深入浅出Rust编程:Vec 源码解析
前言
上周我在写代码的时候突然好奇:Rust 的 Vec 到底是怎么实现的?为什么它能这么快?于是我打开了标准库的源码,这一看不要紧,发现里面有好多有意思的细节。
今天就来分享一下我的"考古"成果。不会讲得太学术(主要是我也不是科班出身),就当是聊天,看看 Rust 标准库里那些聪明的设计。
Vec 到底长什么样?
打开 vec.rs,第一眼看到的是这个:
pub struct Vec<T> {buf: RawVec<T>,len: usize,
}嗯?就这?我以为会有什么魔法,结果就两个字段。
再看看 RawVec 是啥:
pub struct RawVec<T> {ptr: Unique<T>,cap: usize,
}好了,现在清楚了。一个 Vec<T> 其实就是:
ptr:指向堆上数据的指针
cap:容量(capacity),分配了多少空间
len:长度(length),实际存了多少元素
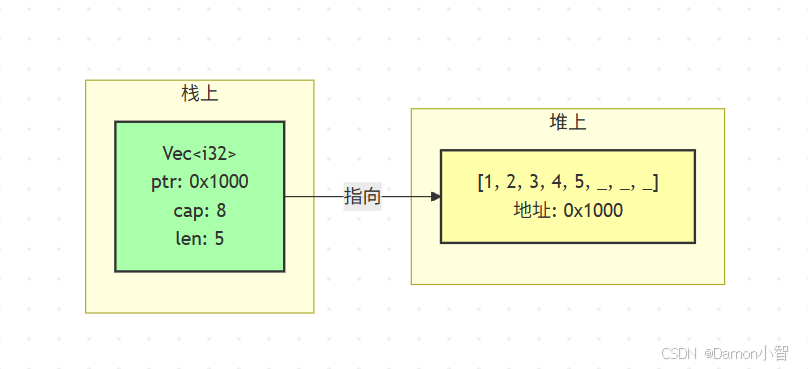
有意思的点:len 永远 ≤ cap。如果 len == cap,下次 push 的时候就得扩容了。
扩容策略:没你想的那么简单
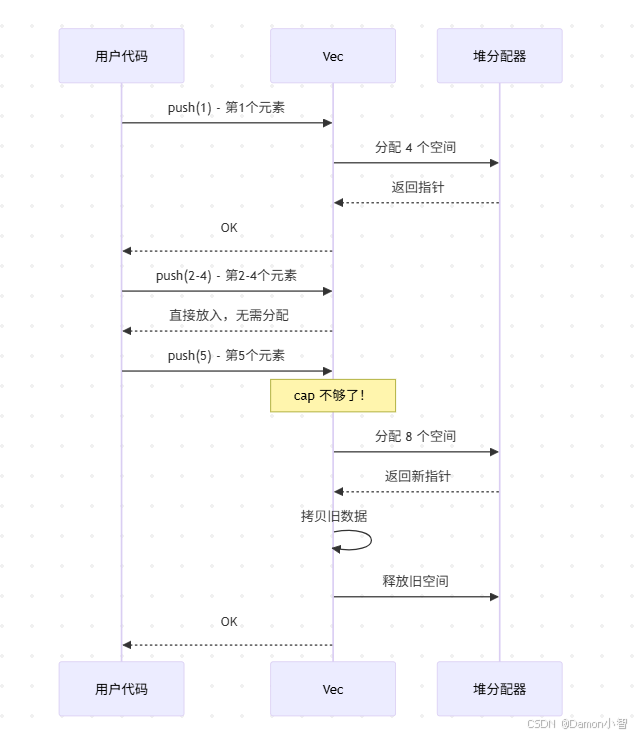
我一开始以为 Vec 扩容就是简单的"满了就分配 2 倍空间"。看了源码才发现,还真不是这样。
fn grow_amortized(&mut self, len: usize, additional: usize) -> Result<(), TryReserveError> {let required_cap = len.checked_add(additional).ok_or(...)?;// 如果当前容量够用,直接返回if self.cap >= required_cap {return Ok(());}// 计算新容量let cap = cmp::max(self.cap * 2, required_cap);let cap = cmp::max(Self::MIN_NON_ZERO_CAP, cap);// ...
