Numpy数值分析库实验
目录
一、任务1:数据创建与基本操作 详细解析
(1)创建7×7温度数组
(2)模拟数据缺失与异常
(3)数组属性与广播机制
完整代码与输出示例
二、任务2:索引、切片与筛选 详细解析
(1)提取特定城市的温度序列
(2)选取指定时间范围的温度子矩阵
(3)布尔索引筛选异常温度
(4)沿指定轴排序温度数据
完整代码与输出示例
三、任务3:特殊数值处理 详细解析
(1)检测数据中的 NaN 与 Inf
(2)替换 NaN 和 Inf
(3)比较清洗前后数据的统计特征
四、任务4:聚合与数学分析 详细讲解
任务概述
代码讲解
1. 计算平均值
2. 计算最大值、最小值和标准差
3. 数学变换
五、任务5:利用Matplotlib实现可视化 详细讲解
1、设置中文字体和解决负号显示问题
2、创建柱状图
3、添加图表标题和轴标签
4、显示图表
完整代码示例
一、任务1:数据创建与基本操作 详细解析
(1)创建7×7温度数组
使用 numpy.random 模块创建一个表示 7 个城市、连续 7 天温度的二维数组(单位:℃):
import numpy as np# 创建7个城市、7天的随机气温数据(范围10~35℃)
temps = np.random.uniform(10, 35, size=(7, 7))关键点解析:
np.random.uniform 函数:
-
功能:生成指定范围内均匀分布的随机数
-
参数:
low=10(下限),high=35(上限),size=(7,7)(输出形状) -
数学表示:每个元素 x 满足 10≤x<35
数组结构:
-
形状:7行×7列(7个城市×7天)
-
数据类型:默认
float64(双精度浮点) -
内存布局:C顺序连续存储(行优先)
验证创建结果:
print("数组形状:", temps.shape) # 应输出 (7, 7)
print("元素总数:", temps.size) # 应输出 49
print("数据类型:", temps.dtype) # 应输出 float64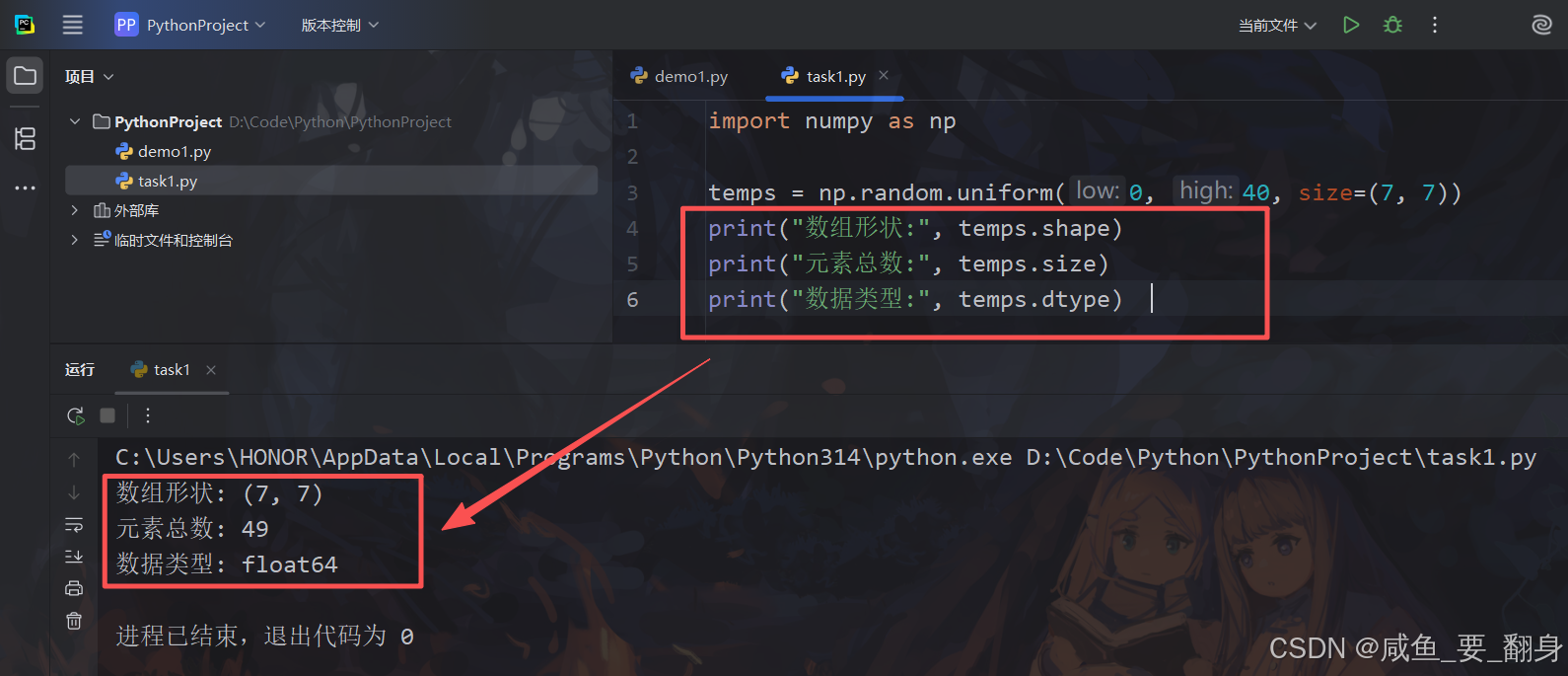
(2)模拟数据缺失与异常
模拟某些数据缺失(设置部分元素为 np.nan)与异常(设置部分元素为 np.inf):
# 模拟缺失与异常数据
temps[2, 4] = np.nan # 第3个城市第5天数据缺失
temps[5, 1] = np.inf # 第6个城市第2天温度异常关键点解析:
特殊值设置:
np.nan (Not a Number):表示缺失值
-
特性:任何涉及NaN的运算结果为NaN
-
检测方法:
np.isnan(temps)
np.inf (Infinity):表示正无穷大
-
产生方式:除零操作或手动赋值
-
检测方法:
np.isinf(temps)
索引方式:
-
使用
[行索引, 列索引]定位特定元素 -
注意:Python使用0-based索引(第3个城市对应索引2)
验证特殊值设置:
print("缺失值位置(2,4):", temps[2, 4]) # 应输出 nan
print("异常值位置(5,1):", temps[5, 1]) # 应输出 inf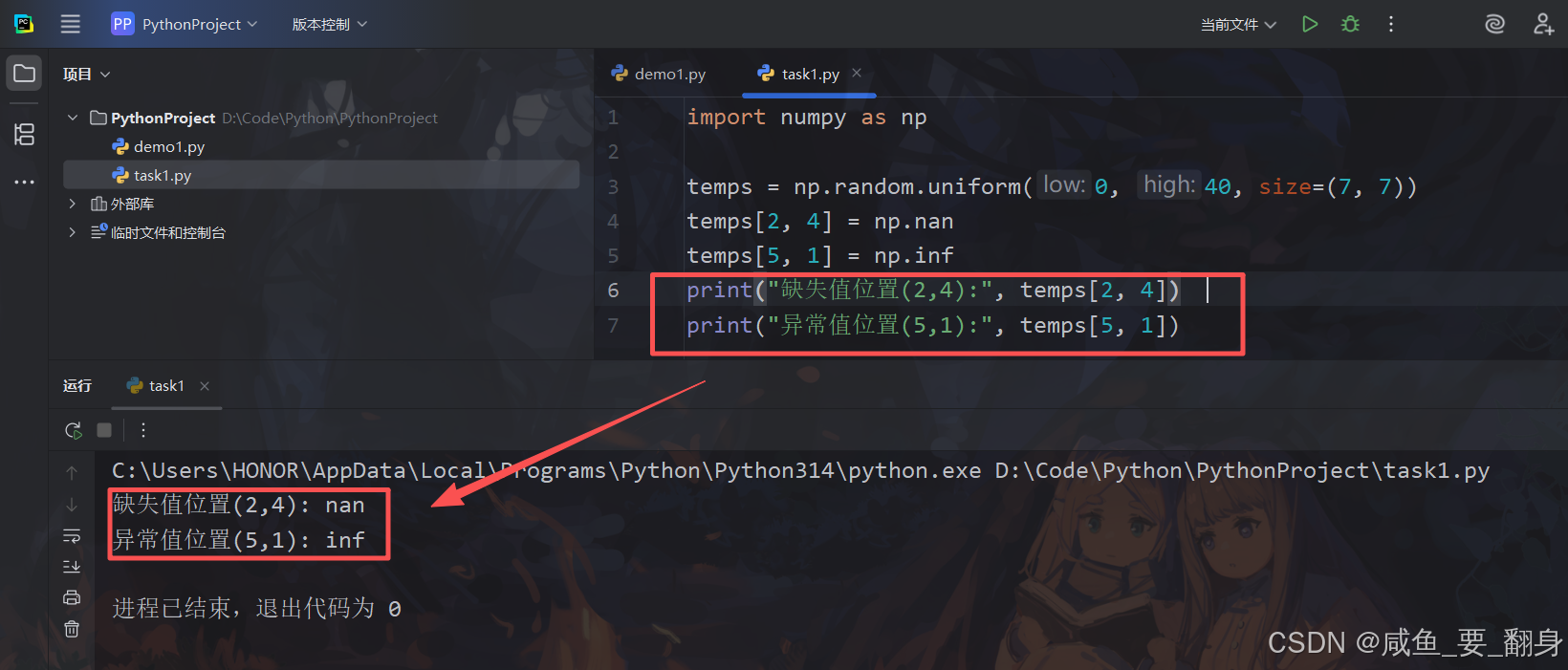
