(Arxiv-2025)BINDWEAVE:通过跨模态整合实现主体一致性的视频生成
BINDWEAVE:通过跨模态整合实现主体一致性的视频生成
paper是USTC发布在Arxiv 2025
paper title:BINDWEAVE: SUBJECT-CONSISTENT VIDEO GENERATION VIA CROSS-MODAL INTEGRATION
Code:https://github.com/bytedance/BindWeave

图1:我们提出的BindWeave在主体到视频生成中的示例结果,展示了其在从单主体输入到复杂多主体组合等广泛场景下生成高保真、主体一致性视频的能力。
ABSTRACT
扩散Transformer在生成高保真视频方面表现出显著能力,能够在较长时间范围内生成视觉连贯、细节丰富的帧。然而,现有的视频生成模型在主体一致性视频生成方面仍存在不足,原因在于难以准确解析涉及复杂空间关系、时间逻辑以及多主体交互的提示词。为解决这一问题,我们提出了BindWeave,一个统一的框架,能够处理从单主体到复杂多主体、异质实体场景的广泛S2V任务。为将复杂的提示语义与具体视觉主体绑定,我们引入了MLLM-DiT框架。在该框架中,预训练的多模态大语言模型(MLLM)执行深层跨模态推理,以实现实体对齐与角色、属性、交互的解耦,从而生成主体感知的隐状态,用以调控扩散Transformer,实现高保真、主体一致性的视频生成。在OpenS2V基准上的实验结果表明,我们的方法在主体一致性、自然性以及文本相关性方面均取得了显著优于现有开源与商业模型的性能。
1 INTRODUCTION
扩散模型的最新进展(Ho et al., 2020;Peebles & Xie, 2023;Wang et al., 2025)已推动视频生成领域取得显著突破(Wan et al., 2025;Yang et al., 2024;Hu et al., 2025;Kong et al.;Polyak et al., 2024;Zheng et al., 2024),在从文本到视频(T2V)(HaCohen et al., 2024;Wan et al., 2025;Chen et al., 2025a)到图像到视频(I2V)(Blattmann et al., 2023;Mao et al., 2025)等多种任务上均表现优异。基础模型如Wan(Wan et al., 2025)与HunyuanVideo(Kong et al.)已能够生成高保真、长时长、内容丰富的视频,展现了巨大的技术潜力。
然而,尽管在视觉质量上取得了显著进步,这些模型在实际应用中仍受限于可控性不足。具体而言,当前模型难以对视频中的关键元素(如特定人物身份、物体外观或品牌标识)进行精确而稳定的控制。这种缺乏可控性的问题成为阻碍其在个性化内容创作、品牌营销、前期可视化以及虚拟试穿等定制化应用中落地的核心瓶颈。
为应对上述挑战,主体到视频(S2V)(Liu et al., 2025)逐渐引起广泛关注。S2V的核心目标是在整个动态序列中,使视频中的一个或多个主体在身份与外观上与给定参考图像保持高度一致。这一能力直接弥补了现有通用模型的可控性缺陷,使得基于用户提供的主体生成定制视频成为可能。
为实现主体一致性视频生成,一些现有工作(Yuan et al., 2024b;Chen et al., 2025b;Huang et al., 2025;Liu et al., 2025;Jiang et al., 2025)扩展了视频基础模型,使其能够接受多张参考图像作为条件输入。例如,Phantom(Liu et al., 2025)采用双分支架构分别处理文本提示与参考图像,并将得到的特征注入扩散Transformer(DiT)(Peebles & Xie, 2023)的注意力层中作为条件;VACE(Jiang et al., 2025)设计了视频条件单元,将多模态输入(文本、图像/视频参考、掩码)统一为一致格式,并通过残差块注入上下文信号以引导视频生成。
