显存占用、kvcache和并发学习笔记
1、训练过程中显存占用量计算
🧠 一、显存占用的主要组成部分
训练一个大模型时,显存消耗主要由 4 大部分 构成:
| 类别 | 内容 | 是否可优化 | 说明 |
|---|---|---|---|
| 1️⃣ 模型参数 (Parameters) | 模型权重,如每层的 W, b 等 | ❌ 一般固定 | 占用大小 = 参数总数 × 每个参数字节数(例如 fp16 = 2 字节) |
| 2️⃣ 优化器状态 (Optimizer States) | Adam 等优化器维护的 m, v 向量 | ✅ 可通过优化器选择或零优化减少 | 一般为参数量的 2~3 倍 |
| 3️⃣ 激活值 (Activations) | 前向传播过程中中间层输出,用于反向传播 | ✅ 可通过梯度检查点减少 | 随 batch size 和层数线性增长 |
| 4️⃣ 其他开销 (Misc.) | 临时 buffer、梯度通信、CUDA kernel 缓冲区等 | ✅ 框架依赖 | 通常占几百 MB ~ 数 GB |
🧩 二、显存占用的近似计算公式
✅ 通用近似公式(以 Adam 优化器、fp16 训练为例):
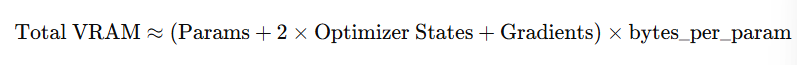
拆开理解:
| 组成部分 | 近似显存占用 |
|---|---|
| 模型参数 | ( |
| 梯度 | ( |
| 优化器状态(Adam: 2 组) | ( 2 × |
| 激活值 | 取决于 batch size、网络深度和输入尺寸,通常比参数多 3~10 倍 |
| 其他 | 约 0.5 ~ 2 GB |
其中:
(
):参数数量
( s ):每个参数的字节数(fp32=4,fp16=2,bf16=2,int8≈1)
🔢 举例计算:BERT-Base(110M 参数)
| 条件 | 数值 |
|---|---|
| 参数量 ( N_p ) | 110M |
| 精度 | fp16(2字节) |
| 优化器 | Adam |
| batch size | 32 |
计算:
✅ 实测:BERT-Base 在 fp16 下 batch=32,显存约 2GB,非常接近。
🔬 三、如何精确估算显存(实践方法)
1️⃣ 静态分析法
适用于 PyTorch:
from torchinfo import summary
summary(model, input_size=(batch, seq_len, hidden_dim))
可看到:
参数量
每层激活 tensor 尺寸
并估算显存消耗。
2️⃣ 动态测量法
通过运行时统计:
import torch
torch.cuda.reset_peak_memory_stats()
# 前向 + 反向
torch.cuda.max_memory_allocated() / 1024**3 # GB
⚙️ 四、显存优化手段与影响
| 技术 | 原理 | 显存节省率 |
|---|---|---|
| FP16 / BF16 训练 | 每参数 2 字节 | 50% |
| Gradient Checkpointing | 不存中间激活,反向时重算 | 30~60% |
| ZeRO (DeepSpeed) | 分布式拆分参数/优化器状态 | 60~90% |
| FlashAttention | 优化 Attention 激活内存 | 20~30% |
| Offload / CPU+GPU 混合训练 | 将部分参数放 CPU | 50%+(速度变慢) |
📊 五、总结表
| 模块 | 典型占比 | 是否随 batch size 增长 |
|---|---|---|
| 参数权重 | 10–20% | ❌ |
| 梯度 | 10–20% | ❌ |
| 优化器状态 | 20–40% | ❌ |
| 激活值 | 30–60% | ✅ |
| 其他 | 5–10% | ✅ |
2、推理过程中显存占用量计算
🧠 一、推理阶段显存占用的主要组成部分
在推理(inference)过程中,显存主要由以下部分构成:
| 类别 | 内容 | 是否随 batch size 增长 | 说明 |
|---|---|---|---|
| 1️⃣ 模型参数 (Weights) | 模型的所有权重 | ❌ 固定 | 占用 = 参数量 × 每参数字节数 |
| 2️⃣ 激活值 (Activations) | 每层前向传播中产生的中间张量 | ✅ | 一般为数层临时存储 |
| 3️⃣ 输入与输出 (Inputs / Outputs) | 输入张量、输出 token、缓存结果 | ✅ | 随 batch size 和序列长度变化 |
| 4️⃣ KV Cache(仅自回归模型) | Transformer 解码器缓存注意力键值对 | ✅ | 线性增长,推理时占大头 |
| 5️⃣ 其他开销 | 临时计算 buffer、CUDA 内核缓存 | ✅ | 一般为几百 MB 到几 GB |
