分布式专题——48 ElasticSearch聚合操作详解
1 聚合的概述
- ElasticSearch 除了搜索功能外,还提供针对其数据的统计分析功能,这一功能通过**聚合(aggregations)**实现;
- 作用:能够极其方便地实现对数据的统计、分析、运算;
- 例:
- 什么品牌的手机最受欢迎?(用于分析类别维度的“热门程度”)
- 这些手机的平均价格、最高价格、最低价格?(用于分析数值维度的“统计指标”)
- 这些手机每月的销售情况如何?(用于分析时间维度的“趋势变化”)
1.1 聚合的使用场景
- 聚合查询的适用场景非常广泛,典型包括商业智能、数据挖掘、日志分析等领域,以下是具体行业/场景的应用示例:
-
电商平台的销售分析:统计每个地区的销售额、每个用户的消费总额、每个产品的销售量等,用于了解销售情况和趋势
-
社交媒体的用户行为分析:统计每个用户的发布次数、转发次数、评论次数等;还可按地区、时间、话题等维度拆分分析,用于理解用户行为和趋势
-
物流企业的运输分析:统计每个区域的运输量、每个车辆的运输次数、每个司机的行驶里程等,用于了解运输情况和优化运输效率
-
金融企业的交易分析:统计每个客户的交易总额、每个产品的销售量、每个交易员的业绩等,用于了解交易情况和优化业务流程
-
智能家居的设备监控分析:统计每个设备的使用次数、每个家庭的能源消耗量、每个时间段的设备使用率等,用于了解用户需求和优化设备效能
-
1.2 基本语法
-
聚合查询的语法结构与ElasticSearch其他查询相似,通常包含以下三部分:
-
查询条件:指定需要聚合的文档,可使用标准的ElasticSearch查询语法,如
term、match、range等; -
聚合函数:指定要执行的聚合操作,如
sum(求和)、avg(求平均)、min(最小值)、max(最大值)、terms(桶聚合,用于分组统计)、date_histogram(基于日期的直方图聚合)等;每个聚合命令都会生成一个聚合结果; -
聚合嵌套:聚合命令可以嵌套,以便更细粒度地分析数据;
-
-
语法示例结构:
GET <index_name>/_search {"aggs": {"<aggs_name>": { // 聚合名称需要自己定义"agg_type": {"field": "<field_name>"}}} }-
aggs_name:聚合函数的名称,由使用者自定义
-
agg_type:聚合种类,比如是桶聚合(
terms)或者是指标聚合(avg、sum、min、max等) -
field_name:字段名称或者叫域名,即要对哪个字段执行聚合操作
-
2 聚合的分类
2.1 概述与示例数据
-
ElasticSearch 的聚合主要分为三类,每类都有明确的功能和类比场景;
-
Metric Aggregation(指标聚合):执行数学运算,对文档字段进行统计分析,类似 MySQL 中的
min()、max()、sum()等聚合函数操作;- MySQL 语句:
SELECT MIN(price), MAX(price) FROM products(统计产品价格的最小值和最大值); - ElasticSearch DSL 类比实现(以“求价格平均值”为例):
{"aggs":{"avg_price":{ // 聚合名称"avg":{ // 求平均值"field":"price"}}} }
- MySQL 语句:
-
Bucket Aggregation(桶聚合):将满足特定条件的文档集合放入“桶”中,每个桶关联一个
key,类似 MySQL 中的GROUP BY操作;- MySQL 语句:
SELECT size, COUNT(*) FROM products GROUP BY size(按产品尺寸分组并统计数量); - ElasticSearch DSL 类比实现(以“按尺寸分组”为例):
{"aggs": {"by_size": { // 聚合名称"terms": { // 桶聚合"field": "size"}}} }
- MySQL 语句:
-
Pipeline Aggregation(管道聚合):对其他聚合的结果进行二次聚合,实现更复杂的多维度统计分析;
-
-
示例数据
-
索引与映射操作
-
删除索引(可选清理操作):
DELETE /employees -
创建索引并定义映射:
PUT /employees {"mappings": {"properties": {"age": { "type": "integer" }, // 整数类型,存储年龄"gender": { "type": "keyword" }, // keyword类型,存储性别(适合精确匹配、分组)"job": { // 文本类型,同时开启keyword子字段(用于分组、聚合)"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 50}}},"name": { "type": "keyword" }, // keyword类型,存储姓名(精确匹配、分组)"salary": { "type": "integer" } // 整数类型,存储薪资}} }
-
-
批量插入文档:通过
