【大模型架构-Transformer、Mamba、Hyena】
大模型架构-Transformer、Mamba、Hyena
- 序列建模发展基本信息总结
- 计算步骤对比(输入为字母序列时)
- 计算步骤解释(输入为字母序列时)
- BERT参数量计算
个人学习自用,一些解释限于仅处理字母序列,有错误或不准确的地方欢迎指正
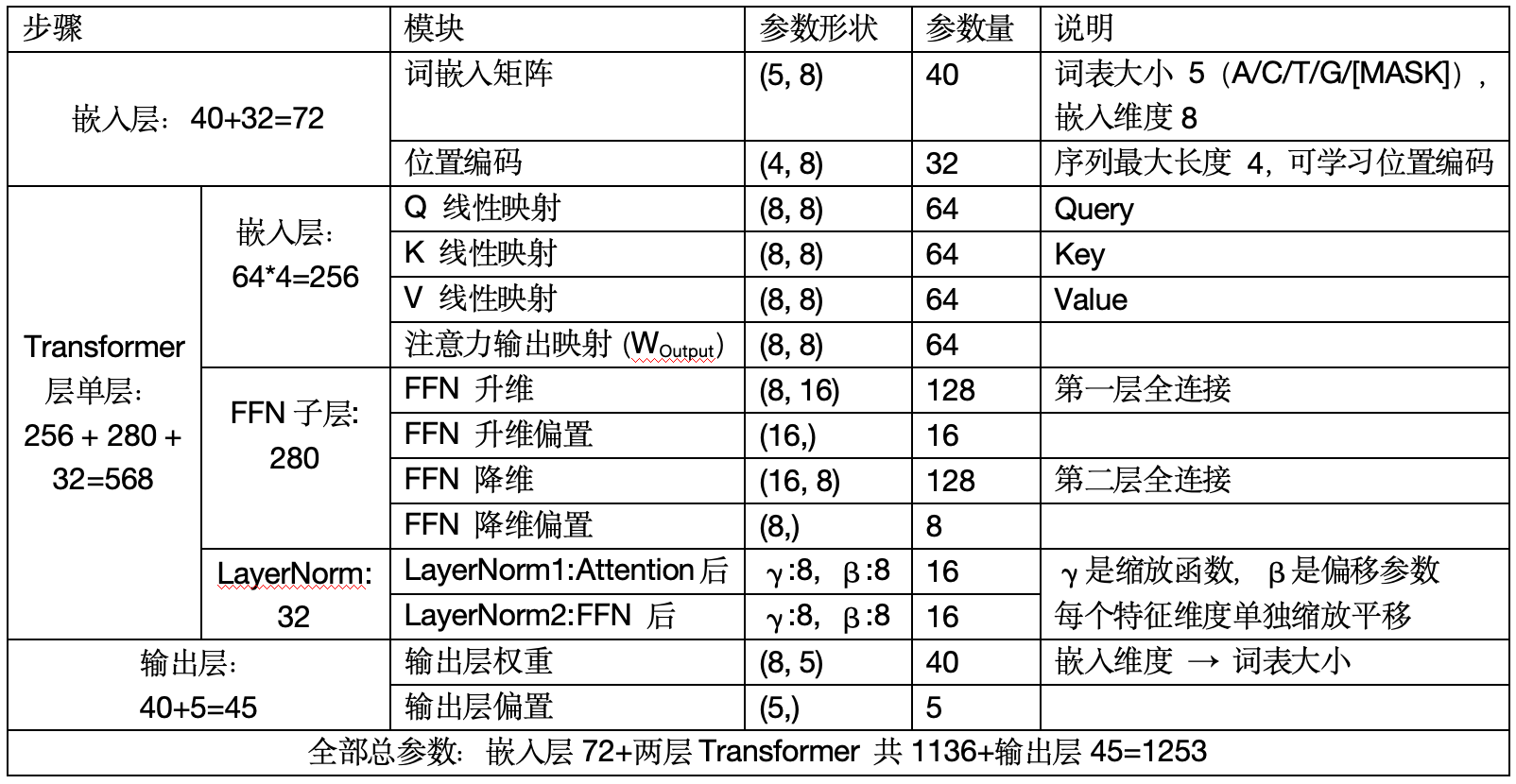
序列建模发展基本信息总结
| 模型架构 | 提出年份 | 引用量(截至25.5.3) | 核心机制 | 变体模型 | 时间复杂度 | 长距离建模 | 并行性 | 输入变化 | 后续传播 | 适用场景 |
|---|---|---|---|---|---|---|---|---|---|---|
| RNN/LSTM/GRU | 1980/1997/2014 | \ | 递归结构 | \ | O(n) | 差/好/较好 | 差 | \ | \ | 短序列建模/长序列建模/资源受限场景 |
| Transformer NIPS会议 | 2017.6 (谷歌) | 178283 | 自注意力机制 | BERT / GPT | O(n²) 超长序列受限 | 优秀 | 优秀 | token→嵌入(+位置编码)→Q/K/V | 全局注意力 | 长序列建模,主流NLP任务 |
| Mamba 仅预印本 | 2023.12(卡内基梅隆大学) | 3113 | 状态空间更新 | Vision Mamba | O(n) | 优秀 | 优秀 | token→嵌入→动态状态更新参数 | 状态更新 | 多模态长序列建模 |
| Hyena ICML会议 | 2023.2(斯坦福大学) | 347 | 长卷积+门控 | Striped Hyena | O(N log L) | 优秀 | 优秀 | token→嵌入→门控+卷积核生成 | 卷积 | 超长序列建模,生物序列等领域 |
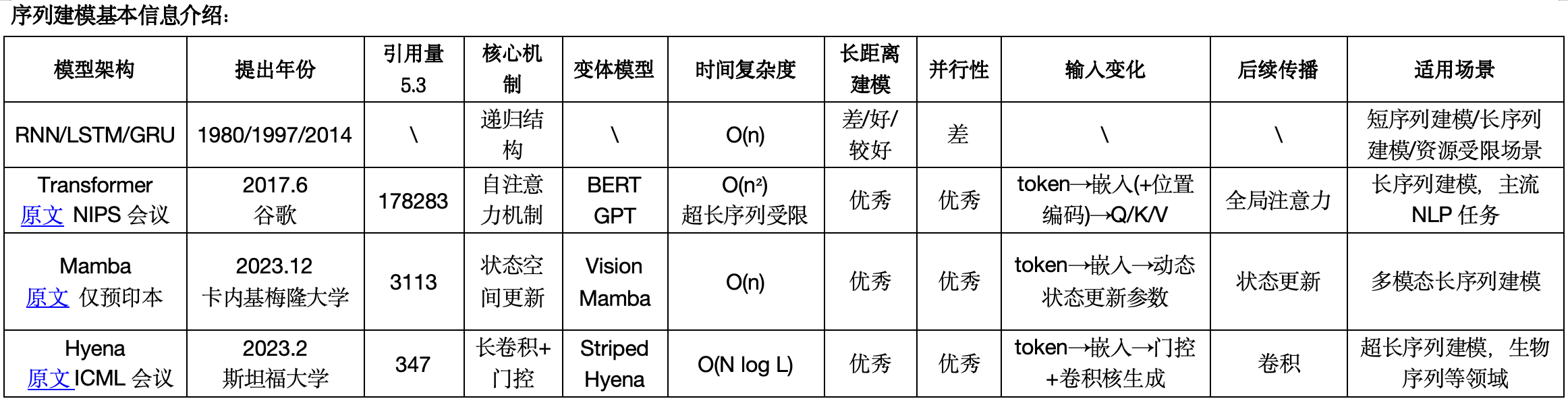
计算步骤对比(输入为字母序列时)
| 步骤 | Transformer | Mamba | Hyena | 异同 |
|---|---|---|---|---|
| 1. 分词 | 需要 | 需要 | 需要 | 相同 |
| 2. 词嵌入 | token 映射为向量 | token 映射为向量 | token 映射为向量 | 相同 |
| 3. 位置编码 | 必须,否则序列无顺序感 | 可选,SSM 隐顺序 | 可选,卷积天然顺序感知 | 不同 |
| 4. 投影 (X: 嵌入;W: 权重) | Q = X ⋅ W Q Q = X \cdot W_Q Q=X⋅WQ K = X ⋅ W K K = X \cdot W_K K=X⋅WK V = X ⋅ W V V = X \cdot W_V V=X⋅WV Q 查询向量,KV 键值对 | 状态空间输入向量: u t = X ⋅ W p r o j u_t = X \cdot W_{proj} ut=X⋅Wproj | 门控准备: z t = σ ( X ⋅ W g a t e ) z_t = \sigma(X \cdot W_{gate}) zt=σ(X⋅Wgate) 卷积准备: h t = X ⋅ W c o n v _ p r o j h_t = X \cdot W_{conv\_proj} ht=X⋅Wconv_proj | 不同 |
| 5. 主干运算 | 注意力得分: scores = Q K T d \text{scores} = \frac{QK^T}{\sqrt{d}} scores=dQKT 注意力输出: attn_out = softmax(scores) ⋅ V \text{attn\_out} = \text{softmax(scores)} \cdot V attn_out=softmax(scores)⋅V 前馈映射: FFN = MLP(attn_out) \text{FFN} = \text{MLP(attn\_out)} FFN=MLP(attn_out) | 动态矩阵: A ( x t ) , B ( x t ) , C ( x t ) , D ( x t ) A(x_t), B(x_t), C(x_t), D(x_t) A(xt),B(xt),C(xt),D(xt) 状态更新: h t = A ( x t ) ⋅ h t − 1 + B ( x t ) ⋅ x t h_t = A(x_t) \cdot h_{t-1} + B(x_t) \cdot x_t ht=A(xt)⋅ht−1+B(xt)⋅xt 输出: y t = C ( x t ) ⋅ h t + D ( x t ) ⋅ x t y_t = C(x_t) \cdot h_t + D(x_t) \cdot x_t yt=C(xt)⋅ht+D(xt)⋅xt | 长卷积计算: conv_out = h t ∗ k ( τ ) \text{conv\_out} = h_t * k(\tau) conv_out=ht∗k(τ) K ( t ) K(t) K(t) 卷积核长度为 t t t | 不同 |
| 6. 非线性激活 | 前馈网络内使用 如 ReLU / GeLU | 可选激活 SiLU 或其他 | 卷积后 ReLU / SiLU 激活 | 相似,位置不同 |
| 7. 残差连接 | Attention 和 FFN 输出加残差 | SSM 输出加残差 | 卷积输出加残差 | 相同 |
| 8. 层归一化 | 每子层后 LayerNorm | 每 SSM/模块后 LayerNorm | 每模块块后 LayerNorm | 相同 |
| 9. 输出层 | 线性变换 + Softmax 分类或回归 | 线性映射 + 分类或回归 | 卷积输出或后接 MLP | 不同 |
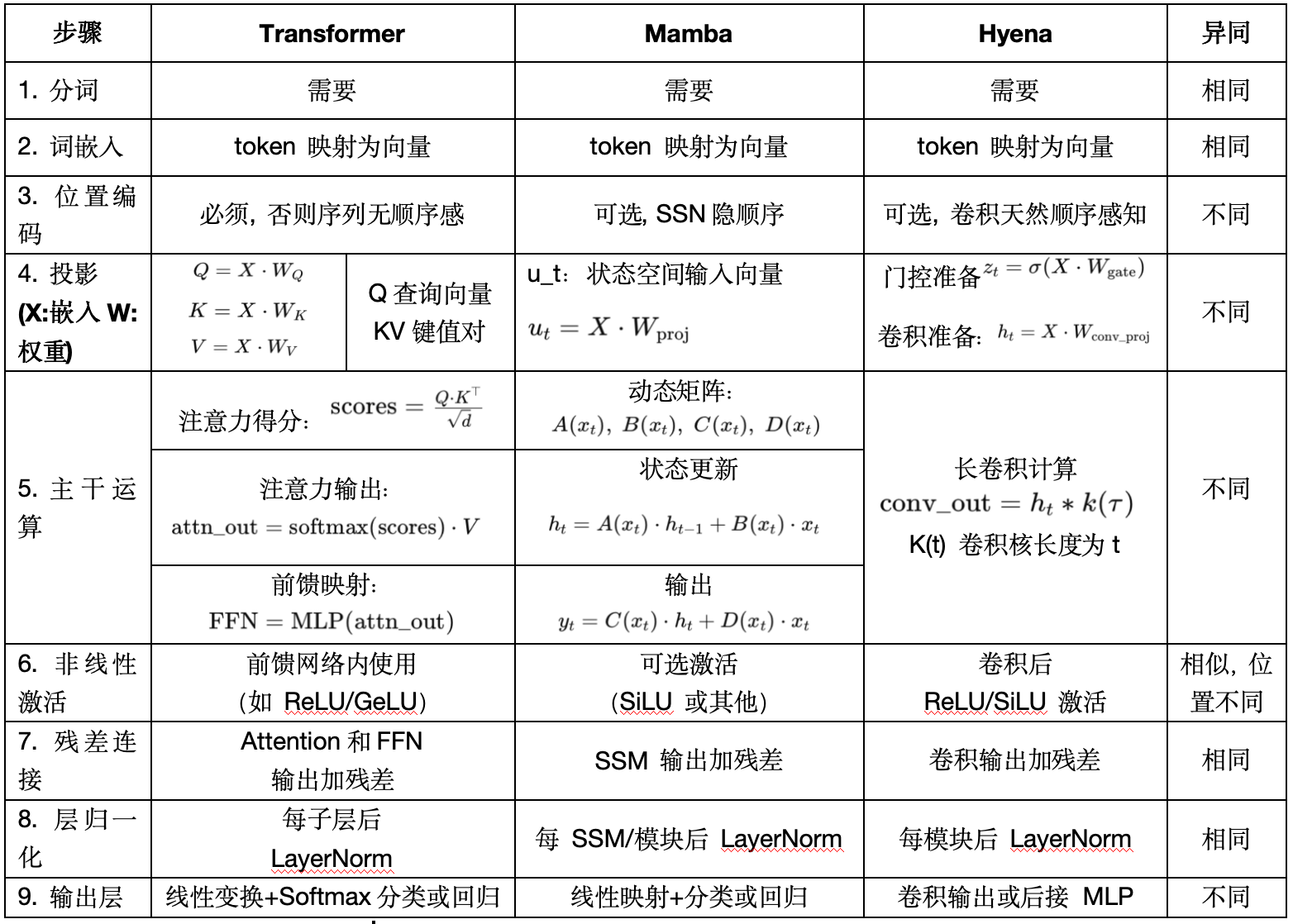
计算步骤解释(输入为字母序列时)
| 模型 | 主干运算解释 | 输入嵌入 Tokenization + Embedding | 输入嵌入 位置编码 | 公式解释补充 对应下表 5.主干运算补充 |
|---|---|---|---|---|
| Transformer 核心: 自注意力机制 | 1. 多头自注意力机制 (Multi-Head Self-Attention): 模型在不同表示的子空间中并行地关注不同位置。 2. 前馈神经网络 (Feed-Forward Neural Network, FFN): 对每个位置的表示进行非线性变换。 | DNA Tokenize: k-mer、BPE、单碱基、可学习分词… Embedding: 将每个 token 转为向量(词嵌入矩阵) | Transformer 需添加位置编码,引入序列中 token 位置信息。 | QKV → softmax → FFN 计算 token 间相似度 聚合值向量 提取深层特征 |
| Mamba 核心: 结构化状态空间模型 | 1. 卷积层 (Convolution):捕捉局部上下文信息。 2. 选择性状态空间模块 (Selective SSM): 动态地建模序列中的长期依赖关系。 | 同上 | Mamba、Hyena 内部机制保留顺序依赖, 因此不使用位置编码,或使用简单增量偏置。 | 状态更新 → 选择性机制 A(x):控制前一状态的更新比例 B(x):控制当前输入对状态的影响 C(x):控制状态对最终输出的影响 D(x):控制输入对最终输出的影响 |
| Hyena 核心: 隐式长卷积 | 1. 门控机制 (Gating Mechanism):控制信息流动。 2. 长卷积 (Long Convolution):捕捉长距离依赖关系。 | 同上 | 同上 | 隐式卷积 → 门控 控制信息前后强化/弱化 准备卷积输入、执行长距离卷积(FFT 实现) |
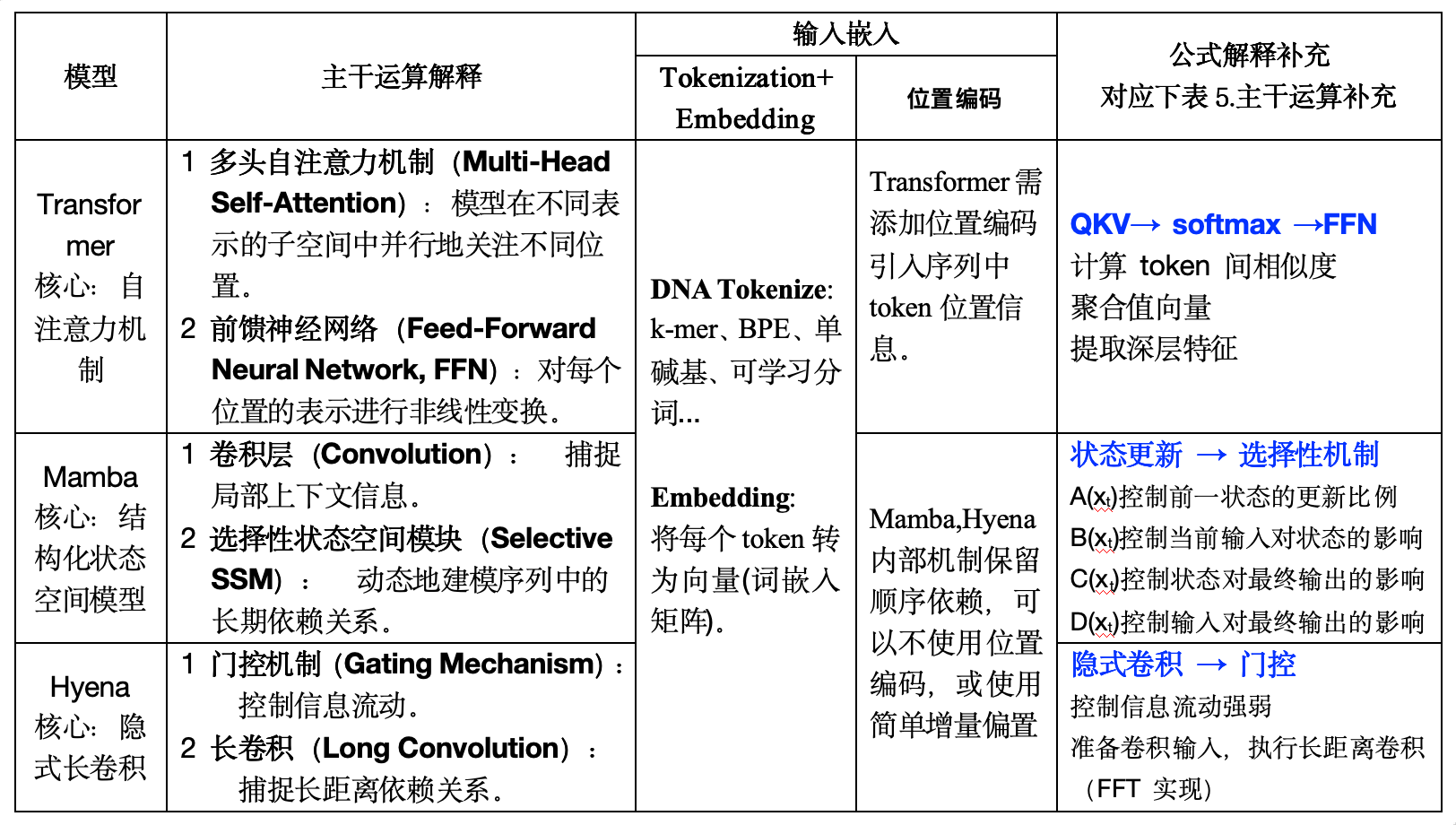
BERT参数量计算
BERT参数量 = embedding层参数 + 层数 * 各层的参数 + 输出层参数。
假设训练此BERT,就1条训练数据(ACTG)长度为4,共2层Transformer,隐藏层维度hidden_size=8
| 步骤 | 模块 | 参数形状 | 参数量 | 说明 |
|---|---|---|---|---|
| 嵌入层:40+32=72 | 词嵌入矩阵 | (5, 8) | 40 | 词表大小 5 (A/C/T/G/[MASK]),嵌入维度 8 |
| 位置编码 | (4, 8) | 32 | 序列最大长度 4,可学习位置编码 | |
| 投影层:64×4 = 256 | Q 线性映射 | (8, 8) | 64 | Query |
| K 线性映射 | (8, 8) | 64 | Key | |
| V 线性映射 | (8, 8) | 64 | Value | |
| 注意力输出映射 ( W o u t p u t W_{output} Woutput) | (8, 8) | 64 | ||
| FFN 子层:280 | FFN 升维 | (8, 16) | 128 | 第一层全连接 |
| FFN 升维偏置 | (16,) | 16 | ||
| FFN 降维 | (16, 8) | 128 | 第二层全连接 | |
| FFN 降维偏置 | (8,) | 8 | ||
| LayerNorm:32 | LayerNorm1:Attention 后 | γ: (8,), β: (8,) | 16 | γ 是缩放函数,β 是偏移参数 |
| LayerNorm2:FFN 后 | γ: (8,), β: (8,) | 16 | 每个特征维度单独缩放平移 | |
| 输出层:40+5=45 | 输出层权重 | (8, 5) | 40 | 嵌入维度 → 词表大小 |
| 输出层偏置 | (5,) | 5 | ||
| 全部总参数:嵌入层 72 + 两层 Transformer 共 1136 + 输出层 45 = 1253 |