C++11实用的“新特性”:列表初始化+右值引用与偷懒艺术——移动语义
今天我们来学习一些C++11中非常实用的新特性。
专栏:🎉《C++》
📌《数据结构》
💡《C语言》
🚀《Linux》

目录
一、C++11的发展史
二、列表初始化
2.1、C++98中的{}
2.2、C++11中的{}
2.3、C++11的std::initializer_list
三、右值引用
3.1、左值与右值
3.2、左值引用与右值引用
3.3、引用延长生命周期
3.4、引用折叠
3.5、完美转发
四、右值引用的偷懒艺术——移动语义
4.1、概念
4.2、使用场景总结
4.2.1、 左值引用主要使用场景回顾
4.2.2、只能传值返回的场景
4.2.3、移动语义适用场景
总结:
一、C++11的发展史
在学习这些新特性之前我们先简单的了解一下!
C++11 是 C++ 的第二个主要版本,并且是从 C++98 起的最重要更新。
从下图可以看出:
C++98到C++11时间间隔还是比较久的。
可能大佬们有那么点躺平的意思。
但C++11之后就开始规律的3年一更了。

 直接进入今天的正题。
直接进入今天的正题。
二、列表初始化
2.1、C++98中的{}
用{}来初始化其实大家都非常熟悉了。
只是需要注意:
C++98中其实仅支持数组和结构体用{}来初始化。
struct Node
{int _a;int _b;
};void test01()
{int arr[] = { 1,2,3,4,5,6 }; // 初始化数组Node node = { 1,2 }; // 初始化结构体对象
}2.2、C++11中的{}
我们都有体会:
使用{}初始化确实是方便。
但是你只支持数组和结构体那使用起来就没那么方便了。
于是C++11就想统一初始化的方式:
• 实现了一切对象皆可用{}初始化,{}初始化也叫做列表初始化。
• 内置类型支持,自定义类型也支持,自定义类型本质是类型转换,中间会产生临时对象,最后优化了以后变成直接构造。
• {}初始化的过程中,可以省略掉=。
• C++11列表初始化的本意是想实现一个大统一的初始化方式,其次他在有些场景下带来的不少便利,如容器push/inset多参数构造的对象时,{}初始化会很方便
下面我们来具体感受一下:
class Date
{
public:Date(int year = 1, int month = 1, int day = 1):_year(year), _month(month), _day(day){cout << "Date(int year, int month, int day)" << endl;}
private:int _year;int _month;int _day;
};void test01()
{// 内置类型int a{100};// 自定义类型// 会去调用自己的构造函数Date d{ 2025,11,8 };
}2.3、C++11的std::initializer_list
上面的初始化已经很方便了。
但是对于对象容器初始化还是不太方便。
比如一个vector对象,我想用N个 值去构造初始化,那么我们得实现很多个构造函数才能支持, vector v1 = {1,2,3}; vector v2 = {1,2,3,4,5};
于是 C++11库中提出了一个std::initializer_list的类。
这个类的本质是底层开一个数组,将数据拷贝 过来,std::initializer_list内部有两个指针分别指向数组的开始和结束。
这是他的文档:《initializer_list》,std::initializer_list支持迭代器遍历。
容器支持一个std::initializer_list的构造函数,也就支持任意多个值构成的 {x1,x2,x3...} 进行初始化。STL中的容器支持任意多个值构成的 {x1,x2,x3...} 进行初始化,就是通过 std::initializer_list的构造函数支持的。

void test04()
{vector<string> st1({ "abc","def","hij","klm" });vector<string> st2(initializer_list<string>{ "abc","def","hij","klm" });for (auto e : st1) { cout << e << " "; }cout << endl;for (auto a : st2) { cout << a << " "; }
}
三、右值引用
引用其实我们都不陌生。
C++98中我们就已经接触过引用了。
就是给变量取别名嘛。
但需要说明:C++98中的引用其实是左值引用。
C++11又引入了右值引用的概念。
 这玩意还有个左右之分。
这玩意还有个左右之分。
相信这时候大家也和我一样都充满了疑惑???????