_bulkAPI 批量插入 20 条员工数据,每条数据包含name、age、job、gender、salary字段,示例片段如下:PUT /employees/_bulk { "index" : { "_id" : "1" } } { "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 } { "index" : { "_id" : "2" } } { "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000} { "index" : { "_id" : "3" } } { "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 } { "index" : { "_id" : "4" } } { "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000} { "index" : { "_id" : "5" } } { "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 } { "index" : { "_id" : "6" } } { "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000} { "index" : { "_id" : "7" } } { "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 } { "index" : { "_id" : "8" } } { "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000} { "index" : { "_id" : "9" } } { "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 } { "index" : { "_id" : "10" } } { "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000} { "index" : { "_id" : "11" } } { "name" : "Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000 } { "index" : { "_id" : "12" } } { "name" : "Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary": 32000} { "index" : { "_id" : "13" } } { "name" : "Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000 } { "index" : { "_id" : "14" } } { "name" : "Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary": 25000} { "index" : { "_id" : "15" } } { "name" : "King","age":33,"job":"Java Programmer","gender":"male","salary":28000 } { "index" : { "_id" : "16" } } { "name" : "Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary": 16000} { "index" : { "_id" : "17" } } { "name" : "Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary": 16000} { "index" : { "_id" : "18" } } { "name" : "Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary": 20000} { "index" : { "_id" : "19" } } { "name" : "Boone","age":30,"job":"DBA","gender":"male","salary": 30000} { "index" : { "_id" : "20" } } { "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000}
-
2.2 指标聚合
-
指标聚合分为单值分析和多值分析两类,各自包含不同的聚合函数:
-
单值分析:只输出一个分析结果,包含以下聚合函数
-
min(最小值)、max(最大值)、avg(平均值)、sum(求和) -
Cardinality(类似 SQL 中的distinct Count,用于统计去重后的数量)
-
-
多值分析:输出多个分析结果,包含以下聚合函数
-
stats(基础统计,包含 min、max、avg、sum、count)、extended stats(扩展统计,增加方差、标准差等) -
percentile(百分位,如计算第 50 百分位数即中位数)、percentile rank(百分位排名) -
top hits(返回排在前面的文档示例)
-
-
-
多指标聚合。例:查询员工的最低、最高和平均工资。通过同时定义
max、min、avg三个单值聚合,分别统计薪资的最大值、最小值和平均值:POST /employees/_search {"size": 0, // 不返回匹配查询条件的原始文档数据,只返回聚合(或其他统计类)结果"aggs": {"max_salary": {"max": {"field": "salary"}},"min_salary": {"min": {"field": "salary"}},"avg_salary": {"avg": {"field": "salary"}}} } -
多值聚合:对 salary 进行统计(stats 聚合)。通过
stats聚合一次性输出薪资的多个统计指标(min、max、avg、sum、count):POST /employees/_search {"size": 0,"aggs": {"stats_salary": {"stats": {"field": "salary"}}} } -
Cardinality 聚合:对搜索结果去重(统计不同岗位的数量)。通过
cardinality聚合统计job.keyword字段的去重数量(即不同岗位的种类数):POST /employees/_search {"size": 0,"aggs": {"cardinate": {"cardinality": {"field": "job.keyword"}}} }
2.3 桶聚合
2.3.1 概述
-
桶聚合是按照一定规则,将文档分配到不同的“桶”中,从而达到分类统计的目的;
-
ElasticSearch 提供了多种桶聚合方式,可分为以下类别:
-
Terms 聚合:基于字段的“词项”进行分组(类似 SQL 的
GROUP BY);- 字段支持要求:
keyword类型字段默认支持 fielddata,可直接用于 Terms 聚合;text类型字段需在 Mapping 中显式开启 fielddata,且会按照分词后的结果进行分桶;
- 字段支持要求:
-
数字类型相关的桶聚合
-
Range / Date Range:对数字或日期字段按“区间”分组(如年龄分“20-30岁”“30-40岁”区间); -
Histogram(直方图) / Date Histogram:对数字或日期字段按“固定间隔”分组(如薪资每 5000 为一个区间,日期每天为一个区间);
-
-
-
桶聚合支持嵌套,即可以在一个桶内再做分桶,实现更细粒度的多层级分析;
-
桶聚合的应用非常广泛,典型场景包括:
-
对数据进行分组统计:如按照地区、年龄段、性别等字段分组统计数量或指标
-
对时间序列数据进行时间段分析:如按照每小时、每天、每月、每季度、每年等时间段拆分分析
-
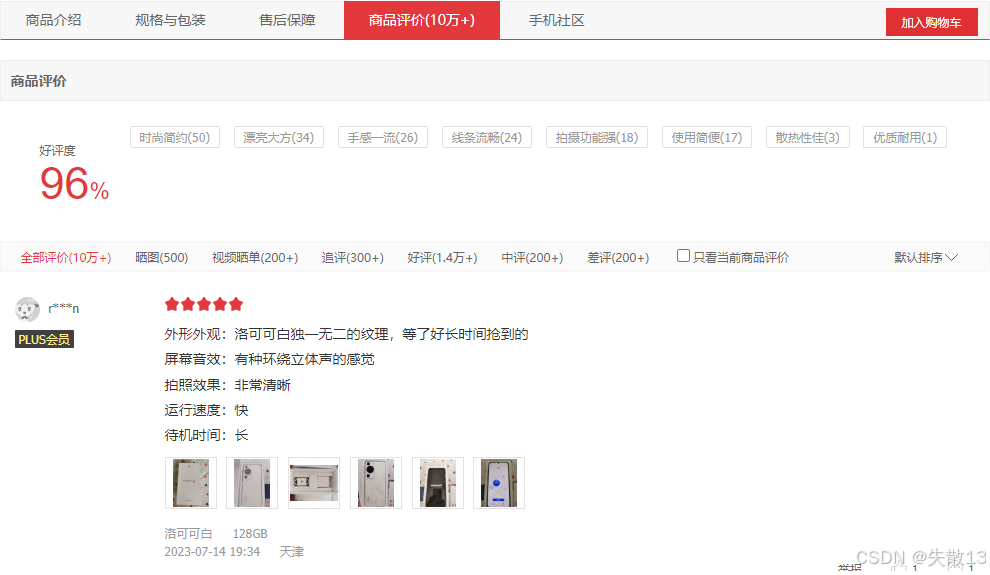
对各种标签信息分类并统计数量:如电商商品评价的“好评标签”“差评标签”分类统计(如图中电商商品评价的“时尚简约”“漂亮大方”等标签分组)
-
-
下图中展示了电商平台“商品评价”的实际场景,其中:
-
评价标签(如“时尚简约(50)”“漂亮大方(34)”)是通过Terms 聚合实现的:将包含相同标签的评价文档归入同一“桶”,并统计每个桶的文档数量(即标签出现次数)
-
评价等级(好评、中评、差评)的分组统计,也是桶聚合的典型应用,通过对“评价等级”字段分组,实现各等级评价的数量统计
-
2.3.2 例:获取 job 的分类信息
-
通过
terms聚合对job.keyword字段进行分组统计,实现岗位类别的分类分析:GET /employees/_search {"size": 0, // 不返回匹配查询条件的原始文档数据,只返回聚合(或其他统计类)结果"aggs": {"jobs": { // 自定义聚合名称"terms": {"field": "job.keyword" // 对岗位的keyword字段进行分组}}} } -
聚合支持以下关键属性来定制分析逻辑:
-
field:指定聚合操作的字段(如上述示例中的
job.keyword) -
size:指定返回的聚合结果数量(控制输出的“桶”数量)
-
order:指定聚合结果的排序方式
-
-
默认情况下,Bucket 聚合会统计每个桶内的文档数量(记为
_count),并按_count降序排序。可以通过order属性自定义排序逻辑,示例如下:GET /employees/_search {"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","size": 10, // 返回前10个岗位分类的聚合结果"order": {"_count": "desc" // 按文档数量降序排序(也可改为"asc"升序)}}}} }
2.3.3 限定聚合范围
-
通过
