【AI论文】FormalMATH:大型语言模型形式化数学推理能力基准测试
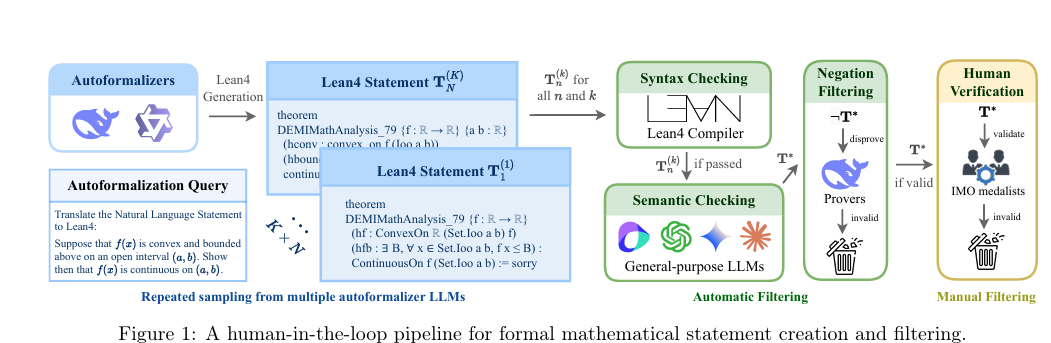
摘要:正式的数学推理仍然是人工智能面临的一个关键挑战,受到现有基准在范围和规模上的限制。 为了解决这个问题,我们提出了FormalMATH,这是一个大规模的Lean4基准,包含5560个经过形式验证的问题,这些问题涵盖了从高中奥林匹克挑战到本科水平的定理,涉及不同的领域(如代数、应用数学、微积分、数论和离散数学)。 为了减轻手动形式化的低效性,我们引入了一种新的人工参与自动形式化管道,该管道集成了:(1)用于语句自动形式化的专用大型语言模型(LLM),(2)多LLM语义验证,以及(3)使用现成的基于LLM的证明器的基于否定的反证过滤策略。 这种方法通过保留72.09%的语句在人工验证之前,同时确保对原始自然语言问题的保真度,降低了专家注释成本。 我们对基于 LLM 的定理证明器的最新评估揭示了其重大局限性:即使是最强大的模型在实际抽样预算下也只能达到 16.46% 的成功率,表现出明显的领域偏差(例如,擅长代数但微积分不及格)和对简化自动化策略的过度依赖。 值得注意的是,我们发现在思维链推理场景中,自然语言解决方案指导和证明成功之间存在一种违反直觉的反向关系,这表明人类书写的非正式推理在正式推理环境中引入了噪音,而不是清晰度。 我们认为FormalMATH为正式数学推理的基准测试提供了一个强大的基准。Huggingface链接:Paper page,论文链接:2505.02735
研究背景和目的
研究背景
形式化数学推理(Formal Mathematical Reasoning, FMR)是人工智能领域中的一个关键挑战,它要求系统能够在严格的数学框架内进行推理和证明。尽管近年来大型语言模型(LLMs)在自然语言处理和形式化数学推理方面取得了显著进展,但现有的基准测试在范围和规模上仍存在限制,无法全面评估LLMs在FMR方面的能力。
具体而言,现有的形式化数学基准测试,如MiniF2F和ProofNet,主要集中在代数和数论等特定领域,且问题数量相对较少。这限制了基准测试的全面性和鲁棒性,使得研究人员难以准确评估LLMs在多样化数学领域中的表现。此外,手动形式化数学问题耗时且成本高昂,进一步限制了大规模基准测试的开发。
为了应对这些挑战,研究人员开始探索自动化形式化方法,利用LLMs将自然语言数学问题转换为形式化语言(如Lean4)。然而,现有的自动化形式化工具在处理复杂数学概念和确保语义一致性方面仍存在不足。
研究目的
本文的研究目的主要包括以下几个方面:
-
开发大规模形式化数学基准测试:构建一个包含多样化数学领域和广泛难度级别的大规模形式化数学基准测试(FormalMATH),以全面评估LLMs在FMR方面的能力。
-
探索自动化形式化方法:提出一种人工参与的自动化形式化管道,集成专用LLMs进行语句自动形式化、多LLM语义验证和基于否定的反证过滤策略,以减少人工验证成本并确保语义一致性。
-
评估现有LLM-based定理证明器:在FormalMATH基准测试上评估现有基于LLM的定理证明器的性能,揭示其局限性和挑战,为未来的研究提供方向。
-
分析思维链推理中的自然语言指导:研究在思维链推理场景中,自然语言解决方案指导对证明成功率的影响,探讨人类书写的非正式推理在正式推理环境中的作用。
研究方法
数据收集与构建
-
数据来源:从多个来源收集自然语言数学问题,包括高中奥林匹克竞赛、本科课程教材和在线数学论坛等。问题涵盖代数、应用数学、微积分、数论和离散数学等多个领域。
-