(3)数组属性与广播机制
输出数组的形状、维度、数据类型,体验广播机制(如为每个城市整体加上一个温度偏移量):
# 输出数组属性
print("气温数据:\n", temps)
print("数组形状:", temps.shape)
print("数据类型:", temps.dtype)# 广播操作:整体升温1.5℃
temps_adjusted = temps + 1.5
print("升温后气温:\n", temps_adjusted)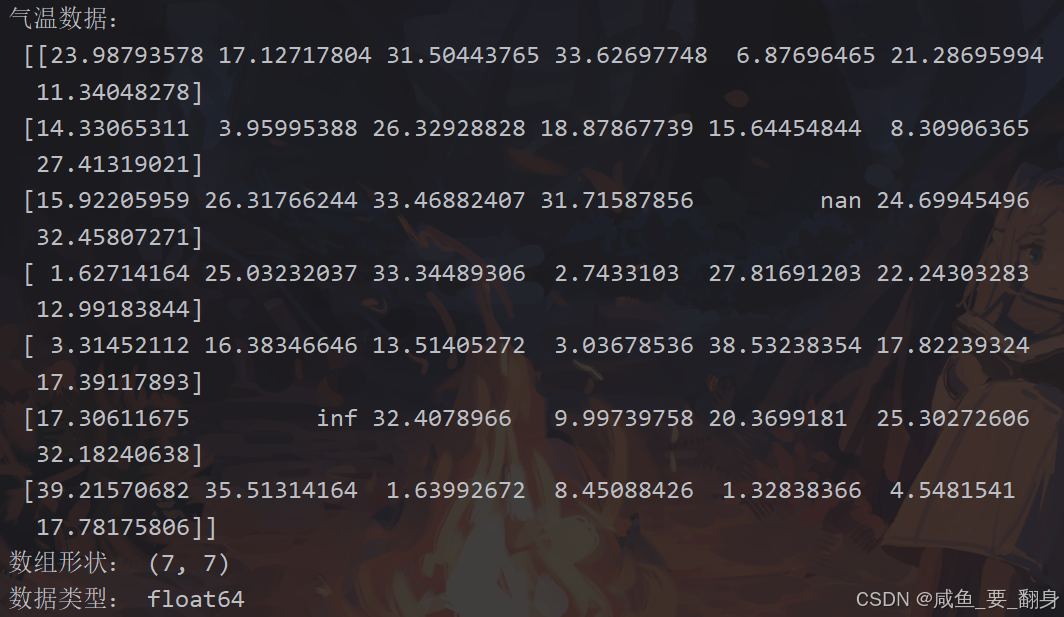
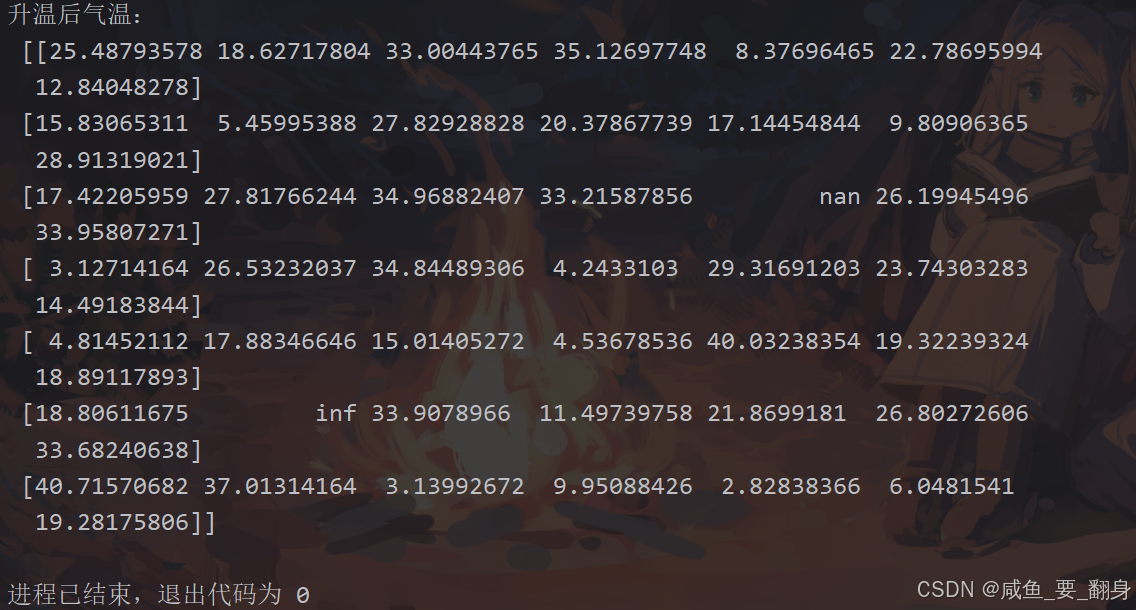
关键点解析:
数组属性:
-
shape:返回元组(7,7)表示维度 -
dtype:显示数据类型(应为float64) -
ndim:返回维度数(此处为2)
广播机制:
-
操作:
temps + 1.5 -
规则:标量1.5被扩展为与
temps相同形状的数组 -
等效运算:
temps_adjusted = temps + np.full_like(temps, 1.5) -
性能:广播操作在内存中不实际复制数据,通过计算时动态扩展实现
验证广播效果:
# 检查第0行第0列元素的计算
original = temps[0, 0]
adjusted = temps_adjusted[0, 0]
print("原始值:", original, "→ 调整后:", adjusted)
print("差值是否为1.5:", np.isclose(adjusted - original, 1.5)) #浮点数近似相等比较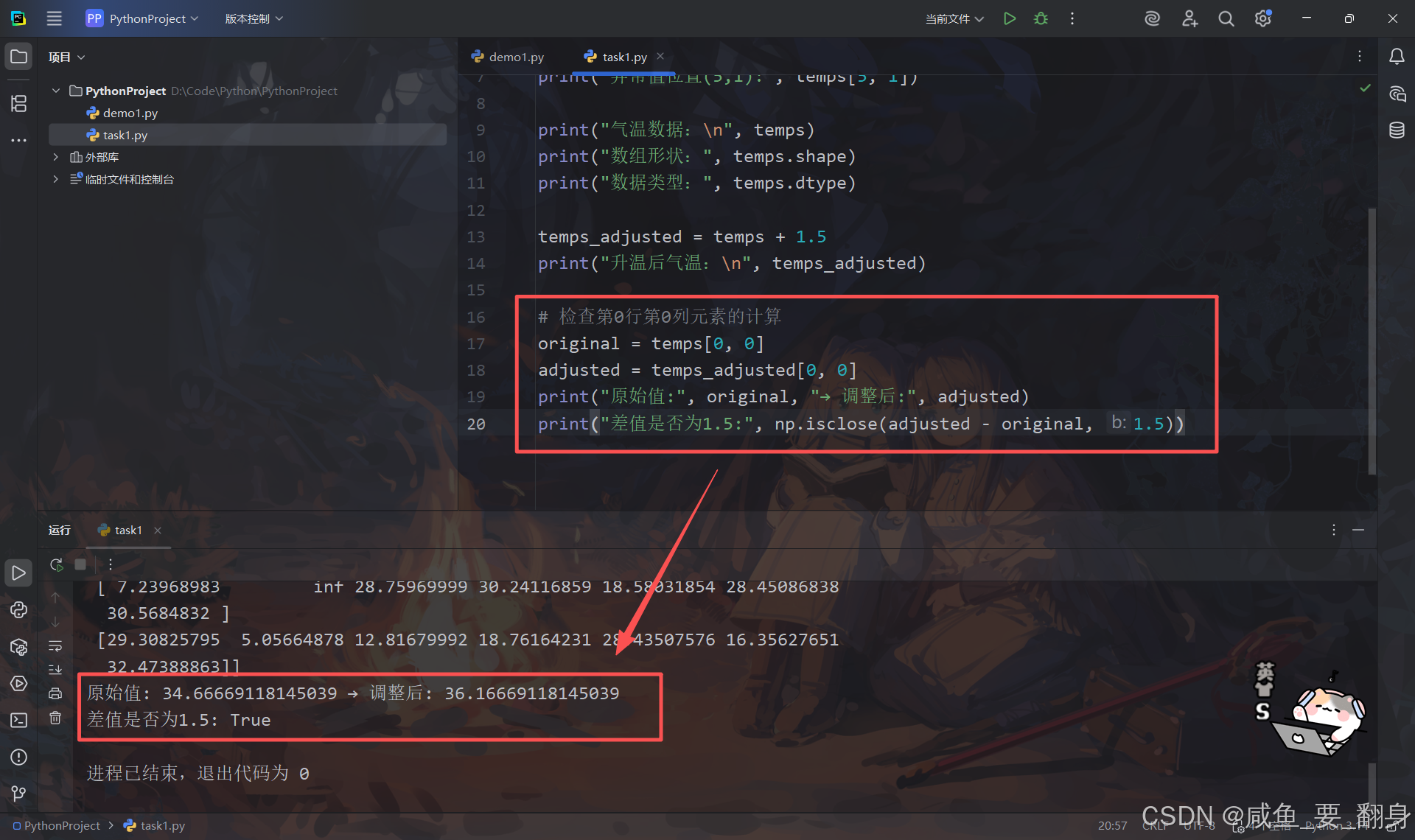
完整代码与输出示例
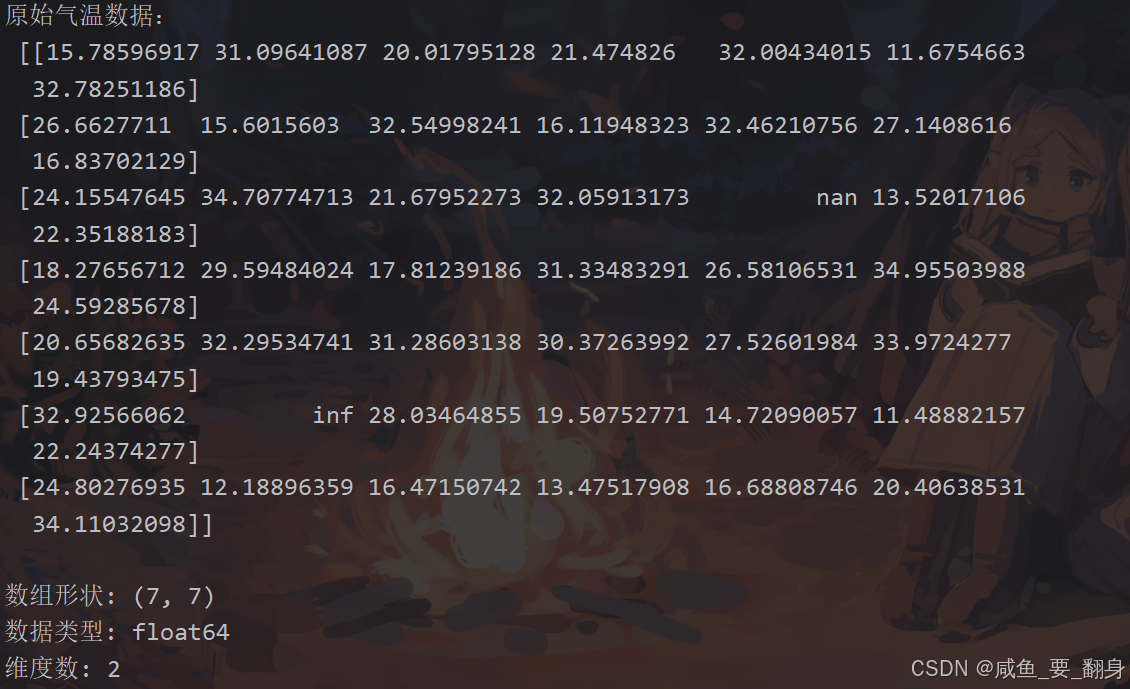
import numpy as np# (1) 创建数据
temps = np.random.uniform(10, 35, size=(7, 7))# (2) 设置特殊值
temps[2, 4] = np.nan
temps[5, 1] = np.inf# (3) 输出属性
print("原始气温数据:\n", temps)
print("\n数组形状:", temps.shape)
print("数据类型:", temps.dtype)
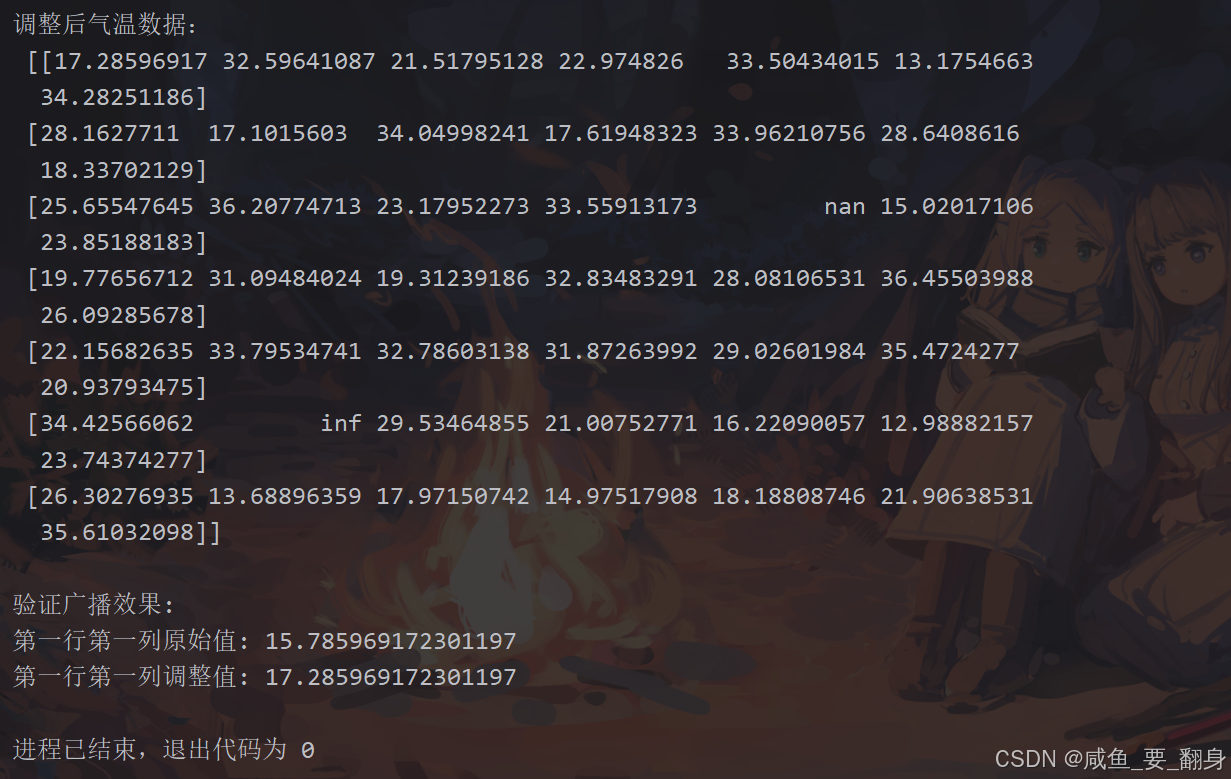
print("维度数:", temps.ndim)# 广播操作
temps_adjusted = temps + 1.5
print("\n调整后气温数据:\n", temps_adjusted)# 验证广播
print("\n验证广播效果:")
print("第一行第一列原始值:", temps[0,0])
print("第一行第一列调整值:", temps_adjusted[0,0])典型输出示例:
二、任务2:索引、切片与筛选 详细解析
(1)提取特定城市的温度序列
# 提取第3个城市一周温度(索引为2,因为Python从0开始计数)
city3 = temps[2, :]
