Go语言chan底层原理
本篇文章内容参考小徐先生等文章,带有个人注解等内容,帮助大家更好的了解chan的底层实现,原文是在语雀chan底层,可以点击查看,如果感觉还不错的同学,不妨点一个免费的赞和关注,冲冲冲,开始今天的学习!
一.概念和定义
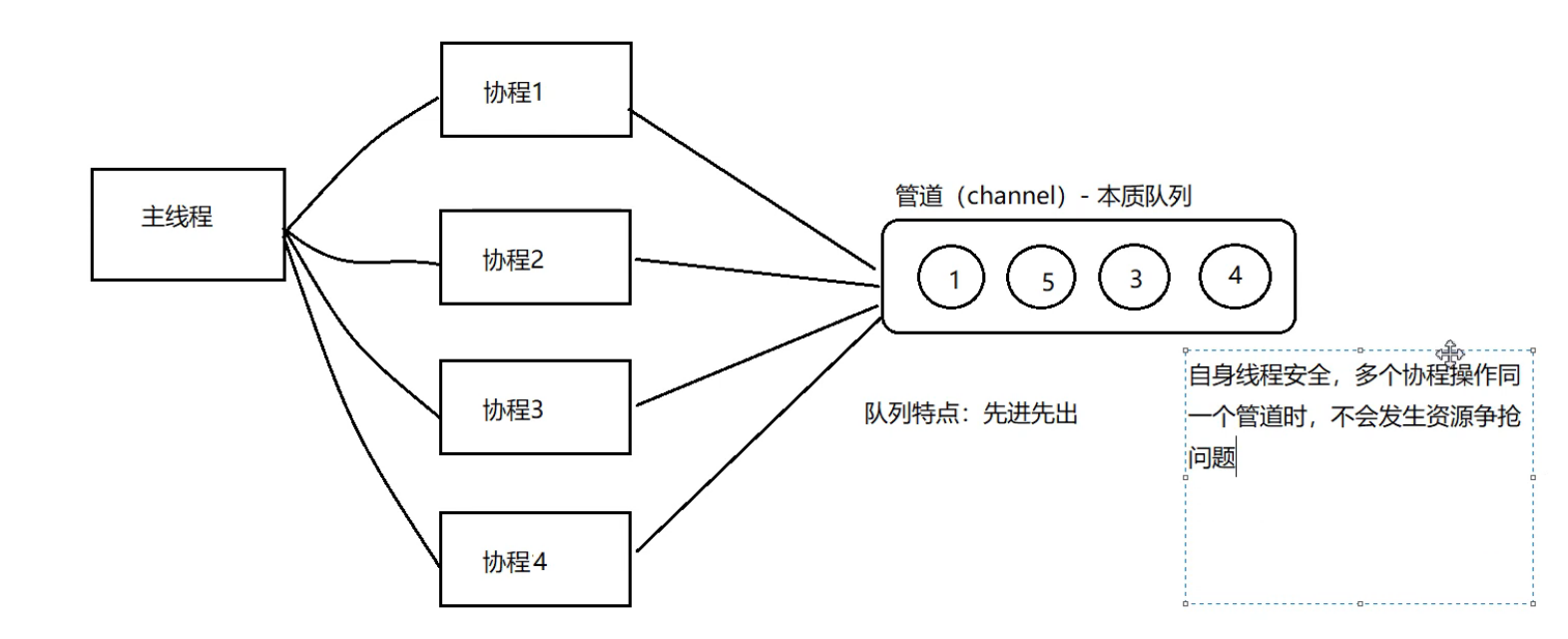
1.1 管道介绍
管道:本质上就是一个数据结构--队列(先进先出)
- 它本身就是并发安全的,不需要加锁。
- 管道是有类型的,一个string类型的管道只能存放string类型的数据。
- 管道是引用类型
1.2.管道的基本操作
1.2.1管道的创建
package mainimport "fmt"func main() {var intChan chan int // 声明一个int类型的管道intChan = make(chan int, 3) //给他开辟空间fmt.Println(intChan)intChan2 := make(chan int,3) //另一种方式的开辟fmt.Println(intChan2)
}
package mainimport "fmt"func main() {intChan := make(chan int) fmt.Println(intChan) //0xc000108070fmt.Printf("管道的长度:%v,管道的容量:%v", len(intChan), cap(intChan))//管道的长度:0,管道的容量:0
}
1.2.2 管道存放和读取
用符号“ <- ”表示存放和读取
package mainimport "fmt"func main() {intChan := make(chan int) fmt.Println(intChan) //0xc000108070fmt.Printf("管道的长度:%v,管道的容量:%v", len(intChan), cap(intChan))//管道的长度:0,管道的容量:0
}读取之后里面就没有数据了,如果在读就会报错,并且我们没有办法直接访问内部的数据
1.2.3 管道的关闭
管道的关闭通过一个close函数实现,关闭之后的管道只能读取,但是不可以写入
package mainimport "fmt"func main() {intChan := make(chan int, 3)intChan <- 10intChan <- 20// 关闭通道close(intChan)// 写入数据会报错intChan <- 30// 读取还是可以的num1 := <-intChannum2 := <-intChanfmt.Println(num1, num2)
}管道的关闭注意的点:
- 关闭1个空的通道
- 关闭一个非空的通道&&已关闭的通道
- 关闭一个非空的通道&&未关闭的通道
在1和2的情况下,都是会提示报错的:panic: close of nil channel
只有3才是正确的关闭,后续会做详细的补充
1.2.4 管道的遍历
管道支持for-range的方式进行遍历,但是需要注意两个细节:
- 在遍历的时候,如果管道没有关闭,则会出现deadlock的错误
- 在遍历的时候,如果管道已经关闭,则会正常遍历数据,遍历完之后会退出。
package mainimport "fmt"func main() {intChan := make(chan int, 10)for i := 0; i < 10; i++ {intChan <- i}// 没有关闭则会报错close(intChan)for v := range intChan {fmt.Println(v)}
}
其实还可以for的死循环进行一个遍历,前提是当管道的长度是0的时候就要跳出。
package mainimport "fmt"func main() {var intchan chan intintchan = make(chan int, 100)for i := 0; i < 100; i++ {intchan <- i}for {num := <-intchanfmt.Println(num)if len(intchan) == 0 {break}}
}1.3 缓冲管道和非缓冲管道
也就是说容量是0的管道是非缓冲通道,反之则是缓冲通道
ch := make(chan string) // 非缓冲通道
ch := make(chan string, 0) // 非缓冲通道
ch := make(chan string, 10) // 缓冲通道, 容量为 101.3.1 非缓冲通道
- 什么是非缓冲通道?
- 非缓冲通道是一种同步通道,它不存储数据。
- 每次写入(发送)操作,都会阻塞,直到有一个对应的读取(接收)操作开始。
- 同理,每次读取操作也会阻塞,直到有一个对应的写入操作完成。
- 为什么阻塞?
- 无缓冲通道的设计目的是确保发送者和接收者在同一时间点完成数据交接。
- 它本质上是一个同步机制,而非数据存储容器。
- 如果没有接收者,写入无法完成,发送操作会永远等待接收者来读取数据。
对于非缓冲通道来说,如果向通道内写入数据就会报错:
fatal error: all goroutines are asleep - deadlock!(死锁)
但是并非说这种通道就没有用,举一个例子:
package mainimport "fmt"func main() {ch := make(chan string) // 没有设置通道的长度go func() {ch <- "hello world"}()msg := <-ch // 一直阻塞,直到接收到通道消息fmt.Println(msg) //hello world
}导致上述的原因是:无缓冲通道上面的发送操作将会阻塞,直到另一个 goroutine 在对应的通道上面完成接收操作,两个 goroutine 才可以继续执行。
要是这样就会有同学就会想,为什么非要加上goroutine呢,我直接传入在读取就ok了,为什么还要多次一举加上goroutine呢?
package mainfunc main() {ch := make(chan string) // 没有设置通道的长度ch <- "hello world" // 向通道发送数据,但是没有接收者msg := <-ch // 代码执行不到这里, 因为上面阻塞发送数据时,就已经死锁了println(msg)
}
// 输出如下
/**fatal error: all goroutines are asleep - deadlock!......exit status 2
*/为什么会报错?(提示这是一个死锁)
什么在主线程里写入一个无缓冲通道(chan),然后直接读取会报错,而引入一个 Goroutine 就可以了?