🧩 二、推理显存的近似计算公式
✅ 通用估算公式:
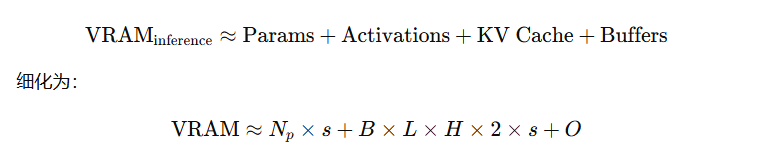 :
:
| 符号 | 含义 |
|---|---|
| ( | 模型参数数量 |
| ( s ) | 每个参数字节数(fp16=2,fp32=4,int8≈1) |
| ( B ) | batch size |
| ( L ) | 序列长度(上下文长度) |
| ( H ) | 隐层维度(hidden size) |
| ( 2 × s ) | 因为 KV Cache 需要同时存储 Key 和 Value |
| ( O ) | 其他缓冲区(一般 0.5~2 GB) |
📊 三、各部分显存占用比例(推理时)
| 部分 | 是否持久驻留 | 占比 |
|---|---|---|
| 模型参数 | ✅ | 60–90% |
| KV Cache | ✅(随着上下文积累) | 10–30% |
| 激活值 | ❌(逐层释放) | 5–10% |
| 输入输出 buffer | ❌ | 1–5% |
🔢 四、举几个具体例子
🌰 例 1:BERT-base (110M 参数) 推理
条件:
参数量:110M
精度:fp16(2 字节)
batch = 1,序列长度 = 128
计算:
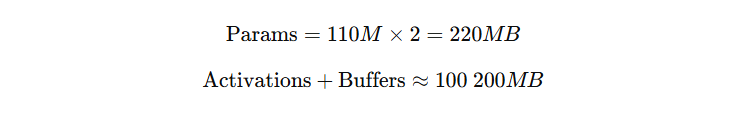
👉 总显存 ≈ 0.4~0.5 GB
✅ 实测:BERT-base fp16 推理时显存约 0.5GB。
🌰 例 2:LLaMA-7B 推理(Transformer decoder-only)
参数量:7B
精度:fp16 (2 bytes)
上下文长度:2048
hidden size = 4096
batch size = 1

总显存 ≈ 14 + 2 + 2 = 18 GB
✅ 所以 LLaMA-7B 推理时至少需要 18GB 显存。
(如果用量化,例如 INT4,可降到 7–8GB)
🧮 五、如何更精确地测量(PyTorch 实战)
import torch
from transformers import AutoModelForCausalLM, AutoTokenizermodel = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", torch_dtype=torch.float16, device_map="cuda")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")inputs = tokenizer("Hello world!", return_tensors="pt").to("cuda")torch.cuda.reset_peak_memory_stats()
outputs = model.generate(**inputs, max_new_tokens=50)
print(torch.cuda.max_memory_allocated() / 1024**3, "GB")
这会打印模型推理时的峰值显存占用。
⚙️ 六、推理显存优化手段
| 技术 | 原理 | 显存节省率 | 说明 |
|---|---|---|---|
| INT8 / INT4 量化 | 参数存储为 8/4 bit | 50–75% | Hugging Face bitsandbytes 常用 |
| KV Cache 压缩 | 用 FP8 或半精度存 KV | 20–40% | FlashAttention2 等支持 |
| 分批推理 (batch=1) | 减少激活与 KV cache | 10–90% | 常用于长文本生成 |
| 层级 offload (CPU / NVMe) | 将部分层暂存在 CPU 或磁盘 | 50–80% | 适合大模型如 70B |
| Streaming KV Cache | 丢弃过久上下文 | 20–60% | 常用于连续生成场景 |
| Tensor Parallel / Model Parallel | 多 GPU 分担参数 | 可线性扩展 | DeepSpeed、Megatron 支持 |
🧩 七、总结对比:训练 vs 推理 显存构成
| 项目 | 训练 | 推理 |
|---|---|---|
| 模型参数 | ✅(梯度+优化器) | ✅(仅参数) |
| 激活值 | ✅(大量保存) | ✅(少量、可复用) |
| 优化器状态 | ✅ | ❌ |
| KV Cache | ❌ | ✅(生成模型特有) |
| 可优化点 | 混合精度、ZeRO | 量化、KV Cache 压缩 |
| 显存主导因素 | 激活值 | 参数 + KV Cache |
✅ 一句总结:
推理显存 ≈ 模型参数 + KV Cache + 少量激活和缓冲区
参数部分固定,KV Cache 随上下文长度线性增长。
3、KV Cache如何计算
🧠 一、KV Cache 是什么?