print("城市3气温:", city3)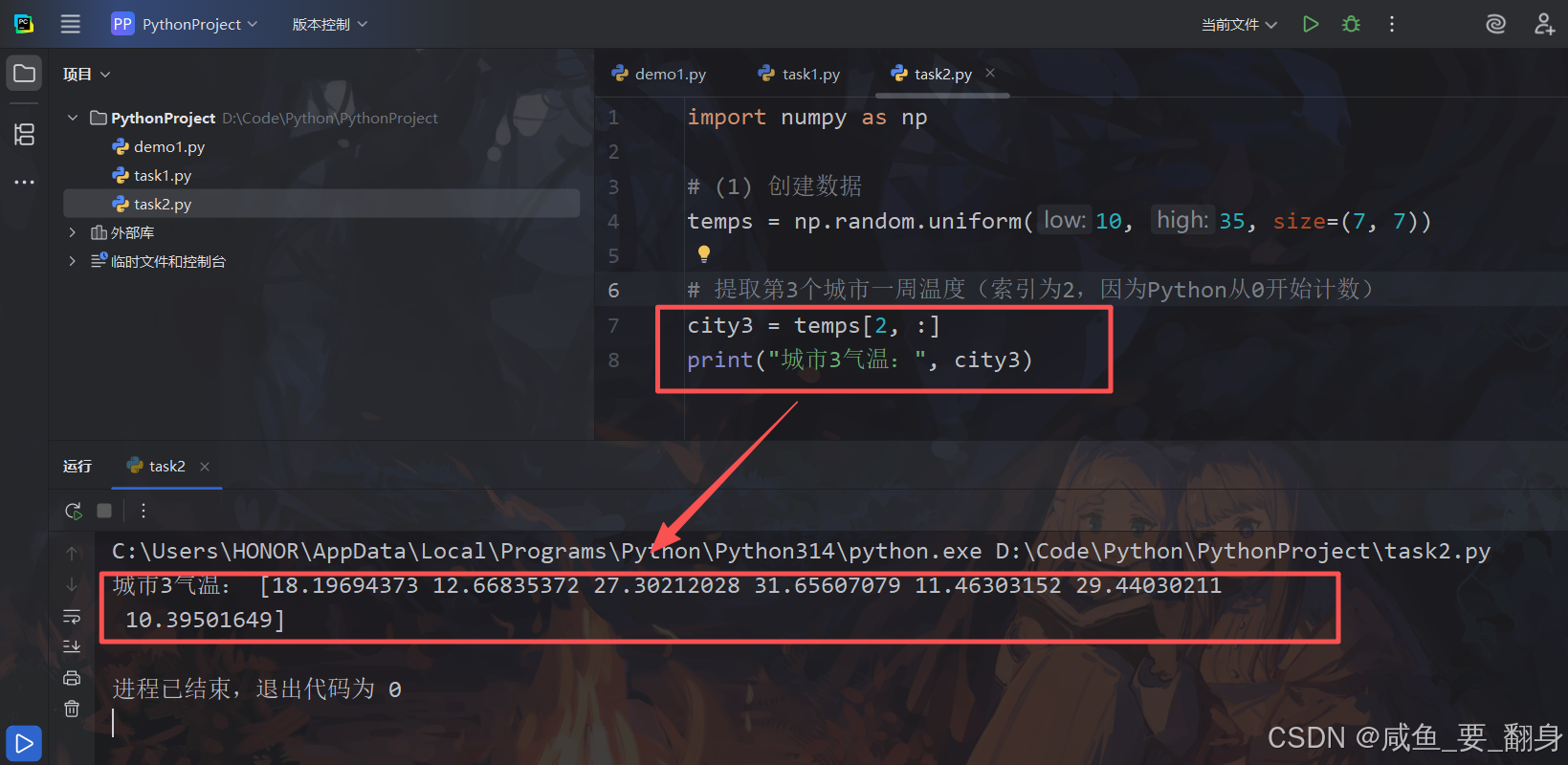
关键点解析:
索引方式:temps[2, :] 表示:
-
2:选择第3行(城市3) -
::选择所有列(7天的数据)
等价于 temps[2, 0:7]:
-
行索引:
2表示第3行(索引从0开始) -
列切片:
0:7表示从第1列到第7列(包含0,不包含7) -
结果:返回第3行的前7个元素
返回结果:
-
形状:
(7,)(一维数组) -
内容:该城市7天的温度序列
验证索引结果:
print("城市3数据形状:", city3.shape) # 应输出 (7,)
print("城市3第1天温度:", city3[0]) # 等价于 temps[2,0]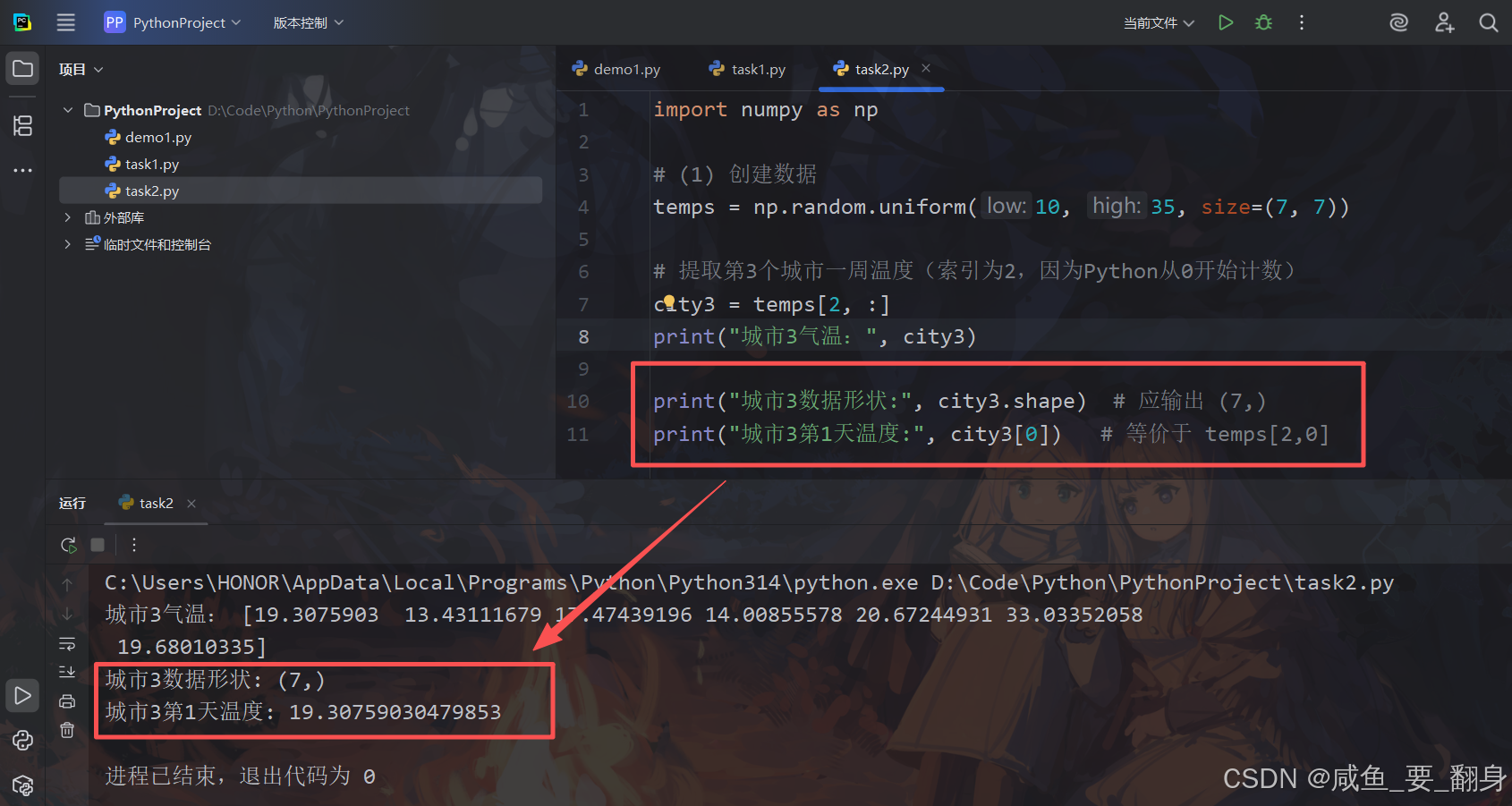
(2)选取指定时间范围的温度子矩阵
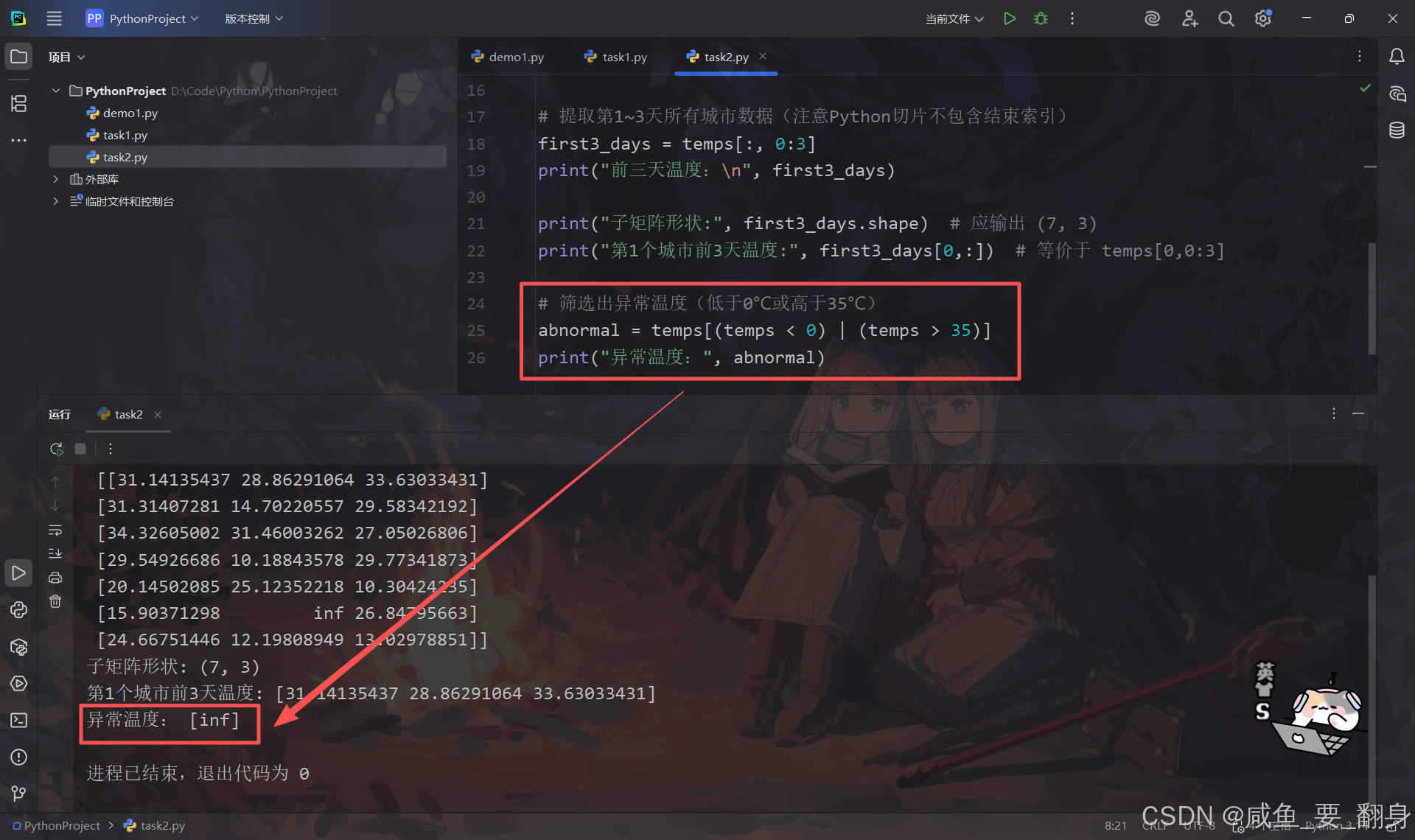
# 提取第1~3天所有城市数据(注意Python切片不包含结束索引)
first3_days = temps[:, 0:3]
print("前三天温度:\n", first3_days)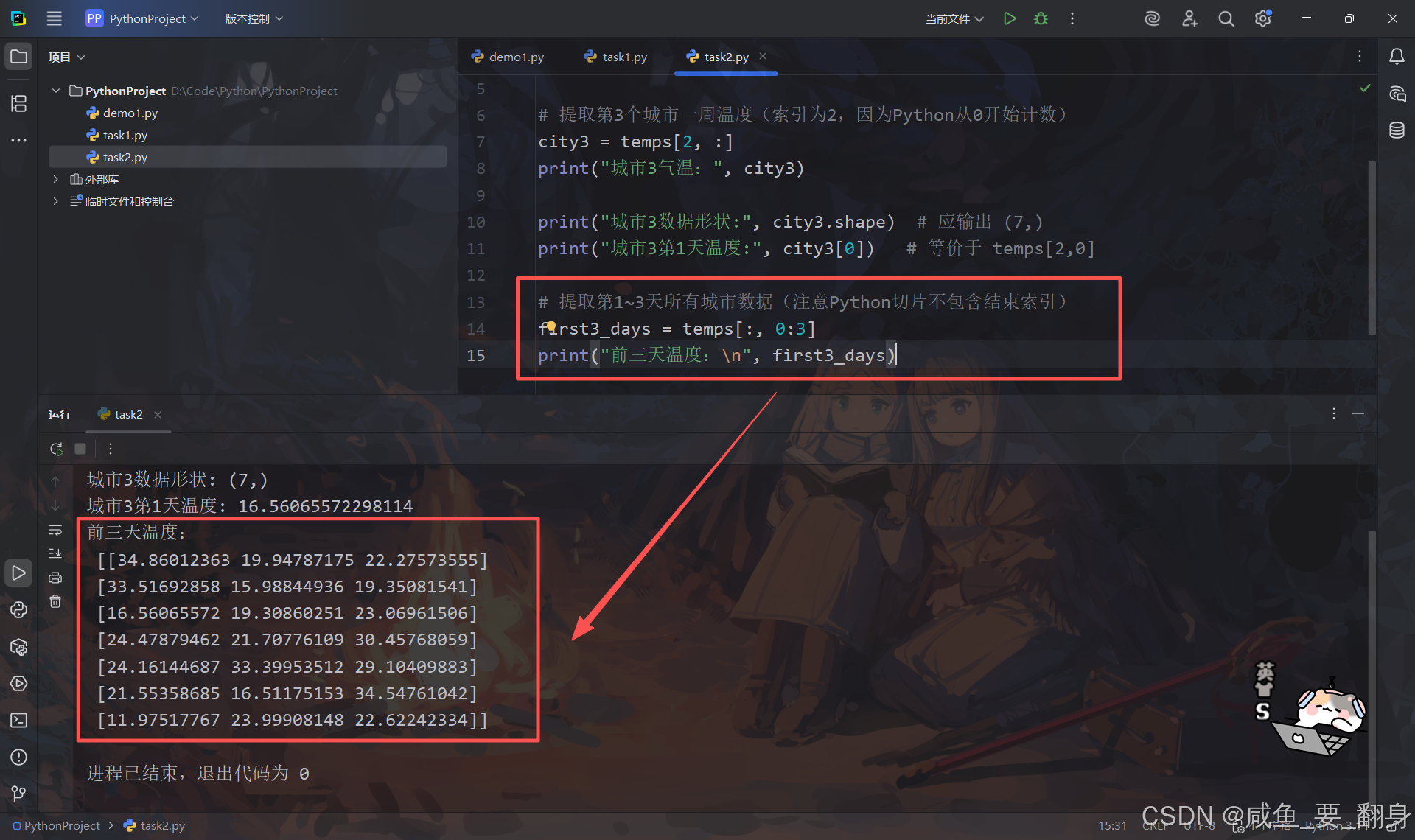
关键点解析:
切片操作:
-
temps[:, 0:3]表示:-
::选择所有行(7个城市) -
0:3:选择第0~2列(第1~3天数据)
-
-
注意:Python切片是左闭右开区间
返回结果:
-
形状:
(7, 3)(7个城市×3天) -
内容:所有城市前3天的温度数据
验证切片结果:
print("子矩阵形状:", first3_days.shape) # 应输出 (7, 3)
print("第1个城市前3天温度:", first3_days[0,:]) # 等价于 temps[0,0:3]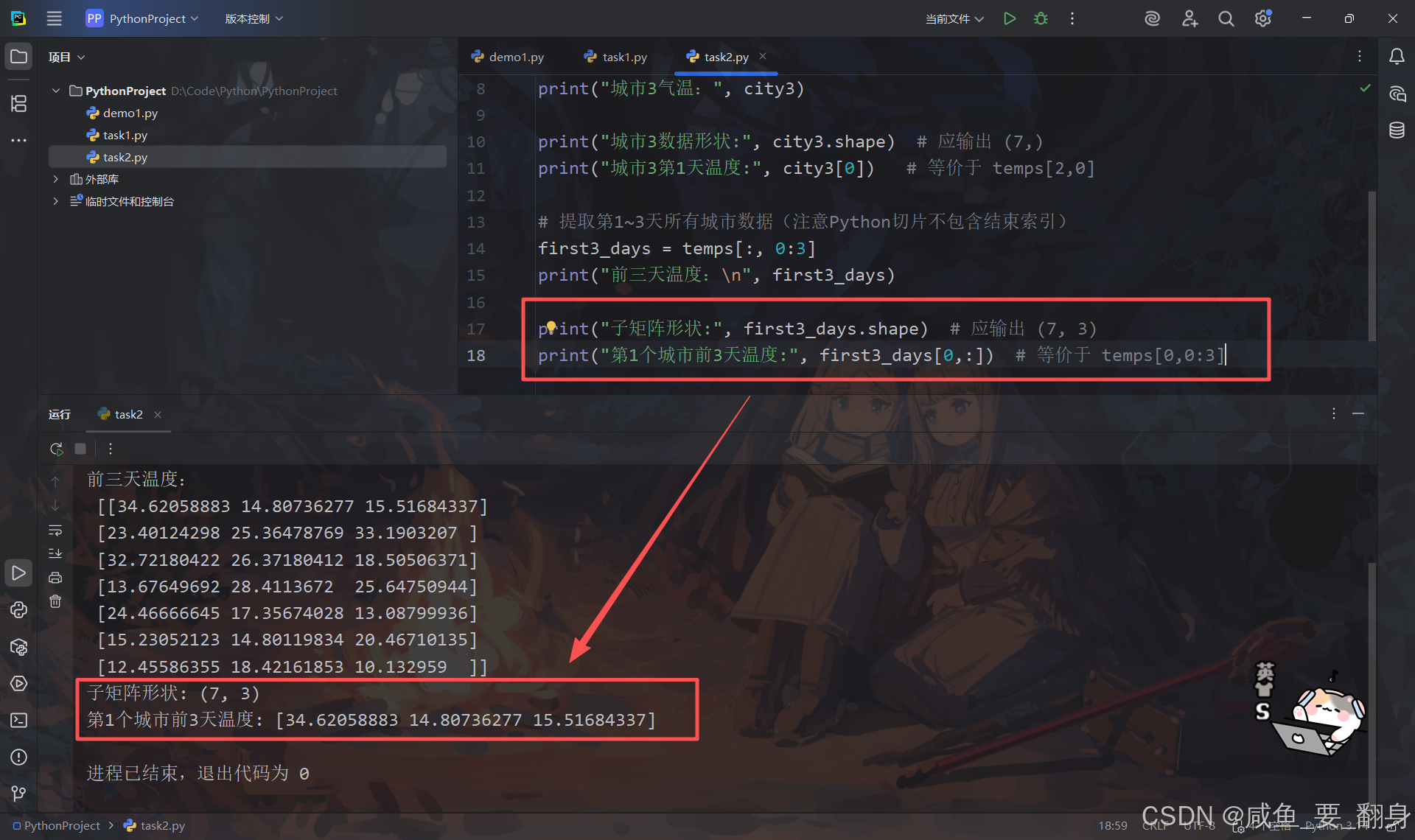
(3)布尔索引筛选异常温度
利用布尔索引找出温度低于 0℃ 或高于 35℃ 的异常数据:
# 筛选出异常温度(低于0℃或高于35℃)
abnormal = temps[(temps < 0) | (temps > 35)]
print("异常温度:", abnormal)关键点解析:
布尔条件组合:
-
(temps < 0) | (temps > 35):-
先分别计算两个布尔数组
-
用
|(按位或)组合条件
-
-
注意:必须用
|而不是or(因为已经转为布尔索引了),且需要括号(运算符优先级)
特殊值处理:
-
np.nan和np.inf不会满足任何比较条件 -
如果需要包含这些特殊值,需额外处理:
abnormal = temps[(temps < 0) | (temps > 35) | np.isnan(temps) | np.isinf(temps)]
返回结果:
-
形状:
(n,)(一维数组,n为异常值数量) -
内容:所有满足条件的温度值(包括NaN/Inf如果条件允许)
验证布尔索引:
# 创建测试数据
test_temps = np.array([[-2, 15, 36], [10, np.nan, 20]])