尽管这些方法取得了令人鼓舞的结果,但它们普遍存在一个共同局限:依赖于“分离-再融合”的浅层信息处理范式。具体而言,这些模型通常使用独立编码器分别提取图像与文本特征,然后通过简单的拼接或交叉注意力机制进行后期融合。虽然该机制在仅涉及外观保持的简单指令下表现尚可,但在面对包含复杂交互、空间关系与时间逻辑的文本提示时,其理解与推理能力明显不足。由于缺乏多模态输入间的深层语义关联,模型往往难以准确解析指令,导致身份混淆、动作错位或属性混合等问题。
为突破这一瓶颈,我们提出了BindWeave——一种为主体一致性视频生成而设计的新框架。为建立深层跨模态语义关联,BindWeave引入多模态大语言模型(MLLM)作为智能指令解析器,以取代传统的浅层融合机制。具体而言,我们首先将参考图像与文本提示构造成一个统一的交织序列。该序列随后由预训练的MLLM处理,以解析复杂的时空关系,并将文本命令与相应的视觉实体绑定。通过这一过程,MLLM生成一组隐状态,这些隐状态编码了各主体的精确身份及其指定交互。这些隐状态作为条件输入传递至生成器,将高层语义解析与基于扩散的生成过程相结合。
此外,为提供基于主体的语义锚点并进一步减少身份漂移,我们还引入了来自参考图像的CLIP(Radford et al., 2021b)特征。因此,我们基于DiT(Peebles & Xie, 2023)的生成器在训练中同时受到MLLM隐状态与CLIP特征的联合约束,从而实现全面的关系与语义引导。为保留细粒度外观细节,我们在扩散过程中引入来自参考图像的VAE(Esser et al., 2021)特征以增强视频潜变量。这种集成高层推理、语义身份与低层细节的多重条件机制确保了生成视频在保真度与一致性方面的卓越表现。
我们在细粒度OpenS2V基准(Yuan et al., 2025)上对BindWeave进行了全面评估,涵盖多种现有方法,包括领先的开源与商业模型。评估指标涉及主体一致性、时间自然性以及文本-视频对齐。大量实验结果表明,BindWeave在主体一致性视频生成方面取得了当前最先进(SOTA)的性能,稳定超越所有竞争方法。定性结果(见图1)进一步展示了生成样本的高质量。这些发现突显了BindWeave在主体一致性视频生成中的有效性及其在科研与商业应用中的巨大潜力。
2 RELATED WORK
2.1 VIDEO GENERATION MODEL
扩散模型推动了视频生成领域的显著进步。早期的方法(Singer et al., 2022;Blattmann et al., 2023;Guo et al., 2023)通常通过引入时间建模模块,将文本到图像模型(Rombach et al., 2022)扩展到视频生成任务中。最近,受其出色的可扩展性启发,扩散Transformer(DiT)(Peebles & Xie, 2023)架构催生了新一代模型,如Wan(Wan et al., 2025)、HunyuanVideo(Kong et al., 2024a)和Goku(Chen et al., 2025a)。然而,这些模型主要聚焦于通用视频生成,在实现精细化控制方面仍有相当大的提升空间。
2.2 SUBJECT-CONSISTENT VIDEO GENERATION
