普通的宣传网站用什么做百度应用商店官网
目录
- 一、1046.最后一块石头的重量
- 二、703. 数据流中的第 K 大元素
- 三、692. 前 K 个⾼频单词
- 四、295. 数据流的中位数

一、1046.最后一块石头的重量
题目链接:1046.最后一块石头的重量
题目描述:

题目解析:
- 题意就是让我们拿出提供的数组的最大两个值,大减小作差,将差值再放入数组,直到数组空了或者只有一个元素为止。
解题思路:
- 题目要求我们在一个乱序的数组中找最大两个值,我们首先想到数组排序,但是由于我们还需要将差值放入数组,我们放一次就需要排序一次。
- 使用优先级队列,大根堆,开销会小一些,我们只需要每次拿堆顶元素即可。
解题代码:
//时间复杂度 O(n)
//空间复杂度 O(n)
class Solution {public int lastStoneWeight(int[] stones) {//创建大根堆PriorityQueue<Integer> queue = new PriorityQueue<>((a,b) -> b - a);//入堆for(int i = 0; i < stones.length; i++)queue.offer(stones[i]);//执行逻辑while(!queue.isEmpty() && queue.size() != 1) {int y = queue.poll();int x = queue.poll();queue.offer(y-x); }//返回值return queue.isEmpty() ? 0 : queue.poll();}
}
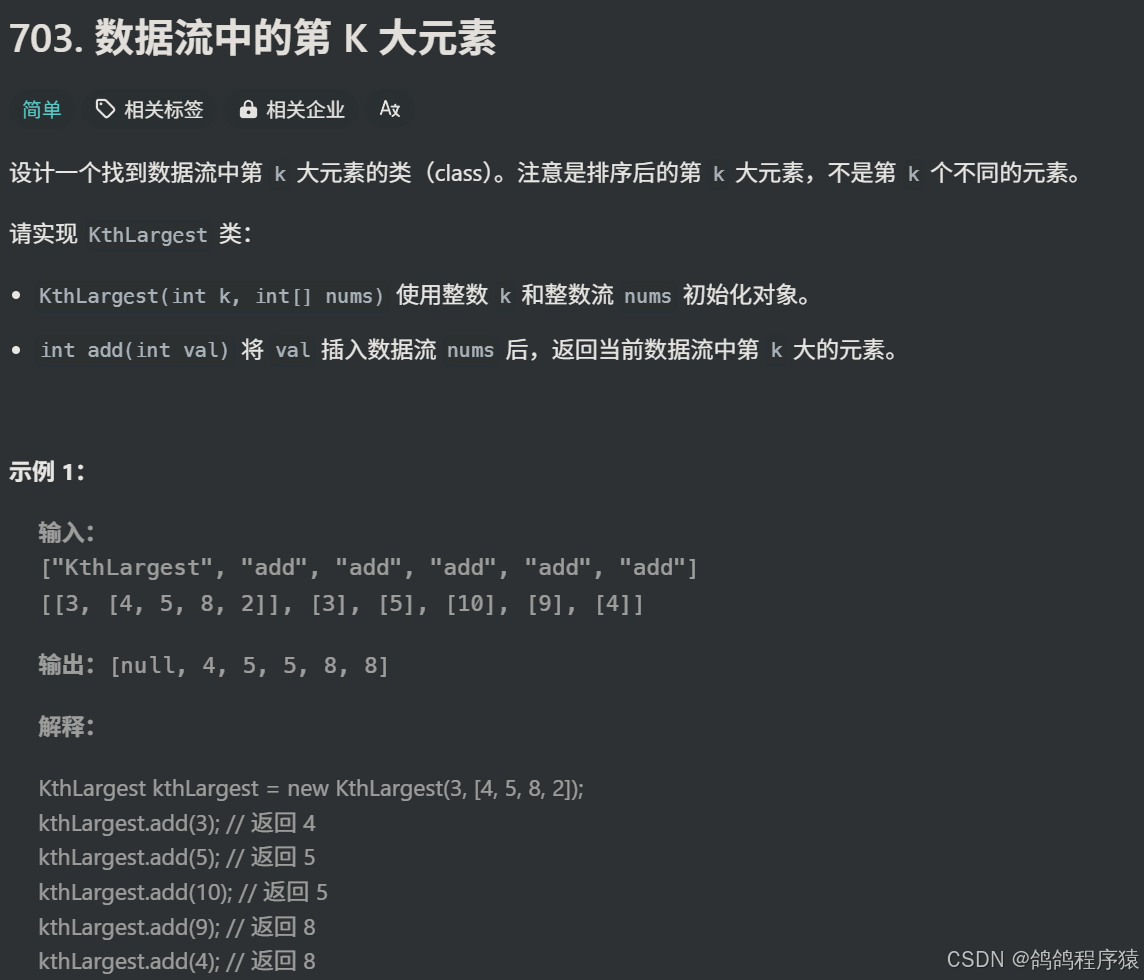
二、703. 数据流中的第 K 大元素
题目链接:703. 数据流中的第 K 大元素
题目描述:
题目解析:
- 给我们一个数组和一个数K,让我们在使用类的add方法后,返回数组中的第K大的数。
解题思路: - 我们使用一个大小为K的小根堆,那么我们剩下在堆中的数,就是数组中第K大到最大的值。
- 返回数组中的第K大的数,就是当前的堆顶。
解题代码:
//时间复杂度 O(nLogK)
//空间复杂度 O(K)
class KthLargest {PriorityQueue<Integer> heap;int param_1;public KthLargest(int k, int[] nums) {heap = new PriorityQueue<Integer>();param_1 = k;for(int i = 0; i < nums.length; i++) {heap.offer(nums[i]);if(heap.size() > param_1) {heap.poll();}}}public int add(int val) {heap.offer(val);if(heap.size() > param_1) {heap.poll();}return heap.peek();}
}三、692. 前 K 个⾼频单词
题目链接:692. 前 K 个⾼频单词
题目描述:

题目解析:
- 给我们一个words的字符串数组,让我们返回数组中出现的频率次数最多到第K多的字符串。
- 当出现频次相同的时候,就直接按照字典顺序,字母前到后比较大小,大在前。
解题思路:
- 我们使用一个hash表,记录下字符串与其出现的次数。
- 在使用一个大小为K的堆,当我们的频次就是hash表中的value相同的时候,我们使用compare比较大小,创建的是大根堆,其余比较频次是小根堆。总体上看还是一个小根堆。
- 最后一次取出堆中的字符串即可,但是由于返回值又是从小到大,最后将结果数组逆序即可。
解题代码:
//时间复杂度:O(NLogK)
//空间复杂U度:O(N)
class Solution {public List<String> topKFrequent(String[] words, int k) {Map<String, Integer> hash = new HashMap<>();PriorityQueue<Pair<String,Integer>> heap = new PriorityQueue<>((a,b) -> {//频次相同大根堆if(a.getValue().equals(b.getValue())) {return b.getKey().compareTo(a.getKey());}//小根堆return a.getValue() - b.getValue();});//hash初始化for( String s : words) {hash.put(s, hash.getOrDefault(s ,0) + 1);}//入堆for(Map.Entry<String, Integer> e : hash.entrySet()) {heap.offer(new Pair<>(e.getKey(),e.getValue()));if(heap.size() > k) {heap.poll();}}//结果处理List<String> ret = new ArrayList<String>();while(!heap.isEmpty()) {ret.add(heap.poll().getKey());}//逆置Collections.reverse(ret);return ret;}
}
四、295. 数据流的中位数
题目链接:295. 数据流的中位数
题目描述:
- 就是让我们实现一个类,有初始化,添加元素(每次添加一个),查看元素中位数
题目解析:
- 我们只需要每次拿取类中的元素的时候,能够直接拿到中位数即可。
- 我们可以使用两个堆,小根堆记录数的中位数之后的部分,大根堆记录中位数的前半部分。
- 这样当元素个数是偶数个的时候,我们直接拿到两个堆的堆顶元素即可。为奇数个元素的时候,直接取出堆元素多的那个的堆顶元素即可。
解题思路:
- 我们使用两个堆,一个大根堆,一个小根堆,在记录下当前的元素个数。
- 当插入元素后,元素个数为偶数:
-
- 当插入元素比大根堆堆顶元素大:
-
-
- 大根堆中元素个数比小根堆多:直接将待插入元素插入小根堆即可。
-
-
-
- 大根堆中元素个数比小根堆少:将小根堆堆顶元素和待插入元素较小值,插入大根堆。另一个给小根堆。
-
-
- 当插入元素比大根堆堆顶元素小:
-
-
- 大根堆中元素个数比小根堆多:将大根堆堆顶元素插入小根堆。待插入元素给大根堆。
-
-
-
- 大根堆中元素个数比小根堆少:直接将待插入元素插入大根堆即可。
-
- 当插入元素后,元素个数为奇数:
-
- 当插入元素比大根堆堆顶元素大:插入小根堆。
-
- 当插入元素比大根堆堆顶元素小:插入大根堆。
解题代码:
//时间复杂度:O(LogN)
//空间复杂度:O(N)
class MedianFinder {//列表中元素个数int n = 0;//大根堆记录前半部分值PriorityQueue<Integer> big;//小根堆记录后半部分值PriorityQueue<Integer> little;public MedianFinder() {big = new PriorityQueue<>((a,b) ->{return b-a;});little = new PriorityQueue<>();}public void addNum(int num) {n += 1;if(n == 1 ) {big.offer(num);return;}//元素个数为偶数,比前面的大if(n % 2 == 0 && big.peek() <= num) {//保持前后数据平衡if(big.size() < little.size()) {//比后面小if(!little.isEmpty() && little.peek() >= num) {big.offer(num);}else {int tmp = little.poll();big.offer(tmp);little.offer(num);}}else {little.offer(num);}return;} //元素个数为偶数,比前面的小if(n % 2 == 0 && big.peek() > num) {//保持前后数据平衡if(big.size() < little.size()) {big.offer(num);}else {int tmp = big.poll();big.offer(num);little.offer(tmp);}return;} //元素个数为奇数,比前面小if(n % 2 != 0 && big.peek() >= num) {big.offer(num);} else {little.offer(num);}}public double findMedian() {if(n % 2 == 0) {return (double)((big.peek() + little.peek())/ 2.0);}if(big.size() > little.size()) {return big.peek();} else {return little.peek();}}
}