3.1、左值与右值
左值是一个存储在内存中的表示数据的表达式(如变量名或解引用的指针)。
一般是有持久状态,存储在内存中,我 们可以获取它的地址,左值可以出现赋值符号的左边,也可以出现在赋值符号右边。定义时const 修饰符后的左值,不能给他赋值,但是可以取它的地址。
// 常见的左值:a,b,*p,s,s[0]... int a = 0; const int b = 1; int* p = &a; string s("abcdef"); s[0] = 'x';
右值也是一个表示数据的表达式。
 重点在下面:
重点在下面:
右值要么是字面值常量、要么是临时对象(匿名对象)。常见的就这两种
我们也不陌生,1,"abc"不就是字面值常量嘛!
临时对象:表达式求值过程会产生临时对象(x+y);传值返回也会产生临时对象...
右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址。
即右值并不在内存当中。
// 常见的右值10; 字面值常量 x + y; 临时对象 fmin(x, y); // 函数返回值(临时对象) string("abcdef"); 匿名对象
判断左值还是右值就一句话:
 :看他能不能取地址就完事了。
:看他能不能取地址就完事了。
3.2、左值引用与右值引用
左值引用是给左值取别名。
右值引用就是给右值取别名。
// 给上面的左值取别名(左值引用)
int& pa = a;
const int& pb = b;
int*& pp = p;
string& ss = s;
char& ps = s[0];// 右值引用(给上面的右值取别名)
int&& z = 10;
int&& sum = x + y;
int&& f = fmin(x, y);
string&& fs = string("abcdef");这时候肯定又有老铁问了:
左值引用能不能引用右值呢?
右值引用能不能引用左值呢?
 你可得记住喽!
你可得记住喽!
const修饰左值引用后可以引用右值。
将左值用move强制转换后可以用右值引用。
// 左值引用无法直接引用右值,可以用const 修饰
const int& px = 10;
const int& py = x + y;
const int& ff = fmin(x, y);
const string& st = string("abcdef");// 右值引用也无法直接引用左值,想要用move强制转换左值
int&& ppa = move(a);
int&& ppb = move(x + y);move是库里面的一个函数模板。
本质是内部进行强制类型转换。
还涉及一些引用折叠的知识。
 我们后面会细讲。
我们后面会细讲。
3.3、引用延长生命周期
临时变量在其完整表达式结束时变销毁。
通俗讲:即其生命周期仅在当前行。
将一个引用(通常是 const 左值引用或右值引用)绑定到一个临时对象时。

就是用const 左值引用或右值引用引用临时对象时。
该临时对象的生命周期会被延长,与引用本身的生命周期保持一致。
// 临时对象在ref被销毁时才销毁
const MyObject& ref = createObject(); // 用 const 引用绑定临时对象MyObject&& ref = createObject(); // 用右值引用绑定临时对象3.4、引用折叠
引用折叠顾名思义就能想来。
int& && pa = a;
你说这是不是引用折叠呢?

你还会说是吗?
C++规定:通过模板或 typedef 中的类型操作可以构成引用的引用。
举几个例子你就明白了。
注意观察下面代码有什么规律:注意其折叠后的类型
测试一:typedef改成的引用折叠
typedef int& lref;
typedef int&& rref;
int n = 0;lref& r1 = n; // r1 的类型是 int&
lref&& r2 = n; // r2 的类型是 int&
rref& r3 = n; // r3 的类型是 int&
rref&& r4 = 1; // r4 的类型是 int&&
// rref&& r4 = n; // 报错对模板函数进行显式实例化:
测试二:& ---- 模板参数为左值引用
& ---- 模板参数为左值引用
template<class T>
void func1(T& x)
{}int x = 1;
func1(x); // 没有折叠,实例化为void func1(int& x)func1<int&>(x); // 存在引用折叠,实例化为void func1(int& x)
//func<int&>(1); // 报错func1<int&&>(x); // 存在引用折叠,实例化为void func1(int& x)
//func1<int&&>(1); // 报错// 存在引用折叠,实例化为void func1(const int& x)
func1<const int&>(x);
func1<const int&>(1);// 存在引用折叠,实例化为void func1(const int& x)
func1<const int&&>(x);
func1<const int&&>(1);
测试三:&& ---- 模板参数为右值引用
&& ---- 模板参数为右值引用
template<class T>
void func2(T&& x)
{}int x = 1;
func2(x); // 没有折叠,实例化为void func1(int&& x)
//func2<int>(x); // 报错func2<int&>(x); // 存在引用折叠,实例化为void func1(int& x)
//func<int&>(1); // 报错func2<int&&>(1); // 存在引用折叠,实例化为void func1(int&& x)// 存在引用折叠,实例化为void func1(const int& x)
func2<const int&>(x);
func2<const int&>(1);func2<const int&&>(2); // 存在引用折叠,实例化为void func1(const int&& x)
//func2<const int&&>(x);不难发现:
当通过模板或 typedef 中的类型操作构成引用的引用(引用折叠)时,除了右值引用的右值引用折叠成右值引用外,其他情况全部折叠成左值引用。
即只要出现一个左值引用,则最终折叠为左值引用。
func2(T&&x)这样的函数模板中,T&& x参数看起来是右值引用参数,但是由于引用折叠的规则,他传递左值时就是左值引用,传递右值时就是右值引用,有些地方也把这种函数模板的参数叫做万能引用。
3.5、完美转发

不是嘛!
