企业级RAG架构设计:从FAISS索引到HyDE优化的全链路拆解,金融/医疗领域RAG落地案例与避坑指南(附架构图)
本文较长,纯干货,建议点赞收藏,以免遗失。更多AI大模型应用开发学习内容,尽在聚客AI学院。
一. RAG技术概述
1.1 什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将信息检索与文本生成相结合的技术,通过实时从外部知识库中检索相关文档,增强大语言模型(LLM)的生成准确性和事实性。其核心价值在于解决LLM的三大痛点:
-
知识固化:预训练数据无法实时更新
-
幻觉问题:生成内容缺乏事实依据
-
领域局限:难以直接处理专业领域问题
典型应用场景:
-
智能客服(如阿里小蜜日均处理千万级问答)
-
法律/医疗领域专业问答
-
企业知识库增强(如微软将RAG集成到Copilot)
-
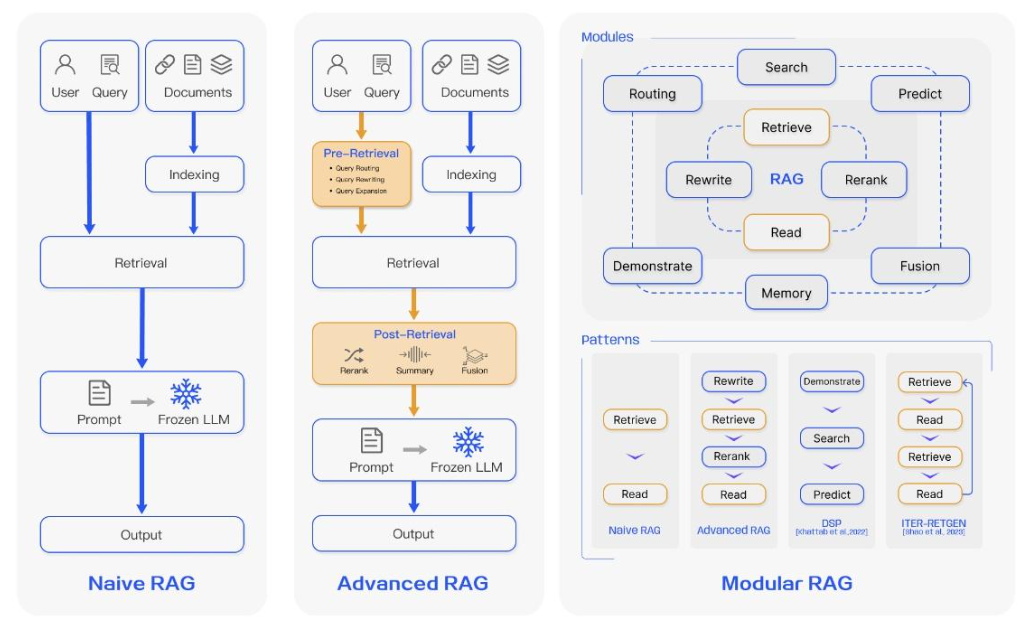
二. RAG如何增强大模型能力
2.1 核心增强机制
-
动态知识注入:每次生成前检索最新资料(如股票实时数据)
-
证据可追溯:生成结果附带参考文档片段
-
长文本处理:通过检索压缩超长上下文(如处理100页PDF)
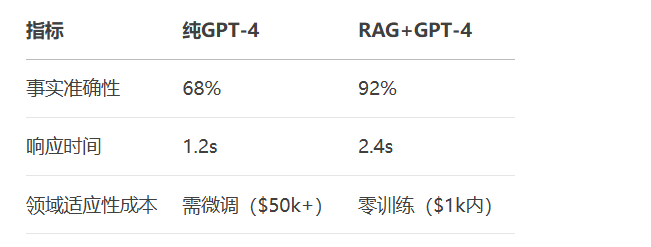
案例对比:
2.2 技术优势
-
低成本:无需微调即可适配新领域
-
可解释性:检索结果提供生成依据
-
安全性:通过知识库过滤敏感内容
三. RAG核心原理与全流程解析
3.1 技术架构图
用户提问 → 向量化 → 检索 → 文档排序 → 上下文构建 → LLM生成 → 输出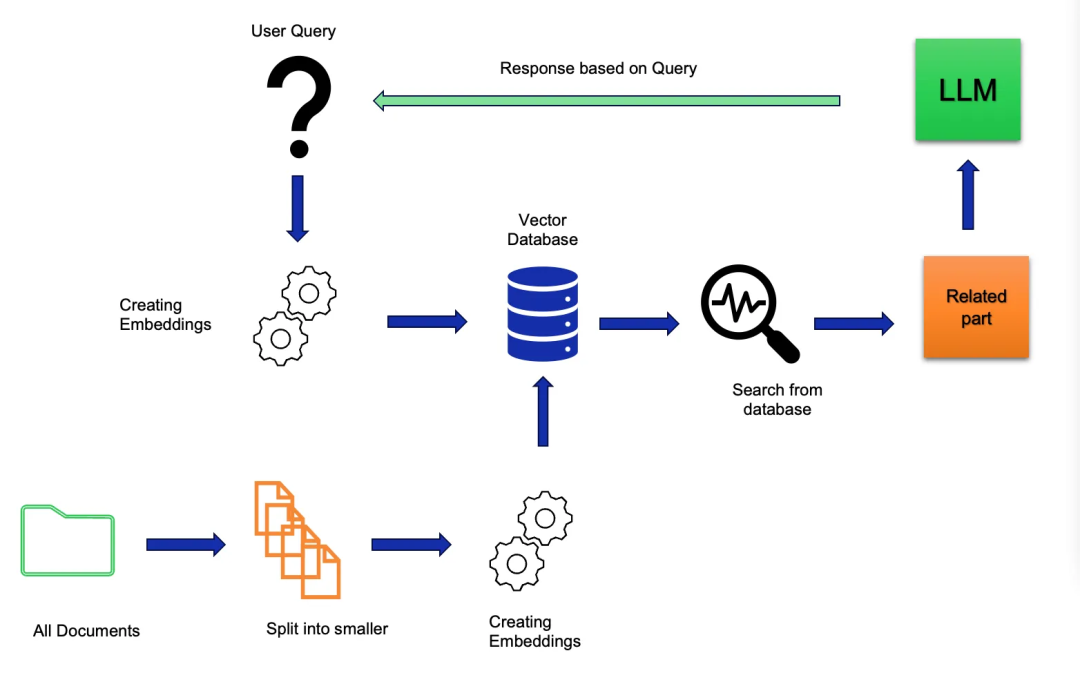
3.2 分阶段详解
阶段1:数据预处理与索引
代码示例:构建向量数据库(使用FAISS)
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
# 加载嵌入模型
encoder = SentenceTransformer('all-MiniLM-L6-v2')
# 假设documents是加载的文本列表
documents = ["大模型原理...", "RAG技术优点..."]
embeddings = encoder.encode(documents)
# 创建FAISS索引
dim = embeddings.shape[1]
index = faiss.IndexFlatL2(dim)
index.add(embeddings)
# 保存索引
faiss.write_index(index, "rag_index.faiss")阶段2:实时检索与重排序
代码示例:检索Top-K文档
def retrieve(query: str, k=5): query_embedding = encoder.encode([query]) distances, indices = index.search(query_embedding, k) return [documents[i] for i in indices[0]]
# 示例
results = retrieve("如何提高RAG的准确性?")
print("相关文档:", results[:2])阶段3:上下文构建与生成
代码示例:调用LLM生成
from transformers import pipeline
generator = pipeline("text-generation", model="gpt2")
def rag_generate(query): contexts = retrieve(query) prompt = f"基于以下信息回答问题:\n{contexts}\n\n问题:{query}\n答案:" return generator(prompt, max_length=500)[0]['generated_text']
# 执行
answer = rag_generate("RAG有哪些优化方法?")
print(answer)3.3 高级优化策略
-
检索增强:
-
HyDE:先用LLM生成假设答案,再检索相关文档
-
Rerank:用交叉编码器(cross-encoder)对初筛结果重排序
-
-
生成控制:
-
引用标注:在生成文本中标记参考来源
-
置信度过滤:丢弃低质量检索结果
-
代码示例:HyDE优化实现
def hyde_retrieve(query): # 生成假设答案 hypo_answer = generator(f"假设答案:{query}", max_length=100)[0]['generated_text'] # 基于假设答案检索 return retrieve(hypo_answer)注:本文代码需安装以下依赖:
pip install sentence-transformers faiss-cpu transformers更多AI大模型应用开发学习内容,尽在聚客AI学院。