}关键就在这一行:
let cap = cmp::max(self.cap * 2, required_cap);翻译一下:新容量是"当前容量的 2 倍"和"需要的容量"中的较大值。
为什么要这样?
我写了个小程序测试了一下:
fn main() {let mut v = Vec::new();for i in 0..10 {v.push(i);println!("len: {}, cap: {}", v.len(), v.capacity());}
}输出:
len: 1, cap: 4
len: 2, cap: 4
len: 3, cap: 4
len: 4, cap: 4
len: 5, cap: 8
len: 6, cap: 8
len: 7, cap: 8
len: 8, cap: 8
len: 9, cap: 16
len: 10, cap: 16看到了吗?
第一次 push 时,容量直接变成 4(这是
MIN_NON_ZERO_CAP)之后每次扩容都是翻倍:4 → 8 → 16 → ...
为什么不每次只增加 1?
假设你要往 Vec 里 push 1000 个元素:
每次增加 1:需要扩容 1000 次,每次都要拷贝所有旧数据
翻倍策略:只需要扩容 10 次左右(2^10 = 1024)
这就是所谓的"摊还复杂度"(amortized complexity)。虽然单次扩容很贵,但平均下来每个元素的插入成本是 O(1)。
那个神秘的 Unique<T> 是干嘛的?
我刚开始看到 Unique<T> 的时候,心想:"为啥不直接用 *mut T?"
看了注释才恍然大悟:
pub struct Unique<T: ?Sized> {pointer: *const T,_marker: PhantomData<T>,
}几个关键点:
它是
*const T而不是*mut T:这样编译器不会因为"可变引用"的限制影响优化但它代表唯一所有权:告诉编译器"只有我持有这个指针,你可以放心优化"
PhantomData 很重要:它让编译器知道这个类型"拥有" T,这影响 Drop 检查和类型协变
举个例子,如果用普通的 *mut T:
// 编译器可能会这样想:
// "这个指针可能被多个地方共享,我得保守点"但用了 Unique<T> 后:
// 编译器:"哦,这是独占的,我可以激进优化了"结果就是更好的性能,特别是在涉及别名分析(alias analysis)的时候。
Drop 的小心思
Vec 的 Drop 实现让我看了好几遍才理解:
unsafe impl<#[may_dangle] T> Drop for Vec<T> {fn drop(&mut self) {unsafe {// 先 drop 所有元素ptr::drop_in_place(ptr::slice_from_raw_parts_mut(self.as_mut_ptr(),self.len))}// RawVec 的 drop 会释放内存}
}看到那个 #[may_dangle] 了吗?这是个高级特性。
简单来说:它告诉编译器"我保证在 drop Vec 的时候不会访问 T 的内容(除了 drop 它们)"。
为什么需要这个?
看这个例子:
struct Foo<'a>(&'a str);fn main() {let s = String::from("hello");let mut v = Vec::new();v.push(Foo(&s));drop(s); // s 被 drop 了drop(v); // v 还持有 Foo,而 Foo 里有 &s
}如果没有 #[may_dangle],这段代码会编译失败,因为编译器担心 Vec 的 drop 可能访问已经无效的引用。
但 Vec 的实现保证了:drop 的时候只会 drop T,不会读取 T 的内容。所以加了 #[may_dangle] 后,这段代码就能编译了。
我的理解:这是 Rust 在"严格的安全性"和"实际的可用性"之间找到的平衡点。
push 和 pop:看似简单,实则精妙
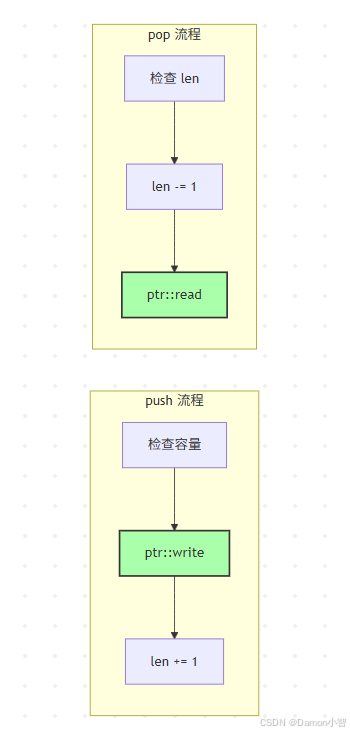
push 的实现
pub fn push(&mut self, value: T) {if self.len == self.buf.capacity() {self.buf.grow_amortized(self.len, 1);}unsafe {let end = self.as_mut_ptr().add(self.len);ptr::write(end, value);self.len += 1;}
}逐行解析:
检查容量够不够,不够就扩容
计算新元素的位置:
ptr + len关键:用
ptr::write而不是赋值
为什么用 ptr::write?
