改进算法超详细:双变异樽海鞘群算法:从最优性能设计到分析
2.5 樽海鞘算法 (SSA)
基于Mirjalili等人近年来对樽海鞘的发现,提出了SSA。基本SSA的运动过程简化为以下重要步骤:
步骤1:初始化一些重要参数,包括种群大小 ( N N N)、问题维度 ( D D D)、问题上界 ( u b ub ub)、问题下界 ( l b lb lb) 和最大评估次数 ( M a x F E s MaxFEs MaxFEs)。
步骤2:根据以下公式获得第一代樽海鞘群,然后我们得到 N N N 个樽海鞘个体。每个人包含一个 D D D 维变量,每个变量是对应上界 u b ub ub 和下界 l b lb lb 之间的随机值。
X = initialization ( N , D , u b , l b ) (1) X = \text{initialization}(N, D, ub, lb) \tag{1} X=initialization(N,D,ub,lb)(1)
步骤3:将樽海鞘个体单独带入函数中进行评估。同时,记录每个个体的适应度值,并在其中获得 F o o d P o s i t i o n FoodPosition FoodPosition,它是樽海鞘的食物来源和当前最优解。
X F i t n e s s i = function ( X i ) (2) XFitness_i = \text{function}(X_i) \tag{2} XFitnessi=function(Xi)(2)
[ F o o d F i t n e s s , minIndex ] = min ( X F i t n e s s ) (3) [FoodFitness, \text{minIndex}] = \text{min}(XFitness) \tag{3} [FoodFitness,minIndex]=min(XFitness)(3)
F o o d P o s i t i o n = X minIndex (4) FoodPosition = X_{\text{minIndex}} \tag{4} FoodPosition=XminIndex(4)
步骤4:进入主循环,SSA开始寻找最优操作。循环的结束条件是达到 M a x F E s MaxFEs MaxFEs。SSA将樽海鞘群分为领导者和跟随者。公式(6)是领导者更新位置的核心机制。其中, c 2 c_2 c2 是服从均匀分布的随机数。简单来说,每个领导者以食物来源(当前最优解)为起点,根据每个变量的上界和下界选择相应的随机值,并根据食物来源探索空间。但上述方法不利于解的收敛,因此SSA有其关键参数 c 1 c_1 c1。从公式(5)可以看出,该变量随着评估次数的增加而连续减少。因此,根据评估次数的时间轴,每个领导者逐渐从大尺度搜索过渡到小尺度探索,即使超出变量范围。值得一提的是,这一过程使算法难以在后期陷入局部最优。公式(7)是种群跟随者的更新公式。像樽海鞘链一样,在现实中,每个跟随者将跟随前一个个体(取平均值)。
c 1 = 2 e − ( 4 × F E s / M a x F E s ) (5) c_1 = 2e^{-(4 \times FEs / MaxFEs)} \tag{5} c1=2e−(4×FEs/MaxFEs)(5)
X j = F o o d P o s i t i o n ± c 1 × ( ( u b j − l b j ) × c 2 + l b j ) (6) X_j = FoodPosition \pm c_1 \times ((ub_j - lb_j) \times c_2 + lb_j) \tag{6} Xj=FoodPosition±c1×((ubj−lbj)×c2+lbj)(6)
X i = ( X j + X j − 1 ) / 2 (7) X_i = (X_j + X_{j-1}) / 2 \tag{7} Xi=(Xj+Xj−1)/2(7)
步骤5:在领导者和种群中的所有跟随者都更新后,SSA重新评估整个种群的位置,选择最佳位置作为新的食物来源,并开始下一轮循环。当然,在评估之前,所有解必须在边界内处理,因为步骤4中的大规模搜索很容易超出范围。
基本SSA的伪代码可以通过整合上述步骤获得,如算法1所示。图1是基本SSA的流程图。