# 筛选异常值
test_abnormal = test_temps[(test_temps < 0) | (test_temps > 35)]
print("测试异常值:", test_abnormal) # 应输出 [-2, 36]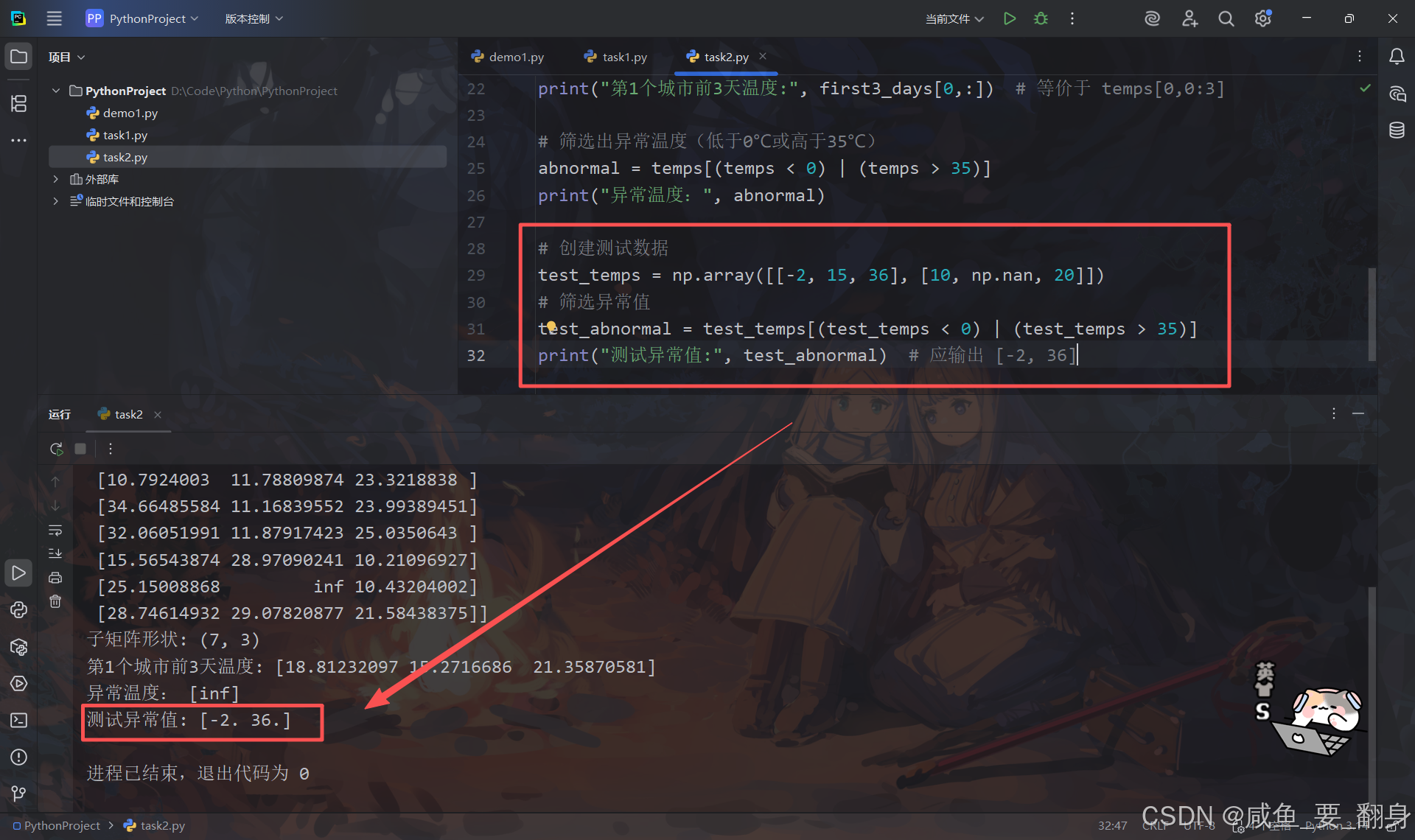
(4)沿指定轴排序温度数据
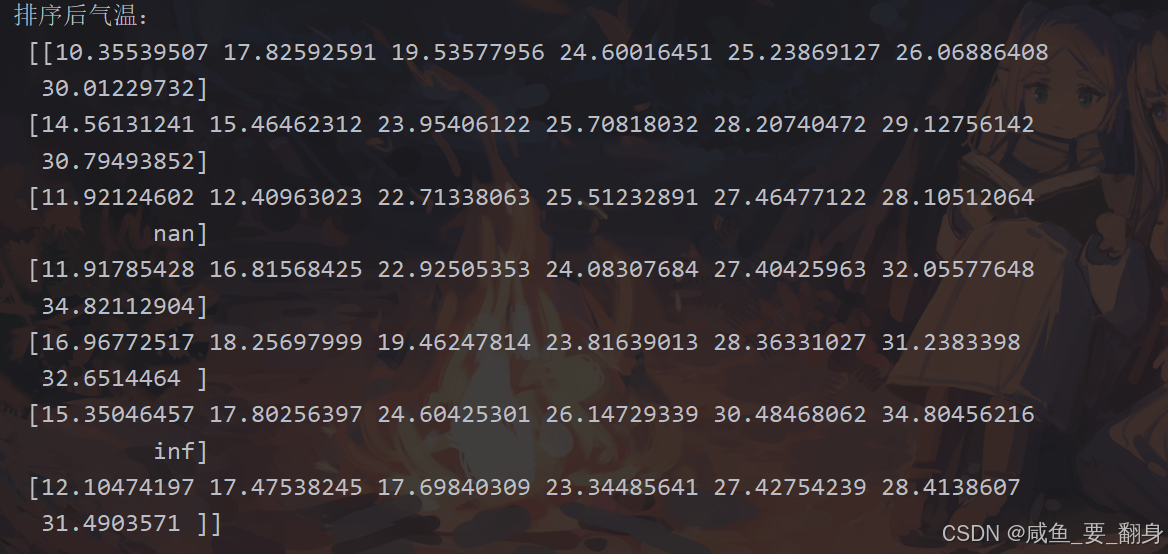
使用 np.sort() 对每个城市的温度进行排序:
# 对每个城市的温度排序(沿列方向,即每天的温度)
sorted_temps = np.sort(temps, axis=1)
print("排序后气温:\n", sorted_temps)关键点解析:
np.sort() 参数:
-
axis=1:沿行方向排序(每个城市内部排序) -
对比
axis=0:沿列方向排序(每天所有城市的温度排序)
排序特性:
-
默认升序排列
-
np.nan会被排到最后 -
np.inf会被视为极大值
返回结果:
-
形状:与原数组相同
(7,7) -
内容:每行数据已排序
验证排序结果:
# 检查某个城市的排序结果
city_idx = 0
print("原始数据:", temps[city_idx,:])
print("排序后:", sorted_temps[city_idx,:])
# 验证是否排序
print("是否升序:", np.all(sorted_temps[city_idx,:-1] <= sorted_temps[city_idx,1:]))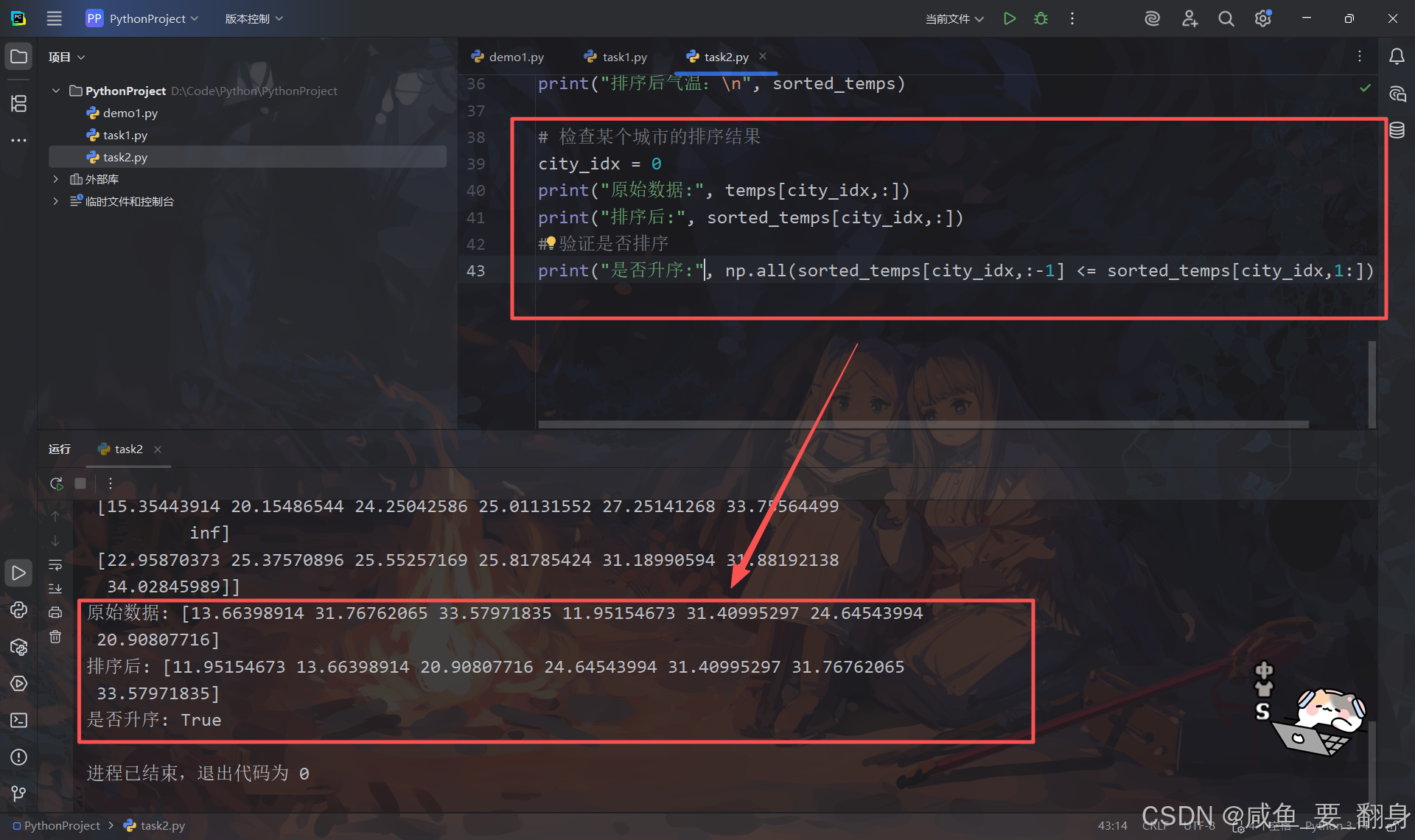
各部分含义:
-
sorted_temps[city_idx, :-1]:取指定城市的所有温度数据(除最后一个) -
sorted_temps[city_idx, 1:]:取指定城市的所有温度数据(除第一个) -
比较关系:
第1个元素 <= 第2个元素 第2个元素 <= 第3个元素 第3个元素 <= 第4个元素 ... 倒数第2个元素 <= 最后一个元素
完整代码与输出示例
import numpy as np# 创建测试数据(包含异常值以便演示)
temps = np.array([[24.1, 18.4, 29.8, 14.3, 22.7, 31.4, 16.7],[19.8, 27.6, 33.1, 20.4, 17.8, 25.3, 28.7],[22.3, 16.7, np.nan, 30.1, 24.5, 19.8, 21.3],[31.2, 26.7, 18.4, 22.3, 29.8, 17.6, 25.1],[20.4, 23.7, 19.8, 30.1, np.inf, 22.3, 28.7],[27.6, np.inf, 24.5, 19.8, 23.4, 31.2, 26.7],[-5.0, 22.3, 30.1, 25.6, 19.8, 24.5, 36.0] # 包含明显异常值
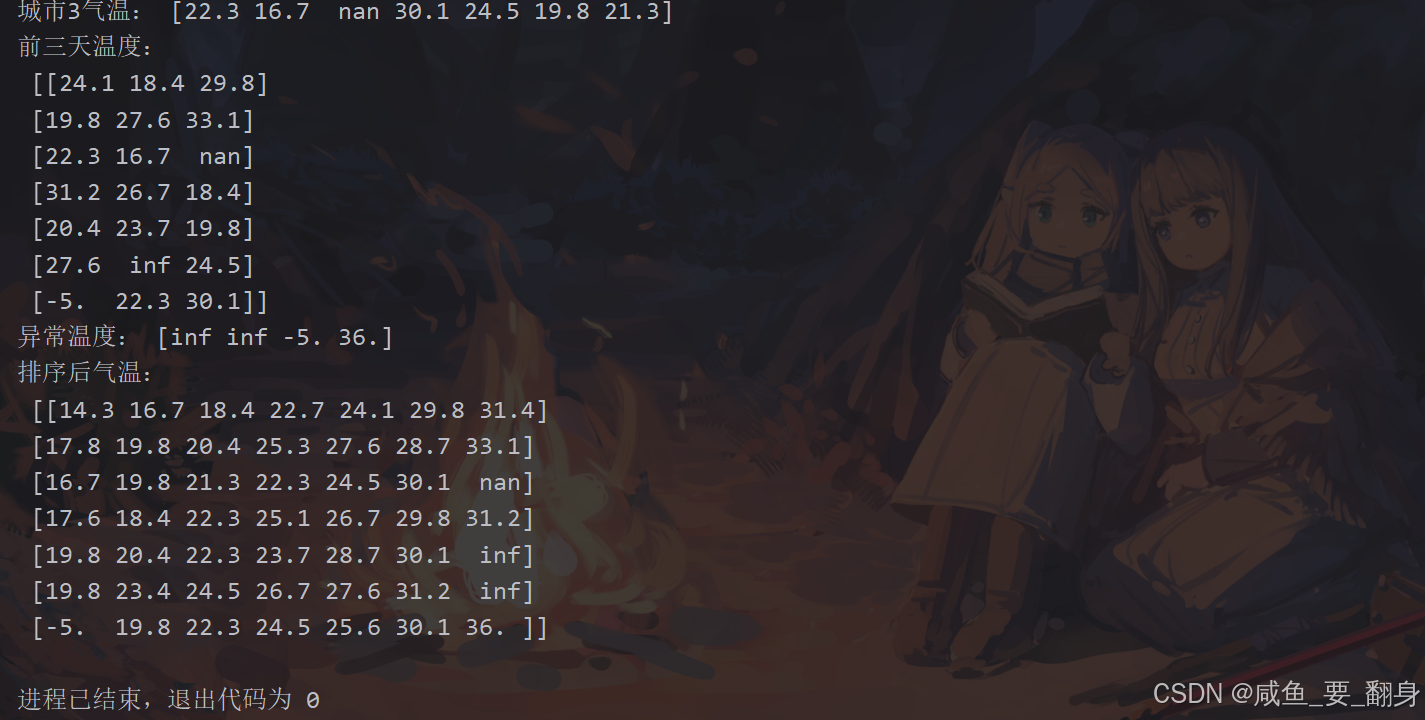
])# (1) 提取城市3数据
city3 = temps[2, :]
print("城市3气温:", city3)# (2) 提取前3天数据
first3_days = temps[:, 0:3]