为实现更精细的控制,主体一致性视频生成受到了广泛关注。早期方法通常依赖于每个主体的单独优化,即在特定主体的图像上微调预训练模型,如CustomVideo(Wang et al., 2024)和DisenStudio(Chen et al., 2024)。虽然这种实例特定的微调能够取得良好效果,但计算开销较大,不利于实时应用。近期的研究趋势转向端到端方法,这类方法在推理过程中通过条件网络或适配器注入身份信息,从而实现对新主体的泛化,无需重新训练。例如,IDAnimator(He et al., 2024)和ConsisID(Yuan et al., 2024a)等模型最初专注于保持面部身份一致性。随后,这一能力被扩展到任意物体和多主体场景中,如ConceptMaster(Huang et al., 2025)、SkyReels-A2(Fei et al., 2025)、Phantom(Liu et al., 2025)以及VACE(Jiang et al., 2025)。尽管取得了进展,但仍存在显著挑战,尤其是在多主体场景中保持身份区分和建模复杂交互关系方面。
3 METHOD
3.1 PRELIMINARIES
基于扩散Transformer的文本到视频生成模型。基于Transformer的文本到视频扩散模型在视频内容生成方面展现出巨大潜力。我们的BindWeave模型建立在基于Transformer的潜扩散架构之上,结合变分自编码器(VAE)(Wan et al., 2025),将视频从像素层面映射到紧凑的潜空间中,在该空间内进行生成过程。每个Transformer块包含时空自注意力、文本交叉注意力、时间条件MLP以及前馈网络(FFN)。交叉注意力以文本提示ctextc_{text}ctext为条件,该提示由T5编码器ET5\mathcal{E}_{T5}ET5(Raffel et al., 2020)获得。我们采用Rectified Flow(Liu et al., 2022;Esser et al., 2024)来定义扩散动态,使得可以通过常微分方程(ODE)实现稳定训练,同时保持与最大似然目标的等价性。在训练的前向过程中,将随机噪声加入干净数据z0z_0z0以生成zt=(1−t)z0+tϵz_t = (1-t)z_0 + t\epsilonzt=(1−t)z0+tϵ,其中ϵ\epsilonϵ从标准正态分布N(0,I)\mathcal{N}(0, I)N(0,I)中采样,时间系数ttt从区间[0,1][0,1][0,1]中采样。因此,学习目标包括估计真实速度场vt=dztdt=ϵ−z0v_t = \frac{dz_t}{dt} = \epsilon - z_0vt=dtdzt=ϵ−z0。网络uΘu_\ThetauΘ通过Flow Matching损失(Esser et al., 2024)进行训练:
L=Et,z0,ϵ,ctext∥uΘ(zt,t,ctext)−vt∥22. \mathcal{L} = \mathbb{E}_{t, z_0, \epsilon, c_{text}} \|u_\Theta(z_t, t, c_{text}) - v_t\|_2^2. L=Et,z0,ϵ,ctext∥uΘ(zt,t,ctext)−vt∥22.
视频生成中的图像条件。自然语言提供了便捷的扩散视频合成接口,但往往对主体身份与空间布局描述不足。这促使我们在文本到视频生成流程中引入参考图像,以锚定外观与几何特征(Wan et al., 2025;Kong et al., 2024b)。例如,Wan(Wan et al., 2025)在输入层中注入图像信息,用于细粒度空间控制与语义引导。
首先,为了保留精确外观,参考图像IimgI_{img}Iimg通过VAE编码为空间潜变量zimgz_{img}zimg。该潜变量在通道维度上与当前视频噪声潜变量xtx_txt拼接,得到的组合潜变量经过分块嵌入与线性投影形成DiT块的初始token序列:
Hin=PatchEmbed(concatc(xt,zimg)). H_{in} = \text{PatchEmbed}(\text{concat}_c(x_t, z_{img})). Hin=PatchEmbed(concatc(xt,zimg)).