这个问题的核心在于Go的无缓冲通道设计和操作的阻塞特性
主要就是因为: 无缓冲通道的特性决定了发送和接收必须在两个独立的 Goroutine 中完成
这样我们转念一想,如果想暂存在缓冲区的话,我们就可以使用缓冲通道。
1.3.2 缓冲通道
和上面的非缓冲通道就形成了对比,它就支持对数据的暂存。
package mainimport "fmt"func main() {ch := make(chan string, 1) // 没有设置通道的长度ch <- "hello world"msg := <-ch // 一直阻塞,直到接收到通道消息fmt.Println(msg) //hello world
}1.4 单向通道
在上述的学习中,我们学习的都是双向通道,接下来,我们要学习的就是单向通道,只支持读或者写。
变量 := make(chan 数据类型)
# 例子
ch := make(chan string)变量 := make(chan 数据类型)
# 例子
ch := make(chan string)变量 := make(chan<- 数据类型)
# 例子
ch := make(chan<- string)类型转换:
注意:双向通道可以转化位单向通道,但是单向通道无法转化为双向通道。
package main// 参数是一个写入通道
func ping(pings chan<- string) {//<-pings // 错误: pings 通道只能写入pings <- "hello world"
}func pong(pings <-chan string, pongs chan<- string) {//pings <- "hello world" // 错误: pings 通道只能读取//<-pongs // 错误: pongs 通道只能写入msg := <-pingspongs <- msg
}func main() {pings := make(chan string)pongs := make(chan string)done := make(chan bool)go ping(pings)go pong(pings, pongs)go func() {msg := <-pongsprintln(msg)done <- true}()<-doneclose(pings)close(pongs)close(done)
}1.5 管道的阻塞和死锁
在上述的学习之中,可能对死锁的概念以及阻塞可能还不太了解,接下来,做一个稍微具体的介绍:
死锁(Deadlock)是计算机系统中并发编程的一个经典问题。它是指多个线程(或进程)在竞争资源时,彼此互相等待对方释放资源,导致所有线程都无法继续执行的一种状态。
简而言之,死锁就是程序或系统进入了“无解的僵局”。
阻塞 :就是指一个进程或线程在执行过程中,因为某种原因(通常是某个条件不满足)而无法继续执行,需要等待某个条件满足后才能继续执行。只会影响当前进程,等待条件满足后,进程可以继续执行。
如果阻塞的问题一直没得到解决,就会引发死锁的问题。
阻塞主要有两种情况:
- 发送阻塞:当一个 goroutine 想往管道里发送数据时,如果发现管道已经满了(如果是有缓冲区的管道的话),那它就会阻塞在那里,一直等到有另一个 goroutine 从管道里接走了数据,腾出了空间,它才能继续发送。
- 接收阻塞:反过来,当一个 goroutine 想从管道里接收数据时,如果发现管道是空的(如果是有缓冲区的管道或者无缓冲区的管道都可能出现这种情况),那它也会阻塞在那里,一直等到有另一个 goroutine 往管道里发了数据,它才能接收到数据并继续执行
读写频率不一致,并不会导致死锁,但是一直写入数据,不读取,就会导致死锁。
管道的阻塞机制其实就是为了保证并发程序中的数据同步和安全。
它让 goroutine 在发送或接收数据时,能够按照一定的顺序来,避免了数据丢失和竞态条件的发生。
解决管道阻塞的方法也有很多
比如你可以使用 select 语句来同时监听多个通道的读写操作,哪个通道准备好了就执行哪个操作;或者使用带有超时机制的 select 语句来避免永久阻塞
还可以使用带有缓冲区的通道来减少阻塞的可能性;甚至可以通过判断通道的状态(使用 len 和 cap 函数)来避免不必要的阻塞。
二 . 管道和协程
2.1.管道和协程的共用案例
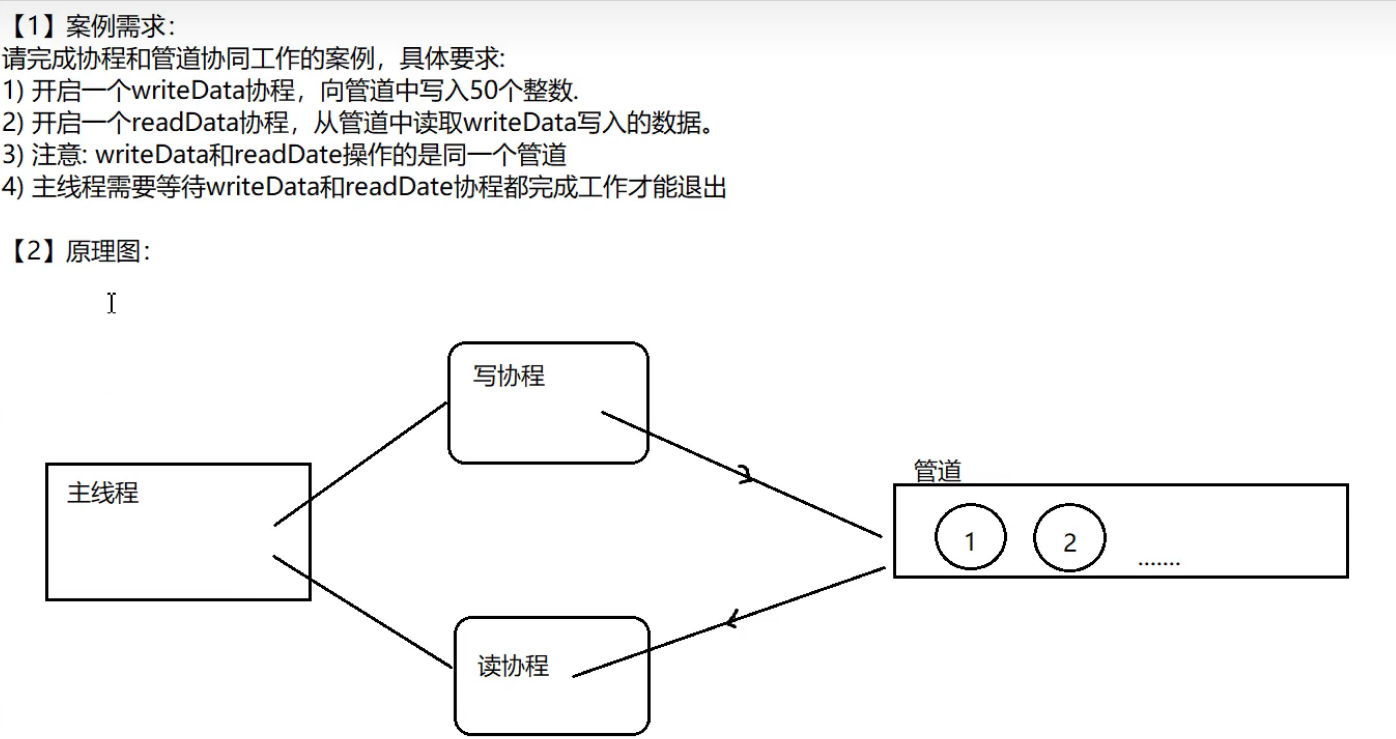
package mainimport ("fmt""sync""time"
)var wg sync.WaitGroupfunc writedata(intchan chan int) {defer wg.Done()for i := 1; i < 50; i++ {intchan <- iprintln("写入的数据为", i)time.Sleep(time.Second)}//使用完,关闭管道close(intchan)
}func read(intchan chan int) {//遍历;defer wg.Done()for v := range intchan {fmt.Println("读取v的值为", v)time.Sleep(time.Second)}
}
func main() { //主线程//写协程和读协程操作一个管道//1.定义管道intchan := make(chan int, 50)wg.Add(2)go writedata(intchan)go read(intchan)wg.Wait()
}
2.2.管道的select功能
select功能:解决多个管道的选择问题,也可以叫做多路复用,可以从多个管道中随机公平选择一个来执行
- case后面必须是io操作,不能是等待值,随机去选择一个io操作
- default防止select被阻塞,加入default
select 类似 switch, 包含一系列逻辑分支和一个可选的默认分支。每一个分支对应通道上的一次操作 (发送或接收), 可以将 select 理解为专门针对通道操作的 switch 语句。
select {
case v1 := <- ch1:
// do something ...
case v2 := <- ch2:
// do something ...
default:
// do something ...
