基于 ESP32 与机器学习的智能语音家居控制系统
一、系统概述
本系统以ESP32(或 ESP32-S3) 为核心,融合机器学习技术实现本地化语音识别,无需依赖云端即可完成语音唤醒、命令解析与家居设备控制。系统支持自定义唤醒词(如 “小 ESP”)和常用控制命令(如 “打开灯光”“关闭风扇”),通过继电器模块控制家电,同时提供语音反馈(如 “已打开空调”)。相比传统云端语音控制,本系统具有响应速度快(<500ms)、隐私性强(本地处理)、无网络依赖的优势,适合家庭、办公室等场景的智能控制。
二、核心技术与方案设计
1. 技术架构
系统采用 “本地语音处理 + 机器学习推理 + 设备控制” 的架构,关键技术包括:
- 语音采集与预处理:通过麦克风采集语音信号,进行降噪、分帧、特征提取(MFCC 梅尔频率倒谱系数);
- 机器学习推理:基于 TensorFlow Lite for Microcontrollers(TFLite-Micro)部署轻量级语音识别模型,实现唤醒词检测和命令分类;
- 设备控制:通过继电器 / 蓝牙模块控制灯光、插座、风扇等家居设备;
- 语音反馈:通过扬声器播放预设提示音或简单 TTS(文本转语音)反馈。
2. 机器学习模型设计
- 唤醒词模型:采用轻量级 CNN(卷积神经网络),基于 Google Speech Commands 数据集的自定义唤醒词(如 “小 ESP”)训练,模型大小控制在 50KB 以内,适合 ESP32 内存;
- 命令识别模型:采用 DNN(深度神经网络),识别 10-20 条常用命令(如 “打开灯光”“调高温度”),输入为 MFCC 特征,输出为命令类别概率。
三、硬件选型
| 组件名称 | 型号规格 | 用途说明 | 数量 |
|---|---|---|---|
| 主控模块 | ESP32-S3-WROOM-1 | 高性能版本,支持 I2S 接口、更大 RAM(320KB),适合运行 TFLite 模型 | 1 |
| 语音采集模块 | INMP441(I2S 数字麦克风) | 低噪声、数字输出,支持 I2S 协议,直接与 ESP32 的 I2S 接口通信 | 1 |
| 音频输出模块 | 8Ω 0.5W 扬声器 + LM386 功放 | 播放反馈提示音(如 “已执行”),LM386 用于驱动扬声器 | 1 套 |
| 家居控制模块 | 4 路继电器模块(5V) | 控制灯光、插座等 220V 家电(需注意强电隔离) | 1 |
| 辅助组件 | 按键(用于模型校准)、LED 指示灯、杜邦线、5V 电源 | 手动触发校准、状态指示、供电 | 若干 |
硬件选型说明:
- ESP32-S3:相比基础款 ESP32,增加了硬件浮点运算单元和更大的 SRAM,能更高效运行机器学习模型,且支持 I2S 接口直接连接数字麦克风,减少信号干扰;
- INMP441:数字麦克风避免了模拟信号的噪声干扰,I2S 接口可通过 DMA 方式高速采集语音数据,适合实时处理;
- 继电器模块:需通过光耦隔离强电与 ESP32,避免干扰或损坏主控。
四、硬件接线图
核心接线表(ESP32-S3 引脚 → 模块引脚)
| ESP32-S3 引脚 | 模块名称 | 模块引脚 | 备注说明 |
|---|---|---|---|
| 3.3V | INMP441 | VDD | 麦克风供电(3.3V) |
| GND | INMP441 | GND | 共地 |
| GPIO18(I2S_BCK) | INMP441 | BCK | I2S 时钟线 |
| GPIO17(I2S_WS) | INMP441 | WS | I2S 声道选择线 |
| GPIO16(I2S_DO) | INMP441 | DO | I2S 数据输出线 |
| GPIO4 | LM386 功放 | IN | 音频信号输入(PWM/DAC) |
| 5V | 继电器模块 | VCC | 继电器供电(需独立 5V,避免 ESP32 过载) |
| GND | 继电器模块 | GND | 共地 |
| GPIO21 | 继电器模块 | IN1 | 控制灯光(高电平触发) |
| GPIO22 | 继电器模块 | IN2 | 控制风扇 |
| GPIO2 | 校准按键 | 一端(另一端接 GND) | 长按进入模型校准模式 |
| GPIO13 | 状态 LED(绿) | 阳极(串 220Ω 电阻) | 系统运行正常指示 |
接线示意图(简化)
plaintext
ESP32-S3 INMP441(麦克风) 继电器模块 音频模块
3.3V ──────── VDD ──────── ────────
GND ──────── GND GND GND
GPIO18──────── BCK
GPIO17──────── WS
GPIO16──────── DO
GPIO21──────── IN1(灯光)
GPIO22──────── IN2(风扇)
GPIO4 ──────── LM386输入
5V ──────── 继电器VCC
五、软件设计
1. 开发环境与依赖
- 开发工具:Arduino IDE 2.0+(需安装 ESP32-S3 开发板支持)
- 核心库:
TensorFlowLite_ESP32:TFLite-Micro 在 ESP32 上的移植库,用于模型推理;ESP32_I2S:驱动 I2S 麦克风采集语音数据;SimpleAudioPlayer:通过 PWM 输出音频反馈;PubSubClient(可选):如需远程控制,可通过 MQTT 连接家居网关。
2. 系统流程图
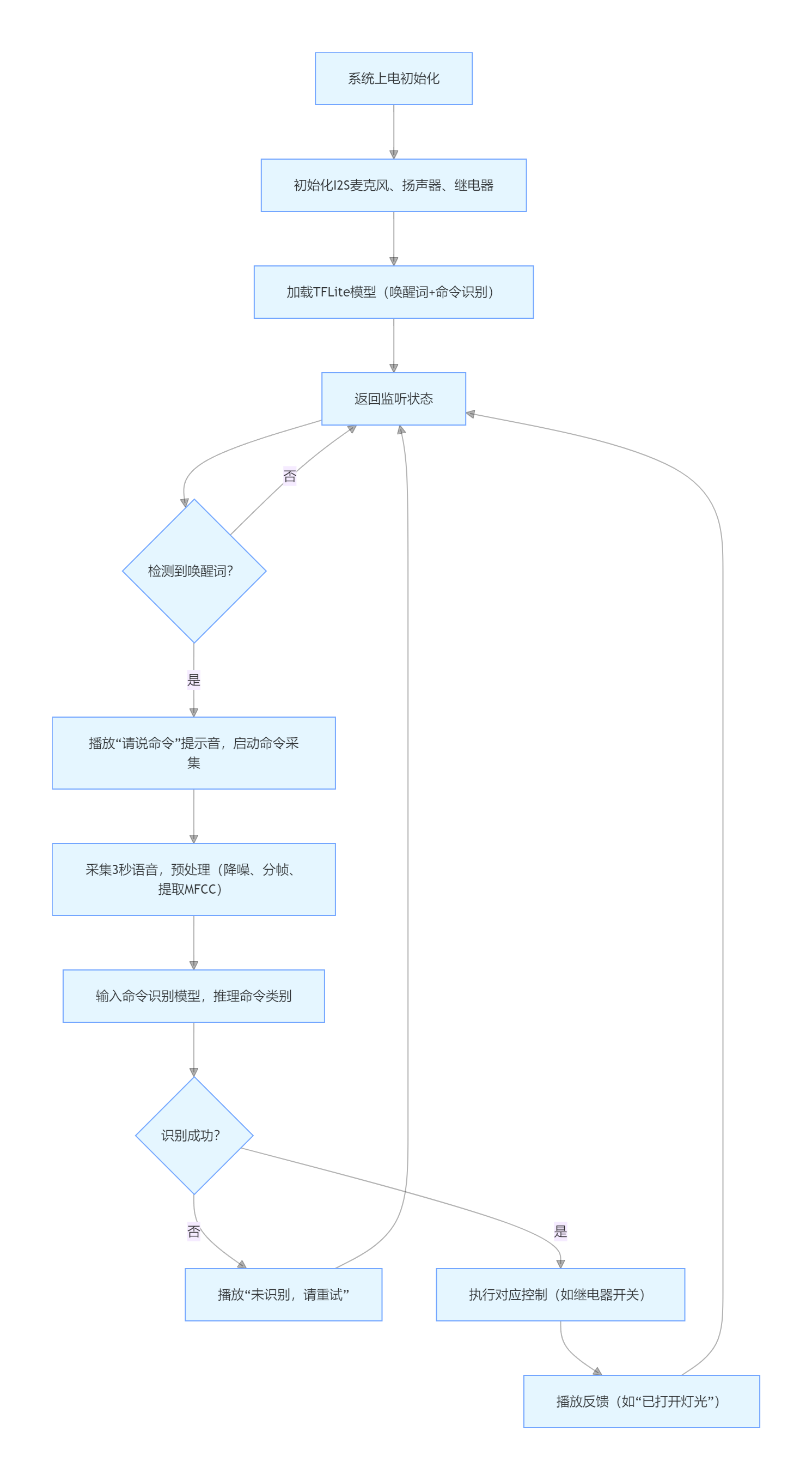
3. 核心代码实现
(1)初始化与模型加载
#include <Arduino.h>
#include <TensorFlowLite.h>
#include "tensorflow/lite/micro/all_ops_resolver.h"
#include "tensorflow/lite/micro/micro_error_reporter.h"
#include "tensorflow/lite/micro/micro_interpreter.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "tensorflow/lite/version.h" // 引入模型(唤醒词模型和命令识别模型,需提前转换为C数组)
#include "wake_word_model.h" // 唤醒词模型(自定义“小ESP”)
#include "command_model.h" // 命令识别模型(10条命令) // I2S麦克风配置
#include <driver/i2s.h>
#define I2S_BCK_PIN 18
#define I2S_WS_PIN 17
#define I2S_DO_PIN 16 // 设备控制引脚
#define RELAY_LIGHT 21 // 灯光继电器
#define RELAY_FAN 22 // 风扇继电器
#define LED_STATUS 13 // 状态指示灯 // TFLite相关变量
tflite::MicroErrorReporter tflite_error_reporter;
tflite::AllOpsResolver tflite_resolver;
const tflite::Model* wake_word_model = nullptr;
tflite::MicroInterpreter* wake_word_interpreter = nullptr;
const tflite::Model* command_model = nullptr;
tflite::MicroInterpreter* command_interpreter = nullptr; // 模型输入输出缓冲区(根据模型输入维度定义)
const int WAKE_WORD_INPUT_SIZE = 490; // 唤醒词模型输入长度(MFCC特征)
float wake_word_input_buffer[WAKE_WORD_INPUT_SIZE];
const int COMMAND_INPUT_SIZE = 980; // 命令模型输入长度
float command_input_buffer[COMMAND_INPUT_SIZE]; void setup() { Serial.begin(115200); pinMode(RELAY_LIGHT, OUTPUT); pinMode(RELAY_FAN, OUTPUT); pinMode(LED_STATUS, OUTPUT); digitalWrite(LED_STATUS, HIGH); // 系统启动完成 // 初始化I2S麦克风 i2s_config_t i2s_config = { .mode = (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_RX), .sample_rate = 16000, // 语音识别常用16kHz采样率 .bits_per_sample = I2S_BITS_PER_SAMPLE_16BIT, .channel_format = I2S_CHANNEL_FMT_ONLY_LEFT, // 单声道 .communication_format = I2S_COMM_FORMAT_STAND_I2S, .intr_alloc_flags = ESP_INTR_FLAG_LEVEL1, .dma_buf_count = 4, .dma_buf_len = 512 }; i2s_pin_config_t pin_config = { .bck_io_num = I2S_BCK_PIN, .ws_io_num = I2S_WS_PIN, .data_out_num = I2S_PIN_NO_CHANGE, // 仅输入,无输出 .data_in_num = I2S_DO_PIN }; i2s_driver_install(I2S_NUM_0, &i2s_config, 0, nullptr); i2s_set_pin(I2S_NUM_0, &pin_config); // 加载唤醒词模型 wake_word_model = tflite::GetModel(wake_word_model_data); // 模型数据来自wake_word_model.h if (wake_word_model->version() != TFLITE_SCHEMA_VERSION) { Serial.println("唤醒词模型版本不匹配!"); while (1); } // 为解释器分配内存(根据模型大小调整) static uint8_t wake_word_tensor_arena[8 * 1024]; // 8KB内存池 wake_word_interpreter = new tflite::MicroInterpreter( wake_word_model, tflite_resolver, wake_word_tensor_arena, sizeof(wake_word_tensor_arena), &tflite_error_reporter ); wake_word_interpreter->AllocateTensors(); // 加载命令识别模型(流程同上) command_model = tflite::GetModel(command_model_data); static uint8_t command_tensor_arena[16 * 1024]; // 16KB内存池 command_interpreter = new tflite::MicroInterpreter( command_model, tflite_resolver, command_tensor_arena, sizeof(command_tensor_arena), &tflite_error_reporter ); command_interpreter->AllocateTensors(); Serial.println("系统初始化完成,等待唤醒词...");
}
(2)语音采集与预处理(MFCC 提取)
// 采样缓冲区(16位PCM数据)
int16_t audio_buffer[1024];
// MFCC特征提取(简化版,实际需实现梅尔滤波器组)
void extractMFCC(int16_t* pcm_data, int pcm_len, float* mfcc_out, int mfcc_len) { // 步骤:1. 预加重(高通滤波);2. 分帧(20ms一帧,16kHz下320点);3. 加窗(汉宁窗); // 4. FFT变换;5. 梅尔滤波;6. 取对数;7. DCT变换得到MFCC特征 // 此处为简化代码,实际需根据语音处理库实现(如使用kissFFT) for (int i = 0; i < mfcc_len; i++) { mfcc_out[i] = (float)pcm_data[i % pcm_len] / 32768.0; // 临时占位,需替换为真实MFCC }
} // 采集唤醒词语音(1秒)并提取MFCC
bool collectWakeWordAudio() { size_t bytes_read; i2s_read(I2S_NUM_0, audio_buffer, sizeof(audio_buffer), &bytes_read, portMAX_DELAY); int samples_read = bytes_read / 2; // 16位数据,字节数/2=样本数 if (samples_read < 16000) { // 16kHz下1秒=16000样本 Serial.println("唤醒词采集数据不足!"); return false; } extractMFCC(audio_buffer, samples_read, wake_word_input_buffer, WAKE_WORD_INPUT_SIZE); return true;
}
(3)机器学习推理与命令执行
// 唤醒词识别(返回是否检测到唤醒词)
bool detectWakeWord() { if (!collectWakeWordAudio()) return false; // 将MFCC特征输入模型 float* input = wake_word_interpreter->input(0)->data.f; memcpy(input, wake_word_input_buffer, WAKE_WORD_INPUT_SIZE * sizeof(float)); // 推理 TfLiteStatus status = wake_word_interpreter->Invoke(); if (status != kTfLiteOk) { Serial.println("唤醒词推理失败!"); return false; } // 输出为“唤醒词”概率(假设输出索引0为唤醒词,1为非唤醒词) float* output = wake_word_interpreter->output(0)->data.f; return (output[0] > 0.8); // 概率>80%认为检测到
} // 命令识别(返回命令ID:0=打开灯光,1=关闭灯光,2=打开风扇...)
int recognizeCommand() { // 采集3秒命令语音(16kHz*3=48000样本) size_t total_samples = 0; while (total_samples < 48000) { size_t bytes_read; i2s_read(I2S_NUM_0, audio_buffer, sizeof(audio_buffer), &bytes_read, portMAX_DELAY); total_samples += bytes_read / 2; } // 提取MFCC特征 extractMFCC(audio_buffer, total_samples, command_input_buffer, COMMAND_INPUT_SIZE); // 输入模型推理 float* input = command_interpreter->input(0)->data.f; memcpy(input, command_input_buffer, COMMAND_INPUT_SIZE * sizeof(float)); TfLiteStatus status = command_interpreter->Invoke(); if (status != kTfLiteOk) { Serial.println("命令推理失败!"); return -1; } // 取概率最大的命令ID float* output = command_interpreter->output(0)->data.f; int max_idx = 0; float max_prob = 0; for (int i = 0; i < 10; i++) { // 假设有10条命令 if (output[i] > max_prob) { max_prob = output[i]; max_idx = i; } } return (max_prob > 0.7) ? max_idx : -1; // 概率>70%认为有效
} // 执行命令
void executeCommand(int cmd_id) { switch(cmd_id) { case 0: // 打开灯光 digitalWrite(RELAY_LIGHT, HIGH); playAudio("打开灯光"); // 播放反馈(需提前录制或TTS生成) break; case 1: // 关闭灯光 digitalWrite(RELAY_LIGHT, LOW); playAudio("关闭灯光"); break; case 2: // 打开风扇 digitalWrite(RELAY_FAN, HIGH); playAudio("打开风扇"); break; case 3: // 关闭风扇 digitalWrite(RELAY_FAN, LOW); playAudio("关闭风扇"); break; default: playAudio("未识别命令"); }
}
(4)主循环
void loop() { // 监听唤醒词 if (detectWakeWord()) { Serial.println("检测到唤醒词!"); digitalWrite(LED_STATUS, LOW); // 状态灯闪烁提示 delay(300); digitalWrite(LED_STATUS, HIGH); playAudio("请说命令"); // 提示用户输入命令 // 识别命令并执行 int cmd = recognizeCommand(); if (cmd != -1) { executeCommand(cmd); } else { playAudio("未听清,请重试"); } Serial.println("返回唤醒词监听..."); } delay(100); // 降低CPU占用
}
六、机器学习模型训练与部署
1. 数据准备
- 唤醒词数据:录制 500 条 “小 ESP” 语音(不同人、不同距离、带环境噪声),以及 5000 条非唤醒词语音(日常对话、背景噪声);
- 命令数据:每条命令(如 “打开灯光”)录制 300 条,覆盖不同口音和语速。
2. 模型训练(基于 TensorFlow)
# 简化的模型训练代码(Python)
import tensorflow as tf
from tensorflow.keras import layers # 唤醒词模型(轻量级CNN)
model = tf.keras.Sequential([ layers.Reshape((49, 10), input_shape=(490,)), # 490=49帧×10维MFCC layers.Conv1D(16, 3, activation='relu'), layers.GlobalMaxPooling1D(), layers.Dense(32, activation='relu'), layers.Dense(2, activation='softmax') # 2类:唤醒词/非唤醒词
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 训练模型(使用准备好的MFCC特征数据)
model.fit(train_x, train_y, epochs=20, validation_data=(val_x, val_y)) # 转换为TFLite-Micro模型
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT] # 量化压缩
tflite_model = converter.convert()
with open('wake_word_model.tflite', 'wb') as f: f.write(tflite_model)
3. 模型部署到 ESP32
- 使用
xxd工具将.tflite模型转换为 C 数组(可被 Arduino 代码引用):bash
xxd -i wake_word_model.tflite > wake_word_model.h - 生成的
wake_word_model.h中包含wake_word_model_data数组,直接在代码中引用(见初始化部分)。
七、系统优化与扩展
1. 性能优化
- 模型轻量化:通过量化(INT8)将模型体积压缩 50% 以上,减少内存占用;
- 推理加速:利用 ESP32-S3 的硬件浮点单元(FPU),或使用 TFLite-Micro 的 CMSIS-NN 优化库;
- 降噪处理:添加自适应滤波算法(如 NLMS)去除环境噪声,提高识别准确率。
2. 功能扩展
- 多设备控制:增加红外发射模块(如 IRremote 库),控制空调、电视等红外设备;
- 蓝牙联动:通过 ESP32 的 BLE 连接智能手环,实现 “靠近自动解锁” 等场景;
- OTA 模型更新:支持通过 WiFi 远程更新语音模型,无需重新烧录固件;
- 自定义命令:通过手机 APP 录制新命令,本地增量训练模型(需简化训练逻辑)。
八、注意事项
- 电源设计:继电器和功放模块需独立 5V 供电,避免 ESP32 电源波动导致语音采集噪声;
- 麦克风安装:远离继电器、电机等电磁干扰源,建议加装海绵防风罩;
- 模型校准:首次使用需在实际环境中校准(长按校准按键,采集背景噪声更新模型阈值);
- 唤醒词误触:通过增加 “双唤醒词”(如 “小 ESP + 确认”)或设置灵敏度调节,减少误触发。
总结
本系统通过 ESP32-S3 的本地计算能力与机器学习结合,实现了脱离云端的智能语音控制,兼顾响应速度与隐私保护。核心难点在于语音预处理优化和轻量级模型设计,需通过大量实际数据训练和调试提升识别稳定性。扩展后可支持多设备联动,成为完整的智能家居控制中枢,适合个人 DIY 或小型场景应用。