自动化形式化:利用专用LLMs将自然语言问题转换为Lean4形式化语句。通过多LLM语义验证确保形式化语句与原始自然语言问题的语义一致性。
-
人工验证:邀请国际数学奥林匹克竞赛奖牌获得者对自动化形式化的结果进行人工验证,确保形式化语句的准确性和语义一致性。
评估方法
-
定理证明器选择:选择多个基于LLM的定理证明器进行评估,包括Kimina-Prover、DeepSeek-Prover、STP和Goedel-Prover等。
-
评估指标:使用Pass@K指标评估定理证明器的性能,该指标衡量在K次采样中至少找到一个有效证明的比例。
-
实验设置:在不同采样预算下评估定理证明器的性能,包括单次采样(K=32)和多次采样(如K=3200)等场景。
研究结果
基准测试构建结果
-
规模与多样性:FormalMATH基准测试包含5560个形式化验证的数学问题,涵盖高中奥林匹克竞赛到本科水平的定理,涉及多个数学领域。
-
自动化形式化效率:通过人工参与的自动化形式化管道,成功保留了72.09%的语句在人工验证之前,显著降低了人工注释成本。
定理证明器评估结果
-
整体性能:现有基于LLM的定理证明器在FormalMATH基准测试上的性能有限,即使是最强的模型(如Kimina-Prover)在实用采样预算下也只能达到16.46%的成功率。
-
领域偏差:定理证明器在不同数学领域中的表现存在显著差异,例如在代数领域表现良好,但在微积分和离散数学等领域表现不佳。
-
自动化策略依赖:定理证明器过度依赖简化的自动化策略,如aesop和linearith等,这些策略在处理复杂推理步骤时效果不佳。
思维链推理分析结果
-
自然语言指导的影响:在思维链推理场景中,自然语言解决方案指导对证明成功率具有反直觉的影响,即提供自然语言解决方案反而降低了证明成功率。
-
原因探讨:人类书写的非正式推理在正式推理环境中引入了噪音而非清晰度,导致证明器在处理复杂推理步骤时更加困难。
研究局限
-
数据集限制:尽管FormalMATH基准测试在规模和多样性上有了显著提升,但仍可能存在某些特定领域或难度级别的问题覆盖不足的情况。
-
自动化形式化准确性:尽管采用了多LLM语义验证和人工验证的方法,但自动化形式化过程中仍可能存在误差,影响基准测试的准确性。
-
定理证明器性能:现有基于LLM的定理证明器在FormalMATH基准测试上的性能有限,表明LLMs在FMR方面仍有很大的提升空间。
-
思维链推理复杂性:思维链推理场景中的自然语言指导影响复杂且难以预测,需要更深入的研究来理解其背后的机制。
未来研究方向
-
扩展数据集:进一步扩展FormalMATH基准测试的数据集,涵盖更多数学领域和难度级别的问题,以提高基准测试的全面性和鲁棒性。
-
改进自动化形式化方法:探索更先进的自动化形式化方法,提高形式化语句的准确性和语义一致性,减少人工验证成本。
-
提升定理证明器性能:开发更强大的基于LLM的定理证明器,优化自动化策略的选择和执行,提高证明器的跨领域泛化能力和复杂推理能力。
-
深入理解思维链推理:深入研究思维链推理场景中的自然语言指导影响,探索如何有效利用自然语言信息来提高证明成功率,同时避免引入噪音。
-
跨学科合作:加强数学、计算机科学和人工智能等领域的跨学科合作,共同推动形式化数学推理技术的发展和应用。
综上所述,本文通过开发FormalMATH基准测试、探索自动化形式化方法、评估现有基于LLM的定理证明器以及分析思维链推理中的自然语言指导影响,为形式化数学推理领域的研究提供了新的视角和方向。未来的研究可以进一步扩展数据集、改进自动化形式化方法、提升定理证明器性能、深入理解思维链推理以及加强跨学科合作,以推动形式化数学推理技术的持续发展。