print("前三天温度:\n", first3_days)# (3) 筛选异常温度
abnormal = temps[(temps < 0) | (temps > 35)]
print("异常温度:", abnormal)# (4) 沿城市维度排序(每天的温度)
sorted_temps = np.sort(temps, axis=1)
print("排序后气温:\n", sorted_temps)典型输出示例:
三、任务3:特殊数值处理 详细解析
(1)检测数据中的 NaN 与 Inf
使用 np.isnan() 与 np.isinf() 检测数据中的 NaN 与 Inf:
print("NaN 位置:\n", np.isnan(temps))
print("Inf 位置:\n", np.isinf(temps))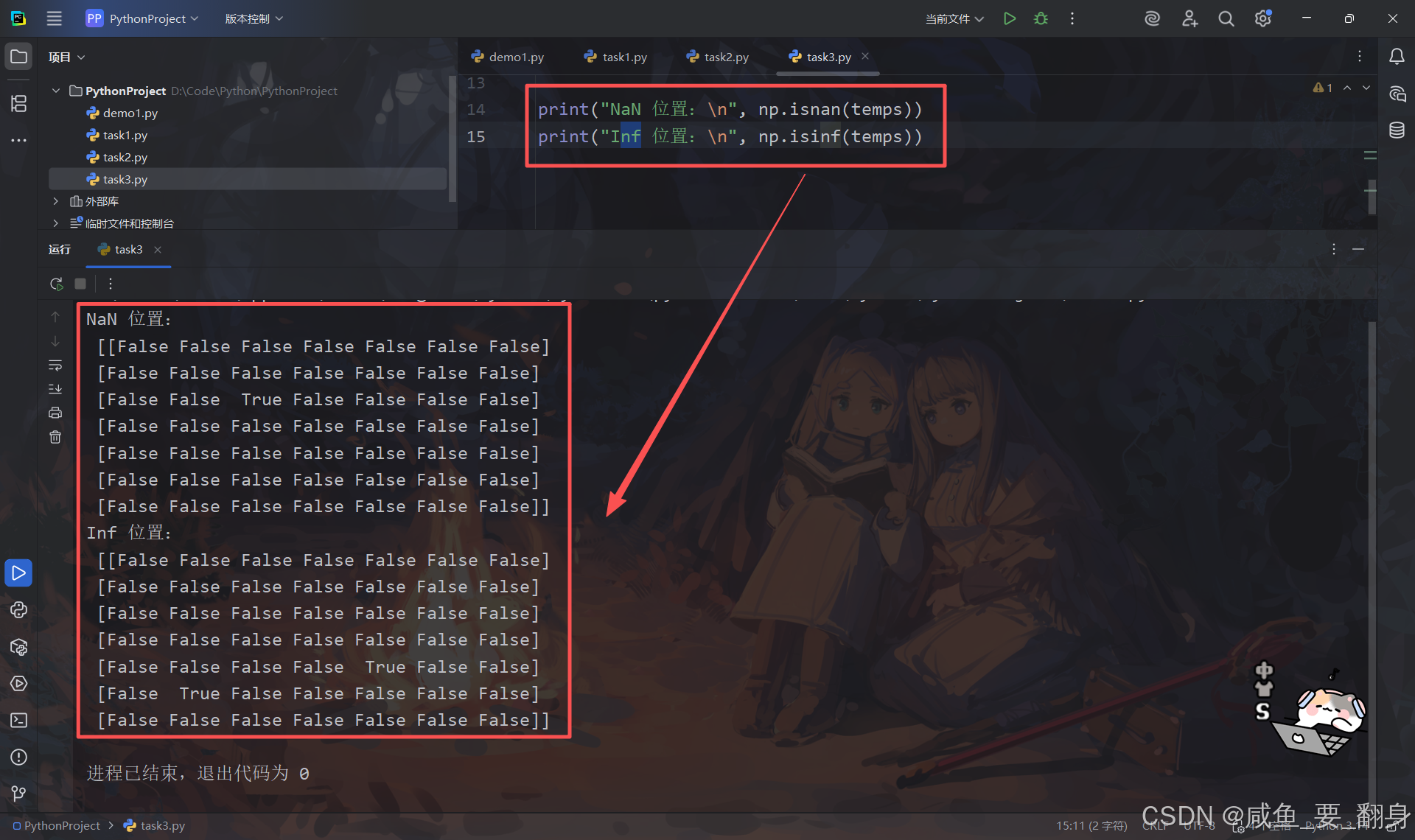
关键点解析:
np.isnan() 函数:
-
作用:检测数组中的
NaN(Not a Number)值 -
返回:布尔数组,
True表示对应位置是NaN -
示例:
arr = np.array([1, np.nan, 3]) print(np.isnan(arr)) # 输出: [False True False]
np.isinf() 函数:
-
作用:检测数组中的
Inf(无穷大)值(包括+Inf和-Inf) -
返回:布尔数组,
True表示对应位置是Inf -
示例:
arr = np.array([1, np.inf, -np.inf]) print(np.isinf(arr)) # 输出: [False True True]
组合使用:
-
可以结合逻辑运算检测有效值:
valid_mask = ~(np.isnan(temps) | np.isinf(temps))
验证检测结果:
# 创建测试数据
test_arr = np.array([[1, np.nan, 3], [np.inf, 5, -np.inf]])
print("NaN 检测:\n", np.isnan(test_arr))
print("Inf 检测:\n", np.isinf(test_arr))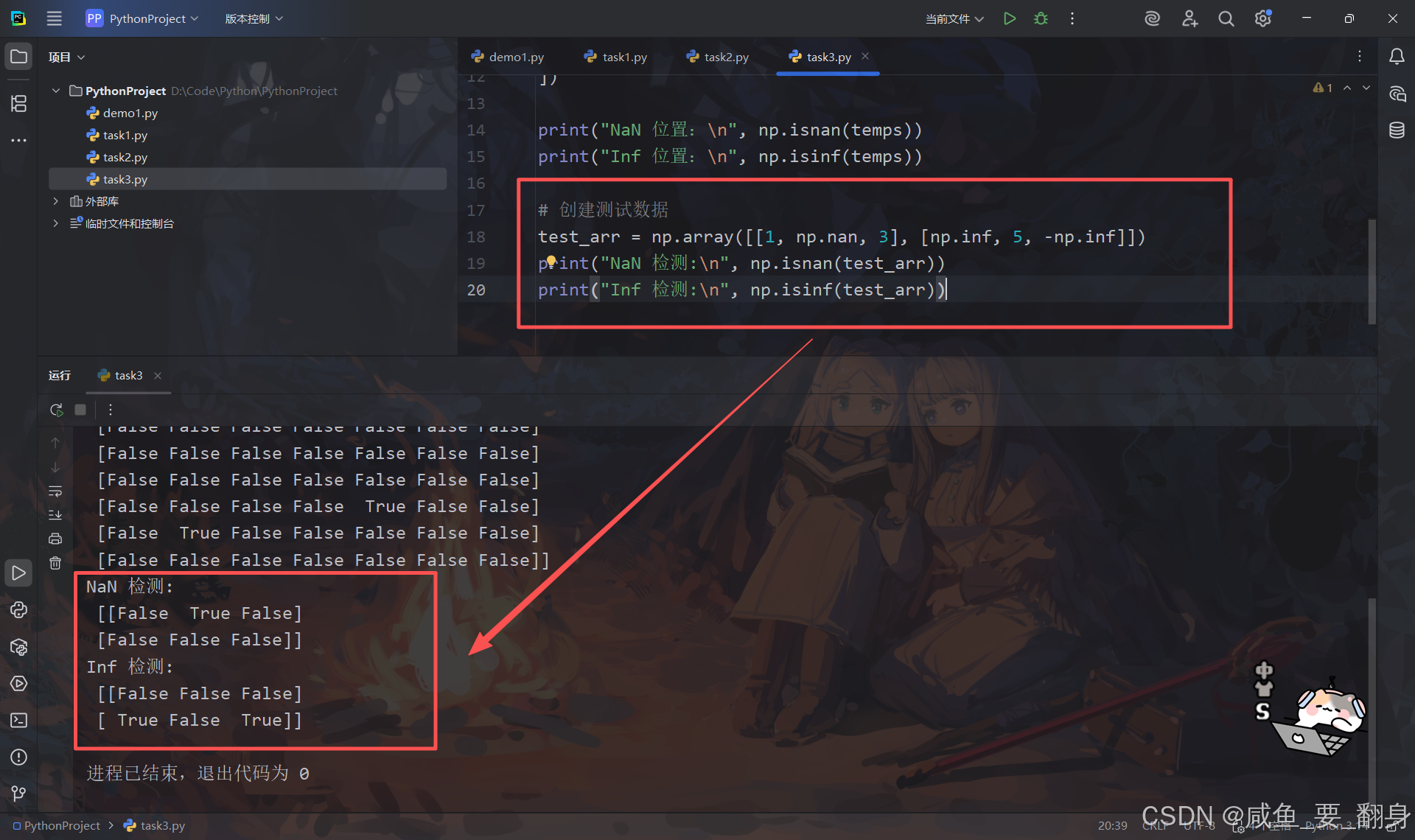
(2)替换 NaN 和 Inf
将 NaN 替换为该城市温度的平均值,将 Inf 替换为最大有效温度值:
for i in range(temps.shape[0]):row = temps[i]valid = row[~np.isnan(row) & ~np.isinf(row)] # 提取有效值mean_val = np.mean(valid) # 计算平均值max_val = np.max(valid) # 计算最大值row[np.isnan(row)] = mean_val # 替换 NaNrow[np.isinf(row)] = max_val # 替换 Inf
print("清洗后数据:\n", temps)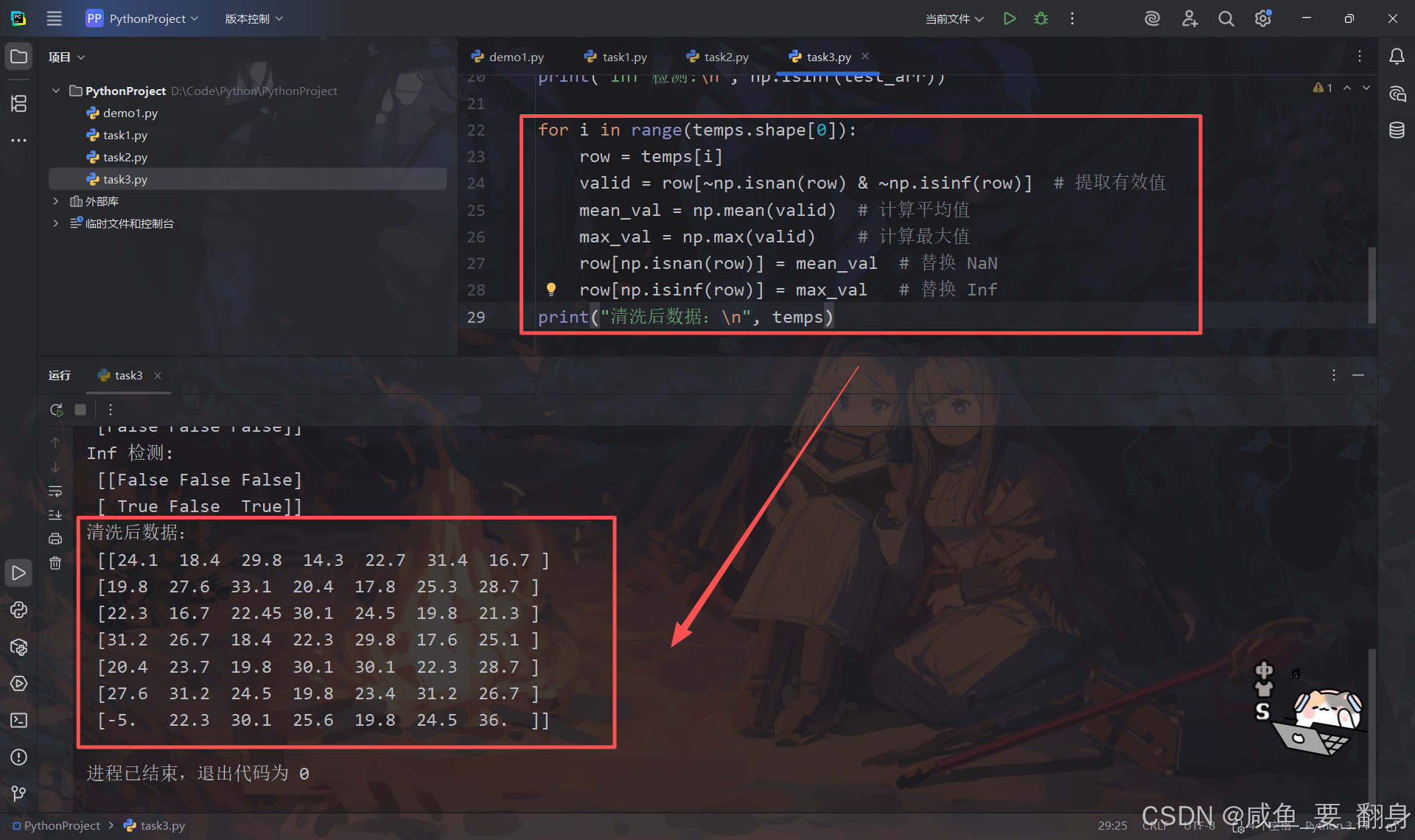
关键点解析:
逐行处理:
-
遍历每个城市(
temps.shape[0]获取行数,shape = (行数, 列数)) -