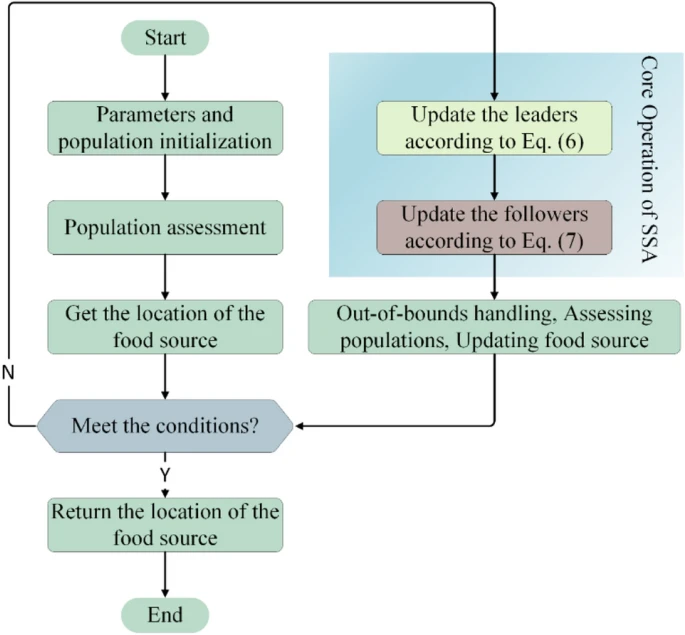
图1. 基本SSA的流程图

3 提出的方法
从上一节对基本SSA的描述中可以看出,SSA只有两个简单的核心公式,在一定程度上具有一定的优化能力。因此,SSA有很好的应用,如引言中所述。然而,基本SSA的优化能力仍有改进的空间,特别是在问题变得更加复杂时。在此基础上,我们提出了一种新的和改进的SSA,即DMSSA。它使用两种突变策略,一种是CMS,另一种是ADMS。
3.1 基本SSA的不足
从步骤4中可以发现,无论它们是领导者还是追随者,它们对种群信息的使用都不足以与其他MAS相比。具体来说,领导者以当前最优解为起点,通过自动生成的随机值进行探索。尽管追随者使用了前一个个体的信息,实验结果似乎影响不大。另一方面,重要参数 c 1 c_1 c1与整个算法的收敛性有关。因为这个参数在算法优化的后期呈指数级下降,无论每个解是否愿意,它们都被迫参与到探索任务中,这很容易陷入某些问题的局部优化困境。
3.2 CMS
受益于杜鹃独特繁殖方法的启发,Gandomi等人[3]提出了CS。因为杜鹃本身既不筑巢也不孵化它的蛋,而是把它的蛋放在鸟的巢里。当杜鹃蛋与巢中的蛋相似时,候选解具有良好的适应度;它们可以存活而不被遗弃。当宿主鸟发现蛋的差异时,它可能会丢弃异卵蛋或直接放弃整个巢以在新的地方建立新巢;也就是说,候选解的适应度不足以存活到下一代。因此,它参与了后续的突变过程。
CMS大致分为三个基本操作:判断、洗牌和突变。
判断:具体来说,宿主鸟判断巢中是否有异卵蛋的过程被抽象为以下公式:
K = rand ( size(nest) ) > P a (8) K = \text{rand}(\text{size(nest)}) > Pa \tag{8} K=rand(size(nest))>Pa(8)
假设巢是搜索代理,Pa是0和1之间的一个概率值,宿主鸟判断巢中蛋的标准。通过将随机数与标准Pa进行比较,我们得到一个0和1的数字矩阵。从这个矩阵中,我们可以知道每个搜索代理需要参与突变的变量(它们被标记为异卵蛋)以及哪些变量被保留(它们成功存活)。
洗牌:洗牌操作如下:
stepsize = rand ∗ nest_diff (9) \text{stepsize} = \text{rand} * \text{nest\_diff} \tag{9} stepsize=rand∗nest_diff(9)
其中rand是一个在0和1之间的随机值,服从均匀分布,nest_diff用于提取不同候选解之间的差异。具体操作可以是将种群中个体的顺序打乱两次(即洗牌操作),然后相减得到nest_diff。这些差异包括解空间中各种探索的方向和大小。
突变:突变操作是接管前两个操作并实现最终位置更新。公式如下所示。
new_nest = nest + stepsize ∗ K (10) \text{new\_nest} = \text{nest} + \text{stepsize} * K \tag{10} new_nest=nest+stepsize∗K(10)
很容易知道,当K的值为0时,候选解中的变量不受影响。相反,变量通过添加不同候选解之间的差异来获得新的解决方案,希望在下一代筛选中存活。这些解决方案充分考虑了不同解决方案之间的信息,并尝试探索解空间。这对于增加种群的多样性和摆脱局部最优是有益的。
3.3 ADMS
ADMS使用三个基本操作:选择、突变和适应。
选择和突变:在本节中,我们采用另一种突变策略,“DE/current-to-best”。基本DE/current-to-best可以采用以下形式:
X i , t + 1 = X i , t + F ( X best , t − X i , t + X r 1 , t − X r 2 , t ) (11) X_{i,t+1} = X_{i,t} + F \left( X_{\text{best},t} - X_{i,t} + X_{r1,t} - X_{r2,t} \right) \tag{11} Xi,t+1=Xi,t+F(Xbest,t−Xi,t+Xr1,t−Xr2,t)(11)
