K8S - StatefulSet 与 DaemonSet - 有状态应用部署与节点管理策略
一、引言
在 Kubernetes 中,Deployment 主要用于管理无状态(Stateless)应用,但对于有状态应用(如数据库)或需要在每个节点运行的系统级任务(如日志收集器),需要使用更专业的资源类型:
• StatefulSet:专为有状态应用设计,提供稳定的网络标识和持久化存储能力。
• DaemonSet:确保每个集群节点运行指定的 Pod,适合系统级后台任务。
二、工作原理
2.1 StatefulSet 有状态应用的守护者
1.核心能力
• 持久化存储:通过 VolumeClaimTemplate 为每个 Pod 绑定独立的持久卷(Persistent Volume,PV),确保数据在 Pod 重启或调度时不会丢失。
• 稳定唯一标识:每个 Pod 都有稳定且唯一的网络标识(如 web-0、web-1),即使 Pod 被重新调度,其名称和网络标识也保持不变。
• 有序部署和扩缩容:StatefulSet 按照定义的顺序依次创建或删除 Pod,确保在扩容或缩容时遵循特定的顺序。
2.适用场景
• 需要持久化存储的应用:如数据库(MySQL、PostgreSQL)或分布式文件系统。
• 需要稳定网络标识的分布式应用:如 ZooKeeper、Etcd 等。
2.2 DaemonSet 节点级守护进程
1.核心能力
• 节点级覆盖:确保集群中的每个节点都运行一个指定的 Pod,包括新加入的节点。
• 特定节点调度:可以通过节点选择器(nodeSelector)或容忍度(tolerations)指定 Pod 运行的目标节点。
2.适用场景
• 系统级后台任务:如日志收集器(Fluentd)、监控代理(Prometheus Node Exporter)等,需要在每个节点上运行的服务。
三、实战示例
3.1 StatefulSet 部署 MySQL 主从集群
场景:使用 StatefulSet 部署一个包含一个主节点和一个从节点的 MySQL 集群。
步骤 1:创建并应用 Headless Service
创建一个 Headless Service,用于 MySQL 节点间的内部通信。
mysql-service.yaml
apiVersion: v1
kind: Service
metadata:name: mysql # Service 的名称
spec:ports:- port: 3306 # Service 监听的端口clusterIP: None # 设置为 None,创建一个 无头serviceselector:app: mysql # 选择具有标签 'app: mysql' 的 Pod
应用 Service到集群
kubectl apply -f mysql-service.yaml
Headless Service 核心要点
DNS 直连特性:
• 不分配虚拟 IP:直接暴露 Pod 的 IP 地址。
DNS 解析规则:
• 查询服务域名(如 mysql.default.svc.cluster.local)时,返回所有关联 Pod 的 IP 列表。
• 每个 Pod 拥有独立的 DNS 记录(如 mysql-0.mysql.default.svc.cluster.local)。
适用场景:
• 需要 Pod 间直接通信的分布式应用(如数据库主从复制)。
• 需要按名称访问特定 Pod 的场景(如主节点固定为 mysql-0)。
步骤2:验证 Headless Service
# 查看 Service 状态(CLUSTER-IP 应为 None)
kubectl get svc mysql# 输出示例:
# NAME TYPE CLUSTER-IP PORT(S) AGE
# mysql ClusterIP None 3306/TCP 5s
步骤 3:创建并应用StatefulSet
创建 StatefulSet,包含两个副本,分别作为主节点和从节点。
mysql-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:name: mysql # StatefulSet 的名称
spec:serviceName: "mysql" # 关联 headless service,必须名字一致replicas: 2 # Pod 副本数量selector:matchLabels:app: mysql # 选择匹配标签为 app=mysql 的 Podtemplate:metadata:labels:app: mysql # Pod 的标签spec:containers:- name: mysql # 容器名称image: mysql:5.7 # 使用的 MySQL 5.7 镜像ports:- containerPort: 3306 # 暴露 MySQL 默认端口env:- name: MYSQL_ROOT_PASSWORDvalue: "password" # 设置 MySQL root 用户密码volumeMounts:- name: mysql-persistent-storagemountPath: /var/lib/mysql # MySQL 数据目录volumeClaimTemplates: #自动为每个pod创建pvc- metadata:name: mysql-persistent-storage # PVC 的名称spec:accessModes: [ "ReadWriteOnce" ] # 访问模式:单节点读写resources:requests:storage: 1Gi # 每个 PVC 请求 1Gi 存储
定义了一个名为 mysql的 StatefulSet,创建两个 MySQL 5.7 实例,每个实例都有一个独立的持久化存储卷,用于存储数据库数据。
关键解析:
• volumeClaimTemplates:为每个 Pod 自动创建 PersistentVolumeClaim(PVC),确保数据持久化。
• serviceName:关联Headless Service,实现 Pod 间通过固定域名通信。
步骤4:应用配置并验证
#部署配置
kubectl apply -f mysql-statefulset.yaml
# 观察 Pod 启动顺序(主节点优先)
kubectl get pods -l app=mysql -w