query子句可以过滤出符合条件的文档,再对这些文档执行聚合操作。下面示例中是对薪资≥10000元的员工文档,按岗位(job.keyword)进行Terms聚合:GET /employees/_search {"query": {"range": { // 范围查询,筛选薪资≥10000的文档"salary": {"gte": 10000}}},"size": 0, // 不返回原始文档,只返回聚合结果"aggs": {"jobs": {"terms": {"field": "job.keyword", // 对岗位的keyword字段分组"size": 10, // 返回前10个岗位分类"order": {"_count": "desc" // 按文档数量降序排序}}}} } -
问题:直接对Text字段执行Terms聚合会失败。Text字段默认不支持聚合操作,若强行执行会抛出异常。下面示例中对
job(Text类型)执行Terms聚合:POST /employees/_search {"size": 0,"aggs": {"jobs": {"terms": {"field": "job" // 直接对Text字段聚合,会报错}}} } -
异常原因:
Text fields are not optimised for operations that require per-document field data like aggregations...(Text字段默认不支持聚合,需改用keyword字段或开启fielddata);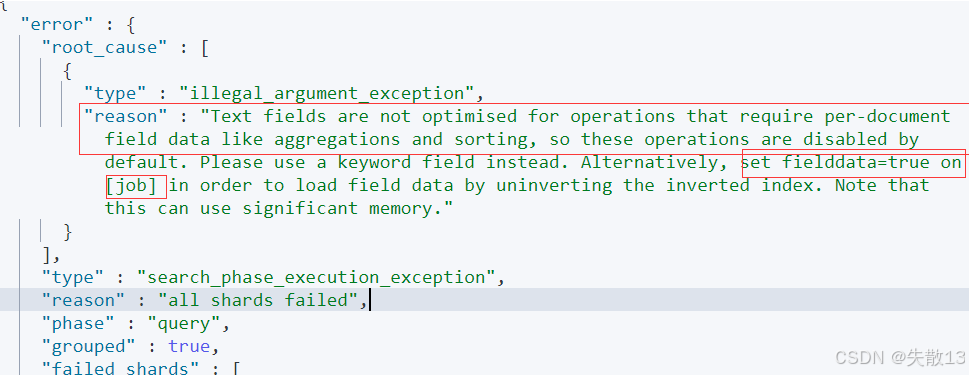
-
解决:对Text字段开启fielddata支持。通过更新Mapping,为Text字段启用
fielddata,使其支持聚合:PUT /employees/_mapping {"properties": {"job": {"type": "text","fielddata": true // 开启fielddata,支持聚合}} } -
开启后,可对Text字段的分词结果执行Terms聚合:
POST /employees/_search {"size": 0,"aggs": {"jobs": {"terms": {"field": "job" // 对Text字段的分词结果分组}}} } -
对
job.keyword(Keyword类型)和job(开启fielddata的Text类型)执行Terms聚合,分桶总数会不同:-
job.keyword是按“完整岗位名称”分组(如“Java Programmer”作为一个桶); -
job(Text类型,开启fielddata)是按“分词结果”分组(如“Java”“Programmer”会被拆分为不同桶);
-
-
可通过
cardinality聚合对比去重数量,示例:POST /employees/_search {"size": 0,"aggs": {"cardinate": {"cardinality": { // 统计去重后的数量"field": "job" // 对比job和job.keyword的结果差异}}} }
2.3.4 Range 聚合
-
按照数字范围对文档进行分桶,且支持自定义桶的
key; -
例:按工资范围分桶(自定义桶标识)
POST employees/_search {"size": 0,"aggs": {"salary_range": {"range": {"field": "salary", // 聚合字段为薪资"ranges": [{ "to": 10000 }, // 薪资 < 10000{ "from": 10000, "to": 20000 }, // 10000 ≤ 薪资 < 20000{ "key": ">20000", "from": 20000 } // 自定义桶标识,薪资 ≥ 20000]}}} }
2.3.5 Histogram聚合
-
按照固定数值间隔对数字字段分桶,可通过
extended_bounds定义桶的范围; -
例:工资按 5000 为间隔分桶(范围 0~100000)
POST employees/_search {"size": 0,"aggs": {"salary_histrogram": {"histogram": {"field": "salary", // 聚合字段为薪资"interval": 5000, // 每 5000 为一个桶"extended_bounds": { // 强制桶范围为 0~100000"min": 0,"max": 100000}}}} }
2.3.6 top_hits 聚合
-
获取分桶后,桶内最匹配的顶部文档列表(可指定数量和排序规则);
-
例:按岗位分组后,获取每个岗位中年龄最大的 3 名员工信息
POST /employees/_search {"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword" // 按岗位分组},"aggs": {"old_employee": {"top_hits": {"size": 3, // 每个桶返回 3 条文档"sort": [ // 按年龄降序排序{ "age": { "order": "desc" } }]}}}}} }
2.3.7 嵌套聚合
-
核心逻辑:在一个聚合的结果上,再嵌套执行另一层聚合,实现多维度分层分析;
-
示例 1:两层嵌套(岗位 + 薪资统计)。按岗位分组后,对每个岗位的薪资执行
stats聚合(统计 min、max、avg 等):POST employees/_search {"size": 0,"aggs": {"Job_salary_stats": {"terms": {"field": "job.keyword" // 第一层:按岗位分组},"aggs": {"salary": {"stats": {"field": "salary" // 第二层:统计每个岗位的薪资指标}}}}} } -
示例 2:三层嵌套(岗位 + 性别 + 薪资统计)。按岗位分组 → 再按性别分组 → 对每个性别组的薪资执行
stats聚合:POST employees/_search {"size": 0,"aggs": {"Job_gender_stats": {"terms": {"field": "job.keyword" // 第一层:按岗位分组},"aggs": {"gender_stats": {"terms": {"field": "gender" // 第二层:按性别分组},"aggs": {"salary_stats": {"stats": {"field": "salary" // 第三层:统计每个性别组的薪资指标}}}}}}} }
2.4 管道聚合
2.4.1 概述
-
管道聚合的核心是对聚合分析的结果再次进行聚合分析,其结果在原聚合中的输出位置分为两类:
-
Sibling(同级):结果与现有分析结果同级,包含以下类型:
Max Bucket、min Bucket、Avg Bucket、Sum BucketStats Bucket、Extended Stats BucketPercentiles Bucket
-
Parent(内嵌):结果内嵌到现有聚合分析结果之中,包含以下类型:
Derivative(求导)Cumulative Sum(累计求和)Moving Function(移动平均值)
-
2.4.2 min_bucket 示例
-
需求:在员工数最多的工种里,找出平均工资最低的工种;
-
实现:
POST employees/_search {"size": 0,"aggs": {"jobs": { // 第一层:按岗位分组"terms": {"field": "job.keyword","size": 10},"aggs": {"avg_salary": { // 第二层:统计每个岗位的平均薪资"avg": {"field": "salary"}}}},"min_salary_by_job": { // 管道聚合:找出平均薪资最低的岗位(与jobs同级)"min_bucket": {"buckets_path": "jobs>avg_salary" // 指定聚合路径}}} } -
说明:
min_bucket用于求之前聚合结果的最小值;- 通过
buckets_path指定聚合路径,min_salary_by_job的结果与jobs聚合同级。
2.4.3 stats_bucket 示例
- 需求:对平均工资进行统计分析(含 min、max、avg、sum、count 等指标);
- 实现:
POST employees/_search {"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","size": 10},"aggs": {"avg_salary": {"avg": {"field": "salary"}}}},"stats_salary_by_job": { // 管道聚合:对平均薪资执行多指标统计"stats_bucket": {"buckets_path": "jobs>avg_salary"}}} }
2.4.4 percentiles_bucket 示例
- 需求:计算平均工资的百分位数(如第 25、50、75 百分位等)。
- 实现:
POST employees/_search {"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","size": 10},"aggs": {"avg_salary": {"avg": {"field": "salary"}}}},"percentiles_salary_by_job": { // 管道聚合:计算平均薪资的百分位数"percentiles_bucket": {"buckets_path": "jobs>avg_salary"}}} }
2.4.5 Cumulative Sum 示例
- 需求:对平均薪资进行累计求和。
- 实现:
POST employees/_search {"size": 0,"aggs": {"age": { // 第一层:按年龄直方图分桶(间隔1岁)"histogram": {"field": "age","min_doc_count": 0,"interval": 1},"aggs": {"avg_salary": { // 第二层:统计每个年龄桶的平均薪资"avg": {"field": "salary"}},"cumulative_salary": { // 管道聚合:对平均薪资累计求和(内嵌到age聚合中)"cumulative_sum": {"buckets_path": "avg_salary"}}}}} }
2.5 聚合的作用范围
2.5.1 概述
- ElasticSearch 聚合分析的默认作用范围是
query的查询结果集,同时支持以下方式改变聚合的作用范围:-
Filter:在聚合内部通过过滤器限定聚合的文档范围 -
Post Filter:在聚合之后对结果进行过滤,不影响聚合的作用范围 -
Global:聚合作用于所有文档(无视query的过滤条件)
-
2.5.2 Query 作用范围(默认)
-
聚合作用于
query过滤后的文档集; -
例:对年龄≥20岁的员工,按岗位(
job.keyword)进行 Terms 聚合:POST employees/_search {"size": 0,"query": {"range": {"age": {"gte": 20}}},"aggs": {"jobs": {"terms": {"field": "job.keyword"}}} }
2.5.3 Filter 作用范围
-
在聚合内部通过
filter限定部分聚合的文档范围,同时可保留全局聚合; -
例:
-
older_person聚合仅作用于年龄≥35岁的员工,统计其岗位分布; -
all_jobs聚合作用于所有员工,统计全部岗位分布:POST employees/_search {"size": 0,"aggs": {"older_person": {"filter": {"range": {"age": {"from": 35}}},"aggs": {"jobs": {"terms": {"field": "job.keyword"}}}},"all_jobs": {"terms": {"field": "job.keyword"}}} }
-
2.5.4 Post Filter 作用范围
-
聚合作用于所有文档,聚合完成后再对结果进行过滤;
-
例:先统计所有岗位分布,再过滤出包含“Dev Manager”的结果
POST employees/_search {"aggs": {"jobs": {"terms": {"field": "job.keyword"}}},"post_filter": {"match": {"job.keyword": "Dev Manager"}} }
2.5.5 Global 作用范围
-
聚合作用于所有文档(无视
query的过滤条件); -
例:
query过滤“年龄≥40岁”的员工,但global聚合会统计所有这些员工的平均薪资(即查询范围内的全部文档)POST employees/_search {"size": 0,"query": {"range": {"age": {"gte": 40}}},"aggs": {"jobs": {"terms": {"field": "job.keyword"}},"all": {"global": {},"aggs": {"salary_avg": {"avg": {"field": "salary"}}}}} }
2.6 排序
2.6.1 概述
- 在 ElasticSearch 聚合(尤其是 Terms 聚合)中,可通过
order指定排序逻辑:-
默认情况下,按照桶内文档数量(
_count)降序排序 -
可通过
size指定返回的桶数量
-
2.6.2 按 _count 和 _key 排序
-
对“年龄≥20岁”的员工,按岗位(
job.keyword)分组后,先按桶内文档数(_count)升序、再按岗位名称(_key)降序排列:POST employees/_search {"size": 0,"query": {"range": {"age": {"gte": 20}}},"aggs": {"jobs": {"terms": {"field": "job.keyword","order": [{ "_count": "asc" },{ "_key": "desc" }]}}} }
2.6.2 按聚合指标(平均薪资)排序
-
先对岗位分组,再统计每个岗位的平均薪资(
avg_salary),最后按平均薪资降序排列岗位:POST employees/_search {"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","order": [{ "avg_salary": "desc" }]},"aggs": {"avg_salary": {"avg": {"field": "salary"}}}}} }
2.6.3 按统计指标(薪资最小值)排序
-
先对岗位分组,再对每个岗位的薪资执行
stats聚合(获取 min、max、avg 等),最后按薪资最小值降序排列岗位:POST employees/_search {"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","order": [{ "stats_salary.min": "desc" }]},"aggs": {"stats_salary": {"stats": {"field": "salary"}}}}} }
3 ES聚合分析不准确的原因及解决
3.1 原因
-
ES聚合分析不精准的根本原因:
- ElasticSearch 在对海量数据进行聚合分析时,会牺牲部分精准度来满足实时性需求;
- 其技术层面的核心原因是:数据分散在多个分片上,聚合时每个分片先取“Top X”(如前3名),再由协调节点合并结果。这种“分片级局部Top + 协调节点全局合并”的机制,会导致最终结果可能不精准(因为分片外的真实Top数据可能未被纳入计算);