}来看一个案例,来具体了解一下这个阻塞机制
package mainimport ("fmt""time"
)func main() {intChan := make(chan int, 1)go func() {time.Sleep(10 * time.Second)intChan <- 1}()stringChan := make(chan string, 1)go func() {time.Sleep(1 * time.Second)stringChan <- "i am string"}()select {case v := <-intChan:fmt.Println(v)case v := <-stringChan:fmt.Println(v)}
}为什么说他是一个阻塞,因为只要到管道东西存完之后,才可以读取这个数据,在intchan要等待10秒,stringchan只要1秒,所以会发生什么?这个select就是监听这几个管道,直到读取到数据,才会执行,否则就会一直等待。
如果两个都被阻塞,可以写入deault,来防止阻塞
package mainimport ("fmt""time"
)func main() {intChan := make(chan int, 1)go func() {time.Sleep(10 * time.Second)intChan <- 1}()stringChan := make(chan string, 1)go func() {time.Sleep(5 * time.Second)stringChan <- "i am string"}()select {case v := <-intChan:fmt.Println(v)case v := <-stringChan:fmt.Println(v)default:fmt.Println("防止阻塞")}
}
这里要分清楚switch和select的语法,以及执行顺序
switch是从上往下判断执行。
而select则是随机选取,看谁先有数据,他就会选取哪一个。
这样就会优先选择default
执行顺序
- 当同时存在多个满足条件的通道时,随机选择一个执行
- 如果没有满足条件的通道时,检测是否存在 default 分支
-
- 如果存在则执行
- 否则阻塞等待
通常情况下,把含有 default 分支 的 select 操作称为 无阻塞通道操作。
package mainimport ("fmt""time"
)func main() {ch1 := make(chan string)ch2 := make(chan string)done := make(chan bool)go func() {ch1 <- "hello"}()go func() {ch2 <- "world"}()go func() {done <- true}()time.Sleep(time.Second) // 休眠 1 秒// 此时 3 个通道应该都满足条件,select 会随机选择一个执行select {case msg := <-ch1:fmt.Printf("ch1 msg = %s\n", msg)case msg := <-ch2:fmt.Printf("ch2 msg = %s\n", msg)case <-done:fmt.Println("done !")}close(ch1)close(ch2)close(done)
}// $ go run main.go
// 输出如下,你的输出可能和这里的不一样, 多运行几次看看效果
/**ch1 msg = hello
*/package mainimport ("fmt""time"
)func main() {ch1 := make(chan string)ch2 := make(chan string)done := make(chan bool)go func() {time.Sleep(time.Second)ch1 <- "hello"}()go func() {time.Sleep(time.Second)ch2 <- "world"}()go func() {time.Sleep(time.Second)done <- true}()// 此时 3 个通道都在休眠中, 不满足条件,select 会执行 default 分支select {case msg := <-ch1:fmt.Printf("ch1 msg = %s\n", msg)case msg := <-ch2:fmt.Printf("ch2 msg = %s\n", msg)case <-done:fmt.Println("done !")default:fmt.Println("default !")}close(ch1)close(ch2)close(done)
}// $ go run main.go
// 输出如下
/**default !
*/package mainimport ("fmt""time"
)func main() {ch1 := make(chan string)ch2 := make(chan string)done := make(chan bool)go func() {// ch1 goroutine 输出 1 次 fmt.Println("[ch1 goroutine]")time.Sleep(time.Second)ch1 <- "hello"}()go func() {// ch2 goroutine 输出 2 次for i := 0; i < 2; i++ {fmt.Println("[ch2 goroutine]")time.Sleep(time.Second)}ch2 <- "world"}()go func() {// done goroutine 输出 3 次for i := 0; i < 3; i++ {fmt.Println("[done goroutine]")time.Sleep(time.Second)}done <- true}()for exit := true; exit; {select {case msg := <-ch1:fmt.Printf("ch1 msg = %s\n", msg)case msg := <-ch2:fmt.Printf("ch2 msg = %s\n", msg)case <-done:fmt.Println("done !")exit = false // 通过变量控制外层 for 循环退出}}close(ch1)close(ch2)close(done)
}// $ go run main.go
// 输出如下,你的输出顺序可能和这里的不一样
/**[done goroutine][ch2 goroutine][ch1 goroutine]ch1 msg = hello[done goroutine][ch2 goroutine]ch2 msg = world[done goroutine]done !
*/2.2.1 select和switch的区别
- select 只能应用于 channel 的操作,既可以用于 channel 的数据接收,也可以用于 channel 的数据发送。 如果 select 的多个分支都满足条件,则会随机的选取其中一个满足条件的分支。
- switch 可以为各种类型进行分支操作, 设置可以为接口类型进行分支判断 (通过 i.(type))。switch 分支是顺序执行的,这和 select 不同。
2.2.2 select设置优先级(后续完善)
当 ch1 和 ch2 同时达到就绪状态时,优先执行任务1,在没有任务1的时候再去执行任务2
func worker2(ch1, ch2 <-chan int, stopCh chan struct{}) {for {select {case <-stopCh:returncase job1 := <-ch1:fmt.Println(job1)case job2 := <-ch2:priority:for {select {case job1 := <-ch1:fmt.Println(job1)default:break priority}}fmt.Println(job2)}}
}2.3.错误处理
如果我们之中有一个线程错误,就会导致其他也报错,要处理这个问题,保证其他线程正常进行,就可以使用我们之前学习的错误处理机制。三.异常处理机制
package mainimport ("fmt""sync""time"
)var wg sync.WaitGroupfunc add() {fmt.Println("加法")
}func Test() {num1 := 10num2 := 0result := num1 / num2fmt.Println(result)
}func main() {go add()go Test()time.Sleep(time.Second * 5)
}
package mainimport ("fmt""sync""time"
)var wg sync.WaitGroupfunc add() {fmt.Println("加法")
}func Test() {defer func() {if err := recover(); err != nil {fmt.Println(err)}}()num1 := 10num2 := 0result := num1 / num2fmt.Println(result)
}func main() {go add()go Test()time.Sleep(time.Second * 5)
}
2.4 超时控制
利用 channel (通道) 和 time.After() 方法实现超时控制。
超时控制就是一个程序超时嘛,就是运行时间过长,也就是某一个程序出现异常,没有在规定时间内完成,从而进行一个捕获。举一个例子:
package mainimport ("fmt""time"
)func main() {ch := make(chan bool)go func() {defer func() {ch <- true}()time.Sleep(2 * time.Second) // 模拟超时操作}()select {case <-ch:fmt.Println("ok")case <-time.After(time.Second):fmt.Println("timeout!")}
}// $ go run main.go
// 输出如下
/**timeout!
*/接下来对这个代码做一个简单的解释,这是我根据个人的见解,加上gpt修改之后的结果。
首先先简单介绍一下time.After()函数的作用
time.After 的实现原理
time.After底层是基于 Go 的定时器机制(time.NewTimer)。- 它创建了一个计时器,当计时器时间到期后,会将当前时间发送到返回的通道中。
这里要知道,他是返回一个通道,时间到期时会向这个通道发送一个值,从而触发select的超时分支。
case <-time.After(time.Second):fmt.Println("timeout!")等同于在 1 秒后自动触发这个 case。2.5 定时器
package mainimport ("fmt""time"
)func main() {ticker := time.NewTicker(time.Second)defer ticker.Stop()done := make(chan bool)go func() {time.Sleep(5 * time.Second) // 模拟耗时操作done <- true}()for {select {case <-done:fmt.Println("Done!")returncase <-ticker.C:fmt.Println(time.Now().Format("2006-01-02 15:04:05"))}}
}// $ go run main.go
// 输出如下,你的输出可能和这里的不一样
/**
2024-11-21 13:26:23
2024-11-21 13:26:24
2024-11-21 13:26:25
2024-11-21 13:26:26
Done!