那什么是完美转发呢?
我们先看一个例子:参数匹配
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }template<class T>
void Function(T&& t) // 万能模板
{Fun(t);
}void Test05() {Function(10); // 传右值int a;Function(a); // 传左值Function(move(a)); // 传右值const int b = 8;Function(b); // 传const 左值Function(move(b)); // 传const 右值
}输出结果:
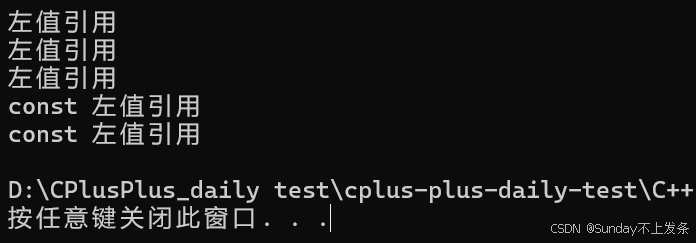
不出意外又是坑。
不应该是传左值调用左值引用的函数,传右值调用右值引用的函数吗?
但结果并不是这样。

这是因为变量表达式都是左值属性,也就意味着一个右值被右值引用绑定后,右值引用变量表达式的属性仍然是左值属性,也就是说Function函数中t的属性是左值,那么我们把t传 递给下一层函数Fun,那么匹配的都是左值引用版本的Fun函数。
这里我们想要保持t对象的属性, 就需要使用完美转发实现。
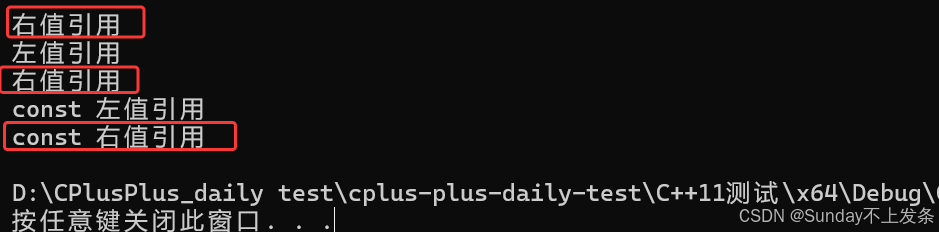
完美转发forward本质是一个函数模板,他主要还是通过引用折叠的方式实现,下面示例中传递给 Function的实参是右值,T被推导为int,没有折叠,forward内部t被强转为右值引用返回;传递给 Function的实参是左值,T被推导为int&,引用折叠为左值引用,forward内部t被强转为左值引用 返回。
template<class T>
void Function(T&& t)
{Fun(forward<T>(t)); // 完美转发
}
四、右值引用的偷懒艺术——移动语义
4.1、概念
允许在特定场景下将对象的资源从一个对象 “转移” 到另一个对象,而非拷贝资源,从而避免不必要的拷贝开销,提升性能。
4.2、使用场景总结
4.2.1、 左值引用主要使用场景回顾
左值引用主要使用场景是在函数中左值引用传参和左值引用传返回值时减少拷贝,同时还可以修改实参和修改返回对象的价值。左值引用已经解决大多数场景的拷贝效率问题。
但有些场景无法使用传引用返回,从而不可避免地就要进行拷贝。
具体下面会讲到。
4.2.2、只能传值返回的场景
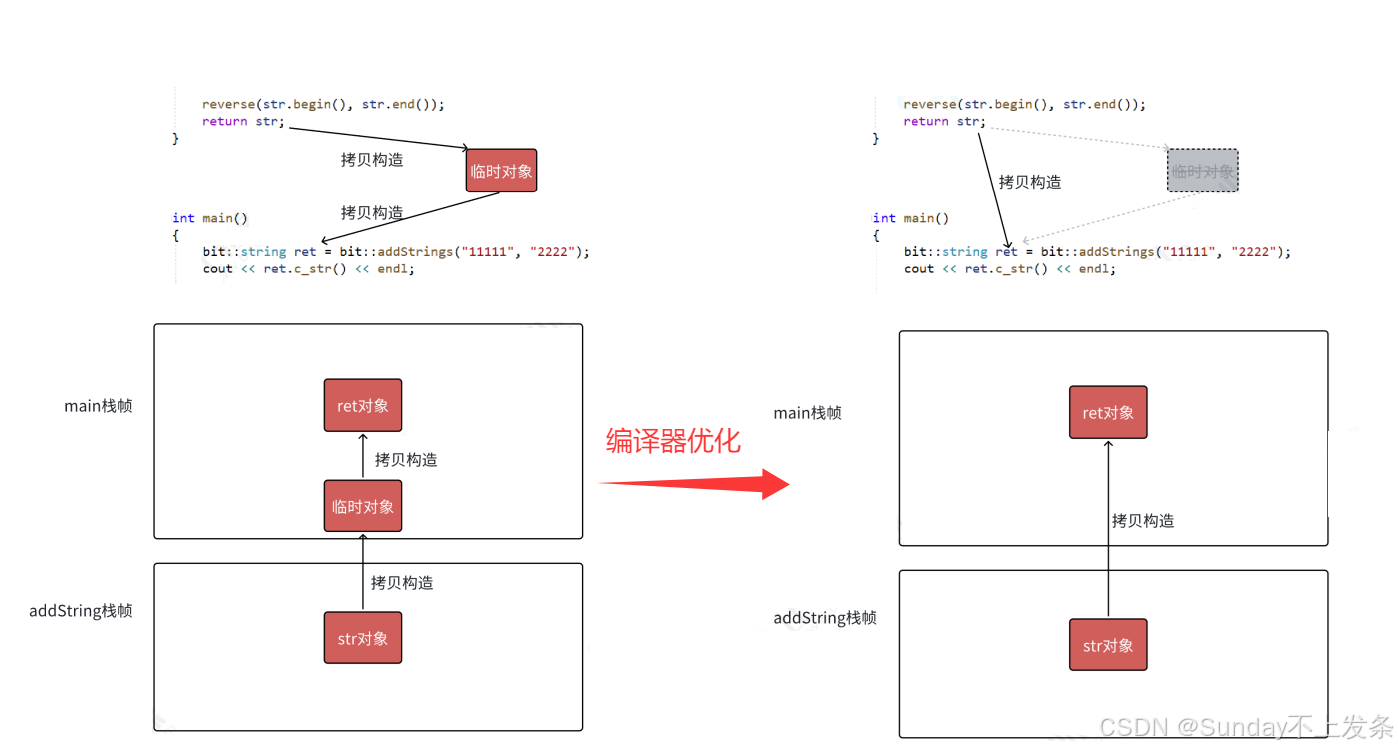
传值返回:本质是调用拷贝构造生成一个临时对象,然后再用临时对象拷贝构造接收返回值的对象。
对于需要深拷贝的对象而言,拷贝构造会有比较大的消耗。
这就是传值返回最大的缺陷。
但值得一提的是:在C++11移动语义出现之前。
编译器在这方面就做了很强的优化。
比如Vs2019的Debug模式下可以将原来的两次拷贝构造直接一步到位。
Release更加疯狂。
直接将拷贝构造也干掉了。
直接用一次构造完成。
Vs2022则Debug和Release模式统统将拷贝构造优化掉了。
所以,即使我们现在传值返回也没什么消耗了。
但具体取决于编译器有没有优化。
1、需要返回自定义类型对象时,由于在函数调用结束时会将对象析构,所以,只能传值返回,避免悬空引用。
// 定义一个结构体
struct Student {string name;int age;
};// 必须传值返回:返回局部Student对象的副本
Student createStudent(string name, int age) {Student s; // 局部结构体对象,函数结束后析构s.name = name;s.age = age;return s;// 正确:传值返回,复制s的内容给调用者(可能被RVO优化)
}int main() {Student s = createStudent("hds", 18);cout << s.name << " " << s.age << endl;return 0;
}
如果用传引用返回,则结果错误:

2、返回字符串拼接的临时对象
// 必须传值返回:返回字符串拼接的临时对象
string concatStr(const string& a, const string& b)
{// 临时对象:a和b拼接后的结果,表达式结束后会销毁return (a + b); // 正确:传值返回临时对象的副本(RVO优化后无拷贝)
}4.2.3、移动语义适用场景
传值返回的消耗就在于深拷贝时的拷贝构造。
那有什么办法能够减小这种消耗呢!