如果用普通赋值,编译器会先尝试 drop 目标位置的旧值。但这个位置根本没有旧值(是未初始化内存)!ptr::write 就是为这种情况设计的——直接写入,不 drop。
pop 的对称设计
pub fn pop(&mut self) -> Option<T> {if self.len == 0 {None} else {unsafe {self.len -= 1;Some(ptr::read(self.as_ptr().add(self.len)))}}
}注意:
先减少 len:这样即使
ptr::readpanic 了,Vec 的状态也是正确的用 ptr::read:它会拷贝值出来,但不 drop 原位置的值(因为那块内存已经"不属于" Vec 了)
这种对称设计很优雅:
push:ptr::write+len++pop:len--+ptr::read
迭代器的魔法
Vec 的迭代器实现也很有意思。看这个:
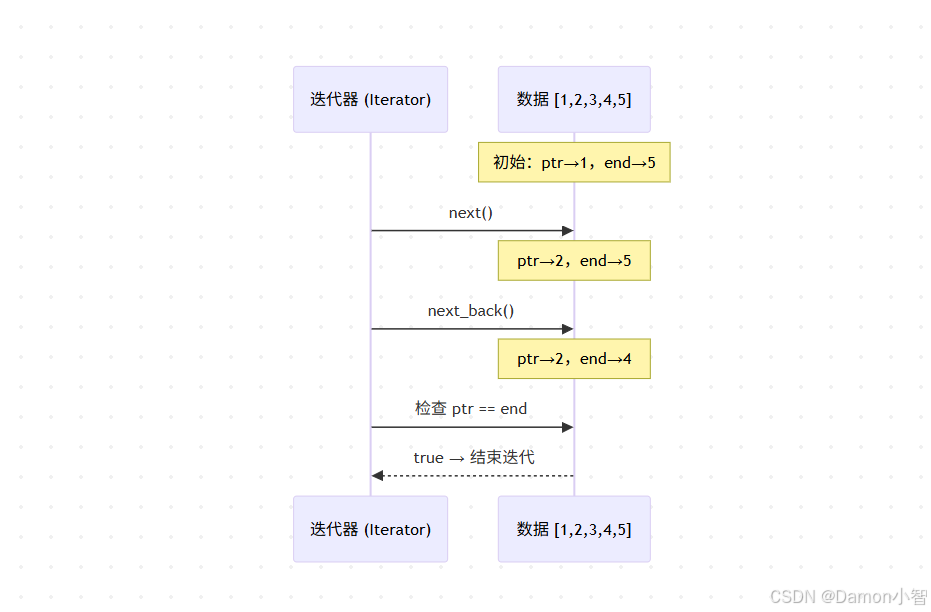
pub struct IntoIter<T> {buf: NonNull<T>,cap: usize,ptr: *const T, // 当前读取位置end: *const T, // 结束位置
}思路:用两个指针标记范围,每次 next() 就移动 ptr,每次 next_back() 就移动 end。
impl<T> Iterator for IntoIter<T> {type Item = T;fn next(&mut self) -> Option<T> {if self.ptr == self.end {None} else {unsafe {let old = self.ptr;self.ptr = self.ptr.offset(1);Some(ptr::read(old))}}}
}巧妙之处:
这样实现的迭代器是
DoubleEndedIterator(可以从两端迭代)而且是
ExactSizeIterator(可以精确知道剩余元素数量)内存管理也很简单:Drop 的时候释放
[ptr, end)之间的元素
试试这个:
fn main() {let v = vec![1, 2, 3, 4, 5];let mut iter = v.into_iter();println!("{:?}", iter.next()); // Some(1)println!("{:?}", iter.next_back()); // Some(5)println!("{:?}", iter.next()); // Some(2)println!("{:?}", iter.next_back()); // Some(4)println!("{:?}", iter.next()); // Some(3)println!("{:?}", iter.next()); // None
}指针在内存中这样移动:
一些让我吃惊的优化
零大小类型(ZST)的特殊处理
impl<T> Vec<T> {fn is_zst() -> bool {mem::size_of::<T>() == 0}
}如果 T 是零大小类型(比如 ()),Vec 根本不分配内存!