*/三 底层原理
基础操作回顾的差不多了,就开始今天的正题吧,发车喽:
本章内容会使用小徐先生的内容,更多的是自己的注解:
3.1 channal的底层数据结构
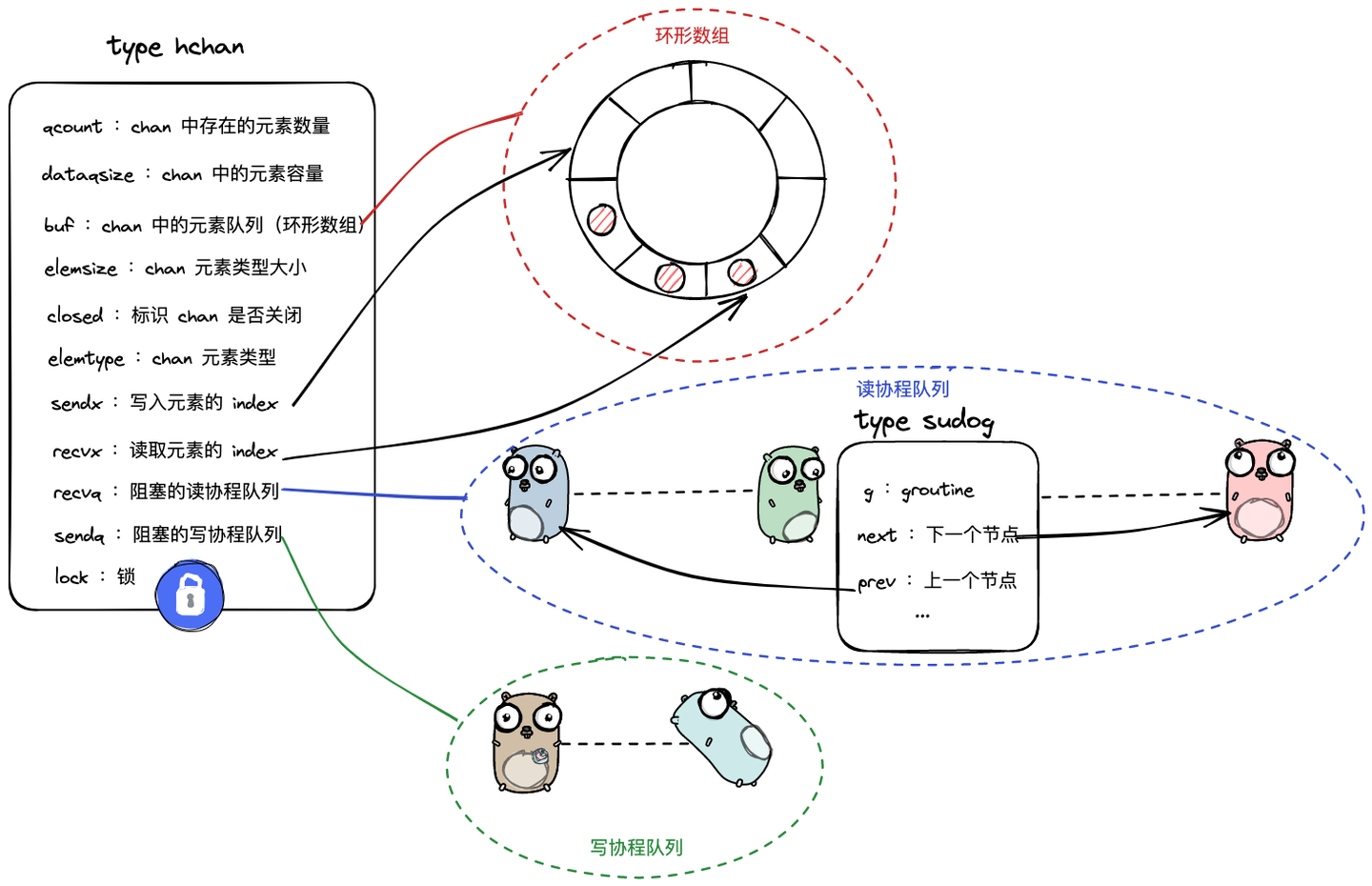
3.1.1 hchan
上述就是一个channal的底层样式,底层是叫hchan,接下来就来看看吧
type hchan struct {qcount uint // total data in the queuedataqsiz uint // size of the circular queuebuf unsafe.Pointer // points to an array of dataqsiz elementselemsize uint16closed uint32elemtype *_type // element typesendx uint // send indexrecvx uint // receive indexrecvq waitq // list of recv waiterssendq waitq // list of send waiterslock mutex
}接下来对这些字段做一个简单的解释:
(1)qcount:当前 channel 中存在多少个元素;
(2)dataqsize: 当前 channel 能存放的元素容量;
(3)buf:channel 中用于存放元素的环形缓冲区;
(4)elemsize:channel 元素类型的大小;
(5)closed:标识 channel 是否关闭;
(6)elemtype:channel 元素类型;
(7)sendx:发送元素进入环形缓冲区的 index;(写入)
(8)recvx:接收元素所处的环形缓冲区的 index;(读取)
(9)recvq:因接收而陷入阻塞的协程队列;(接受等待队列)
(10)sendq:因发送而陷入阻塞的协程队列;(写入等待队列)
lock就是锁
3.1.2 waitq
type waitq struct {first *sudoglast *sudog
}这个数据结构是阻塞的协程队列,看下它的两个字段的含义
first:队列的头部
last:队列的尾部
3.1.3 sudog
type sudog struct {g *gnext *sudogprev *sudogelem unsafe.Pointer // data element (may point to stack)isSelect bool// ...c *hchan
}sudog:用于包装协程的节点
(1)g:goroutine,协程;
(2)next:队列中的下一个节点;
(3)prev:队列中的前一个节点;
(4)elem: 读取/写入 channel 的数据的容器;
(5)c:标识与当前 sudog 交互的 chan.
(6)isSelect:标注是否多路复用,
3.2 构造器函数
通过make函数创建channal的过程,
主要分为有缓冲和无缓冲,在有缓冲里面又分为struct类型和pointer类型。
在runtime包下
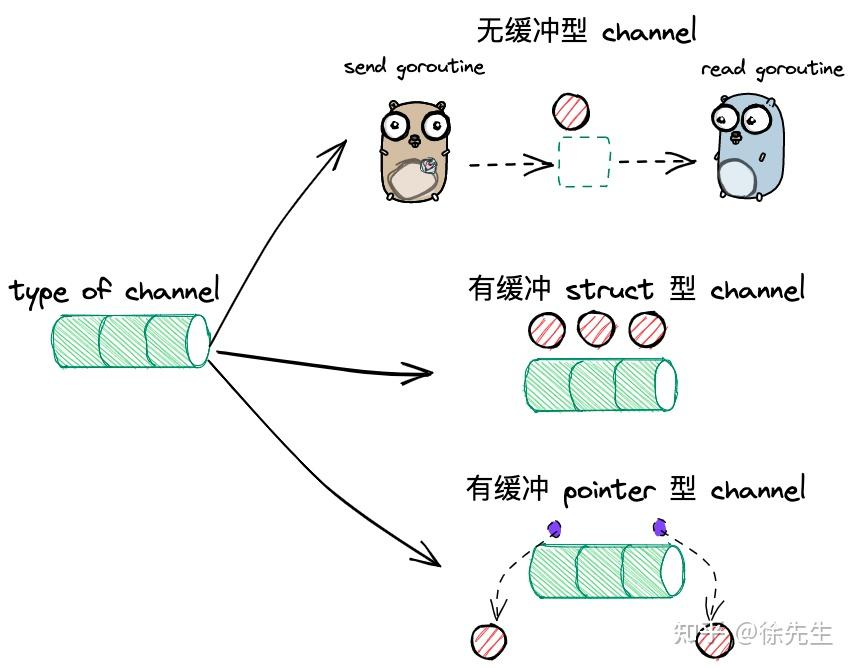
func makechan(t *chantype, size int) *hchan {elem := t.elem// ...mem, overflow := math.MulUintptr(elem.size, uintptr(size)) // 通过元素类型,和元素个数获取要开辟的内存大小啦if overflow || mem > maxAlloc-hchanSize || size < 0 {panic(plainError("makechan: size out of range"))}// 超过上限则panicvar c *hchanswitch {case mem == 0:// 这个mem 就是上面计算得出得内存大小// Queue or element size is zero. c = (*hchan)(mallocgc(hchanSize, nil, true))case elem.ptrdata == 0:// Elements do not contain pointers.// Allocate hchan and buf in one call.// 如果这些元素不包含指针类型// buf 通过指针的偏移来获取非缓冲区的位置c = (*hchan)(mallocgc(hchanSize+mem, nil, true))// 这里的内存是连续的。c.buf = add(unsafe.Pointer(c), hchanSize)default:// Elements contain pointers.// 就是指针类型,指针类型就没有必要申请连续的空间,所以通过new操作c = new(hchan)c.buf = mallocgc(mem, elem, true)}c.elemsize = uint16(elem.size)c.elemtype = elem c.dataqsiz = uint(size) //总容量,在上层,就是传入cap的值lockInit(&c.lock, lockRankHchan)return
}(1)判断申请内存空间大小是否越界,mem 大小为 element 类型大小与 element 个数相乘后得到,仅当无缓冲型 channel 时,因个数为 0 导致大小为 0;
(2)根据类型,初始 channel,分为 无缓冲型、有缓冲元素为 struct 型、有缓冲元素为 pointer 型 channel;
(3)倘若为无缓冲型,则仅申请一个大小为默认值 96 的空间(也就是hchanSize);
(4)如若有缓冲的 struct 型,则一次性分配好 96 + mem 大小的空间,并且调整 chan 的 buf 指向 mem 的起始位置;
(5)倘若为有缓冲的 pointer 型,则分别申请 chan 和 buf 的空间,两者无需连续;
(6)对 channel 的其余字段进行初始化,包括元素类型大小、元素类型、容量以及锁的初始化.