每次处理一行数据(
row = temps[i])
提取有效值:valid = row[~np.isnan(row) & ~np.isinf(row)]:
-
~是逻辑非,用于反转布尔值 -
&是逻辑与,组合两个条件 -
结果:仅包含非 NaN 且非 Inf 的值
计算统计量:
-
mean_val = np.mean(valid):计算有效值的平均值 -
max_val = np.max(valid):计算有效值的最大值
替换特殊值:
-
row[np.isnan(row)] = mean_val:将 NaN 替换为平均值 -
row[np.isinf(row)] = max_val:将 Inf 替换为最大值
注意事项:
-
如果某行全部是 NaN/Inf,
valid会为空数组,导致mean()和max()报错 -
改进方案:添加检查逻辑
if len(valid) == 0:mean_val = 0 # 或其他默认值max_val = 0
验证替换结果:
# 创建测试数据
test_temps = np.array([[np.nan, 2, 3], [np.inf, 5, 6]])
print("原始数据:\n", test_temps)# 手动替换
for i in range(test_temps.shape[0]):row = test_temps[i]valid = row[~np.isnan(row) & ~np.isinf(row)]mean_val = np.mean(valid)max_val = np.max(valid)row[np.isnan(row)] = mean_valrow[np.isinf(row)] = max_val
print("替换后数据:\n", test_temps)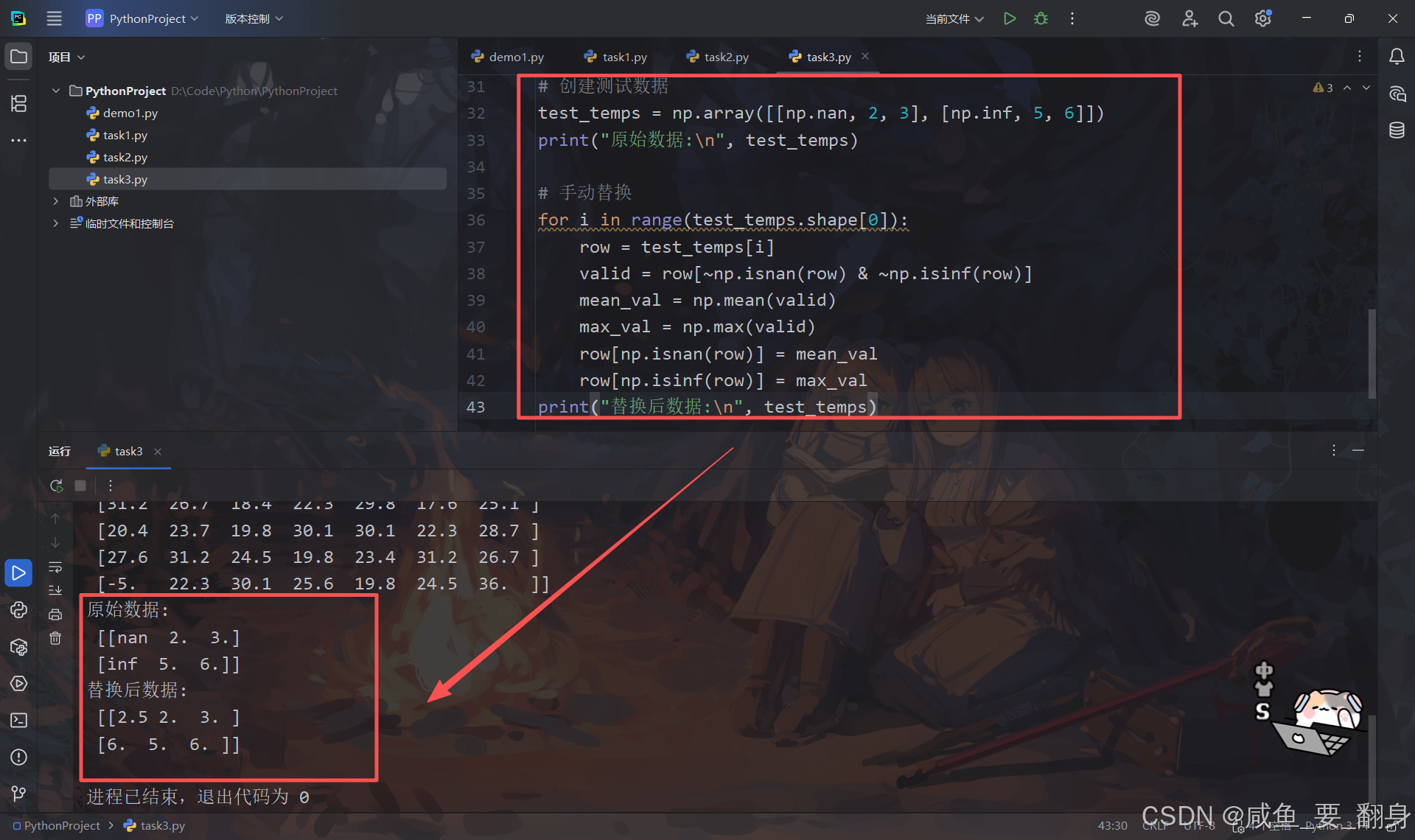
(3)比较清洗前后数据的统计特征
# 假设原始数据为 temps_original,清洗后数据为 temps_cleaned
# 这里我们直接比较清洗前后的 temps(假设 temps 还未被修改)
temps_original = temps.copy() # 保存原始数据# 执行清洗操作(同上)
for i in range(temps.shape[0]):row = temps[i]valid = row[~np.isnan(row) & ~np.isinf(row)]mean_val = np.mean(valid)max_val = np.max(valid)row[np.isnan(row)] = mean_valrow[np.isinf(row)] = max_val# 比较统计特征
print("原始数据统计:")
print("均值:", np.mean(temps_original, axis=1))
print("标准差:", np.std(temps_original, axis=1))
print("最大值:", np.max(temps_original, axis=1))print("\n清洗后数据统计:")
print("均值:", np.mean(temps, axis=1))
print("标准差:", np.std(temps, axis=1))
print("最大值:", np.max(temps, axis=1))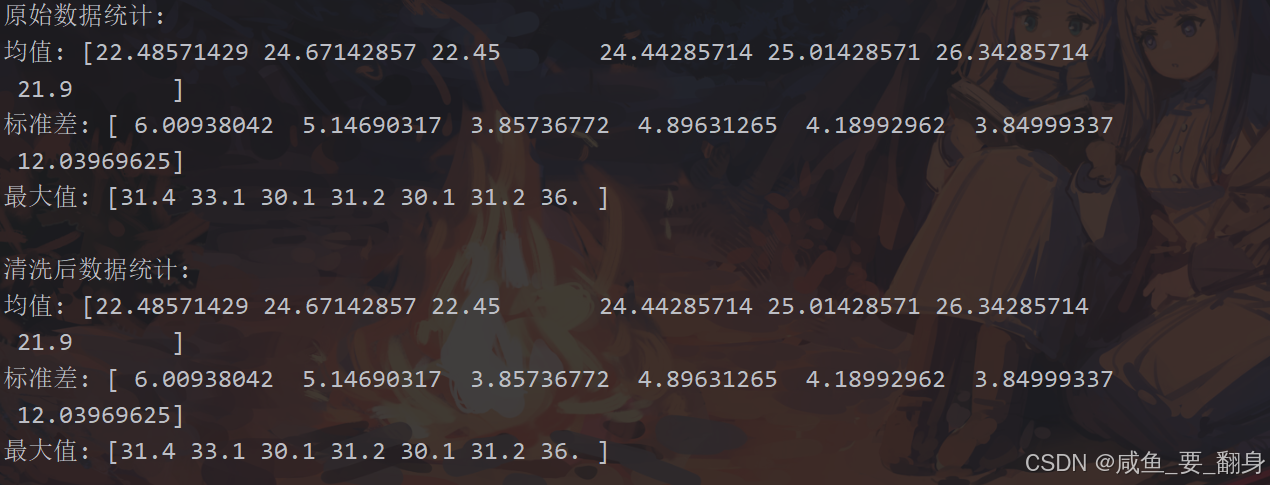
关键点解析:
统计指标:
-
np.mean(axis=1):计算每行的平均值(每个城市的平均温度) -
np.std(axis=1):计算每行的标准差(温度波动性) -
np.max(axis=1):计算每行的最大值(最高温度)
比较目的:
-
观察清洗是否显著改变了数据分布
-
检查异常值处理是否合理(如替换后的值是否偏离太多)
改进建议:
-
使用
np.nanmean()和np.nanmax()直接忽略 NaN/Inf -
比较整体统计量(不按行):
print("全局均值 - 原始:", np.nanmean(temps_original)) print("全局均值 - 清洗后:", np.mean(temps))
四、任务4:聚合与数学分析 详细讲解
任务概述
这个任务要求对温度数据集进行多种聚合和数学分析操作,包括:
-
计算每日和各城市的平均气温
-
计算最大值、最小值、标准差等统计指标
-
使用NumPy的逐元素函数进行数学变换
-
结合多种统计函数进行综合分析
代码讲解
假设我们有一个温度数据集 temps,它是一个二维NumPy数组,其中:
-
行代表不同的城市
-
列代表一周7天的温度记录
1. 计算平均值
计算每日平均气温(按列求均值)、各城市一周平均气温(按行求均值):
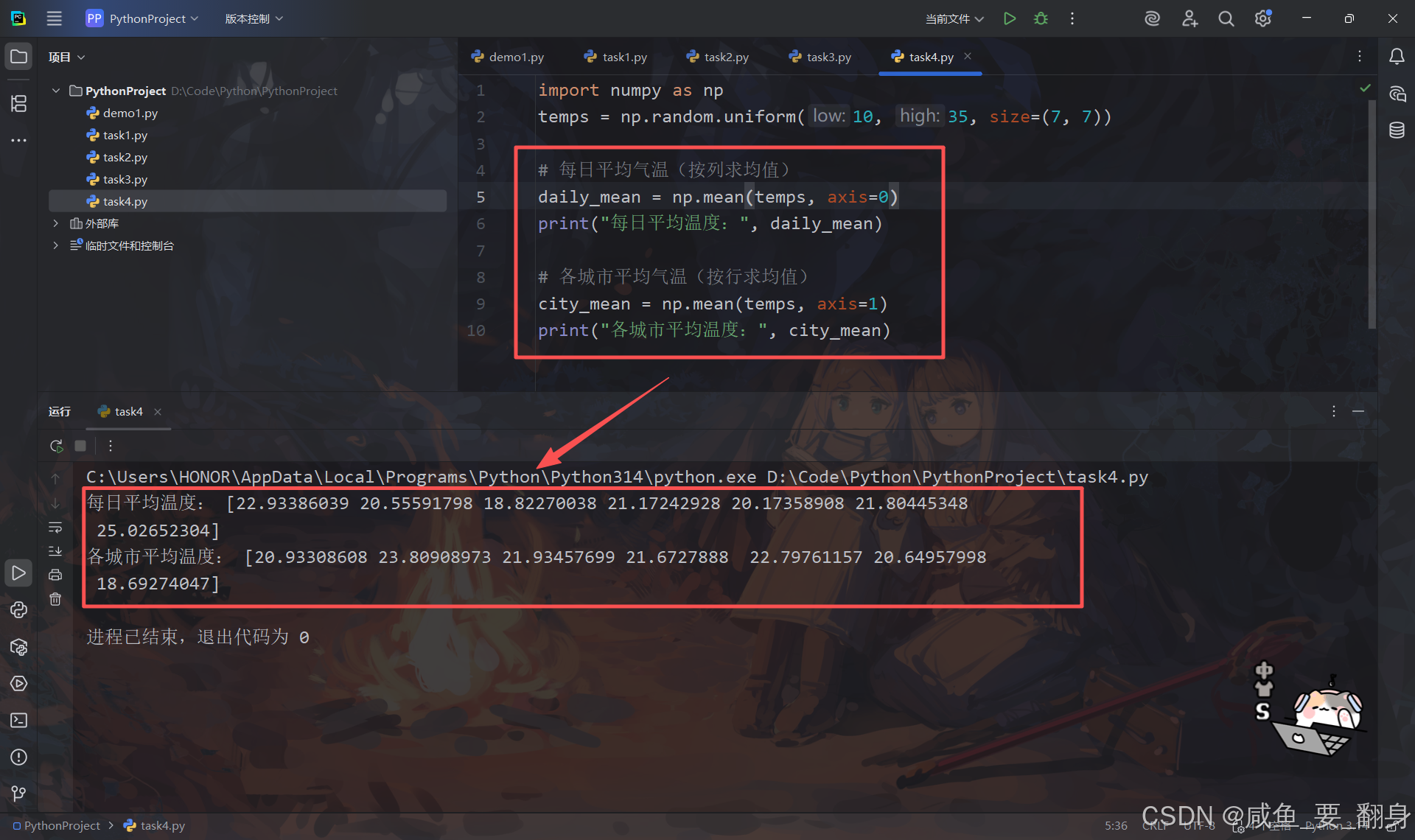
# 每日平均气温(按列求均值)
daily_mean = np.mean(temps, axis=0)
print("每日平均温度:", daily_mean)# 各城市平均气温(按行求均值)
city_mean = np.mean(temps, axis=1)
print("各城市平均温度:", city_mean)-
np.mean()是NumPy的均值计算函数 -
axis参数指定计算方向:-
axis=0:沿垂直方向(按列)计算,得到每日平均气温(所有城市在同一天的平均温度) -
axis=1:沿水平方向(按行)计算,得到各城市平均气温(单个城市一周的平均温度)
-
2. 计算最大值、最小值和标准差
计算最大值、最小值、标准差等聚合指标:
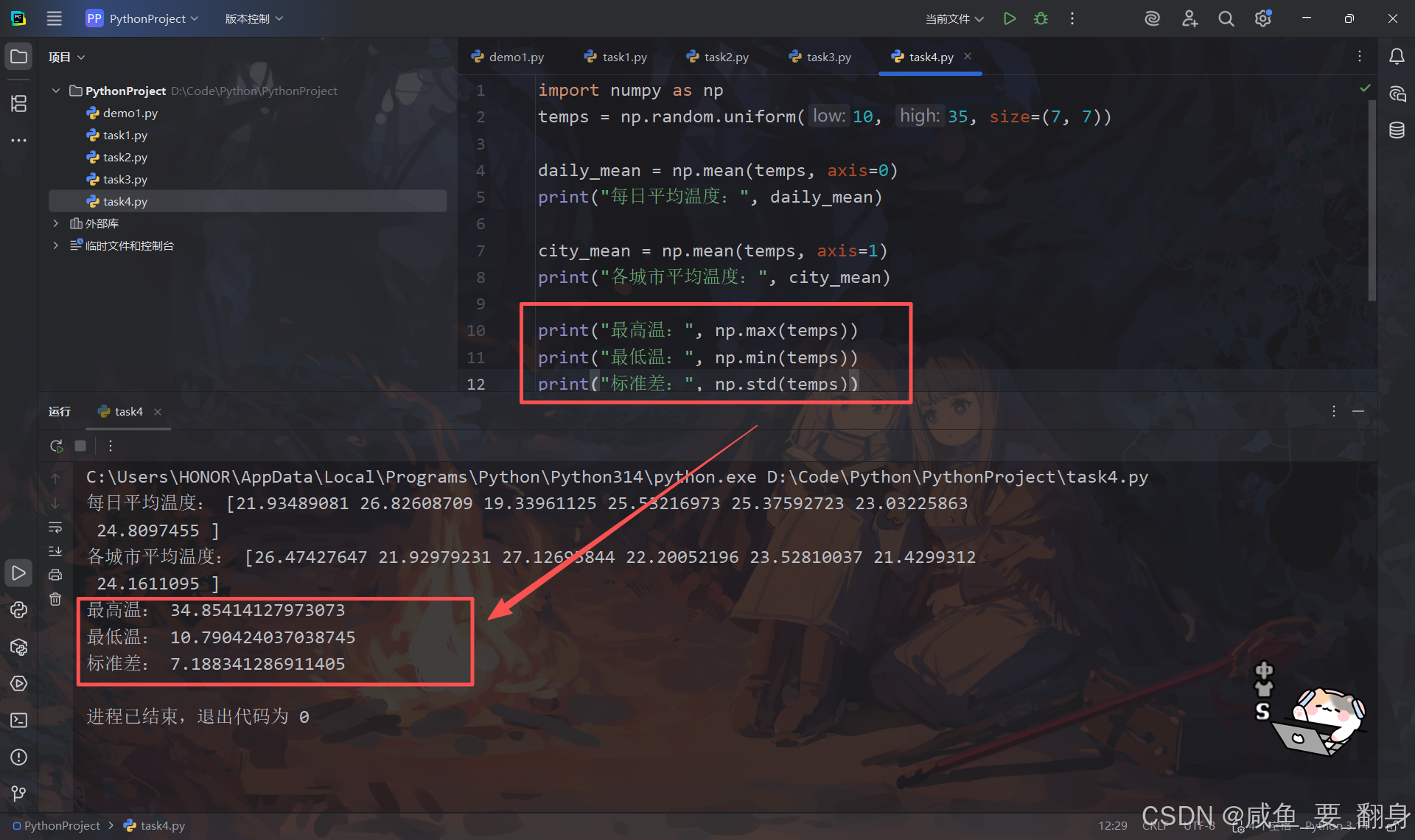
# 计算最大、最小、标准差
print("最高温:", np.max(temps))
print("最低温:", np.min(temps))
print("标准差:", np.std(temps))-
np.max():计算数组中的最大值(所有温度中的最高温) -
np.min():计算数组中的最小值(所有温度中的最低温) -
np.std():计算标准差(衡量温度数据的离散程度)
3. 数学变换
使用逐元素函数(如 np.sqrt()、np.exp()、np.log())进行数学变换,观察结果变化:
# 数学变换示例
log_temps = np.log(temps)
print("对数变换后:\n", log_temps)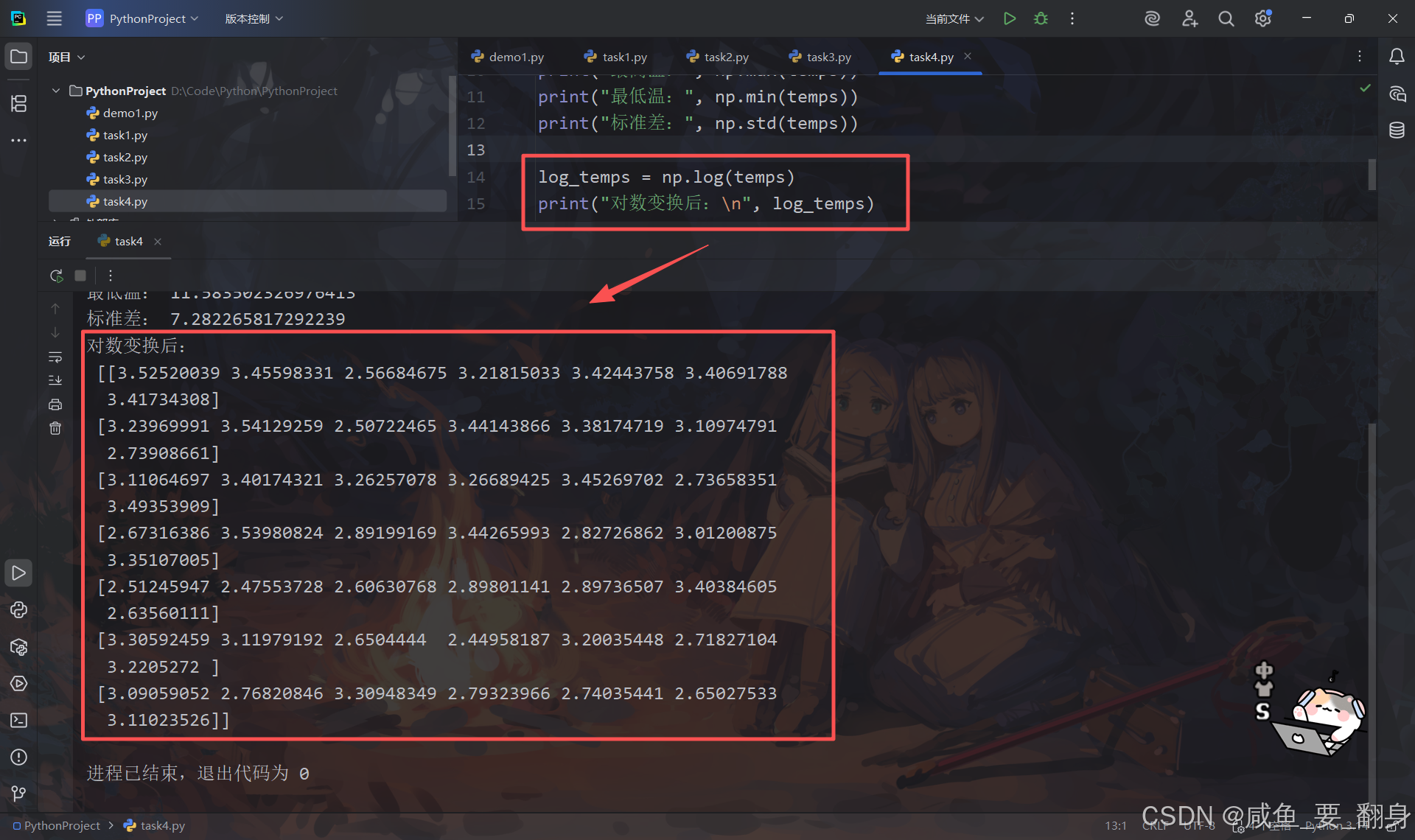