随后,通过交叉注意力机制注入多模态条件以实现语义引导。预训练视觉编码器EvisionE_{vision}Evision(如CLIP)将IimgI_{img}Iimg处理为语义tokenHimgH_{img}Himg,而文本编码器提供文本tokenHtxtH_{txt}Htxt。在每个交叉注意力层中,查询(Q)来自视频token(记作HvidH_{vid}Hvid,在第一层中Hvid=HinH_{vid} = H_{in}Hvid=Hin)。查询、键和值矩阵通过专用线性投影层(ΦQ,ΦK,ΦV)(\Phi_Q, \Phi_K, \Phi_V)(ΦQ,ΦK,ΦV)计算:
Qvid=ΦQ(Hvid),Kimg=ΦK(Himg),Vimg=ΦV(Himg), Q_{vid} = \Phi_Q(H_{vid}), \quad K_{img} = \Phi_K(H_{img}), \quad V_{img} = \Phi_V(H_{img}), Qvid=ΦQ(Hvid),Kimg=ΦK(Himg),Vimg=ΦV(Himg),
文本流中的KtxtK_{txt}Ktxt与VtxtV_{txt}Vtxt以相同方式获得。注意力层输出通过标准缩放点积注意力算子Attn(·)融合多源信息:
Hout=Hvid+Attn(Qvid,Ktxt,Vtxt)+γ Attn(Qvid,Kimg,Vimg), H_{out} = H_{vid} + \text{Attn}(Q_{vid}, K_{txt}, V_{txt}) + \gamma \, \text{Attn}(Q_{vid}, K_{img}, V_{img}), Hout=Hvid+Attn(Qvid,Ktxt,Vtxt)+γAttn(Qvid,Kimg,Vimg),
其中γ\gammaγ为平衡图像与文本引导的标量。
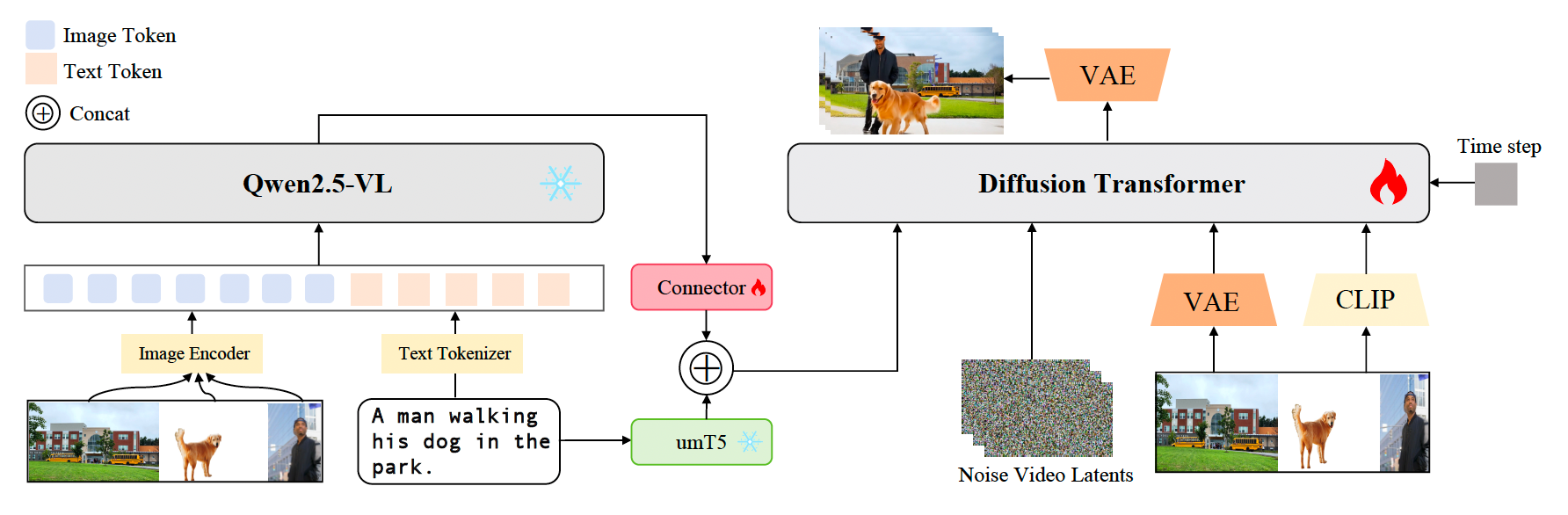
图2:我们方法的框架。一个多模态大语言模型执行跨模态推理,从文本提示和可选的参考图像中进行实体定位,并解耦角色、属性与交互。生成的主体感知信号通过交叉注意力和轻量级适配器作用于扩散Transformer,从而引导生成在身份一致、关系协调和时间连贯性方面均表现出高保真度的视频。
3.2 ARCHITECTURE
我们提出的BindWeave旨在克服主体一致性视频生成中浅层融合范式的局限性。我们方法的核心原则是在生成过程开始之前,用对多模态输入的深层推理理解取代浅层、事后融合。为此,BindWeave首先利用多模态大语言模型(MLLM)作为智能指令解析器。该MLLM生成一个指导性结构,以一系列隐藏状态的形式体现,编码复杂的跨模态语义和时空逻辑,并在整个合成过程中精确地引导扩散Transformer(DiT)。图2展示了BindWeave架构的示意图。
3.3 INTELLIGENT INSTRUCTION PLANNING VIA MLLM