这里要注意一个点,就是mem等于0,这里并非只有无缓冲队列定义才可以是0,如果他的类型是struct{},则他的空间也可能是0,因为struct{}这个类型的内存大小是0
c1 := make(chan struct{}) //无缓冲3.3 select 底层结构(待完善)
这里开始重新介绍一下select:
首先他是Go语言提供的IO多路复用机制,使用多个case同时监听多个channal的读写状态。
type scase struct {c *hchan // chanelem unsafe.Pointer // 读或者写的缓冲区地址kind uint16 //case语句的类型,是default、传值写数据(channel <-) 还是 取值读数据(<- channel)pc uintptr // race pc (for race detector / msan)releasetime int64
}3.4 写流程
下面介绍的流程都是按照源码来的,可以看看源码,是1.23中的
后续的介绍,都是按照源码的顺序来介绍的
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {if c == nil {if !block {return false}gopark(nil, nil, waitReasonChanSendNilChan, traceBlockForever, 2)throw("unreachable")}if debugChan {print("chansend: chan=", c, "\n")}if raceenabled {racereadpc(c.raceaddr(), callerpc, abi.FuncPCABIInternal(chansend))}// Fast path: check for failed non-blocking operation without acquiring the lock.//// After observing that the channel is not closed, we observe that the channel is// not ready for sending. Each of these observations is a single word-sized read// (first c.closed and second full()).// Because a closed channel cannot transition from 'ready for sending' to// 'not ready for sending', even if the channel is closed between the two observations,// they imply a moment between the two when the channel was both not yet closed// and not ready for sending. We behave as if we observed the channel at that moment,// and report that the send cannot proceed.//// It is okay if the reads are reordered here: if we observe that the channel is not// ready for sending and then observe that it is not closed, that implies that the// channel wasn't closed during the first observation. However, nothing here// guarantees forward progress. We rely on the side effects of lock release in// chanrecv() and closechan() to update this thread's view of c.closed and full().if !block && c.closed == 0 && full(c) {return false}var t0 int64if blockprofilerate > 0 {t0 = cputicks()}lock(&c.lock)if c.closed != 0 {unlock(&c.lock)panic(plainError("send on closed channel"))}if sg := c.recvq.dequeue(); sg != nil {// Found a waiting receiver. We pass the value we want to send// directly to the receiver, bypassing the channel buffer (if any).send(c, sg, ep, func() { unlock(&c.lock) }, 3)return true}if c.qcount < c.dataqsiz {// Space is available in the channel buffer. Enqueue the element to send.qp := chanbuf(c, c.sendx)if raceenabled {racenotify(c, c.sendx, nil)}typedmemmove(c.elemtype, qp, ep)c.sendx++if c.sendx == c.dataqsiz {c.sendx = 0}c.qcount++unlock(&c.lock)return true}if !block {unlock(&c.lock)return false}// Block on the channel. Some receiver will complete our operation for us.gp := getg()mysg := acquireSudog()mysg.releasetime = 0if t0 != 0 {mysg.releasetime = -1}// No stack splits between assigning elem and enqueuing mysg// on gp.waiting where copystack can find it.mysg.elem = epmysg.waitlink = nilmysg.g = gpmysg.isSelect = falsemysg.c = cgp.waiting = mysggp.param = nilc.sendq.enqueue(mysg)// Signal to anyone trying to shrink our stack that we're about// to park on a channel. The window between when this G's status// changes and when we set gp.activeStackChans is not safe for// stack shrinking.gp.parkingOnChan.Store(true)gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceBlockChanSend, 2)// Ensure the value being sent is kept alive until the// receiver copies it out. The sudog has a pointer to the// stack object, but sudogs aren't considered as roots of the// stack tracer.KeepAlive(ep)// someone woke us up.if mysg != gp.waiting {throw("G waiting list is corrupted")}gp.waiting = nilgp.activeStackChans = falseclosed := !mysg.successgp.param = nilif mysg.releasetime > 0 {blockevent(mysg.releasetime-t0, 2)}mysg.c = nilreleaseSudog(mysg)if closed {if c.closed == 0 {throw("chansend: spurious wakeup")}panic(plainError("send on closed channel"))}return true
}3.4.1 两类异常情况处理
func chansend1(c *hchan, elem unsafe.Pointer) {chansend(c, elem, true, getcallerpc())
}func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {// 1.这里是处理未初始化的channalif c == nil {if !block {return false}gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)// 这里会把当前写操作的goroutine挂起,陷入一个被动阻塞// 这是一种异常阻塞的情况,最后导致死锁throw("unreachable")}//...(表示中间还有内容,只不过不太涉及)lock(&c.lock)//加锁// 2.这里就是对一个已经关闭的chan进行写数据,就会导致panicif c.closed != 0 {unlock(&c.lock)panic(plainError("send on closed channel"))}//...后面还有内容呢
}(1)对于未初始化的 chan,写入操作会引发死锁;
eg : var ch chan int (这种就是未初始化,是一个nil)
(2)对于已关闭的 chan,写入操作会引发 panic.
3.4.2 case1:写时存在阻塞读协程
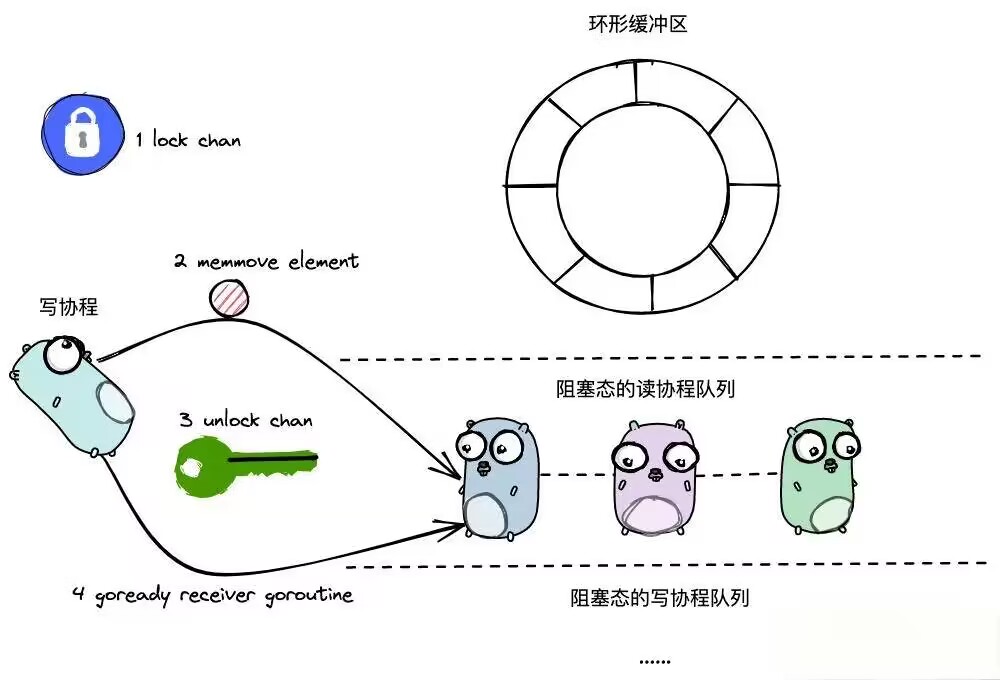
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {// ...// 1. 加锁lock(&c.lock)// ...if sg := c.recvq.dequeue(); sg != nil {// 从阻塞读队列取出一个节点(队首)// 由于这里是一个阻塞的读goroutine,所以里面是又数据的// Found a waiting receiver. We pass the value we want to send// directly to the receiver, bypassing the channel buffer (if any).send(c, sg, ep, func() { unlock(&c.lock) }, 3)// return true}// ..
}(1)写的时候加锁,保证并发安全
(2)从阻塞态协程队列中取出一个 goroutine 的封装对象 sudog;
(3)在 send 方法中,会基于 memmove 方法,直接将元素拷贝交给 sudog 对应的 goroutine;
(4)在 send 方法中会完成解锁动作.
最后通过goready唤醒
这里可能会有点懵懵的感觉,这里其实时读时的阻塞,既然读协程阻塞,那就说明这个管道要么时无缓冲,要么就是没有数据才会导致这个读管道阻塞
具体是一个什么情况呢?