在 Transformer 的 自回归推理 中(即逐 token 生成的模式),每次生成一个新 token,模型需要计算当前 token 与历史所有 token 的注意力(Attention)。
如果每次都重新计算历史 token 的 Key 和 Value,会非常浪费时间。
所以我们在推理时引入缓存机制:
KV Cache:存储每层的 Key 和 Value 张量,以便下一个 token 复用。
每次生成新 token:
只计算新的 Key/Value
将它们拼接(append)到缓存中
🧩 二、KV Cache 的张量形状(核心)
对一个 Transformer 层来说,注意力机制的 Key 和 Value 张量形状为:
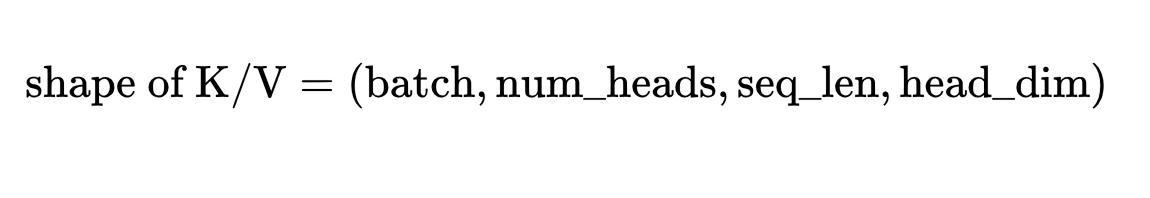
其中:
batch:一次推理的样本数量num_heads:多头注意力的头数(例如 32、40、64)seq_len:上下文长度(包括已生成的 token 数)head_dim:每个注意力头的维度(通常为 hidden_size / num_heads)
注意:每层都会存一份 K 和 V(两份数据),并且每个都需要相同显存。
💾 三、KV Cache 显存计算公式
每层的 KV Cache 占用为:
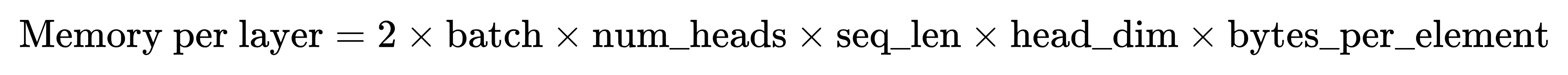
乘以 2:因为要同时缓存 Key 和 Value
bytes_per_element:取决于精度(fp16=2,fp32=4,int8=1)
总的 KV Cache 占用为:

🔢 四、举个具体例子:LLaMA-7B
| 参数 | 数值 |
|---|---|
| 模型层数(num_layers) | 32 |
| 隐层维度(hidden_size) | 4096 |
| 注意力头数(num_heads) | 32 |
| 每头维度(head_dim) | 4096 / 32 = 128 |
| batch size | 1 |
| 序列长度(seq_len) | 2048 |
| 精度 | FP16(2 bytes) |
1️⃣ 单层 KV Cache 占用:
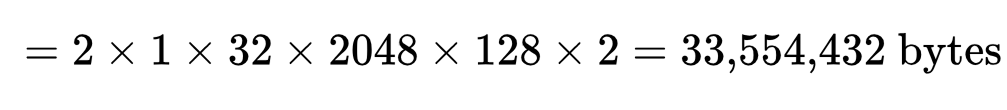
≈ 32 MB
2️⃣ 全模型 32 层:

✅ 总 KV Cache ≈ 1 GB
如果 seq_len = 4096,则占用翻倍 ≈ 2 GB。
如果 batch size = 4,则再乘 4 → 8 GB。
所以 KV Cache 占用 ∝ batch × seq_len × hidden_size × num_layers。
⚙️ 五、对比不同模型的 KV Cache 占用
| 模型 | 层数 | hidden_size | heads | seq_len | 精度 | KV Cache |
|---|---|---|---|---|---|---|
| BERT-base | 12 | 768 | 12 | 512 | fp16 | 24 MB |
| LLaMA-7B | 32 | 4096 | 32 | 2048 | fp16 | 1.0 GB |
| LLaMA-13B | 40 | 5120 | 40 | 2048 | fp16 | 1.6 GB |
| LLaMA-70B | 80 | 8192 | 64 | 4096 | fp16 | 10+ GB |
🚨 注意:每翻倍 上下文长度(seq_len)或 batch size,KV Cache 显存也线性翻倍!
