【高并发架构】从 0 到亿,从单机部署到 K8s 编排:高并发架构的 8 级演进之路

文章目录
- 前言
- 一. 单机架构
- 1.1 概念引入
- 1.2 技术栈模型
- 二. 应用数据分离架构
- 2.1 概念引入
- 2.2 技术栈模型
- 三. 应用服务集群架构
- 3.1 概念引入
- 3.2 技术栈模型
- 四. 读写分离/主从分离架构
- 4.1 概念引入
- 4.2 技术栈模型
- 五. 冷热分离架构
- 5.1 概念引入
- 5.2 技术栈模型
- 六. 垂直分库架构
- 6.1 概念引入
- 6.2 技术栈模型
- 七. 微服务架构
- 7.1 概念引入
- 7.2 技术栈模型
- 八. 容器编排架构
- 8.1 概念引入
- 8.2 技术栈模型
前言
在互联网行业飞速发展的当下,企业应用从初创期到承载亿级用户、高并发访问,系统架构的 “承载力” 成为业务持续发展的核心保障 —— 既要承接海量流量冲击,又要保障服务高可用、可扩展与迭代效率。
但架构演进从无 “一步到位”。从支撑小规模业务的单机架构,到优化数据管理的应用数据架构;从突破单机性能瓶颈的应用服务集群架构,到缓解数据库压力的读写分离 / 主从分离、冷热分离、垂直分库架构;再到应对系统复杂度的微服务架构,以及云原生时代的容器编排架构…… 每一类架构,都是技术团队为解决特定阶段 “性能、扩展性、开发效率” 等问题,探索出的阶段性方案。
本文将沿着 “亿级高并发” 的架构演进路径,以 “概念引入” 说明每种架构的诞生背景与核心目标,以 “技术栈模型” 解析其实现要点,助力你理清架构迭代逻辑,在不同业务阶段找准架构设计的思路。
一. 单机架构
1.1 概念引入
在互联网初期,用户的访问量很少,并没有对产品的性能和安全性提出很高的要求,所以选择了一种比较简单的架构:单机架构,架构简单,不需要专业的运维同志。
- 单机服务架构是将应用程序、数据库、存储等所有服务组件都部署在同一台物理服务器或虚拟机上的架构模式,所有业务请求都在这一台机器内完成处理。
1.2 技术栈模型
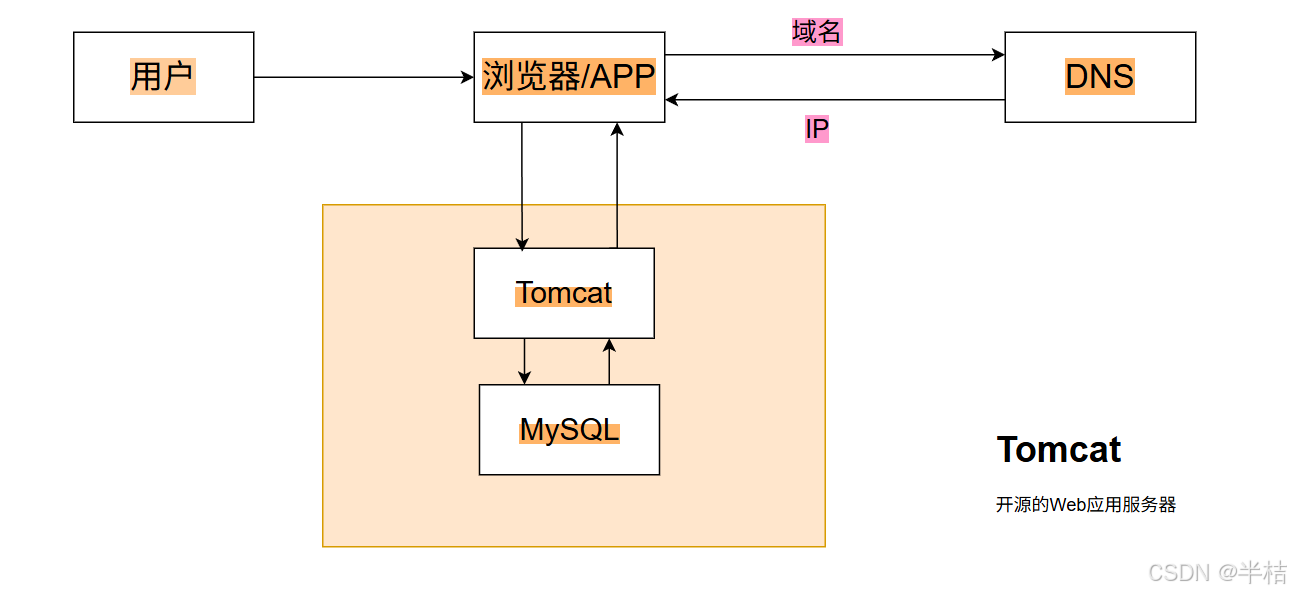
- 用户先登录浏览器,输入要进行访问的域名;
- 浏览器将域名交给DNS机构,DNS返回IP给浏览器;
- 浏览器将请求发送到目标服务器上,目标服务器从数据库中拿取数据,再返回给服务器。
二. 应用数据分离架构
2.1 概念引入
因为单机架构将应用服务与数据库服务放在同一个服务器上,共用一份资源,这就必定会导致双方竞争资源。
- 因此应用数据分离架构就是将应用服务与数据库服务分布在不同的服务器上。
- 该架构中应用服务与数据库服务通过网络进行通信。
2.2 技术栈模型
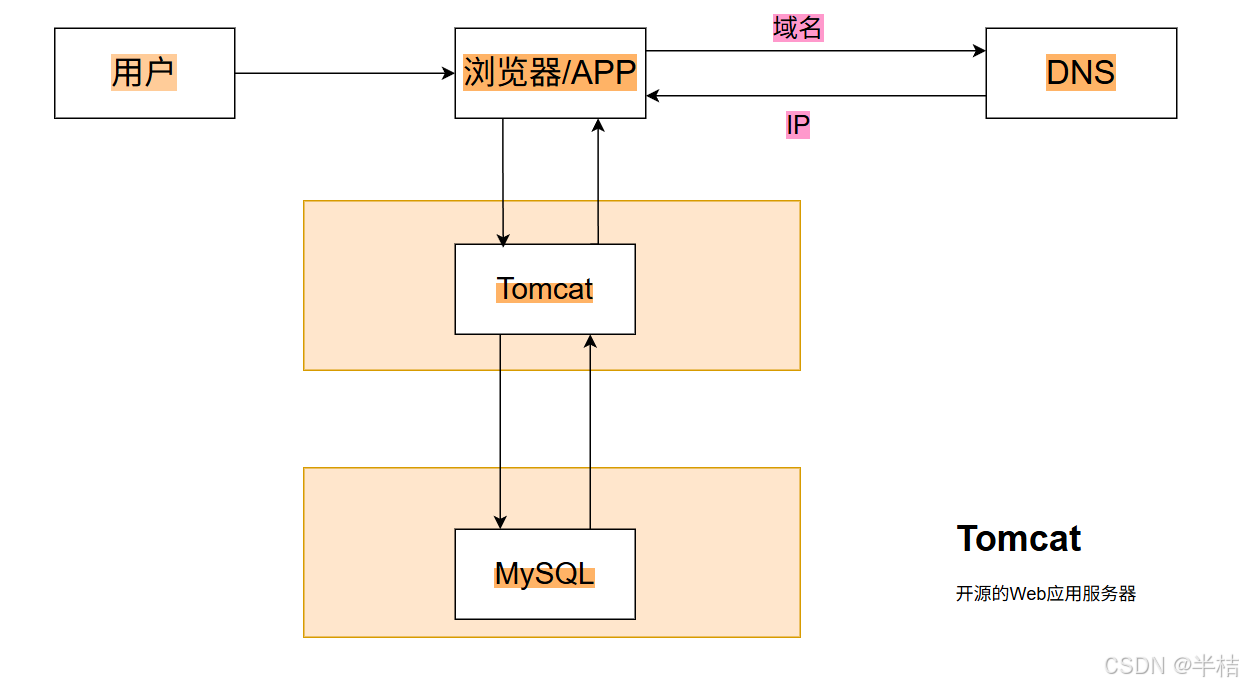
用户获取数据的流程与上面类似,此处就不再赘述了。
三. 应用服务集群架构
3.1 概念引入
此时我们的产品开始变得流行起来了,一个应用服务器已经扛不住了,此时我们需要进行解决,那如何进行解决呢??
- 最直接的方法就是:增加应用服务器的数量,让多个应用服务器来处理业务,这就是应用服务集群架构。
此时又出现了另一个问题:每个服务器都有一个IP地址,用户的请求来了交给那一台服务器??
- 此时就需要引入另一个应用服务:负载均衡。
引入负载均衡,确实解决了产品的应用服务器的资源分配问题,但是现在负载均衡也是一个应用,也要部署在应用服务器上,那么负载均衡服务器会不会扛不住???*
答案是:会,负载均衡服务器也会扛不住,此时依旧是原来的方法,搞多个负载均衡应用服务器,在其上面再使用一个更好的负债均衡服务器。
常见的负载均衡选择由以下几类:
Nginx:可处理1~10+万并发;LVS:处理10~100+万并发;F5:处理100~1000+万并发;
因此可以通过这种一层层的往上进行叠加来实现负载均衡。那么如果F5也扛不住了怎么办?
- 此时就有最后一道防线
DNS来进行解决,DNS知道用户要访问的域名有多个服务器可以进行访问,此时DNS就可以为不同用户返回不同服务器IP,来让用户均衡访问。
3.2 技术栈模型
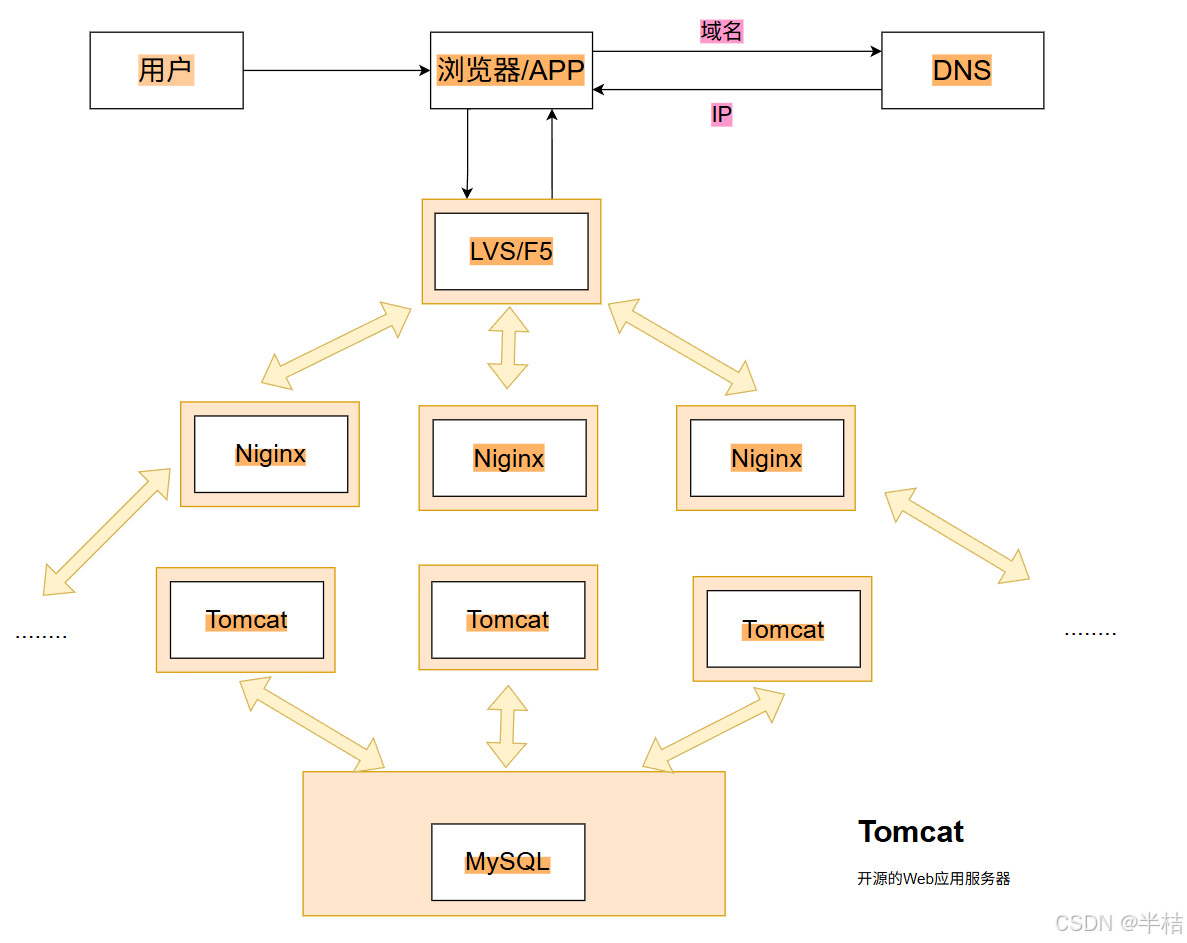
- 用户先登录浏览器,输入要进行访问的域名;
- 浏览器将域名交给DNS机构,DNS返回IP给浏览器;
- 浏览器将请求发送到负载均衡服务器上,有负载均衡应用负责将请求交给线程的服务器,最后加到产品应用服务器上;
- 同理将响应也依次向上进行传递。
四. 读写分离/主从分离架构
4.1 概念引入
在上面架构中,我们确实通过增加应用服务器解决了应用服务器扛不住的问题。
但是,此时又有另一个问题了:所有应用服务都要从数据库中进行数据的读取和写入,此时数据库扛不住了,折磨多应用同时进行读写。
如何进行解决:直接搞多个数据库服务器???
肯定不能直接这样做,因为数据库服务器中的数据必须要能够共享,负责又会出现不同用户读取不同的数据库,读取出来的数据居然是不一样的。
- 此时引入了读写分离或主从分离架构,设置一个主数据库服务器,负责所有应用的写操作,设置多个从数据库服务器,都负责用户的读请求。
此时每次先主数据库插入数据后,都将数据拷贝一份到所有的从数据库中,保证所有数据库数据一致。
同样增加多个数据库,就有需要进行负载均衡,此处采用的中间件是Mycat或tddl。
4.2 技术栈模型
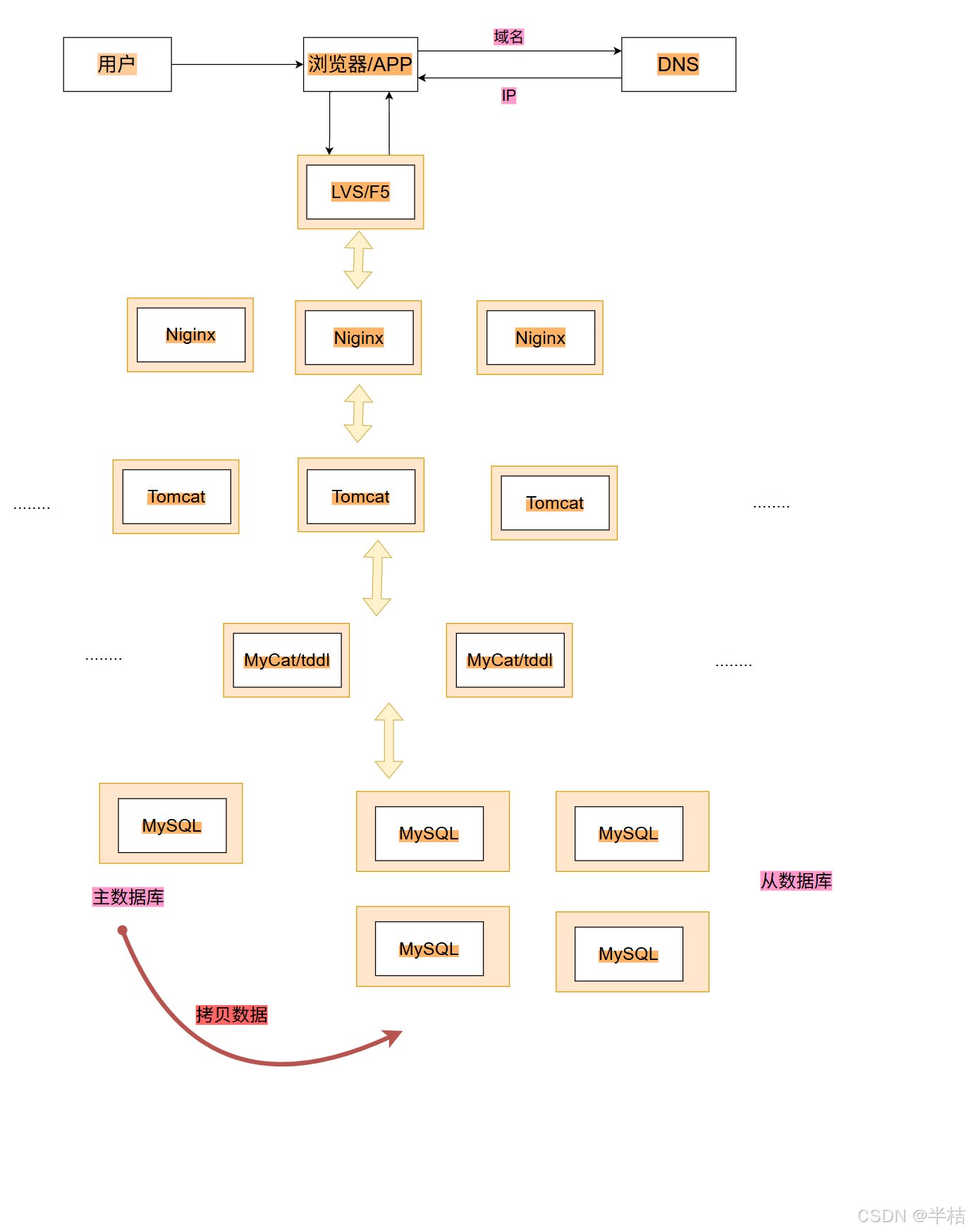
- 用户先登录浏览器,输入要进行访问的域名;
- 浏览器将域名交给DNS机构,DNS返回IP给浏览器;
- 浏览器将请求发送到负载均衡服务器上,有负载均衡应用负责将请求交给线程的服务器,最后加到产品应用服务器上;
- 应用服务器如果要进行写操作,直接去主数据库中进行写入,写入完成后,将写入的数据拷贝一份给所有的从数据库;如果应用服务器要进行读操作,直接去从数据库中进行读取。
五. 冷热分离架构
5.1 概念引入
此时的架构基本已经满足我们的需要了,但是每次在数据库中进行读取的时候都还是要从磁盘上进行读取,与外设IO的效率是很慢的,此时为了更加提高效率,我们又引入了另一个组件。
- 引入缓冲,实现冷热分离,将高频访问的热数据单独存放在一个服务器中,将访问量较少的数据依旧放到磁盘中,这就是冷热分离架构。
此时我们采用的组件是redis来负责将热数据进行缓存。
5.2 技术栈模型
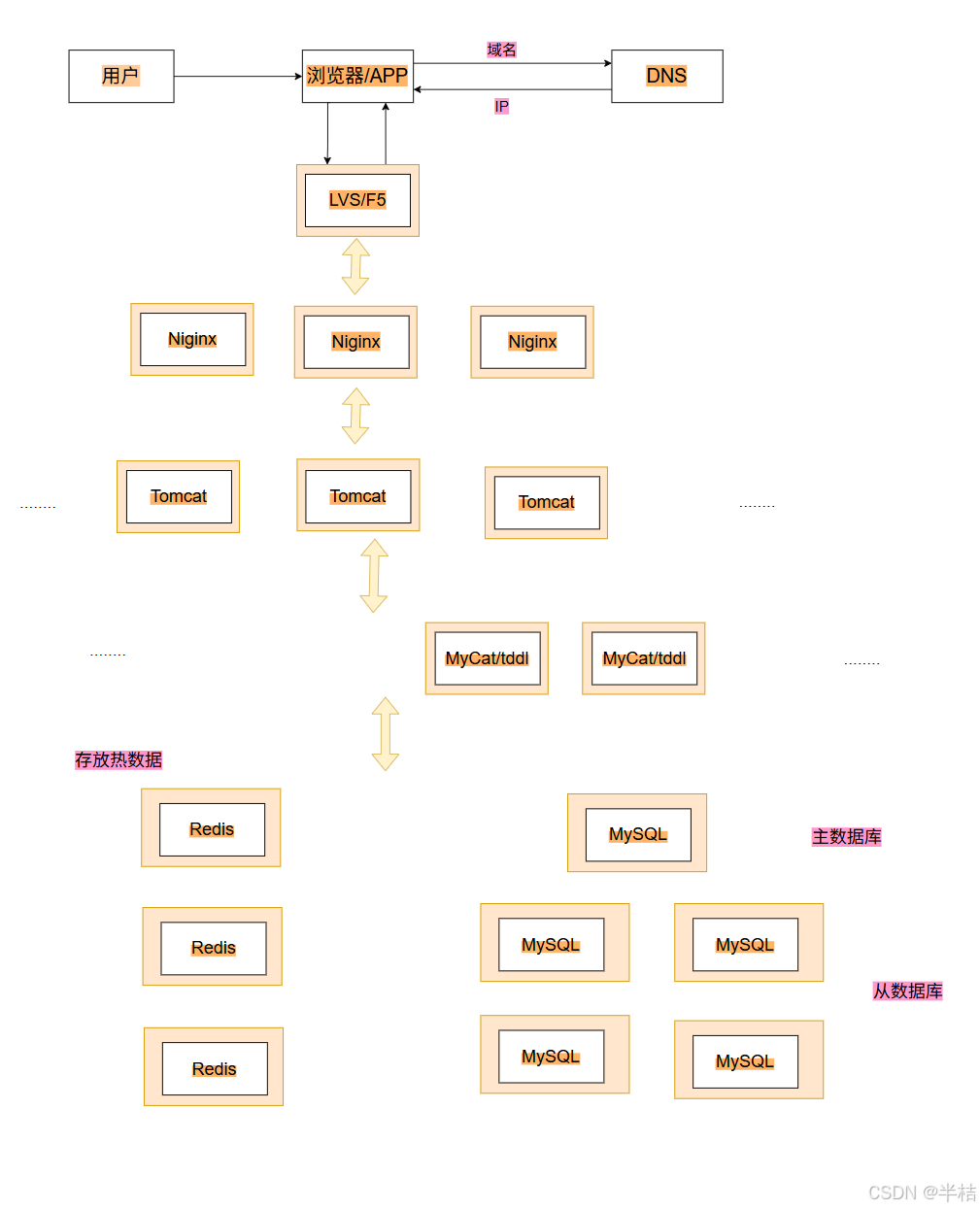
- 用户先登录浏览器,输入要进行访问的域名;
- 浏览器将域名交给DNS机构,DNS返回IP给浏览器;
- 浏览器将请求发送到负载均衡服务器上,有负载均衡应用负责将请求交给线程的服务器,最后加到产品应用服务器上;
- 在进行读取的时候,先从
redis中进行读取,如果有直接拿到数据,如果没有再到MySQL数据库中进行数据的读取。
六. 垂直分库架构
6.1 概念引入
随着业务的数据量增大,大量的数据存储在同一个库中已经显得有些力不从心了,所以可以按照业务,将数据分别存储。
- 此时就可以根据数据的类型,进行分类,将不同类型的数据放在不同的数据库中,部署到不同的服务器上,这就是垂直分库架构。
其中分库,分表的操作可以由上面谈到的Mycat中间件来负责。
其中可以使用:
- Redis Cluster是Redis 官方分布式集群方案;
- TiDB作为分布式关系型数据库,来对每个MySQL数据库集群进行管理。
6.2 技术栈模型
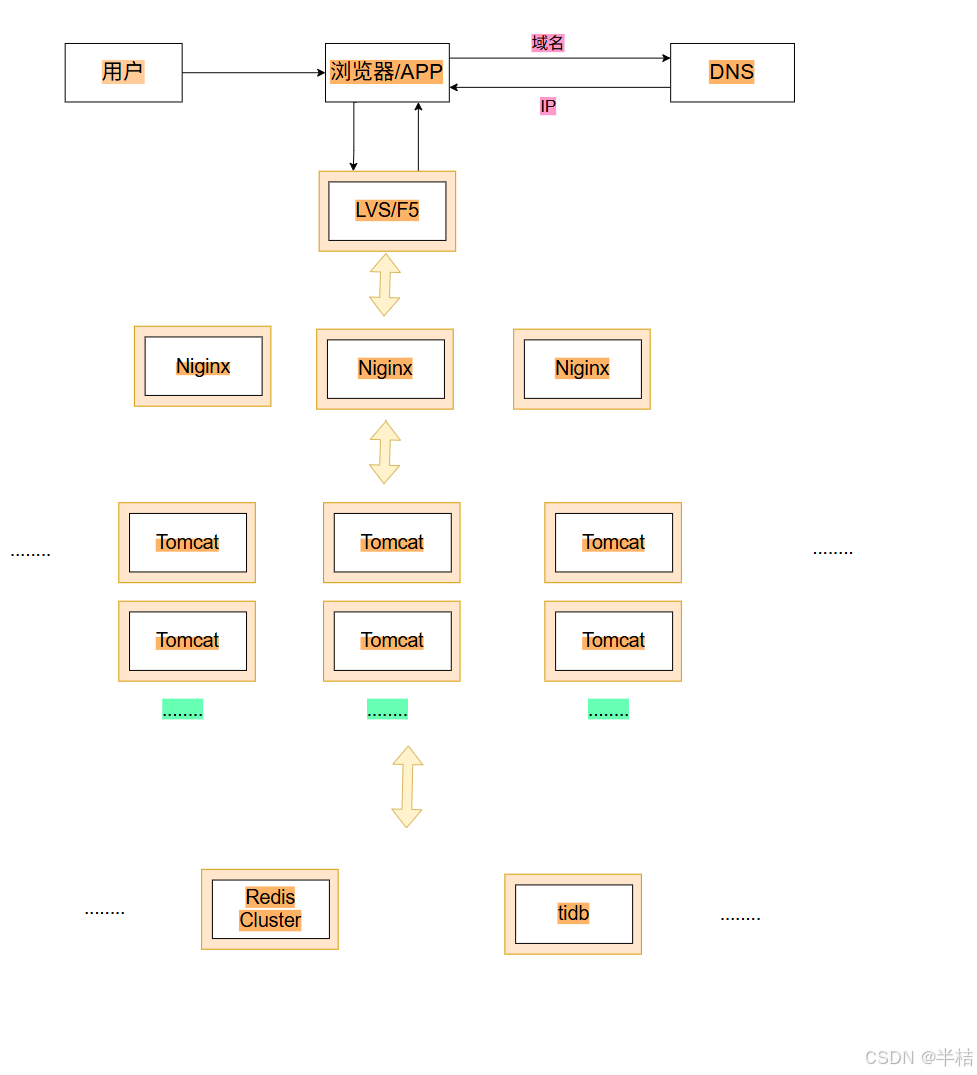
通过这种方式,应用服务器在进行数据读取的时候,只需要根据要读取的数据类型,到指定的数据库中进行读取即可。
七. 微服务架构
7.1 概念引入
随着产品中业务的不断增加,有些业务用户需要频繁使用,而有些业务用户的用户的使用频率就很好,此时如果还是将每个服务器上都部署所有的业务,让每个应用服务器都能够处理所有业务,就会导致服务器中的一些资源是浪费的。
- 此时就引入了微服务架构将复杂业务系统拆分为多个独立、可独立部署、可独立扩展的小型服务
此处就可以使用:Spring Cloud 和 Dubbo 都是 Java 生态中主流的微服务框架,用于解决分布式系统中服务间的通信、治理、协调等问题,但两者的设计理念、技术路线和侧重点有明显差异。
7.2 技术栈模型
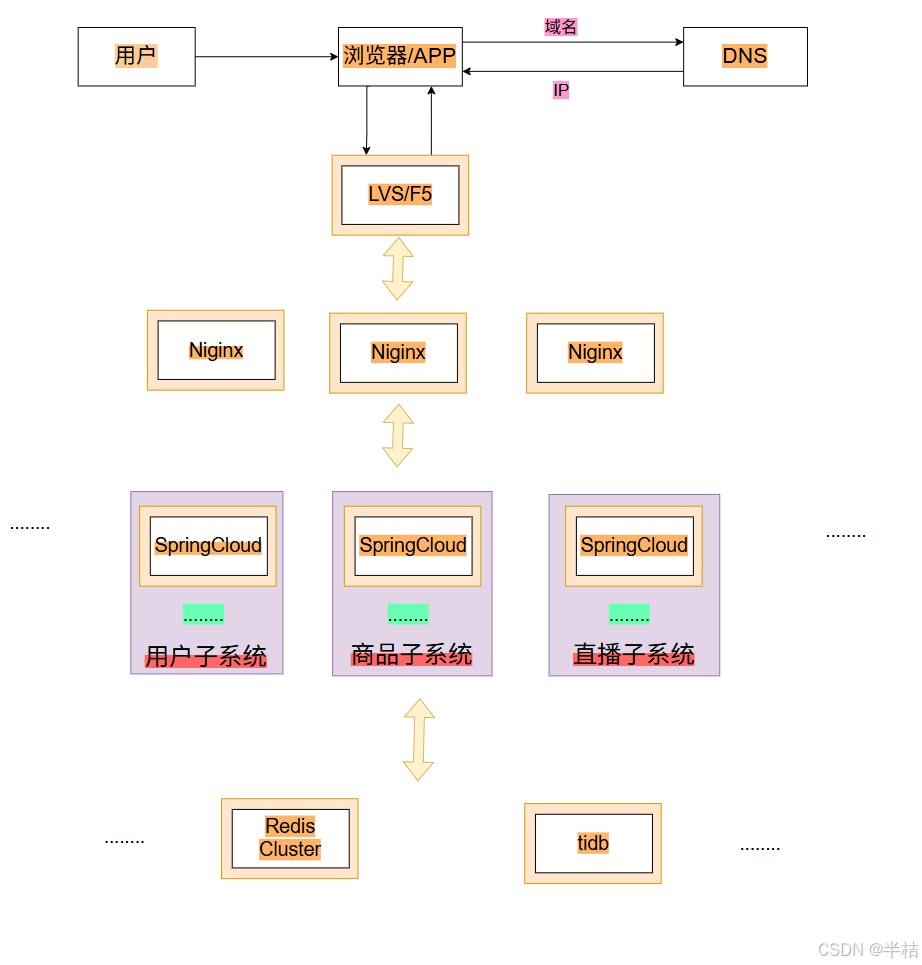
从此以后,负载均衡在进行请求的分发的时候,会将对应的请求发送给对应的应用系统来进行处理。
八. 容器编排架构
8.1 概念引入
随着业务增长,然后发现系统的资源利用率不高,很多资源用来应对短时高并发,平时又闲置,需要动态扩缩容,还没有办法直接下线服务器,而且开发、测试、生产每套环境都要隔离的环境,运维的工作量变的非常大。
比如,如果双11到了,淘宝的订单量会变得分到,此时就需要使用一些额外的服务器来满足需求,此时就让运维去再额外部署500台服务器,双11过了,订单量下来了,此时再让运维将这些服务器上的应用下下来。
过了几天,元旦到了,订单量又变得很大,又让运维去再部署500台服务器,过了两天,又让运维将应用从服务器上下下来。此时运维需要频繁的对大量服务器重复的进行同样的操作,并且数量还不少,运维同志的工作量变得巨大。
- 因此就出现了容器编排架构,借助容器化技术(如Docker)将应用/服务打包为镜像,通过容器编排工具(如k8s)动态分布,部署镜像,让服务以容器化方式运行。
8.2 技术栈模型
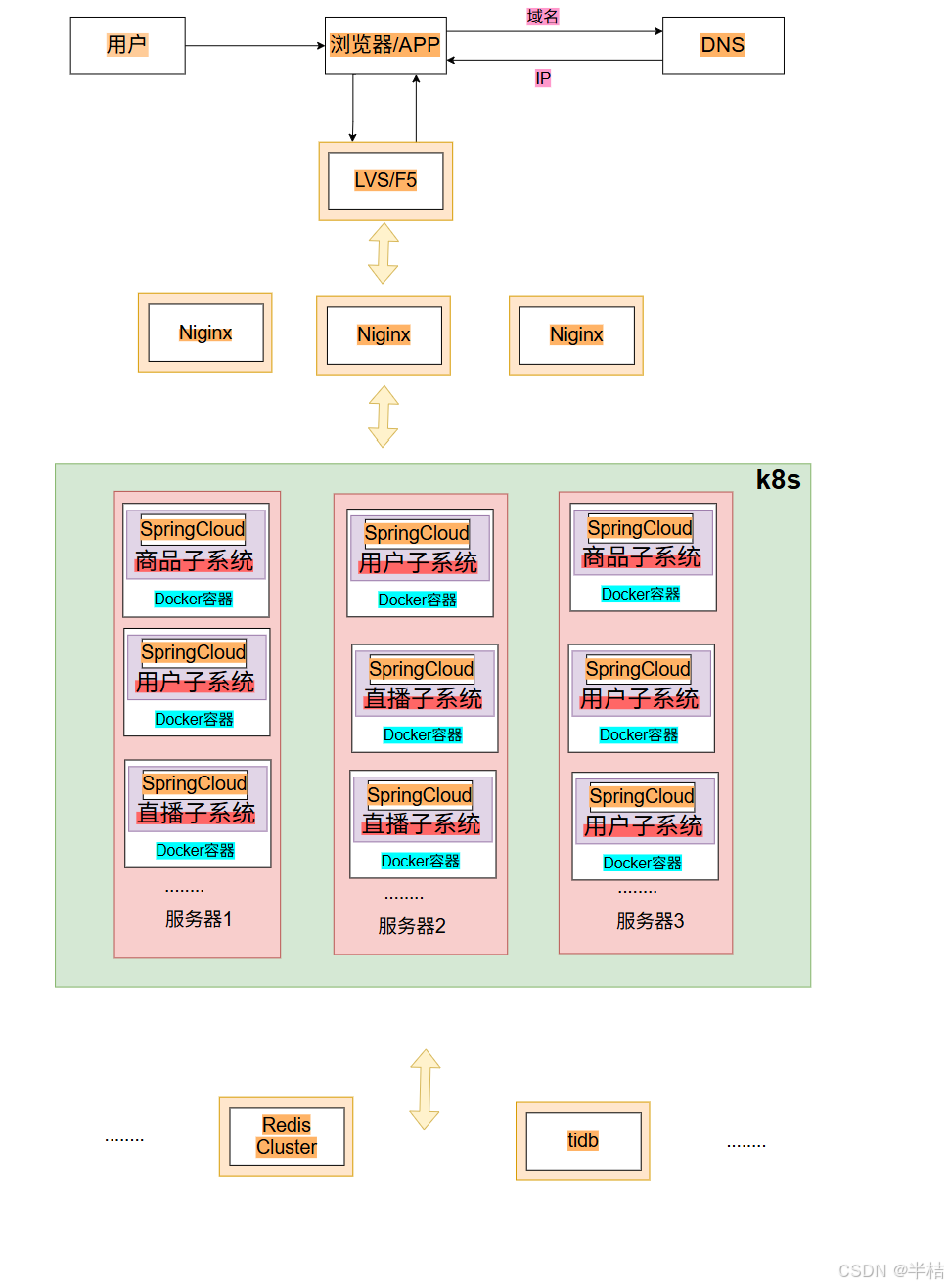
应用/服务可以打包为 Docker 镜像,通过 K8S 来动态分发和部署镜像。
Docker 镜像可理解为一个能运行你的应用/服务的最小的操作系统,里面放着应用/服务的运行代码,运行环境根据实际的需要设置好。把整个“操作系统”打包为一个镜像后,就可以分发到需要部署相关服务的机器上,直接启动 Docker 镜像就可以把服务起起来,使服务的部署和运维变得简单。