为了有效促进文本提示与参考图像之间的联合跨模态学习,我们引入了一种统一的多模态解析策略。给定一个文本提示T\mathcal{T}T和KKK个用户指定的主体,每个主体都有对应的参考图像IkI_kIk,我们通过在文本提示后附加每个参考图像的占位符来构建一个多模态序列X\mathcal{X}X:
X=[T,⟨img⟩1,⟨img⟩2,…,⟨img⟩K],
\mathcal{X} = [\mathcal{T}, \langle \text{img} \rangle_1, \langle \text{img} \rangle_2, \ldots, \langle \text{img} \rangle_K],
X=[T,⟨img⟩1,⟨img⟩2,…,⟨img⟩K],
I=[I1,I2,…,IK],
\mathcal{I} = [I_1, I_2, \ldots, I_K],
I=[I1,I2,…,IK],
其中⟨img⟩k\langle \text{img} \rangle_k⟨img⟩k是一个特殊的占位符标记,MLLM会在内部将其与第kkk个图像IkI_kIk进行对齐。这种统一的表示方式保留了文本描述与其对应视觉主体之间的重要上下文联系。随后,该序列被输入至预训练的多模态大语言模型(MLLM)。通过处理多模态输入(X,I)(\mathcal{X}, \mathcal{I})(X,I),MLLM生成一系列隐藏状态HmllmH_{mllm}Hmllm,这些隐藏状态体现了对场景的高层语义推理,有效地将文本指令与其具体的视觉身份绑定:
Hmllm=MLLM(X,I). H_{mllm} = \text{MLLM}(\mathcal{X}, \mathcal{I}). Hmllm=MLLM(X,I).
为了对齐冻结的MLLM与我们的扩散模型之间的特征空间,这些隐藏状态通过一个可训练的轻量投影连接器CprojC_{proj}Cproj进行投影,得到特征对齐的条件cmllmc_{mllm}cmllm:
cmllm=Cproj(Hmllm). c_{mllm} = C_{proj}(H_{mllm}). cmllm=Cproj(Hmllm).
尽管这种基于MLLM的条件提供了宝贵的高层跨模态推理,但我们也认识到扩散模型在解析细粒度文本语义方面具有极强的能力。为了提供互补信号,我们使用T5文本编码器ET5\mathcal{E}_{T5}ET5(Raffel et al., 2020)独立编码原始提示,得到专用的文本嵌入ctextc_{text}ctext:
ctext=ET5(T). c_{text} = \mathcal{E}_{T5}(\mathcal{T}). ctext=ET5(T).
随后,我们将这两种互补的信号流拼接,形成最终的关系条件信号cjointc_{joint}cjoint:
cjoint=Concat(cmllm,ctext). c_{joint} = \text{Concat}(c_{mllm}, c_{text}). cjoint=Concat(cmllm,ctext).