🔍 六、为什么 KV Cache 会越来越占显存?
在自回归生成(如对话、写作)中,每生成一个新 token,就要在缓存中 追加 一个新的 (K,V):
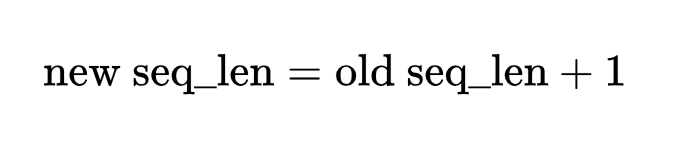
所以:
生成越长的文本,占用显存越多
batch 越大,占用显存越多
hidden_size 越高,占用显存越多
🧠 七、优化 KV Cache 显存的常见技术
| 优化方法 | 原理 | 效果 | 代表实现 |
|---|---|---|---|
| FP8 / INT8 KV Cache | 缓存时用低精度存储 | 约节省 50% | FlashAttention2、DeepSpeed-Inference |
| KV Cache Sharding | 在多 GPU 之间分片存储 KV | 水平扩展 | Tensor Parallel |
| Streaming KV Cache | 丢弃部分历史 token | 线性降低 | StreamingLLM、vLLM |
| Dynamic KV Pruning | 仅保留重要 token 的 Key/Value | 20–40% 降低 | LongLLM |
| CPU / NVMe Offload | 把旧 KV 移出 GPU 显存 | 大幅降低显存,牺牲速度 | DeepSpeed-Inference |
| Paged Attention (vLLM) | 用分页内存管理 KV | 显存碎片率更低 | vLLM 开源实现 |
📘 八、总结
| 项目 | 影响因素 | 增长关系 | 可优化性 |
|---|---|---|---|
| KV Cache 显存 | batch × seq_len × hidden_size × num_layers × bytes_per_elem × 2 | 线性增长 | ✅ 可压缩/分片/流式 |
一句话总结:
它是推理阶段显存增长的主要来源,尤其在长上下文或批量生成时。
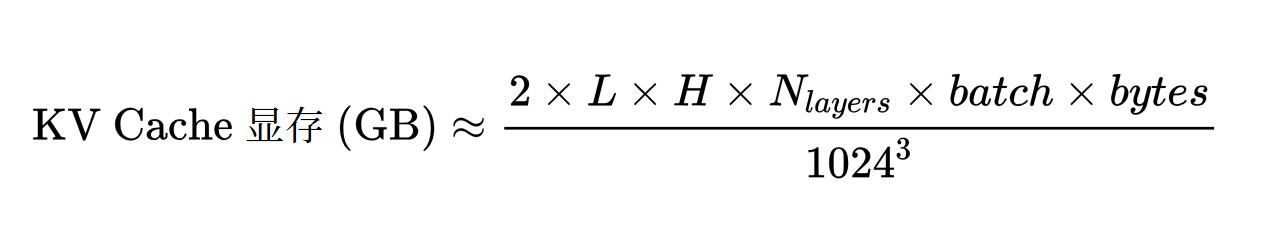
4、LLM并发支持估算
🧠 一、什么是“并发数”
在大模型推理中,“并发数”有两种常见含义:
| 名称 | 含义 | 示例 |
|---|---|---|
| 并发请求数(Request Concurrency) | 同时处理的不同用户请求数量(每个用户一条生成流) | 例如同一时间 10 个人发消息 |
| Batch Size 并发(Batch Concurrency) | 在一次推理中同时生成多个样本(通过批处理) | 例如一次 forward 处理 4 个样本 |
两者的关系:
总并发数 ≈ GPU 显存能容纳的最大 batch size × 每秒处理请求数
🧩 二、显存消耗与并发的关系

💾 三、逐项拆解估算公式
1️⃣ 模型参数占用
固定值,与并发无关:
![]()
例如 LLaMA-7B,FP16 占用 ≈ 14GB。
2️⃣ 每个请求的 KV Cache 占用
来自上一节公式:
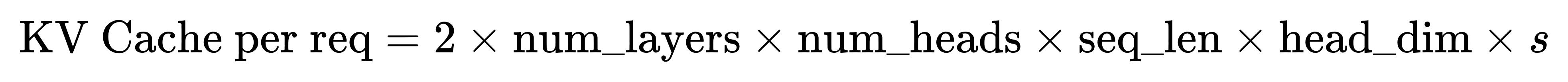