从上述公式可以看出,第t代的第i个个体通过突变操作生成第(t + 1)代的个体。更重要的是,变异的来源来自全局最优解、当前解和两个其他非重复解的线性组合。虽然添加两个非重复解将增强解空间的探索,但以牺牲收敛速度为代价。因此,上述公式修改如下:
X i , t + 1 = X i , t + F ( X best , t − X r 1 , t − 1 + X r 1 , t − X r 2 , t ) (12) X_{i,t+1} = X_{i,t} + F \left( X_{\text{best},t} - X_{r1,t-1} + X_{r1,t} - X_{r2,t} \right) \tag{12} Xi,t+1=Xi,t+F(Xbest,t−Xr1,t−1+Xr1,t−Xr2,t)(12)
与前一个公式的不同之处在于,变异的来源被更改为第t代解和第(t - 1)代解的线性组合。具体来说, X i , t X_{i,t} Xi,t是突变的起点,它需要突变的方向和大小。而 X best , t − X r 1 , t − 1 X_{\text{best},t} - X_{r1,t-1} Xbest,t−Xr1,t−1提供了全局最优解的参考,这是探索和优化中最重要的值。其次, X r 1 , t − X r 2 , t − 1 X_{r1,t} - X_{r2,t-1} Xr1,t−Xr2,t−1提供了两代之间差异的信息。因为前一代种群通过适者生存生成下一代种群,两代之间的差异为种群对最优解的探索提供了方向和大小。
适应性:值得一提的是,随着迭代次数的增加,F应该继续减小,因为 X i , t X_{i,t} Xi,t对变异来源的参考程度在减小,但它不会减小到零。同时,交叉率CR也应该有一个类似的过程。因此,候选解从大规模探索逐渐过渡到小规模探索。受JADE [77]的启发,变异因子F和交叉率CR被自适应地给出,具体形式如下:
C R ∼ N ( μ C R , σ C R ) (13) CR \sim N \left( \mu_{CR}, \sigma_{CR} \right) \tag{13} CR∼N(μCR,σCR)(13)
F ∼ C ( γ , μ F ) (14) F \sim C \left( \gamma, \mu_F \right) \tag{14} F∼C(γ,μF)(14)
μ C R = ( 1 − c ) ⋅ μ C R + c ⋅ mean A ( S C R ) (15) \mu_{CR} = (1 - c) \cdot \mu_{CR} + c \cdot \text{mean}_A \left( S_{CR} \right) \tag{15} μCR=(1−c)⋅μCR+c⋅meanA(SCR)(15)
μ F = ( 1 − c ) ⋅ μ F + c ⋅ mean L ( S F ) (16) \mu_F = (1 - c) \cdot \mu_F + c \cdot \text{mean}_L \left( S_F \right) \tag{16} μF=(1−c)⋅μF+c⋅meanL(SF)(16)
mean L ( S F ) = ∑ F ∈ S F F 2 ∑ F ∈ S F F (17) \text{mean}_L \left( S_F \right) = \frac{\sum_{F \in S_F} F^2}{\sum_{F \in S_F} F} \tag{17} meanL(SF)=∑F∈SFF∑F∈SFF2(17)
其中交叉率CR服从正态分布, σ C R \sigma_{CR} σCR固定为0.1。变异因子F服从柯西分布, γ \gamma γ也设置为0.1。 μ C R \mu_{CR} μCR和 μ F \mu_F μF的初始值都设置为0.5。此外,将CR调整到[0, 1]的范围,并将F调整到(0, 1]的范围。与正态分布相比,柯西分布趋于更加渐进,使解决方案无论在哪个时期都保持足够的活力来探索全局最优解。顺便说一下,上述超参数的设置都来自JADE [77]的文献。
在 S C R S_{CR} SCR和 S F S_F SF中分别存储了每次成功的交叉率CR和变异因子F。此外,本研究中给出的存储阈值设置为追随者的数量。如果超过阈值,多余的数量将被随机删除。计算外部存储 S C R S_{CR} SCR的算术平均值,并计算外部存储 S F S_F SF的Lehmer平均值,如公式(17)所示。在每次迭代结束时, μ C R \mu_{CR} μCR和 μ F \mu_F μF根据预期的想法进行减少。