首先就是读操作时,channal没有数据,读取时如果channal为空,则当前goroutine会被挂到 recvq(接受等待队列)的队尾,由于没有数据,他会被阻塞。直到有其他goroutine写入channal的时候,该goroutine的信息就会被封装为一个sudog结构添加到recvq
接着就到了 写操作时,有阻塞的读操作
当执行 ch <- value 写入数据时,如果 recvq 中有等待接收的 goroutine:
- 写操作的
goroutine会直接将数据拷贝到等待队列中队首的sudog(对应的goroutine)。 - 阻塞在队首的读操作会被唤醒,直接拿到该数据,继续执行。
- 此时不会将数据存入环形队列,因为这种情况是直接的 goroutine-to-goroutine 数据传递。
3.4.3 case2:写时无阻塞读协程但环形缓冲区仍有空间
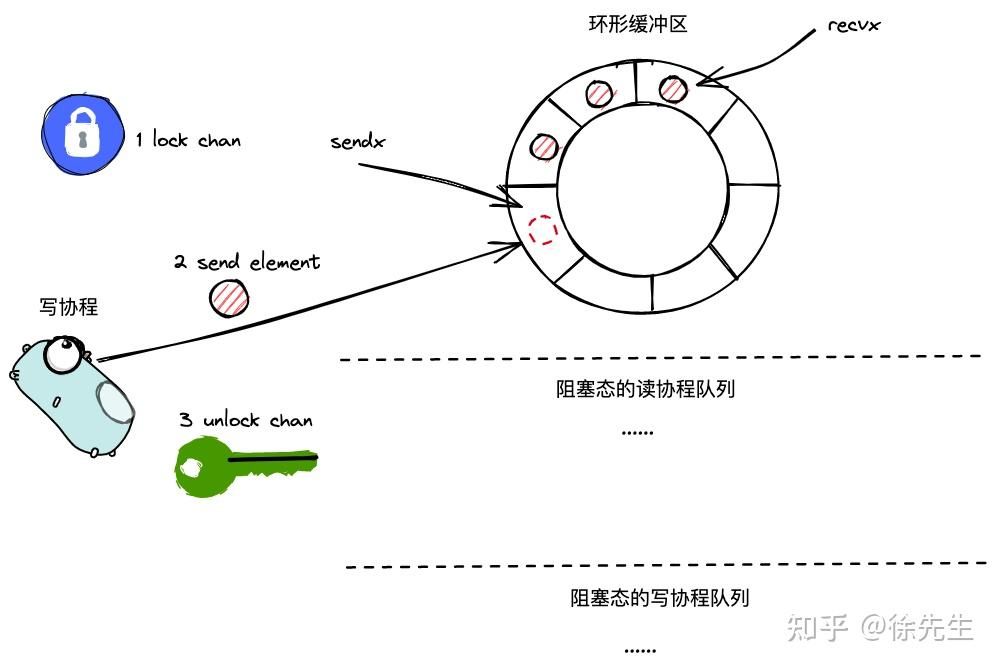
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {// ...lock(&c.lock)//加锁// ...if c.qcount < c.dataqsiz {// qcount是当前缓冲区已有的数据大小 小于 容量// Space is available in the channel buffer. Enqueue the element to send.qp := chanbuf(c, c.sendx)//c.sendx写数据的指针,写到哪个凹槽typedmemmove(c.elemtype, qp, ep)// 把我当前要写的数据拷贝到凹槽c.sendx++// 到下一个凹槽if c.sendx == c.dataqsiz {c.sendx = 0}//判断是否越界c.qcount++ //元素数量加1unlock(&c.lock)return true}// ...
}(1)加锁;
(2)将当前元素添加到环形缓冲区 sendx 对应的位置;
(3)sendx++;
(4)qcount++;
(5)解锁,返回.
写操作时,没有阻塞的读操作
- 如果写入时
recvq是空的: - 写入的数据会被存入
channel的环形队列中(buf)。 - 如果环形队列已满,则写入操作的
goroutine会被挂到sendq(发送等待队列)的队尾,直到有读取操作腾出空间。
优先从sendq中取出数据,接着在从环形队列读取
3.4.4 case3:写时无阻塞读协程且环形缓冲区无空间
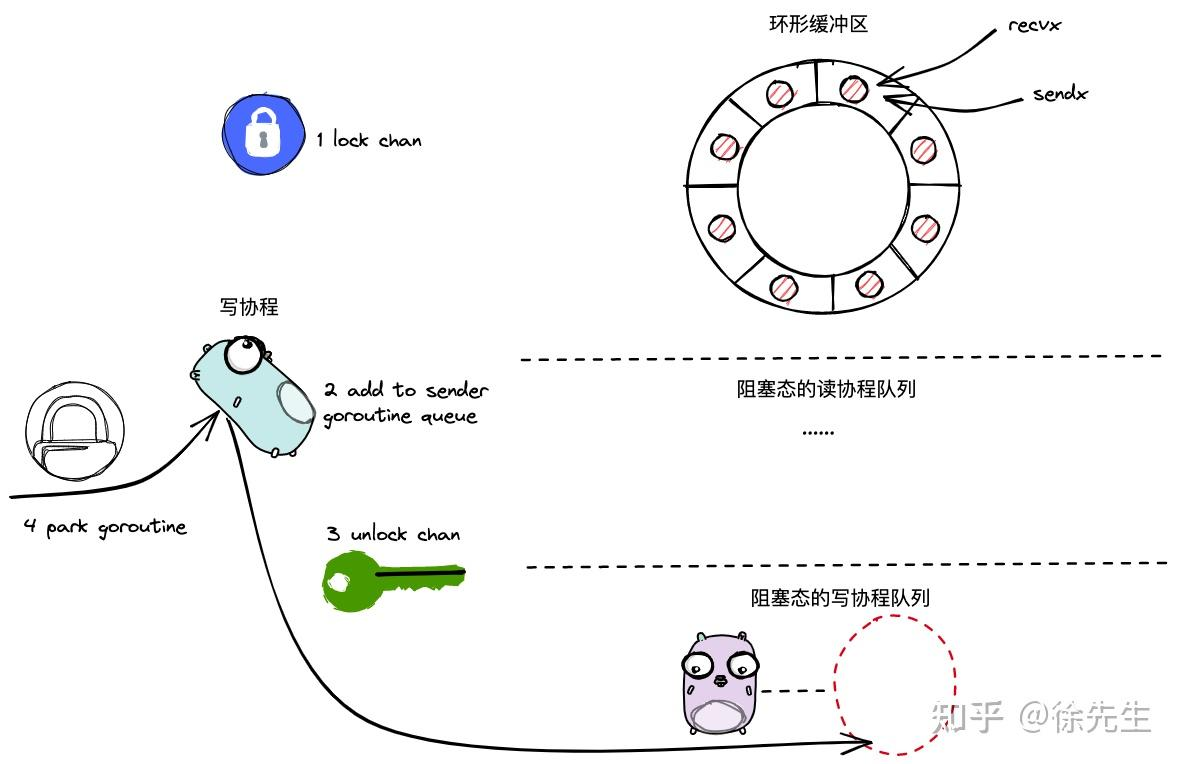
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {// ...lock(&c.lock)// ...gp := getg() //拿到当前goroutine的引用mysg := acquireSudog() // 把当前的goroutine封装成sudogmysg.elem = epmysg.g = gpmysg.c = cgp.waiting = mysgc.sendq.enqueue(mysg) //将封装的sudog加入写协程队列atomic.Store8(&gp.parkingOnChan, 1)gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)// 代码会卡住,后续在读协程的介绍里,会打破这里的,将其唤醒接着进行。gp.waiting = nilclosed := !mysg.successgp.param = nilmysg.c = nilreleaseSudog(mysg)return true
}(1)加锁;
(2)构造封装当前 goroutine 的 sudog 对象;
(3)完成指针指向,建立 sudog、goroutine、channel 之间的指向关系;
(4)把 sudog 添加到当前 channel 的阻塞写协程队列中;
(5)park 当前协程;
(6)倘若协程从 park 中被唤醒,则回收 sudog
(sudog能被唤醒,其对应的元素必然已经被读协程取走,接下来只需要执行回收就可以了);
(7)解锁,返回
前提是没有读协程,目前就是缓冲区buf已经满了,或者没有缓存区
他的一个执行流程就是先加锁,将写协程添加到写协程队列,将其挂起,调用park使其被动阻塞
3.4.5 写流程的一个整体链路
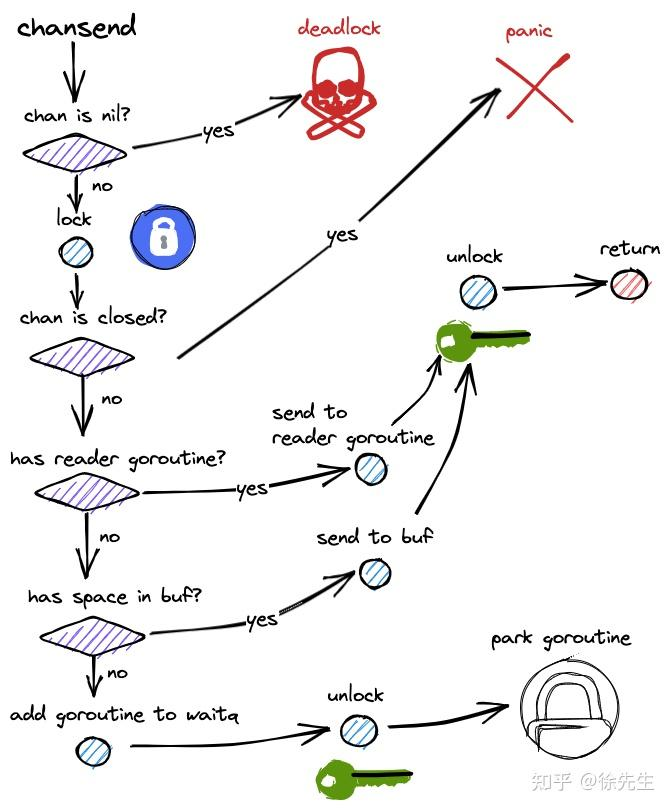
向channal里面写数据,首先会调用routime/chan.go里面的chansend方法
如果chan是nil(也就是未初始化)导致异常阻塞,最后导致deadlock(死锁的问题)
如果不是nil,先加锁,接着判断该channal是否已经关闭,如果已经关闭则报panic
如果没有关闭,接着进行下面的分支:
1.如果存在堵塞读协程,则直接将写协程内容拷贝给读协程,并将其唤醒
2.如果没有阻塞读协程,则首先将内容发buf,如果buf已满,则发给sendq(阻塞写协程队列)(发给sendq的是包装过的goroutine,也就是sudog)
3.发送给sendq的,执行一个gopark操作,进行一个阻塞
后面会被读协程唤醒,唤醒时数据直接被读走
3.5 读流程
3.5.1 异常 case1:读空 channel
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {if c == nil {gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)throw("unreachable")}// ...
}(1)park 挂起,引起死锁;
这里也是导致一个永久阻塞,从而导致死锁的问题。
3.5.2 异常 case2:channel 已关闭且内部无元素
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {lock(&c.lock)if c.closed != 0 {if c.qcount == 0 {unlock(&c.lock)if ep != nil {typedmemclr(c.elemtype, ep)}return true, false}// The channel has been closed, but the channel's buffer have data.} // ...
}(1)直接解锁返回即可
内部无元素,返回的是对应的零值。
3.5.3 case3:读时有阻塞的写协程
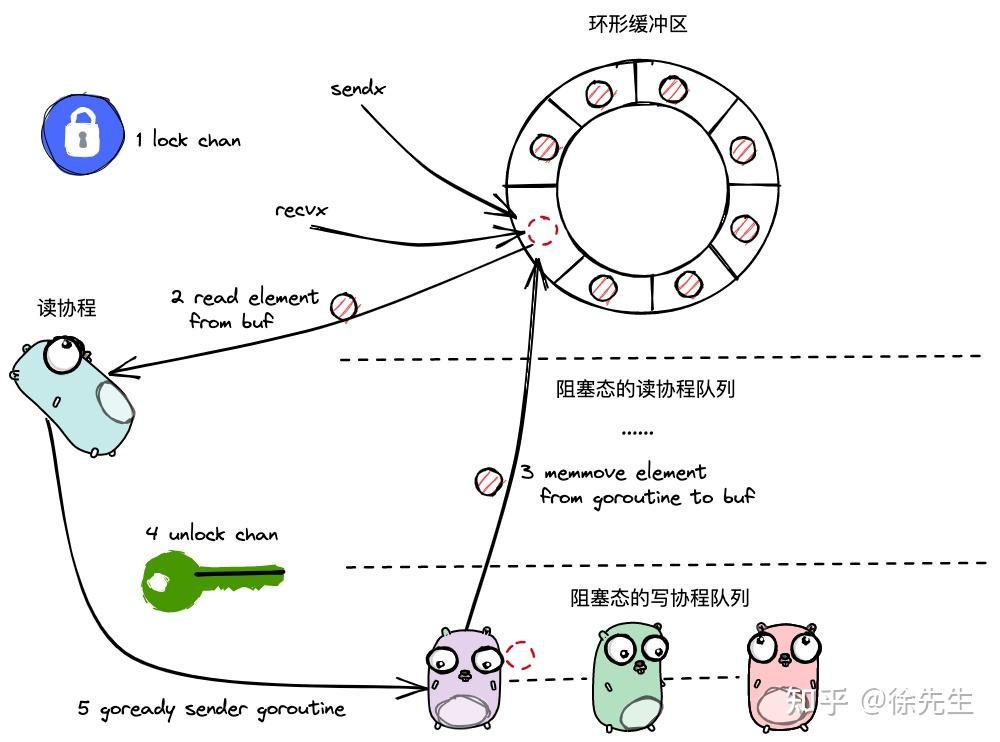
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {lock(&c.lock)// Just found waiting sender with not closed.if sg := c.sendq.dequeue(); sg != nil {// 这里是判断这个sendq里面是否有阻塞队列。recv(c, sg, ep, func() { unlock(&c.lock) }, 3)//这个是对该方法的一个封装,就是具体内容的封装return true, true}
}这个就是上述方法的封装。
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {if c.dataqsiz == 0 {if ep != nil {// copy data from senderrecvDirect(c.elemtype, sg, ep)}} else {// Queue is full. Take the item at the// head of the queue. Make the sender enqueue// its item at the tail of the queue. Since the// queue is full, those are both the same slot.qp := chanbuf(c, c.recvx)if ep != nil {typedmemmove(c.elemtype, ep, qp)}typedmemmove(c.elemtype, qp, sg.elem)c.recvx++if c.recvx == c.dataqsiz {c.recvx = 0}c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz}sg.elem = nilgp := sg.gunlockf()gp.param = unsafe.Pointer(sg)sg.success = truegoready(gp, skip+1)
}(1)加锁;
(2)从阻塞写协程队列中获取到一个写协程;
(3)倘若 channel 无缓冲区,则直接读取写协程元素,并唤醒写协程;
(4)倘若 channel 有缓冲区,则读取缓冲区头部元素,并将写协程元素写入缓冲区尾部后唤醒写协程;
(5)解锁,返回.
首先要知道,什么是情况导致了阻塞的写协程,那肯定就是buf里面的数据已经满了,溢出的在sendq里面
首先第一步是上锁,然后读取是先buf之后才是sendq,将buf队尾数据给读协程,把sendq的队首sudog信息给buf的队尾,然后将这个写协程唤醒。
3.5.4 case4:读时无阻塞写协程且缓冲区有元素
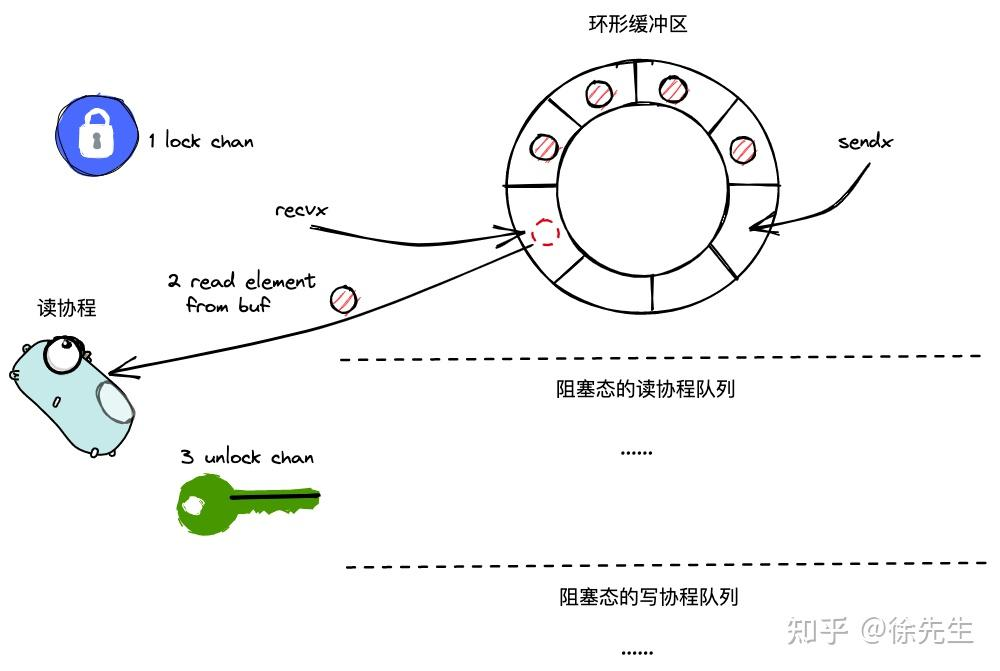
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {lock(&c.lock)if c.qcount > 0 {// Receive directly from queueqp := chanbuf(c, c.recvx)//从这里拿到对应的队首的指针if ep != nil {typedmemmove(c.elemtype, ep, qp)}//把对应的队首的数据给eptypedmemclr(c.elemtype, qp)c.recvx++ //移动指针取出数据,队首指针后移if c.recvx == c.dataqsiz {c.recvx = 0}//到尾部则重新回到首部c.qcount-- //数量-1unlock(&c.lock) //解锁return true, true}
}(1)加锁;
(2)获取到 recvx 对应位置的元素;
(3)recvx++
(4)qcount--
(5)解锁,返回
这个情况是没有阻塞的写协程的情况,buf里面还是有元素,获取里面的队首元素,然后就没了。
操作就是队列的操作,很简单。
3.5.5 case5:读时无阻塞写协程且缓冲区无元素
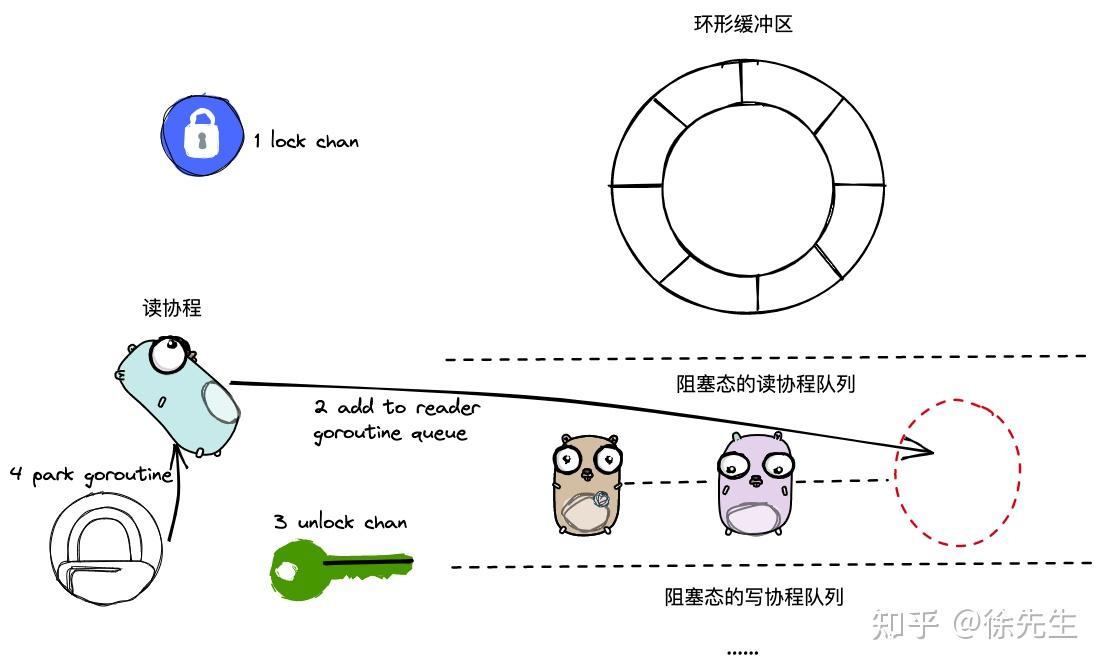