举个例子(LLaMA-7B,FP16,seq_len=2048):
→ 每请求 KV Cache ≈ 1GB
🔢 四、实例计算:LLaMA-7B 在 24GB 显存上推理
| 项目 | 值 |
|---|---|
| 模型参数(fp16) | 14GB |
| 每请求 KV Cache(seq_len=2048) | 1GB |
| 其他开销 | 2GB |
| GPU 总显存 | 24GB |

✅ 即:理论上可同时处理 8 个请求(batch=8)。
实际上考虑到 fragment 和 runtime buffer,稳定并发通常为理论值的 60%–80%,
所以实际安全并发 ≈ 5~6。
📊 五、不同模型的并发估算参考表(FP16)
| 模型 | 参数量 | 单请求 KV Cache(2048 tokens) | 24GB 显存下最大并发 | 备注 |
|---|---|---|---|---|
| BERT-base | 110M | 0.02 GB | ≈ 400 | 无自回归生成 |
| LLaMA-7B | 7B | 1.0 GB | ≈ 5–8 | 常见单卡上限 |
| LLaMA-13B | 13B | 1.6 GB | ≈ 2–3 | 需要量化或 offload |
| Qwen-14B | 14B | 1.7 GB | ≈ 2 | 同级别显存需求 |
| LLaMA-70B | 70B | 8–10 GB | 0.5 | 多卡推理必需 |
⚙️ 六、如何提升并发能力
| 方法 | 原理 | 提升幅度 | 实际应用 |
|---|---|---|---|
| 量化 (INT8 / INT4) | 降低参数精度 | 参数显存 -50~75% | bitsandbytes / AWQ |
| KV Cache 压缩 (FP8) | 降低缓存精度 | KV Cache -40~50% | FlashAttention2 / vLLM |
| Paged Attention (vLLM) | 动态分配 KV 内存 | 显存碎片率 -50% | vLLM / TensorRT-LLM |
| Streaming KV Cache | 丢弃历史缓存 | 长对话显存线性下降 | StreamingLLM |
| Pipeline Parallel / ZeRO | 多 GPU 分担参数 | 几乎线性扩展 | DeepSpeed-Inference |
| Batching 请求 | 动态批处理请求 | 提升吞吐率 | vLLM、TGI、TensorRT |
🧮 七、实战经验公式(快速估算)

(单位:GB)
举例:
GPU:24GB
模型:14GB
每请求占 1.5GB
→ 并发 ≈ (24 - 14)/1.5 = 6.6 ≈ 6个并发请求
✅ 八、总结
| 部分 | 是否随并发增加 | 显存影响 |
|---|---|---|
| 模型权重 | ❌ 固定 | 恒定部分 |
| KV Cache | ✅ 线性增长 | 主导因素 |
| 激活与输入 | ✅ 线性增长 | 次要因素 |
| 总显存 | ≈ 参数 + 并发 × (KV Cache + buffer) |
💡 一句话总结:
并发上限主要取决于:
