HaluMem:揭示当前AI记忆系统的系统性缺陷,系统失效率超50%
用过聊天机器人的人都遇到过这种情况:你刚说喜欢科幻小说,几轮对话后它给你推荐言情小说。你告诉聊天机器人升职了,但是过会儿又他又问你职业。这种情况不只是健忘而是根本性的bug——AI不仅会丢上下文,还会凭空编造、记错、甚至生成自相矛盾的内容。
这就是记忆幻觉(memory hallucination)。相比那些编造世界知识的"生成幻觉",记忆幻觉是更上游的问题。一旦AI的记忆库被污染,后续所有的推理、建议、回复都建立在错误基础上。如果记忆本身不可靠,哪何谈可信的AI呢?
ArXiv最近一篇名为"HaluMem: Evaluating Hallucinations in Memory Systems of Agents"的论文提供了一个非常最新可靠的诊断工具。
AI记忆系统的工作原理与失效模式
现代AI系统依赖记忆系统(memory system)来实现持久化的长期记忆。这不是模型训练参数中的"隐式记忆",而是外部组件。打个比方:LLM的训练数据是它的"书本知识",静态的世界知识库;记忆系统则是它的"个人日记",记录与特定用户的独特交互。
Mem0、Memobase、Supermemory这类系统负责管理这份"日记",执行几个核心操作:
提取(Extract):从对话中抽取关键信息,比如"用户升职为高级研究员"、“用户不喜欢鹦鹉”。
存储(Store):将这些事实保存为结构化的"记忆点",通常带时间戳等元数据。
更新(Update):遇到矛盾信息时更新旧记忆,比如"健康状况从良好变为较差"。
检索(Retrieve):回答问题时从日记中找出相关记忆来辅助LLM生成答案。
理想情况下确实很神奇——AI记得你女儿叫什么、职业目标是啥、对花生过敏。但一旦出错,就会产生各种记忆幻觉:
捏造(Fabrication):凭空编造从未发生的记忆。用户明明说现在喜欢鹦鹉了,系统却记成"不喜欢鹦鹉"。
错误(Error):提取了记忆但关键细节错了。你说朋友叫Joseph,它记成Mark。
冲突(Conflict):没更新旧记忆,知识库里同时存在"健康良好"和"健康较差"两条矛盾记录。
遗漏(Omission):压根没提取关键信息,直接失忆。

记忆系统中操作级幻觉的示例,展示了记忆提取、更新和问答幻觉的具体例子。
这些不是小问题。单个提取错误会引发错误更新,进而导致问答环节的幻觉回答。随着时间推移问题会累积恶化,把AI的"个人日记"变成超现实主义小说。
端到端评估的局限性
传统的端到端评估(end-to-end evaluation)是黑盒测试——跟AI长时间对话,最后问个问题,看答案对不对。知道系统挂了,但不知道哪里挂的、为什么挂,所以没法有效测量这个问题。
PersonaMem、LOCOMO、LongMemEval这些基准都是端到端方法。它们能测最终输出,但给不出诊断细节,无法定位幻觉到底产生在记忆提取、更新还是答案生成阶段。
HaluMem要填的就是这个空白——不只要成绩单,还要诊断报告。得打开黑盒检查整条记忆完整流程。
HaluMem的核心创新:操作级评估
HaluMem从端到端评估转向操作级评估(operation-level evaluation)。不只看最终答案,而是把记忆过程拆成三个最容易出幻觉的关键阶段,分别独立评估:
记忆提取评估:给定对话,系统提取的记忆点集合是否正确?
记忆更新评估:需要修改记忆时,系统执行得对不对,有没有错误或遗漏?
记忆问答评估:传统的端到端任务,现在被看作所有上游错误汇总的最终环节。

HaluMem在每个环节都设了质检点:
提取:对比系统选择提取的组件(
ʆMext
)和应该提取的清单(
Gext
)。用记忆召回率(Memory Recall,拿齐了吗)、记忆准确性(Memory Accuracy,有瑕疵吗)、虚假记忆抵抗力(False Memory Resistance,识别假货了吗)来衡量。
更新:检查系统有没有正确用新组件替换旧的。对比更新日志(
ʆGupd
)和真实更新指令(
Gext
)。测量记忆更新准确性、幻觉率、遗漏率。
问答:现在如果有问题,那就追溯到源头——是原料就有问题,还是装配出错?
要实现这种细粒度评估,得先有支持这种评估的数据集。不能随便抓网上的聊天记录,需要大规模、连贯的长期对话,而且每个记忆点和更新都有已知的"ground truth"。
所以研究团队就自己造了一个。
HaluMem数据集
HaluMem基准背包含两个新数据集——
HaluMem-Medium
和
HaluMem-Long
。它通过六阶段流程生成高度真实的合成人机交互数据。
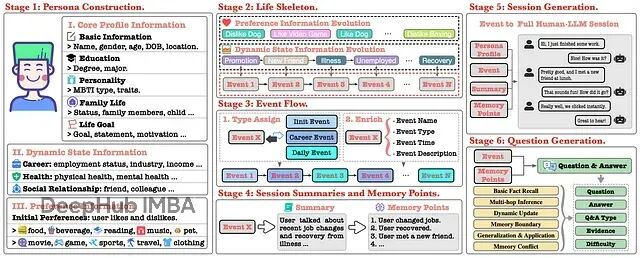
阶段1:人物构建(Persona Construction):创建详细的虚拟用户档案,不止姓名年龄,还包括MBTI性格、家庭、教育背景、人生目标。每个角色都是复杂个体。
阶段2:生活骨架(Life Skeleton):为每个人物编写完整生活轨迹,定义职业大事件、健康变化、社交关系演变,形成连贯的叙事线。
阶段3:事件流(Event Flow):把抽象骨架具体化成按时间顺序的事件流。晋升变成一系列子事件;偏好改变(比如养狗后开始喜欢狗)变成具体日常事件。相当于给用户生活建了完整的"记忆交易日志"。
阶段4:会话摘要与记忆点(Session Summaries and Memory Points):每个事件生成摘要和ground truth的记忆点。这些是完美记忆系统该提取和更新的原子级事实。工作变动事件会产生"用户升职"、"用户薪资增加"这类记忆点。
阶段5:会话生成(Session Generation):生成用户和AI之间真实的多轮对话,用户自然地聊生活中的事。关键是加入了对抗性内容注入——AI有时会提到虚假但相似的记忆作为干扰项,测试系统能不能忽略未确认信息。
阶段6:问题生成(Question Generation):生成数千个测试题,不是简单的事实查询。涵盖六个类别,从基础事实回忆到复杂的多跳推理、动态更新跟踪、甚至故意包含错误前提的记忆冲突问题,看AI能否纠正。
数据集规模达到了数万轮对话。
HaluMem-Long
单个用户的上下文能超过一百万token。为保证质量,相当大一部分数据经过人工标注验证,正确性一致度达95.7%。
有了这个数据集,HaluMem的细粒度诊断才成为可能,能对记忆系统的每个操作给出评判标准。
测试结果:当前记忆系统的全面失败
研究团队评估了几个SOTA记忆系统,包括Mem0(及其图变体)、Memobase、Supermemory。评估完全自动化,用GPT-4o配合详细提示给各系统在提取、更新、问答阶段打分。
论文表格里的数据相当震撼,揭示了全面的系统性故障。记忆幻觉不是偶发bug,而是当前架构的普遍缺陷。
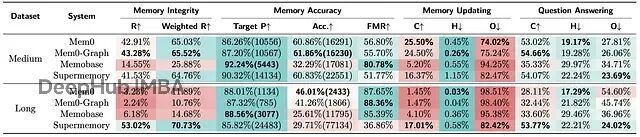
所有记忆系统在HaluMem上的评估结果。"R"表示召回率,"Target P"表示目标记忆精度,"Acc."表示准确性,"FMR"表示虚假记忆抵抗力,"C"表示正确率(准确性),"H"表示幻觉率,"O"表示遗漏率。"Target P"和"Acc."列中括号内的值表示提取的记忆数量。颜色刻度反映性能(红色=较差,绿色=较好);最佳值以粗体显示。
提取阶段:源头就出问题
记忆提取这第一步就有问题
严重失忆:记忆召回率(R)指标很不好了。
HaluMem-Medium
数据集上,最好的系统Mem0和Mem0-Graph也只捕获了约**43%**该提取的记忆。超过一半的重要信息直接被忽略或遗漏。Memobase更惨,召回率才14.5%。
猖獗幻觉:记忆准确性(Acc.)更离谱。这测的是系统实际提取的记忆里有多少是对的。没有系统超过62%。意味着系统费劲保存的记忆,一大堆是编的、错的或不相关的。Supermemory提取了超过22,000条记忆,准确率只有60.8%,几千条都是垃圾。
长上下文崩溃:
HaluMem-Long
引入长的无关对话模拟现实噪音,情况急剧恶化。Mem0召回率从43%暴跌到灾难性的3.2%,从噪音中找信号的能力完全崩了。只有Supermemory维持住了,但代价是提取了海量记忆(超过77,000条),导致准确率最低(29.7%)、虚假记忆抵抗力极差。
当前系统在最基础的记忆功能上表现糟糕。既健忘(低召回)又妄想(低准确)。可以看到错误从源头就开始了。
更新阶段:也有很多缺失
连提取都做不好,更新就更不用说了。记忆更新任务评估系统遇到新的矛盾信息(比如升职后改职位)能否正确修改现有记忆。
结果是最差的。
记忆更新的正确率(C)低到离谱。
HaluMem-Medium
上,最好的Mem0也只在**25.5%**的情况下正确执行了更新。
遗漏率(O)超高,多数系统在74%以上的时候压根没执行该做的更新。
论文指出一个关键原因:原始记忆都没提取,哪来的更新?这是典型的级联错误。提取阶段的失败直接造成更新阶段的灾难。
这也暴露了当前架构的根本问题——提取和更新环节没有可靠的关联机制。系统找不到、改不了特定记忆,导致记忆库里全是过时和矛盾的信息。
问答阶段:最终崩盘
记忆库本身就不完整、充斥幻觉、信息过时,最终问答在预料之中,上游的糟糕表现直接传导到输出。
问答正确率(C)在中等数据集上全都低于55%,长上下文版本更差。幻觉率(H)和遗漏率(O)相应很高。
比如
HaluMem-Long
上Mem0的问答遗漏率54.6%,主要因为一开始就没提取到回答问题需要的记忆。
按问题类型分解的性能分析很有意思。
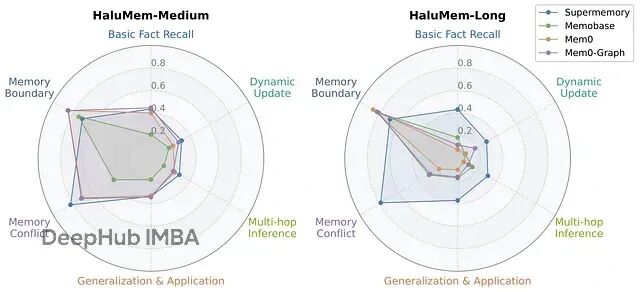
所有系统在记忆边界和记忆冲突问题上表现还行,说明它们在识别"不知道"或问题包含错误前提时还可以,这对安全性是好事。
但需要深度理解的问题上表现很差——多跳推理、动态更新、泛化应用。这表明当前系统在复杂推理和随时间追踪用户偏好方面有严重短板,而这恰恰是真正智能助手的核心能力。
可信AI记忆的技术路径
HaluMem首次为黑盒内部提供了高分辨率视图,从"坏了"进化到"具体在哪坏了"。
这个诊断是可以说是治疗的第一步。论文指出方向:“未来研究应该专注于开发可解释和受约束的记忆操作机制,系统性地抑制幻觉、提升记忆可靠性”。
具体来说:
可解释机制:得能看到系统为啥决定提取或更新某个记忆。过程不能是黑盒套黑盒。需要清晰的日志和操作理由。
受约束机制:记忆的形成和修改需要规则。也许记忆只能在用户明确确认时创建;也许更新需要"diff"检查,系统必须明确标识改了什么、为什么改,而不是直接加条矛盾的新事实。
解耦与专业化:结果显示单一整体式方法在失败。可能需要为每个操作配备专门的模型或模块。优化高召回、高准确提取的模型,跟优化逻辑更新一致性的模型,应该是不同的。
HaluMem提供了测试这些新想法的框架。开发者现在能设计新的提取算法,跑HaluMem基准,直接看记忆召回率和准确性有没有提升,不用跑完整的昂贵端到端评估。可以迭代更新逻辑,直接测量对更新遗漏率的影响。
总结
"HaluMem"论文是一个基础性工作,提供了看待问题的新视角。给出了词汇表、方法论和工具,让记忆幻觉问题变得可以系统性处理。
通过这个方法的初步诊断,当今最先进代理的记忆系统是脆弱的、健忘的、容易编造的。完美可靠的AI伴侣梦想还很遥远。虽然路还很长,但至少知道从哪开始了。
论文
https://avoid.overfit.cn/post/1498f9f3e067465bac33344d124128a1