37.关注推送
关注的用户有新的评论时,要推送给其他关注他的用户。
关注推送也叫做Feed流,投喂。
通过无线下拉刷新获取新的信息。
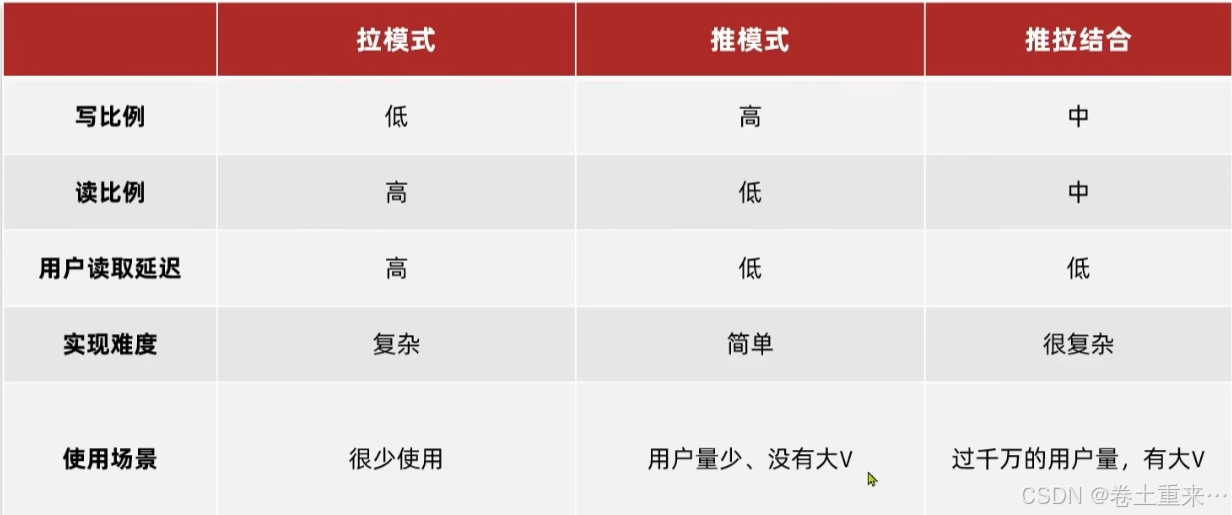
1.拉模式,读的压力比较大。每个粉丝都要去读取用户的发件箱中的数据,每次耗时较长。
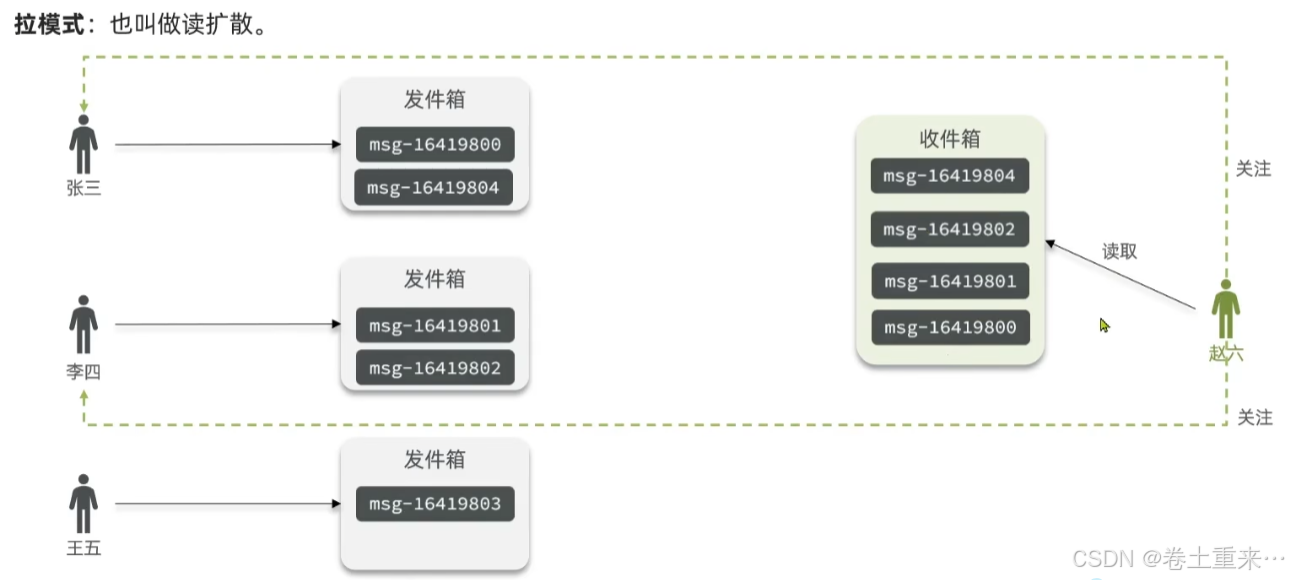
2.推模式,写的压力比较大。要写给每个粉丝的收件箱里。粉丝读取自己的收件箱很容易。
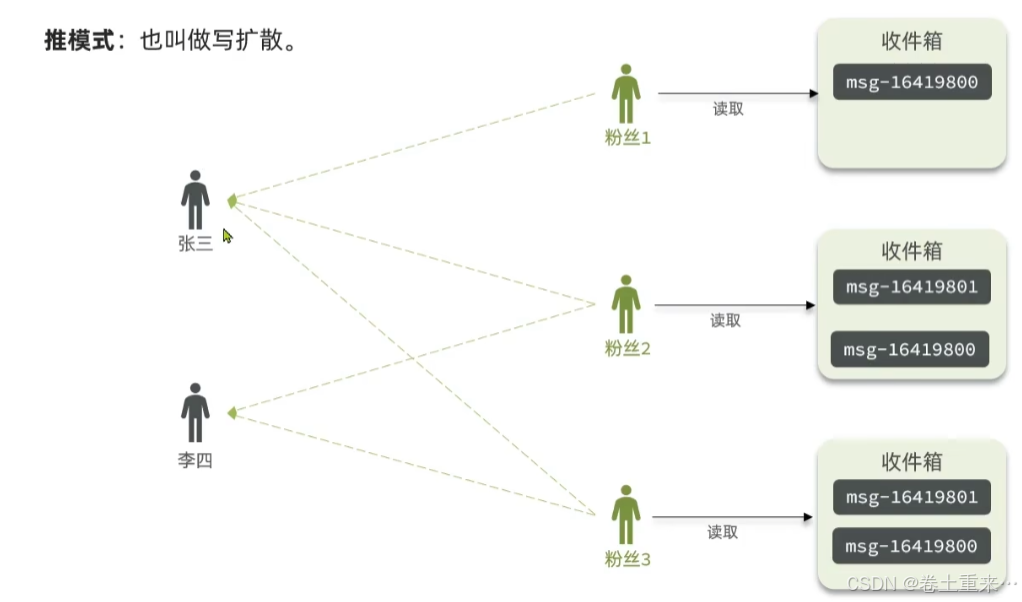
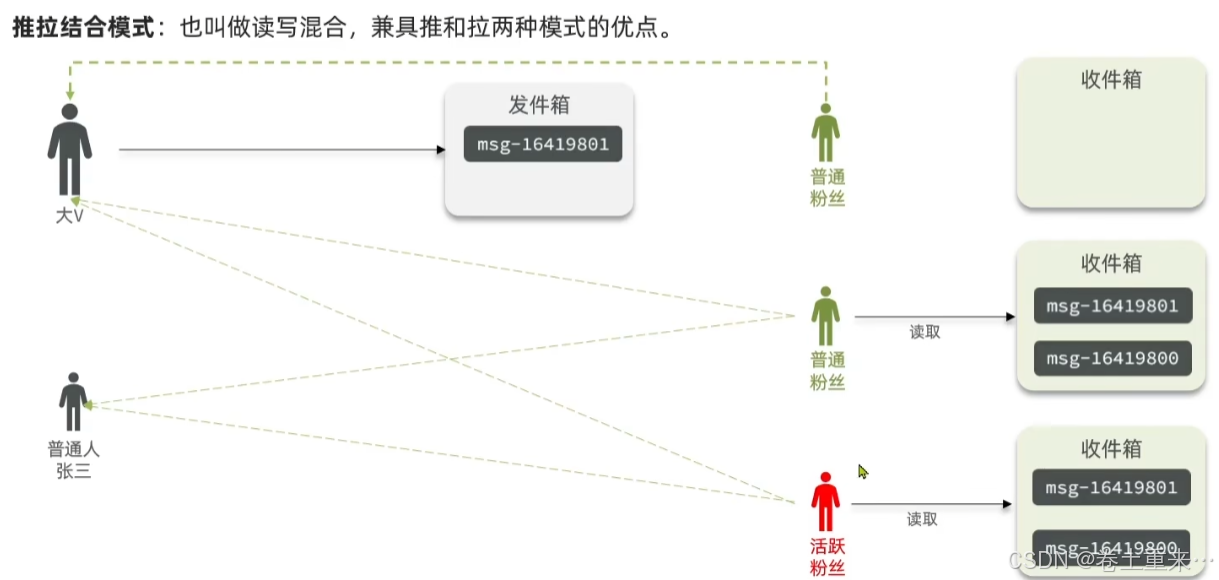
3.推拉结合模式
对于普通粉丝,采用拉的方式,通过读取用户的收件箱,读的压力就比较大。
对于活跃粉丝,采用推的方式,大V一更新数据就直接写到活跃粉丝的收件箱里。活跃粉丝只需要读取自己收件箱中数据即可。
需求:
1.新增探店笔记时候,保存blog数据到数据库中,然后再将blog的id推送消息到粉丝收件箱。后续就可以根据id在数据库中获取到所有信息。
2.收件箱可以根据时间排序,使用redis的数据结构实现。
3.实现分页效果。
使用的redis的数据结构
list 有序的,有角标也可以实现分页。
sortedset 支持按照评分score排序,排名从0开始可以实现分页获取数据。
按照角标来查的命令:
zrevrange key start end 倒序排名
range key start end 正序排名
range key start end withscores 带上分数
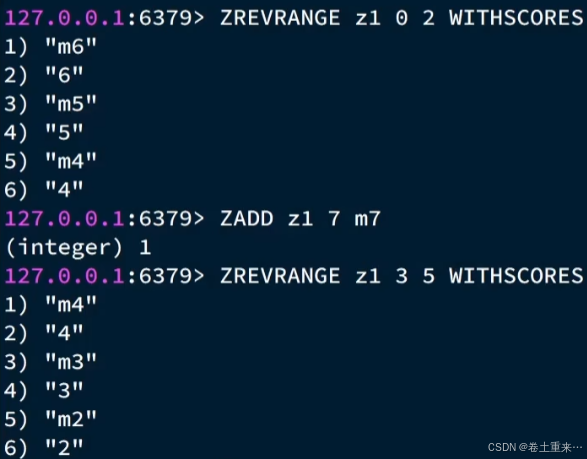
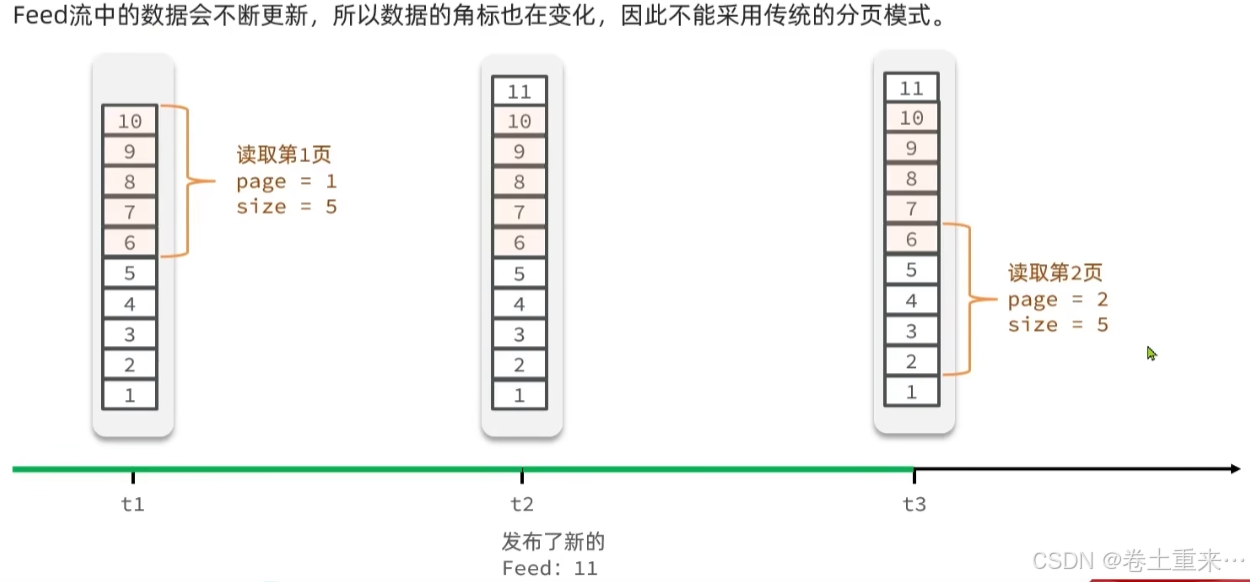
当添加数据后,读取第二页的数据就会出现重复读取了6号位置的数据。
应该采用滚动分页
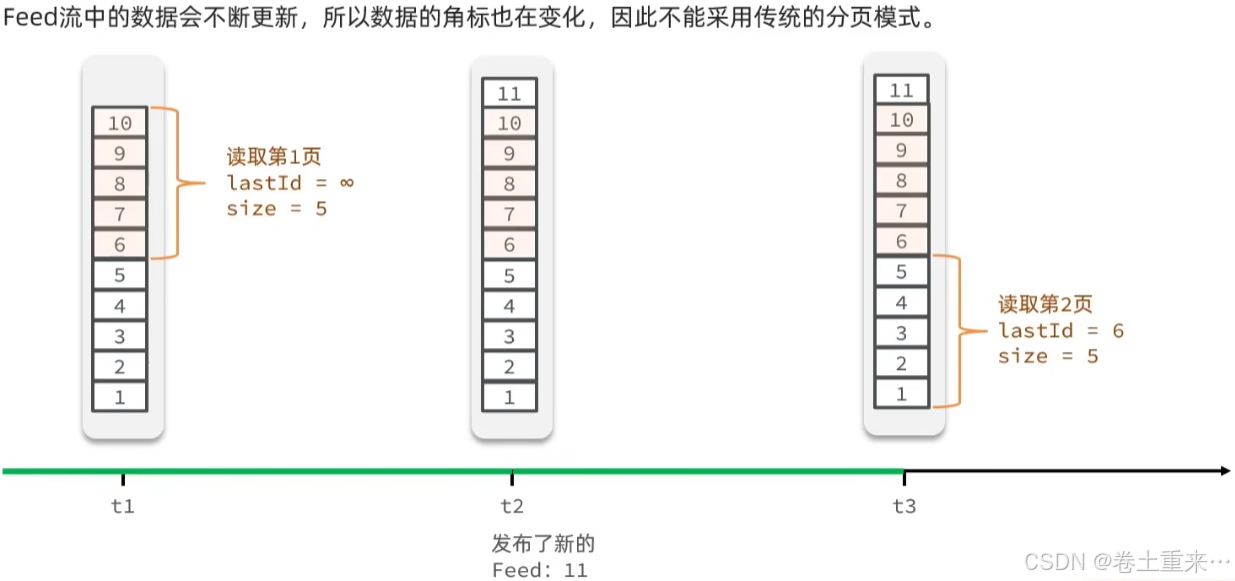
记录当前页的最后一条数据的位置,下一页查询就从该位置开始查询。
list结构不支持滚动分页查询,它是根据角标去查询的。
所以数据会经常更新变化,就是用滚动查询,那么就需要用到sortedset 结构,可以根据score排序,然后从score的最小值开始滚动查询。
按照分数来查的redis命令
zrevrangebyscore z1 1000 0 withscores limit 0 3
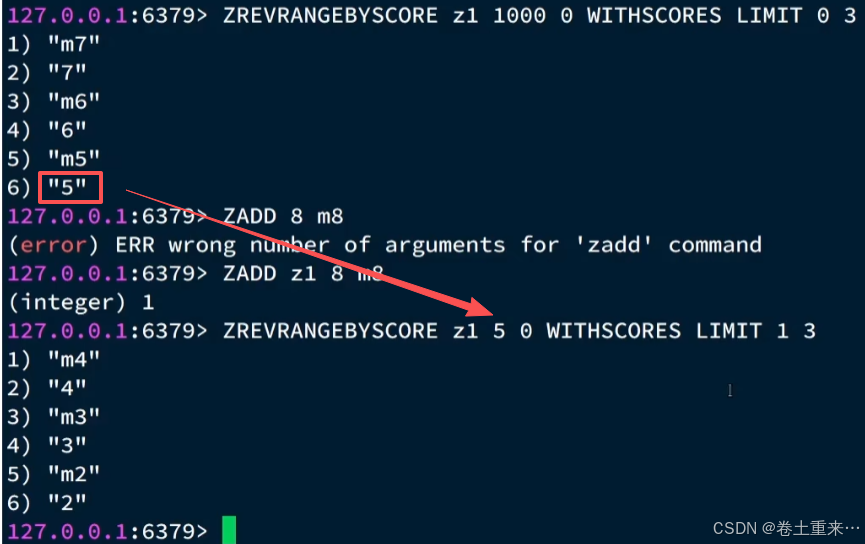
max:分数的最大值,第一次给一个特别大的值,比score的最大值大即可。第二次为第一次查询的score的最小值。如果是时间戳就是当前时间戳肯定是最大值。
min:分数最小值,默认固定为0。
offset:偏移量,第一次的偏移量固定为0,表示从第一个元素开始。第二次的偏移量=第一次socre的最小值在第一页查询集合中出现的次数。
count:查询的数量,每页的条数
