path = "path/to/your/index.faiss"vector_store.save_local(save_path)return save_path
def load_vector_store(save_path,embeddings):# 注释:定义一个函数load_vector_store,用于加载向量存储# 参数save_path:字符串类型,表示向量存储文件的路径# 参数embeddings:嵌入对象,用于向量存储的检索和索引# 注释:注释掉的代码,原本用于指示用户设置向量存储文件的路径# load_path = "path/to/your/index.faiss"# 注释:使用FAISS库的load_local方法加载本地向量存储# save_path:向量存储文件的路径# embeddings:嵌入对象,用于向量存储的检索和索引vector_store = FAISS.load_local(save_path, embeddings)# 注释:返回加载的向量存储对象return vector_storedef create_vector_store_and_retriever(documents, embeddings_model):# 测试一个文件向量化与检索# 定义文本分割的参数kwargs = {"separator":"\n","chunk_size":1000,"chunk_overlap":200}# 调用get_texts_split函数,将文档分割成小块文本split_texts = get_texts_split(documents, **kwargs)# 调用create_vector函数,将分割后的文本转换为向量存储vector_store = create_vector(split_texts, embeddings_model)# 调用create_retriever函数,创建一个检索器,用于从向量存储中检索信息retriever = create_retriever(vector_store)# 返回创建好的检索器return retriever# 写一个检索demo
def retriever_demo(embeddings_model):# 定义Word文档的路径word_file_path = "/langchain/langchain_demo/file/demo.docx"# 调用load_word_document函数加载Word文档内容documents = load_word_document(word_file_path)print(documents)# 使用一个文件内容向量化与检索测试# 调用create_vector_store_and_retriever函数创建向量存储和检索器retriever = create_vector_store_and_retriever(documents, embeddings_model)# 测试检索# 定义查询问题query = "文档主要内容是什么?"# 调用retriever的get_relevant_documents方法获取与查询相关的文档results = retriever.get_relevant_documents(query)# 返回检索结果return results# 主函数
if __name__ == "__main__":# 使用一个文件内容向量化与检索测试word_file_path = "/langchain/langchain_demo/file/demo.docx" # 替换为你的Word文件路径from EmbedModelOpenAI import load_embed_model_localembeddings_model = load_embed_model_local() # 加载embed模型,这个再我之前章节有介绍res = retriever_demo(embeddings_model)print(res)# documents = load_word_document(word_file_path)# retriever = create_vector_store_and_retriever(documents, embeddings_model)