这时候右值引用的价值就来了:
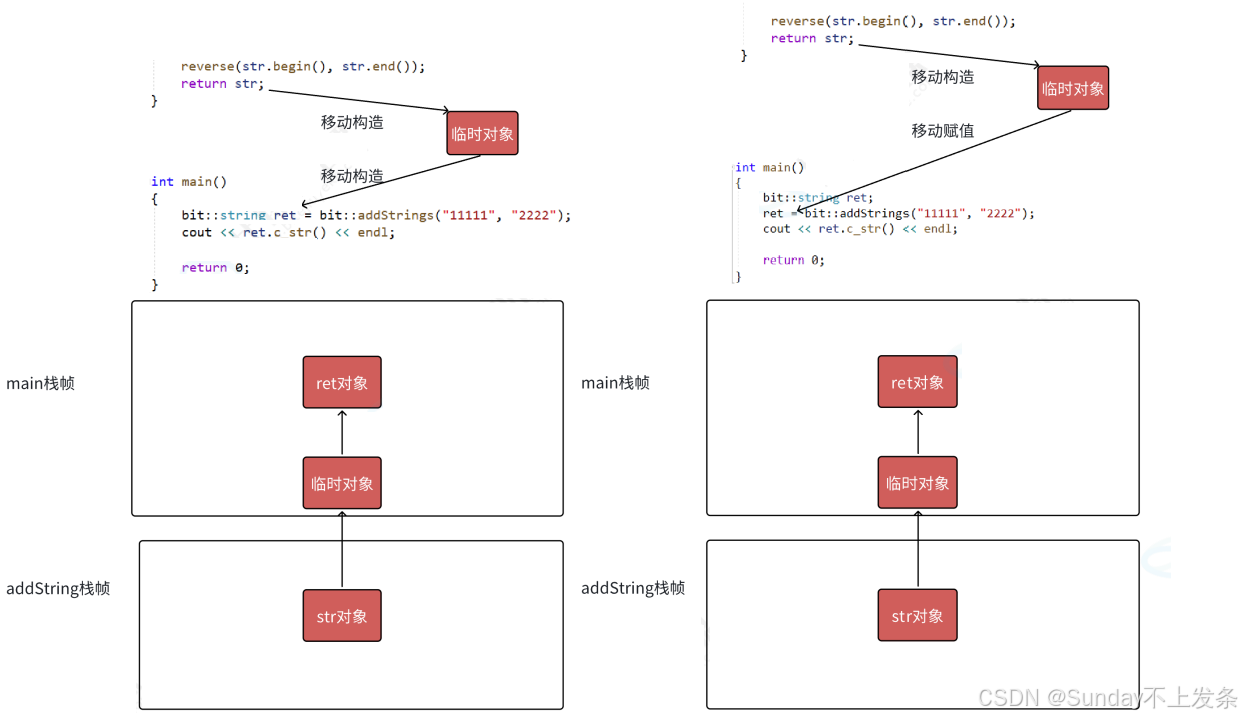
若返回的对象是右值,编译器会调用移动构造函数,直接 “窃取” 原对象的资源而非拷贝。
移动构造只是将原对象的资源交换给目标对象。
所以消耗大大减少。
// 将临时对象的资源交换过来,不发生拷贝,效率大大增加
void swap(string& ss)
{std::swap(_str, ss._str);std::swap(_size, ss._size);std::swap(_capacity, ss._capacity);
}// 移动构造
// 右值引用:临时对象
string(string&& s)
{swap(s);
}// 移动赋值
string& operator=(string&& s)
{swap(s);return *this;
}
总结:
- 对于自定义类型:优先移动构造,无移动时回退拷贝,编译器可优化为直接构造。
- 对于内置类型:直接内存拷贝。