该复合信号不仅包含显式的文本指令,还包含关于主体交互与时空逻辑的深层推理,为后续生成阶段提供了坚实的基础。
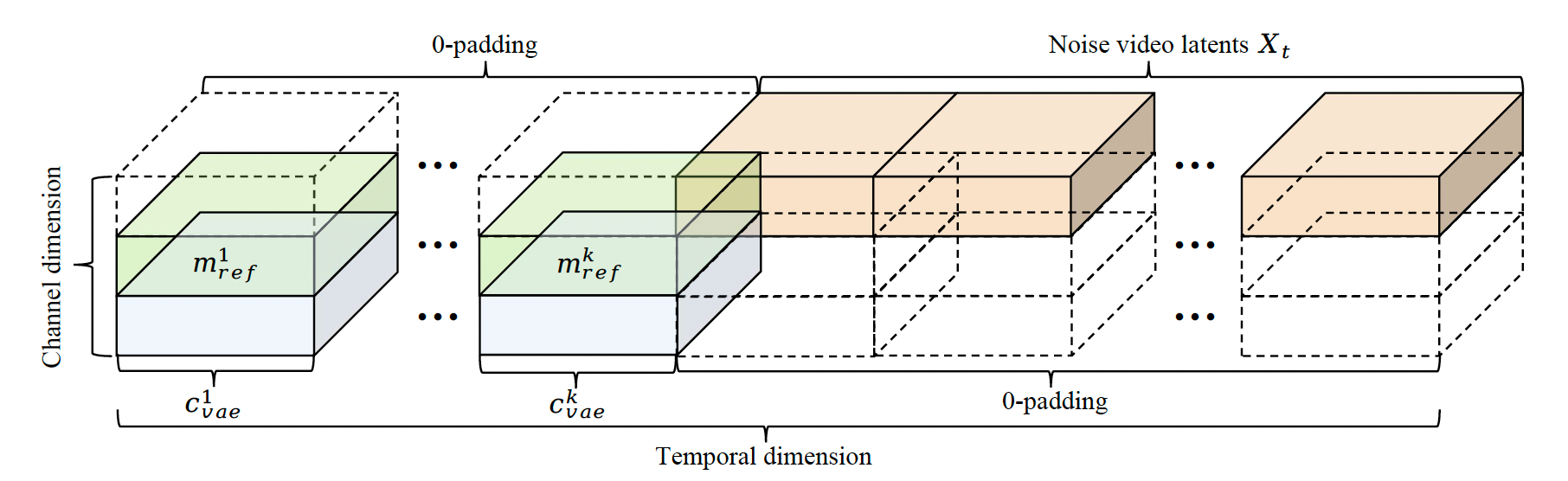
图3:我们自适应多参考条件策略的示意图。
3.4 COLLECTIVELY CONDITIONED VIDEO DIFFUSION
在指令规划过程中,我们将有用的语义信息整合进cjointc_{joint}cjoint。接下来,我们需要将cjointc_{joint}cjoint作为条件输入到DiT模块中以引导视频生成。我们的生成主干网络uΘu_{\Theta}uΘ在预训练的时空变分自编码器(VAE)的潜空间中运行。为了确保高保真且一致的视频生成,我们采用了一种集体条件机制,该机制能够协同整合多种信息流。如第3.1节所述,我们的集体条件机制在两个协同层面上运行:对时空输入的条件化以及跨注意力机制。为了保持来自参考图像的细粒度外观细节,我们设计了一种自适应多参考条件策略,如图3所示。具体而言,我们将参考图像编码为低层VAE特征,记为:
cvae=EVAE({Irefi}) c_{vae} = \mathcal{E}_{VAE}(\{I_{ref}^i\}) cvae=EVAE({Irefi})
由于S2V与I2V不同,参考图像并不被视为实际的视频帧。我们首先在噪声视频潜变量的时间轴上扩展,填充KKK个额外的时序槽并置零:
x~t=padT(xt,K) \tilde{x}_t = \text{pad}_T(x_t, K) x~t=padT(xt,K)
然后,我们将参考图像的VAE特征cvaec_{vae}cvae放置在这KKK个填充的时间位置上(其他位置为零),并在通道维度上进一步拼接相应的二进制掩码mrefm_{ref}mref,以突出主体区域。DiT块的最终输入通过通道级拼接后经patch嵌入得到:
Hvid=PatchEmbed(concatc(x~t,c~vae,m~ref)) H_{vid} = \text{PatchEmbed}(\text{concat}_c(\tilde{x}_t, \tilde{c}_{vae}, \tilde{m}_{ref})) Hvid=PatchEmbed(concatc(x~t,c~vae,m~ref))
其中c~vae\tilde{c}_{vae}c~vae和m~ref\tilde{m}_{ref}m~ref在KKK个填充时间槽之外为零,仅在这些槽内携带参考条件信号。此设计在保留原视频时间完整性的同时,通过通道条件注入细粒度外观信息并强调主体区域。接着,高层语义引导通过跨注意力层注入,涉及两个不同的信息信号:来自MLLM的关系条件cjointc_{joint}cjoint(用于场景组合)以及来自CLIP的图像特征cclip=ECLIP({Irefi})c_{clip} = \mathcal{E}_{CLIP}(\{I_{ref}^i\})cclip=ECLIP({Irefi})(用于主体身份)。
在每个DiT块中,演化中的视频tokens HvidH_{vid}Hvid生成查询QvidQ_{vid}Qvid。条件信号cjointc_{joint}cjoint和cclipc_{clip}cclip被投影以形成各自的键和值矩阵。注意力层的最终输出是这些信息流的加权和,扩展了公式(4):