3.4 提出的DMSSA
我们提出了一种基于CMS和ADMS的新SSA变体。与原始SSA相比,我们保留了原始SSA的结构,并继续采用领导者和追随者的两部分结构。同时,DMSSA引入了两种独特的突变策略。一种是CMS。该策略充分考虑了水平维度信息(问题维度),并采用大于Pa的变量的突变策略。同时,不同个体之间的差异被纵向提取,并且这些差异被应用于同意变化的个体变量。与原始SSA领导者没有使用种群信息生成的随机值相比,这种方法保持了随机性,并且不会使随机过程过于剧烈。另一种突变策略是使用自适应DE。与原始DE相比,DMSSA参考各种个体信息。最优解个体保证了搜索最佳方向的一般方向,并且通过不同代个体的差异来纠正一般方向。同时,受JADE的启发,交叉率CR和突变因子F采用不同的自适应方法。此外,交叉率CR与杜鹃蛋中的Pa相关。最后,新算法采用了原始SSA中未使用的适者生存方法。只有后代个体超过父代个体时,后代个体才能存活。这是两种策略的前提。
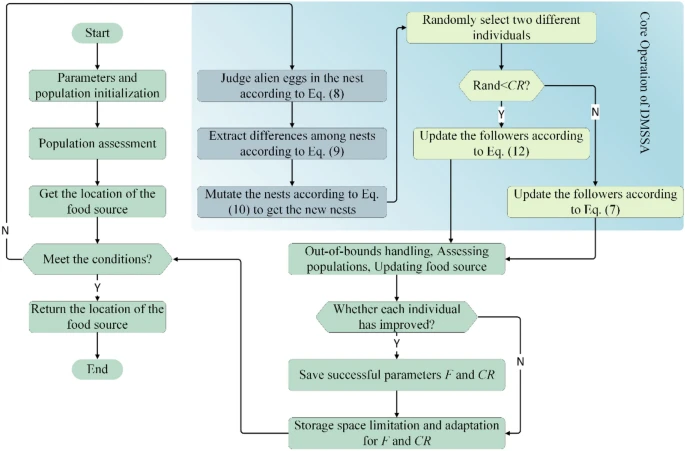
算法2展示了DMSSA的伪代码。图2展示了DMSSA的思想和想法,完整代码
%__________________________________________________________________________________%
% Double Mutational Salp Swarm Algorithm(DMSSA) source codes demo version 1.0 %
% By "Chao Lin" Dated: 24-06-2022 %
%__________________________________________________________________________________%
function [FoodPosition,Convergence_curve]=DMSSA(N,MaxFEs,lb,ub,dim,fobj)
tic
lb=ones(1,dim).*lb;
ub=ones(1,dim).*ub;Convergence_curve = [];
FEs=0;
SalpPositions=initialization(N,dim,ub,lb);
SalpFitness=ones(N,1)*inf;
FoodPosition=zeros(1,dim);
FoodFitness=inf;%calculate the fitness of initial salps
for i=1:size(SalpPositions,1)SalpFitness(i)=fobj(SalpPositions(i,:));FEs=FEs+1;
end[FoodFitness,min_salp_fitness] = min(SalpFitness);
FoodPosition = SalpPositions(min_salp_fitness(1),:);t=2; % start from the second iteration since the first iteration was dedicated to calculating the fitness of salpsCRm=0.5;SCR=[];
Fm=0.5;SF=[];
%Main loop
while FEs<MaxFEs+2SalpPre=SalpPositions;SalpFitPre=SalpFitness;CR=CRm+0.1*randn();CR=min(1,max(0,CR));pa=CR;new_nest=empty_nests(SalpPositions,lb,ub,pa) ;SalpPositions(1:N/2,:)=new_nest(1:N/2,:);A=randperm(N);A(A<=N/2)=[];r1=A(1);r2=A(2);F = Fm + 0.1 * tan(pi * (rand() - 0.5));F = min(1, F);while F<=0F = Fm + 0.1 * tan(pi * (rand() - 