【2025最新】Baichuan-M1-instruct部署教程
首先机器至少要A100、4090、3090
这里选AutoDL的4090D,运行至少要20G显存。这里镜像选基础镜像11.8【更新!!!!!!!!!24G带不动!显存不够】
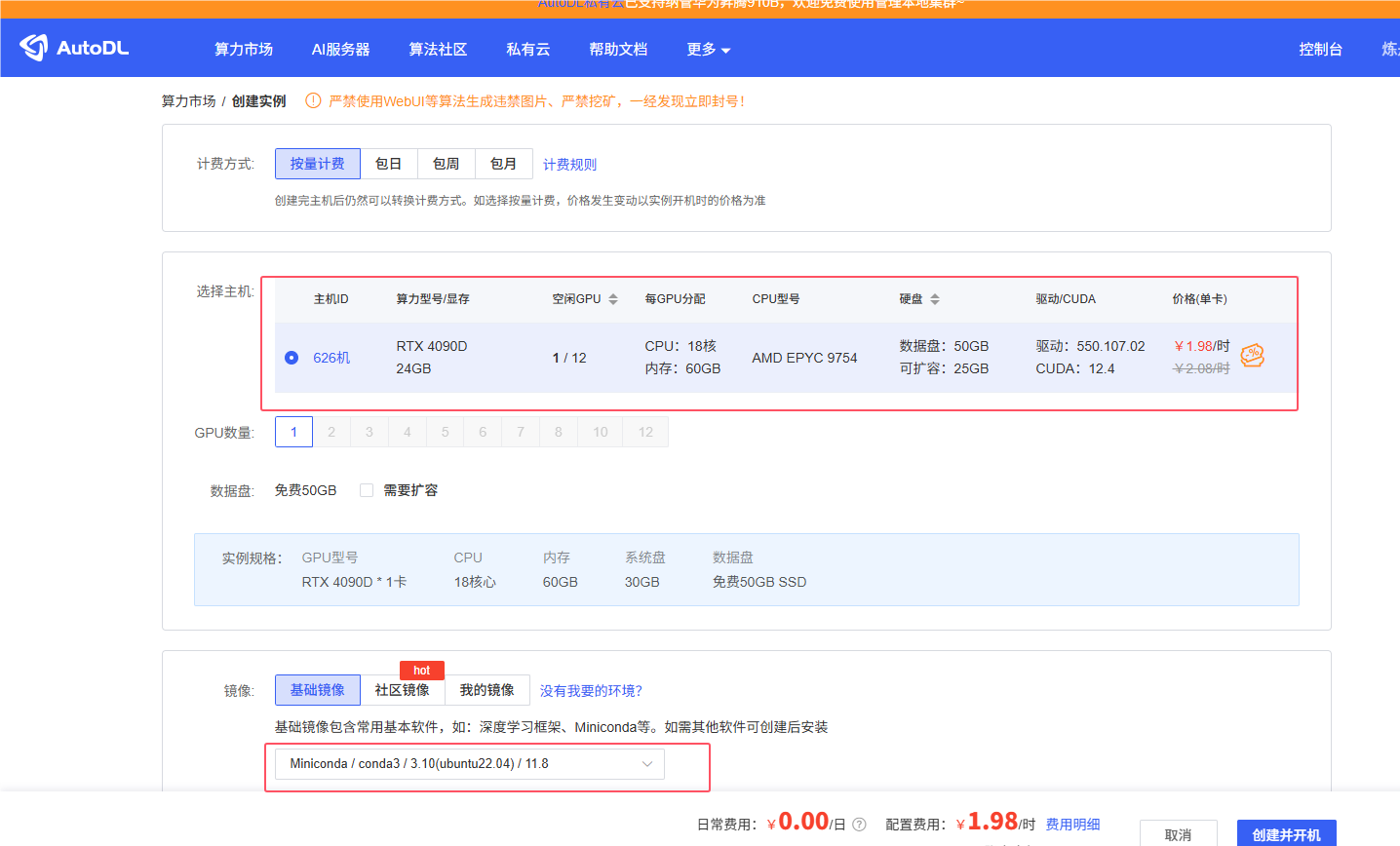
有时候会看见两种不同的4090,这里解释一下。选4090D主要是因为便宜:
RTX 4090 和 RTX 4090D 存在多方面的区别,具体如下:
- 核心规格3:
- CUDA 核心数量:RTX 4090 拥有 16,384 个 CUDA 核心,而 RTX 4090D 的 CUDA 核心数量为 14,592 个,相比 4090 减少了约 11%。
- SM 单元:RTX 4090 有 128 个 SM 单元,RTX 4090D 为 114 个。
- Tensor 核心:RTX 4090 有 512 个 Tensor 核心,RTX 4090D 有 456 个,减少了大约 11%。
- RT 核心:RTX 4090 有 128 个光线追踪核心,RTX 4090D 有 114 个。
- 频率:RTX 4090 基础频率为 2,235MHz,RTX 4090D 为 2,280MHz,两者加速频率相同,均为 2,520MHz。
- 性能表现6:
- 理论性能:RTX 4090D 的性能约为 RTX 4090 性能的 95%,两者有 5% 左右的性能差距。
- 游戏性能:在 3DMark 基准测试中,RTX 4090D 跑分落后 RTX 4090 约 5%-8%。在 4K 光栅化游戏测试中,RTX 4090D 的游戏帧数比 RTX 4090 弱 5.5% 左右;在 4K 光追游戏测试和 4K DLSS 游戏测试中,RTX 4090D 的游戏帧数比 RTX 4090 弱 5.8% 左右。
- AI 推理性能:在 AI 推理测试中,RTX 4090D 的单精度和双精度浮点运算性能与 RTX 4090 的差距约为 5%,整数性能仅落后 2.6%。
- 功耗散热3:
- 功耗:RTX 4090 的功耗为 450W,对系统电源要求较高。RTX 4090D 的功耗约为 420-425W,相对更节能。
- 散热:由于功耗较低,RTX 4090D 温度控制更稳定,适合长时间高负载运行。
- 市场定位与价格3:
- 市场定位:RTX 4090 是面向全球市场的旗舰显卡;RTX 4090D 是为满足中国市场需求、规避美国政府对尖端 AI 智能芯片的管制而推出的特供版。
- 价格:两款显卡首发定价都是 12,999 元,但 RTX 4090 现在在国内仍然处于禁售状态,从非官方渠道购买最便宜的价格也得 15,000 元以上;4090D 显卡各显卡品牌官方店有在售,价格普遍更便宜,也更容易入手。
- 其他特性3:RTX 4090 可超频,而 RTX 4090D 锁定了超频功能。不过,两者均搭载 24GB GDDR6X 显存,位宽 384bit,带宽 1,008GB/s,并且都支持 NVIDIA 的 DLSS 3 技术和双 AV1 编码器。
链接服务器:
先往数据盘传一下这个文件,对应cuda11、torch2.5、python3.12

新建环境
conda create -n baichuanm1 python=3.12.9
加载环境
source ~/.bashrc
如果环境安装错了,用下面的命令卸载:
conda env remove -n baichuanm1
激活环境以后:
pip install sentencepiece