Hout=Hvid+Attn(Qvid,Kjoint,Vjoint)+Attn(Qvid,Kclip,Vclip) H_{out} = H_{vid} + \text{Attn}(Q_{vid}, K_{joint}, V_{joint}) + \text{Attn}(Q_{vid}, K_{clip}, V_{clip}) Hout=Hvid+Attn(Qvid,Kjoint,Vjoint)+Attn(Qvid,Kclip,Vclip)
其中(Kjoint,Vjoint)(K_{joint}, V_{joint})(Kjoint,Vjoint)和(Kclip,Vclip)(K_{clip}, V_{clip})(Kclip,Vclip)分别由cjointc_{joint}cjoint和cclipc_{clip}cclip通过线性投影层得到。通过以这种结构化方式整合高层关系推理(cjointc_{joint}cjoint)、语义身份引导(cclipc_{clip}cclip)以及低层外观细节(cvaec_{vae}cvae),BindWeave能够有效地引导扩散过程,生成不仅在视觉上忠实于主体,而且在逻辑与语义上与复杂用户指令一致的视频。
3.5 TRAINING AND INFERENCE
训练设置。遵循第3.1节中描述的修正流(rectified flow)公式,我们的模型被训练以预测真实的速度场。BindWeave的总体训练目标可以表述为模型输出与vtv_tvt之间的均方误差(MSE):
Lmse=∥uΘ(zt,t,cjoint,cclip,cvae)−vt∥22 \mathcal{L}_{mse} = \|u_{\Theta}(z_t, t, c_{joint}, c_{clip}, c_{vae}) - v_t\|_2^2 Lmse=∥uΘ(zt,t,cjoint,cclip,cvae)−vt∥22
我们的训练数据来自公开可用的500万规模的OpenS2V-5M数据集(Yuan等人,2025)。通过一系列过滤策略,我们提炼出一个最终的高质量数据集,约包含100万视频-文本对。训练过程遵循两阶段课程学习策略。所有训练均在512个xPU上进行,全局批大小为512,采用恒定学习率5×10−65\times10^{-6}5×10−6和AdamW优化器。
初始稳定阶段持续约1000次迭代,使用一个从100万数据中筛选出的核心子集,以其卓越的质量和代表性为特征。这一阶段对于适应Subject-to-Video(S2V)任务的特定需求至关重要,主要专注于学习如何忠实地保持主体的视觉身份,同时与对应的文本运动指令对齐。这为后续的大规模训练奠定了坚实基础。
随后,训练进入全规模阶段,额外进行5000次迭代,模型在此阶段接触整个100万规模的精炼数据集。第二阶段允许模型在稳定基础上进一步学习,从更广泛的高质量样本中吸收信息,从而显著提升其生成能力与泛化性能。
推理设置。在推理阶段,我们的BindWeave接受灵活数量的参考图像(通常为1到4张),同时由一个文本提示引导生成过程,描述所需场景与行为。类似于Phantom(Liu等人,2025),我们在推理时使用提示重写器,以确保文本准确描述所提供的参考图像。生成过程在50步内完成,使用修正流(Liu等人,2022)轨迹,并结合无分类器引导(CFG, Ho & Salimans, 2022),其缩放系数为ω\omegaω。在每一步中,噪声的引导估计计算如下:
ϵ^θ(xt,c)=ϵθ(xt,∅)+ω(ϵθ(xt,c)−ϵθ(xt,∅)) \hat{\epsilon}_{\theta}(x_t, c) = \epsilon_{\theta}(x_t, \varnothing) + \omega(\epsilon_{\theta}(x_t, c) - \epsilon_{\theta}(x_t, \varnothing)) ϵ^θ(xt,c)=ϵθ(xt,∅)+ω(ϵθ(xt,c)−ϵθ(xt,∅))
其中ϵθ(xt,c)\epsilon_{\theta}(x_t, c)ϵθ(xt,c)为在提示ccc条件下的噪声预测,而ϵθ(xt,∅)\epsilon_{\theta}(x_t, \varnothing)ϵθ(xt,∅)为无条件预测。该估计随后被调度器用于推导xt−1x_{t-1}xt−1。
4 EXPERIMENTS
4.1 EXPERIMENTAL SETTINGS
基准与评估指标。为确保公平比较,我们采用OpenS2V-Eval基准(Yuan等人,2025),并遵循其官方评估协议,该协议提供了对主体一致性与身份保真度的精细化评估。该基准包含180个提示,分为七个不同类别,涵盖从单一主体(人脸、身体、实体)到多主体及人类–实体交互的各种场景。为量化性能,我们报告该协议中的自动化指标,所有指标的分数越高表示结果越好。这些指标包括:Aesthetics(Christoph Schuhmann,2024),用于评估视觉吸引力;MotionSmoothness(Bradski等人,2000),用于衡量时间平滑度;MotionAmplitude(Bradski等人,2000),用于衡量运动幅度;以及FaceSim(Yuan等人,2024a),用于衡量身份保持。此外,我们还采用OpenS2V-Eval(Yuan等人,2025)引入的三项与人类感知高度相关的指标:NexusScore(主体一致性)、NaturalScore(自然度)和GmeScore(文本-视频相关性)。
实现细节。BindWeave基于DiT架构(Wan等人,2025)的基础视频生成模型进行微调。在本次评估中,不包括T2V和I2V的预训练阶段。对于核心指令规划模块,我们使用Qwen2.5-VL-7B(Bai等人,2025)作为多模态大语言模型(MLLM)。为使多模态控制信号与DiT的条件空间对齐,我们引入一个轻量级连接器,将Qwen2.5-VL的隐藏状态投影。具体而言,该连接器由一个包含GELU激活函数的两层MLP组成。我们使用Adam优化器进行训练,学习率为5×10−65 \times 10^{-6}5×10−6,全局批大小为512。为减轻“复制粘贴”伪影,我们对参考图像应用数据增强(如随机旋转、缩放)。在推理阶段,我们使用50步去噪过程,并将CFG引导尺度ω\omegaω设为5。
基线模型。我们将BindWeave与最新的定制视频生成方法进行比较,包括开源方法(Phantom(Liu等人,2025)、VACE(Jiang等人,2025)、SkyReels-A2(Fei等人,2025)、MAGREF(Deng等人,2025))以及商业产品(Kling-1.6(Kwai,2024)、Vidu-2.0(Bao等人,2024)、Pika Lab(2024)、Hailuo Team(2024))。