# 输出:
# NAME READY STATUS RESTARTS AGE
# mysql-0 1/1 Running 0 30s
# mysql-1 1/1 Running 0 60s# 检查 PVC 绑定状态
kubectl get pvc
# 输出:
# NAME STATUS VOLUME CAPACITY
# mysql-persistent-storage-mysql-0 Bound pvc-xxx 1Gi
# mysql-persistent-storage-mysql-1 Bound pvc-yyy 1Gi
此时,应看到 mysql-0(主节点)和 mysql-1(从节点)依次启动。
3.2 DaemonSet 部署 Fluentd 日志收集器
场景:在每个节点部署 Fluentd,收集3.1 示例中 MySQL 集群日志(包括 /var/log/mysql)。
步骤1:创建 DaemonSet
定义一个 DaemonSet,确保 Fluentd 在每个节点上运行。
apiVersion: apps/v1
kind: DaemonSet
metadata:name: fluentd
spec:selector:matchLabels:name: fluentdtemplate:metadata:labels:name: fluentdspec:tolerations:- key: node-role.kubernetes.io/mastereffect: NoSchedulecontainers:- name: fluentdimage: fluent/fluentd-kubernetes-daemonset:v1.11-debian-1 # fluentd镜像resources: # 必须添加资源限制requests:cpu: "100m"memory: "200Mi"limits:cpu: "500m" # 不超过节点单核的50%memory: "1Gi" # 根据日志量调整volumeMounts:- name: varlogmountPath: /var/log # 收集主机系统日志- name: mysql-log # 搭载mysql 容器日志目录mountPath: /var/log/mysqlvolumes:- name: varloghostPath:path: /var/log- name: mysql-log # mysql容器日志目录hostPath:path: /var/log/containers # 日志路径
关键点解析:
• DaemonSet:确保在集群中的每个节点上运行一个 Fluentd Pod,用于日志收集。
• selector:指定 Pod 的标签选择器,确保 DaemonSet 只管理具有匹配标签的 Pod。
• template:定义了要部署的 Pod 模板,包括其元数据和规范。
• containers:在每个 Pod 中运行的容器列表,此处为 Fluentd。
• volumeMounts:将主机的 /var/log目录挂载到容器内,以便 Fluentd 能访问并收集日志。
• volumes:定义了挂载到容器的卷,此处使用 hostPath将主机目录直接映射到容器。
通过上述配置,Fluentd 将在集群的每个节点上运行,并收集该节点的日志信息。
步骤 2:应用配置并验证
# 部署 DaemonSet
kubectl apply -f fluentd-daemonset.yaml# 查看 DaemonSet 状态
kubectl get daemonset fluentd
输出示例:NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE
fluentd 2 2 2 2 2验证 Pod 分布(每个节点一个 Pod)kubectl get pods -l name=fluentd -o wide
输出示例:NAME READY STATUS NODE AGE
fluentd-xxxx 1/1 Running node-1 2m
fluentd-yyyy 1/1 Running node-2 2m
四、生产选型策略
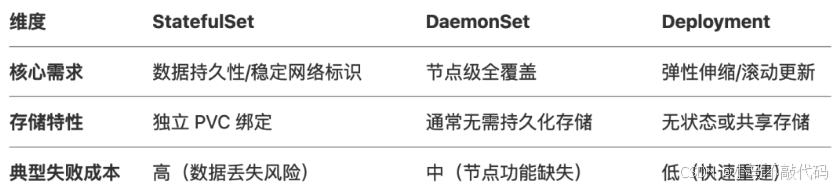
4.1 决策关键维度
4.2 决策树
是否需要每个节点运行实例?
├─ 是 → DaemonSet(日志/监控代理等)
└─ 否 → 是否需要保持数据或身份?├─ 是 → StatefulSet(数据库/中间件)└─ 否 → Deployment(Web服务/API等)
4.3 生产实践原则
1.StatefulSet 使用规范
本质作用
• 差异化副本管理:处理主从节点拓扑关系(如 MySQL 主从架构),实现有序启停。
• 状态持久化:通过 PVC 绑定机制保证 Pod 重建时数据不丢失。
生产限制
StatefulSet ≠ 高可用中间件方案
├─ 仅解决存储和身份问题,不提供数据容灾/备份能力
└─ 网络拓扑管理依赖人工配置(如主从同步规则)
Kubernetes 状态管理能力边界
├─ 能做的:Pod 调度、存储绑定、基础健康检查
└─ 不能做的:数据一致性保障、跨集群容灾、备份恢复
决策路径
云托管服务 > Helm Chart > 自研 StatefulSet(需配套运维体系)
部署策略
• 云原生替代:直接采用云厂商的高可用产品,这样不仅提供了持久化功能,还实现了数据的备份和容灾。
• 中间件场景:优先使用 Helm Chart(如 Bitnami MySQL Chart)。无需自己写stateful manifest,只需找对应中间件 helm chart 直接安装即可。
2.DaemonSet 使用规范
核心定位
• 节点级基础设施:网络插件(Calico)、存储驱动(Ceph)、监控代理(Node Exporter)
• 禁止场景:业务应用、需弹性伸缩的服务。
五、总结
5.1 核心重点
| 工作负载 | 核心价值 | 生产实践优先级 |
|---|---|---|
| StatefuSet | 状态持久化+稳定的网络标识 | 云托管服务>Helm Chart>自研 |
| DaemonSet | 节点级覆盖+基础设施管理 | 仅用于系统组件(日志、监控、网络) |
| Deployment | 无状态弹性伸缩+滚动更新 | 微服务、前端应用默认方案 |