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {lock(&c.lock)gp := getg()mysg := acquireSudog()mysg.elem = epgp.waiting = mysgmysg.g = gpmysg.c = cgp.param = nilc.recvq.enqueue(mysg)atomic.Store8(&gp.parkingOnChan, 1)gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)gp.waiting = nilsuccess := mysg.successgp.param = nilmysg.c = nilreleaseSudog(mysg)return true, success
}(1)加锁;
(2)构造封装当前 goroutine 的 sudog 对象;
(3)完成指针指向,建立 sudog、goroutine、channel 之间的指向关系;
(4)把 sudog 添加到当前 channel 的阻塞读协程队列中;
(5)park 当前协程;
(6)倘若协程从 park 中被唤醒,则回收 sudog(sudog能被唤醒,其对应的元素必然已经被写入);
(7)解锁,返回
这个操作就是 buf 和 sendq 他们里面都没有数据了,这个时候呢先加锁,然后把他封装成一个节点sudog,放入recvq中,这时解锁,然后调用gopark把自己挂起。
当有写的goroutine来的时候,才会唤醒。唤醒不需要考虑数据交互,在唤醒之前就已经做好了数据的交互
3.5.6 读流程整体串联
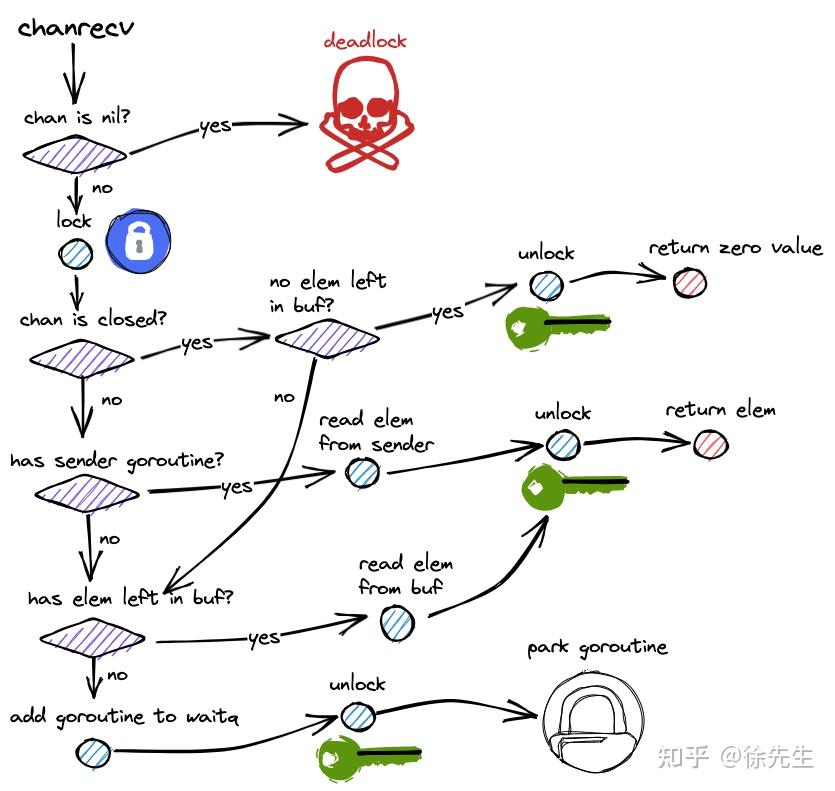
对读流程做一个整体的串联:
首先当我对一个channal进行读取的时候,先判断他是否为nil,如果是的话,就是陷入一个永久阻塞,从而导致死锁的一个问题,如果不是nil,也就是已经初始化了对其进行一个加锁。
接着判断这个chan是否已经关闭,如果已经关闭且没有数据的话就解锁,返回一个零值。
如果没有关闭,就从缓存区的队首拿数据
1.有数据(未溢出)就直接拿出,然后就是队首指针的移动,解锁,最后返回buf队首元素
2.有数据(溢出)直接拿出,指针改变,从recvq里面拿出一个数据给buf,解锁,返回之前buf队首的元素
3.无数据,则将自己封装加入到recvq当中,解锁,然后gopark将自己挂起。
当有写的goroutine来时才会被唤醒
3.6 阻塞与非阻塞模式
在上述源码分析流程中,均是以阻塞模式为主线进行讲述,忽略非阻塞模式的有关处理逻辑.
此处阐明两个问题:
(1)非阻塞模式下,流程逻辑有何区别?
(2)何时会进入非阻塞模式?
3.6.1 非阻塞模式逻辑区别
非阻塞模式下,读/写 channel 方法通过一个 bool 型的响应参数,用以标识是否读取/写入成功.
(1)所有需要使得当前 goroutine 被挂起的操作,在非阻塞模式下都会返回 false;
(2)所有是的当前 goroutine 会进入死锁的操作,在非阻塞模式下都会返回 false;
(3)所有能立即完成读取/写入操作的条件下,非阻塞模式下会返回 true.
3.6.2 何时进入非阻塞模式
默认情况下,读/写 channel 都是阻塞模式,只有在 select 语句组成的多路复用分支中,与 channel 的交互会变成非阻塞模式:
ch := make(chan int)
select{case <- ch:
default:}3.6.3 代码一览
func selectnbsend(c *hchan, elem unsafe.Pointer) (selected bool) {return chansend(c, elem, false, getcallerpc())
}func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected, received bool) {return chanrecv(c, elem, false)
}在 select 语句包裹的多路复用分支中,读和写 channel 操作会被汇编为 selectnbrecv 和 selectnbsend 方法,底层同样复用 chanrecv 和 chansend 方法,但此时由于第三个入参 block 被设置为 false,导致后续会走进非阻塞的处理分支.
四.面试题
一.底层讲解&& 常规面试问题
1.1 Channel的用途? 通信共享内存
1.2 Channel是否并发安全?
1.3 Channel的底层原理?
1.4 Channel 读写流程?
1.5 Select的底层原理?Select可以用来干什么? 一个g服务多个 channel的读写 ,挂起g,加入所有case的等待队列
1.6对nil,关闭,开启的channel进行读写关闭分别会出现什么情况?
二.其他面试问题
1.2 channal是否并发安全?
是并发安全的,它的设计初衷就是为了实现在多个goroutine之间实现安全的传递数据。
而不需要额外的锁机制来防止竞争条件。
1.3 channal的底层原理?
1.4
1.6 nil 已关闭 开启 的channl进行读写会发生什么
| 操作\chan | nil | 已关闭 | 有数据的 |
| 读(<-chan) | 永久阻塞 | 正常执行 | 正常执行 |
| 写 (chan<-) | 永久阻塞 | panic | 正常执行 |
| 关闭(close(chan)) | panic | painc | 正常执行 |