pip install einops==0.8.0
pip install torch==2.5.0
pip install torchvision==0.20.0
pip install torchaudio==2.5.0
确认一下环境:
查看cuda版本,cuda版本为V11.8.89
nvcc -V
(myenv) root@autodl-container-6c3e4aa234-8adeb2ea:~# nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
接着把这个包安装一下 pip install ,注意这个包对应的是cuda11、torch2.5、python3.12,其它情况对应的包在这里找:
Releases · Dao-AILab/flash-attention · GitHub
![]()
接下来下载模型,把这个文件传到服务器并运行
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('baichuan-inc/Baichuan-M1-14B-Instruct',cache_dir='/root/autodl-tmp/')运行测试代码看看效果,这里注意bachuanM1-14B-instruct只支持16位量化
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import os#os.environ["CUDA_VISIBLE_DEVICES"] = "7"
# 1. Load pre-trained model and tokenizer
model_name = "/root/autodl-tmp/baichuan-inc/Baichuan-M1-14B-Instruct/"
tokenizer = AutoTokenizer.from_pretrained(model_name,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name,trust_remote_code=True,torch_dtype = torch.bfloat16).cuda()
# 2. Input prompt text
prompt = "May I ask you some questions about medical knowledge?"# 3. Encode the input text for the model
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "please introduce yourself"}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# 4. Generate text
generated_ids = model.generate(**model_inputs,max_new_tokens=512
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]# 5. Decode the generated text
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]# 6. Output the result
print("Generated text:")
print(response)