这里使用了 np.log() 进行自然对数变换,其他可用的逐元素函数包括:
-
np.sqrt():平方根 -
np.exp():指数函数 -
np.square():平方 -
np.sin()、np.cos()等三角函数
数学变换的作用:
-
改变数据的分布形态
-
缩小数据的尺度
-
使数据更接近正态分布(某些统计方法的前提假设)
注意事项:
- 输入数据必须都是正数(对数函数定义域)
- 变换后的数据单位改变,解释需谨慎
五、任务5:利用Matplotlib实现可视化 详细讲解
1、设置中文字体和解决负号显示问题
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题plt.rcParams: Matplotlib的全局配置参数
-
font.sans-serif: 设置无衬线字体为'SimHei'(黑体),确保图表中的中文能正常显示 -
axes.unicode_minus: 设置为False解决负号'-'显示为方块的问题
为什么需要这个设置?
-
默认情况下Matplotlib不支持中文显示
-
在包含负数的坐标轴上,负号可能显示为乱码
2、创建柱状图
plt.bar(range(7), city_mean)plt.bar(): 创建柱状图的函数
-
第一个参数
range(7): x轴位置,这里创建了0-6共7个位置 -
第二个参数
city_mean: 每个柱子的高度,应该是包含7个城市平均温度的数组
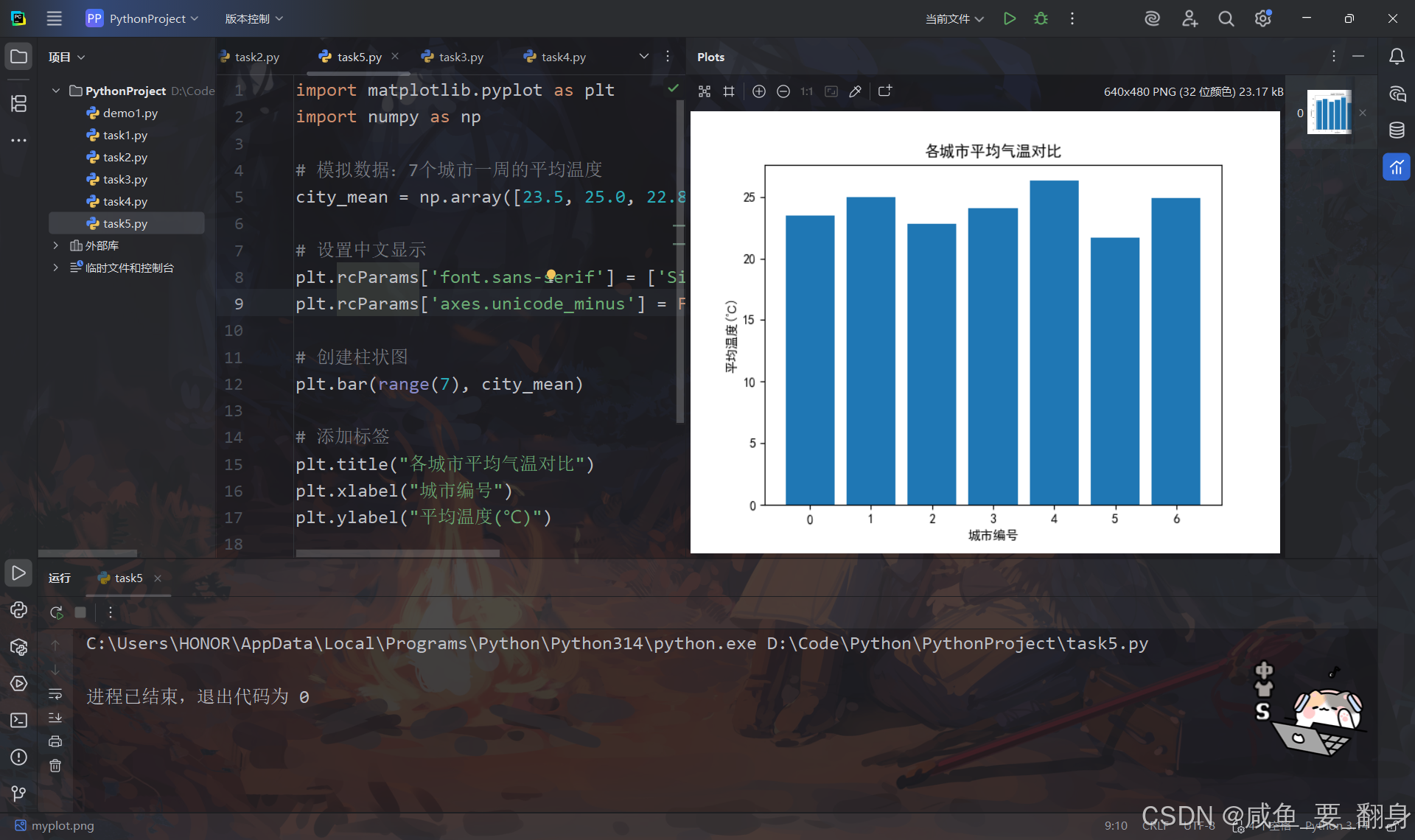
假设city_mean数据:如果city_mean = [23.5, 25.0, 22.8, 24.1, 26.3, 21.7, 24.9],则会:
-
在x=0位置画高度为23.5的柱子
-
在x=1位置画高度为25.0的柱子
-
...以此类推
3、添加图表标题和轴标签
plt.title("各城市平均气温对比") # 图表标题
plt.xlabel("城市编号") # x轴标签
plt.ylabel("平均温度(℃)") # y轴标签这些函数分别用于:
-
title(): 设置图表标题 -
xlabel(): 设置x轴说明文字 -
ylabel(): 设置y轴说明文字
4、显示图表
plt.show()-
plt.show(): 显示创建好的图表 -
在Jupyter Notebook中可能不需要这行,但在脚本中必须调用才能显示图表
完整代码示例
假设我们有以下完整数据:
import matplotlib.pyplot as plt
import numpy as np# 模拟数据:7个城市一周的平均温度
city_mean = np.array([23.5, 25.0, 22.8, 24.1, 26.3, 21.7, 24.9])# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 创建柱状图
plt.bar(range(7), city_mean)# 添加标签
plt.title("各城市平均气温对比")
plt.xlabel("城市编号")
plt.ylabel("平均温度(℃)")# 显示图表
plt.show()