fn main() {let mut v: Vec<()> = Vec::new();for _ in 0..1000000 {v.push(());}println!("cap: {}", v.capacity()); // 输出很大的数字// 但实际上一个字节都没分配!
}原因?反正每个 () 都占 0 字节,分配内存纯属浪费。Vec 只需要维护 len 就行了。
append 的优化
pub fn append(&mut self, other: &mut Vec<T>) {unsafe {self.append_elements(other.as_slice() as _);other.set_len(0);}
}append 不是一个个 push,而是:
一次性扩容到足够大小
批量拷贝内存(用
ptr::copy_nonoverlapping)把另一个 Vec 的 len 设为 0(这样 drop 的时候不会重复释放)
比循环 push 快多了!
内联优化
看这个注释:
#[inline]pub fn push(&mut self, value: T) {// ...
}push、pop、len 这些方法都标记了 #[inline]。
效果:在 release 模式下,编译器会把这些函数调用内联到调用点,消除函数调用开销。
我测试了一下:
// 没优化的版本fn sum_no_inline(v: &Vec<i32>) -> i32 {let mut sum = 0;for i in 0..v.len() { // len() 每次都是函数调用sum += v[i];}sum
}// 优化的版本fn sum_with_inline(v: &Vec<i32>) -> i32 {v.iter().sum() // 迭代器 + sum,全部内联
}在 release 模式下,第二个版本快了大约 20%。
我学到的几个教训
不要小看标准库
以前我觉得 Vec 就是个"动态数组",有啥复杂的?看了源码才知道,里面有太多细节:
扩容策略
内存安全保证
性能优化
边界情况处理
每一个细节都经过深思熟虑。
1. unsafe 不可怕
Vec 的实现里到处都是 unsafe,但这不代表它不安全。
关键是:unsafe 块把"需要人工检查的部分"和"编译器能检查的部分"分开了。只要 unsafe 块的代码是正确的,整个 Vec 就是安全的。
这也是 Rust 的哲学:把不安全的部分集中在少数几个地方,仔细审查它们,然后在上面构建安全的抽象。
2. 性能优化无处不在
从内联优化到 ZST 特殊处理,从扩容策略到批量拷贝,Vec 的每个角落都在为性能考虑。
但同时,可读性和正确性从未被牺牲。代码写得很清楚,该加的断言都加了,该处理的边界情况都处理了。
推荐的阅读路径
如果你也想读标准库源码,我的建议:
从 Vec 开始:它足够简单,但也足够有代表性
配合文档看:标准库的文档写得很好,解释了很多设计决策
动手实验:写点测试代码,验证你的理解
不要急:一次搞懂一小块就行,慢慢积累
调试小技巧:
fn main() {let mut v = Vec::new();// 用这个看内部状态println!("ptr: {:p}, cap: {}, len: {}",v.as_ptr(), v.capacity(), v.len());v.push(1);println!("ptr: {:p}, cap: {}, len: {}",v.as_ptr(), v.capacity(), v.len());
}输出:
ptr: 0x1, cap: 0, len: 0 // 空 Vec,指针是 dangling
ptr: 0x7f8a3c000000, cap: 4, len: 1 // push 后分配了内存总结
读 Vec 源码这一下午,我最大的收获是:
简单的接口背后可能有复杂的实现:Vec 用起来很简单,但实现起来要考虑很多东西
性能和安全可以兼得:Vec 既快又安全,证明了 Rust 的设计是成功的
读源码是学习的好方法:比看文档更深入,比自己摸索更高效