注意:当socre值一样的时候,第二页查询的偏移量不能是1了,而应该是上一页中socre的最小值的个数。比如上一页的score的最小值为6,score在第一页查询集合中有两个,那么偏移量就为2。

@Overridepublic Long saveBlog(Blog blog) {//获取登录用户UserDTO user = UserHolder.getUser();blog.setUserId(user.getId());boolean save = save(blog);if (!save) {throw new ServiceException("新增探店笔记失败");}//查询笔记作者(当前用户)的所有粉丝List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();//推送笔记id给所有粉丝follows.stream().forEach(follow -> {String key = UserConstant.FEED_KEY + follow.getUserId();stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());});//返回idreturn blog.getId();} @GetMapping("/of/follow")public ApiResponse blogOfFollow(@RequestParam("lastId") Long lastId,@RequestParam(value = "offset", defaultValue = "0") Integer offset) {//offset 偏移量//lastId 表示每一次查询都要带上上一次查询的时间戳ScrollResult scrollResult = blogService.blogOfFollow(lastId, offset);return ApiResponse.success(scrollResult);}@Overridepublic ScrollResult blogOfFollow(Long lastId, Integer offset) {//1.获取当前用户UserDTO user = UserHolder.getUser();//2.查询收件箱 zrevrangebyscore key max min limit offset countString key = UserConstant.FEED_KEY + user.getId();Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, lastId, offset, 2);if(typedTuples == null || typedTuples.isEmpty()) {return new ScrollResult();}//3.解析数据:blogId、minTime(时间戳)、offset//初始化好大小,提升性能List<Long> ids = new ArrayList<>(typedTuples.size());Long minTime = 0L;int os = 1;for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {String blogId = typedTuple.getValue();ids.add(Long.valueOf(blogId));long time = typedTuple.getScore().longValue();//分数-最小时间戳if(minTime == time) {os++;}else {minTime = time;os = 1;}}//4.根据id查询blogString blogIdsStr = StrUtil.join(",", ids);List<Blog> blogs = query().in("id", ids).last("order by field (id," + blogIdsStr + ")").list().stream().collect(Collectors.toList());blogs.forEach(this::queryBlogUser);//5.封装并返回ScrollResult scrollResult = new ScrollResult();scrollResult.setList(blogs);scrollResult.setMinTime(minTime);scrollResult.setOffset(os);return scrollResult;}