0.5));F = min(1, F);endfor i=N/2+1:Nfor j=1:dimif rand()<CRSalpPositions(i,j)=SalpPositions(i,j)+(FoodPosition(j)-SalpPre(r1,j))*F+(SalpPositions(r1,j)-SalpPre(r2,j))*F;elseSalpPositions(i,j)=(SalpPositions(i,j)+SalpPositions(i-1,j))/2;endendendfor i=1:size(SalpPositions,1)SalpPositions(i,:)=max(SalpPositions(i,:),lb);SalpPositions(i,:)=min(SalpPositions(i,:),ub); SalpFitness(i)=fobj(SalpPositions(i,:));FEs=FEs+1;if SalpFitness(i)<FoodFitnessFoodPosition=SalpPositions(i,:);FoodFitness=SalpFitness(i);endif SalpFitness(i)>SalpFitPre(i)SalpPositions(i,:)=SalpPre(i,:);SalpFitness(i)=SalpFitPre(i);elseif i>N/2SCR=[SCR;CR];SF=[SF;F];endendendif size(SCR,1)>N/2rndpos=randperm(size(SCR,1));rndpos=rndpos(1:N/2);SCR=SCR(rndpos,:);endif size(SF,1)>N/2rndpos=randperm(size(SF,1));rndpos=rndpos(1:N/2);SF=SF(rndpos,:);endc=1/10;CRm=(1-c)*CRm+c*mean(SCR);Fm = (1 - c) * Fm + c * sum(SF .^ 2) / sum(SF);Convergence_curve(t-1)=FoodFitness;t = t + 1;
end
toc
endfunction new_nest=empty_nests(nest,Lb,Ub,pa)
% A fraction of worse nests are discovered with a probability pa
n=size(nest,1);
% Discovered or not -- a status vector
K=rand(size(nest))>pa;% In the real world, if a cuckoo's egg is very similar to a host's eggs, then
% this cuckoo's egg is less likely to be discovered, thus the fitness should
% be related to the difference in solutions. Therefore, it is a good idea
% to do a random walk in a biased way with some random step sizes.
%%% New solution by biased/selective random walks
stepsize=rand*(nest(randperm(n),:)-nest(randperm(n),:));
new_nest=nest+stepsize.*K;
for j=1:size(new_nest,1)s=new_nest(j,:);new_nest(j,:)=simplebounds(s,Lb,Ub);
end
end
function s=simplebounds(s,Lb,Ub)% Apply the lower boundns_tmp=s;I=ns_tmp<Lb;ns_tmp(I)=Lb(I);% Apply the upper bounds J=ns_tmp>Ub;ns_tmp(J)=Ub(J);% Update this new move s=ns_tmp;
end