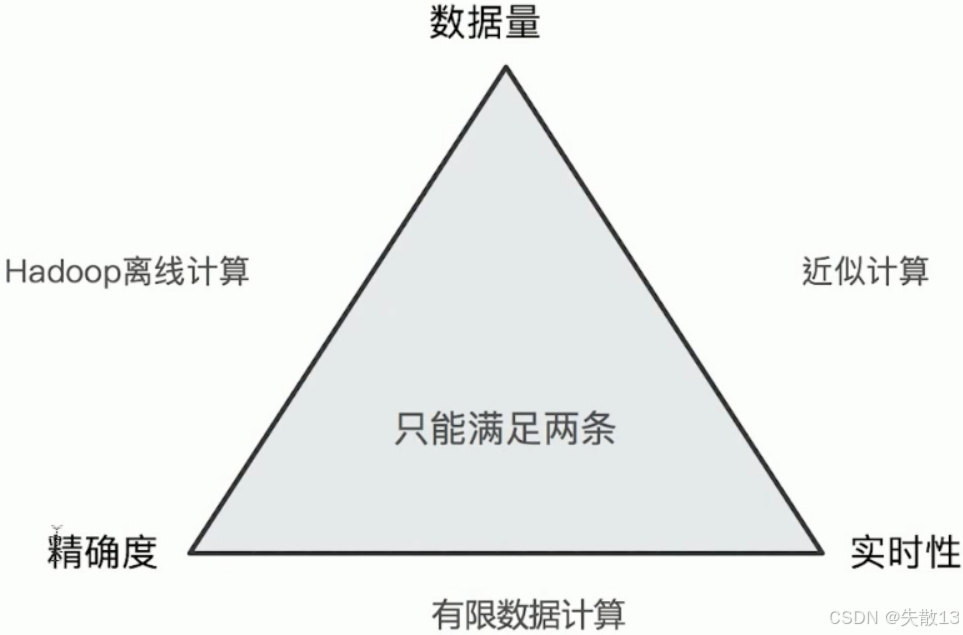
-
在数据处理场景中,存在以下三角权衡关系,且只能同时满足其中两条:
-
Hadoop离线计算:追求精确度和大数据量处理,但实时性差;
-
近似计算(如ES聚合):追求数据量和实时性,但精确度有损失;
-
有限数据计算:追求精确度和实时性,但数据量有限;
-
-
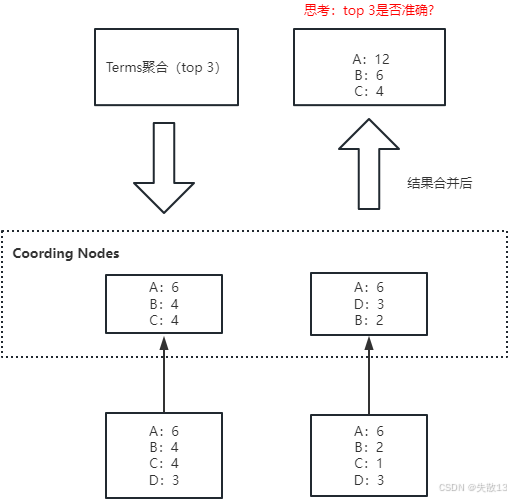
以“获取Top 3岗位”的Terms聚合为例,执行流程和不精准性可拆解为:
-
执行流程
-
每个数据分片(如Node1、Node2、Node3)先各自计算本地的“Top 3”结果;
-
协调节点(Coordinating Nodes)收集所有分片的本地Top 3,再合并出最终的“Top 3”;
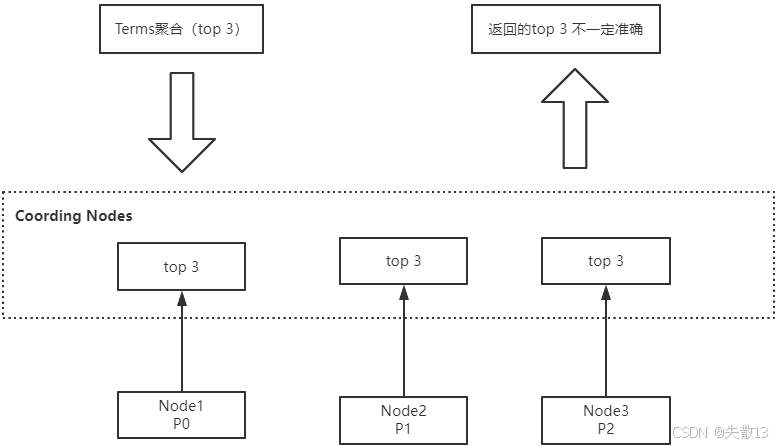
-
-
这种流程会导致结果不精准,以下图为例:
-
分片1的本地数据:A(6)、B(4)、C(4)、D(3) → 本地Top 3是A、B、C;
-
分片2的本地数据:A(6)、B(2)、C(1)、D(3) → 本地Top 3是A、D、B;
-
协调节点合并后结果:A(12)、B(6)、C(4) → 但真实全量数据中,D可能有更高的真实计数(如分片1的D(3) + 分片2的D(3) = 6),却因未进入分片本地Top 3而被遗漏,最终导致返回的Top 3不精准;
-
-
3.2 解决方案一:设置主分片为1
- 原理:将索引的主分片数设置为1,避免数据分散在多个分片上,从而让聚合在单个分片的全量数据上执行,保证精准度;
- 注意点:ElasticSearch 7.x版本已默认将主分片数设为1;
- 适用场景:数据量小的小集群、小规模业务场景(数据量小,性能开销可接受)。
3.3 解决方案2:调大 shard_size 值
-
原理:
shard_size指每个分片上聚合的数据条数,需大于等于size(size是聚合结果的返回数量);- 官方推荐公式:
shard_size = size * 1.5 + 10。shard_size越大,结果越趋近于精准聚合结果;size:聚合结果的返回值(如期望返回前3名,size就是3);shard_size:每个分片上聚合的数据条数;
- 可通过
show_term_doc_count_error参数显示最差情况下的错误值,辅助确定shard_size大小;
-
适用场景:数据量大、分片数多的集群业务场景;
-
测试:使用Kibana的测试数据
DELETE my_flights PUT my_flights {"settings": {"number_of_shards": 20},"mappings" : {"properties" : {"AvgTicketPrice" : {"type" : "float"},"Cancelled" : {"type" : "boolean"},"Carrier" : {"type" : "keyword"},"Dest" : {"type" : "keyword"},"DestAirportID" : {"type" : "keyword"},"DestCityName" : {"type" : "keyword"},"DestCountry" : {"type" : "keyword"},"DestLocation" : {"type" : "geo_point"},"DestRegion" : {"type" : "keyword"},"DestWeather" : {"type" : "keyword"},"DistanceKilometers" : {"type" : "float"},"DistanceMiles" : {"type" : "float"},"FlightDelay" : {"type" : "boolean"},"FlightDelayMin" : {"type" : "integer"},"FlightDelayType" : {"type" : "keyword"},"FlightNum" : {"type" : "keyword"},"FlightTimeHour" : {"type" : "keyword"},"FlightTimeMin" : {"type" : "float"},"Origin" : {"type" : "keyword"},"OriginAirportID" : {"type" : "keyword"},"OriginCityName" : {"type" : "keyword"},"OriginCountry" : {"type" : "keyword"},"OriginLocation" : {"type" : "geo_point"},"OriginRegion" : {"type" : "keyword"},"OriginWeather" : {"type" : "keyword"},"dayOfWeek" : {"type" : "integer"},"timestamp" : {"type" : "date"}}} }POST _reindex {"source": {"index": "kibana_sample_data_flights"},"dest": {"index": "my_flights"} }GET my_flights/_count GET kibana_sample_data_flights/_search {"size": 0,"aggs": {"weather": {"terms": {"field":"OriginWeather","size":5,"show_term_doc_count_error":true}}} }GET my_flights/_search {"size": 0,"aggs": {"weather": {"terms": {"field":"OriginWeather","size":5,"shard_size":10,"show_term_doc_count_error":true}}} }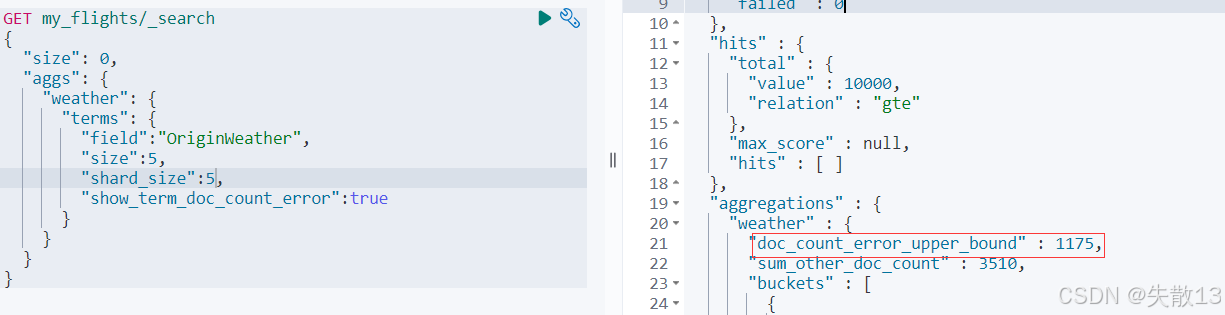
- 当未调整
shard_size(或shard_size较小时),聚合结果可能存在偏差; - 调大
shard_size后,通过show_term_doc_count_error可查看错误范围(doc_count_error_upper_bound是被遗漏的term分桶包含文档的最大可能值;sum_other_doc_count是除返回结果外其他term的文档总数),结果精准度显著提升;
- 当未调整
3.4 解决方案3:将 size 设置为全量值
- 原理:将
size设置为2^32 - 1(分片支持的最大值),确保聚合包含所有可能的候选数据,从而解决精度问题; - 注意:ElasticSearch 1.x版本中
size=0代表全量,高版本已取消该逻辑,因此需设置最大值; - 弊端:若分片数据量极大,会消耗巨大的CPU资源用于排序,且可能阻塞网络;
- 适用场景:对聚合精准度要求极高的业务场景(因性能问题,不推荐常规使用)。
3.5 解决方案4:使用Clickhouse/Spark进行精准聚合
- 原理:借助Clickhouse(列式存储、OLAP引擎)或Spark(分布式计算框架)的强大计算能力,在海量数据场景下实现精准聚合;
- 适用场景:数据量非常大、聚合精度要求高、响应速度快的业务场景(需依赖外部计算引擎,脱离ElasticSearch自身聚合能力)。
4 ElasticSearch 聚合性能优化
4.1 插入数据时对索引进行预排序
-
索引预排序(Index Sorting)在插入数据时对索引进行预排序,而非查询时再排序,以此提升范围查询(range query)和排序操作的性能;
-
这是 Elasticsearch 6.X 及之后版本才有的特性;
-
配置方法:创建新索引时,可配置每个分片内的段如何排序。例:
PUT /my_index {"settings": {"index": {"sort.field": "create_time", // 指定排序字段(如创建时间)"sort.order": "desc" // 指定排序顺序(降序)}},"mappings": {"properties": {"create_time": {"type": "date" // 字段类型为日期}}} } -
预排序会增加 Elasticsearch 的写入成本:
- 在某些场景下,开启索引预排序会导致约 40%-50% 的写性能下降;
- 因此,若业务场景更关注写入性能,不建议开启索引预排序;
- 若业务更依赖范围查询和排序的读性能,则可考虑使用。
4.2 使用节点查询缓存
-
**节点查询缓存(Node Query Cache)用于有效缓存过滤器(filter)**操作的结果。若多次执行同一
filter操作,缓存可大幅提升性能;但过滤器中任意值的修改,都需要重新计算并缓存新结果; -
使用方式:在包含
filter的查询请求中,Elasticsearch 会自动尝试使用节点查询缓存优化性能。例:GET /your_index/_search {"query": {"bool": {"filter": {"term": {"your_field": "your_value"}}}} }
4.3 使用分片请求缓存
-
触发条件:在聚合语句中设置
size: 0(含义:只返回聚合结果,不返回查询结果),即可使用分片请求缓存存储结果; -
例:
GET /es_db/_search {"size": 0,"aggs": {"remark_agg": {"terms": {"field": "remark.keyword"}}} }
4.4 拆分聚合,使聚合并行化
- 背景:Elasticsearch 中多个聚合条件默认不是并行运行的。若 CPU 资源充足,可将多个聚合拆分为多个查询,借助
_msearch实现并行聚合,从而缩短响应时间; - 常规多条件聚合(串行执行):
GET /employees/_search {"size": 0,"aggs": {"job_agg": {"terms": {"field": "job.keyword"}},"max_salary": {"max": {"field": "salary"}}} } _msearch并行聚合(拆分后并行执行):GET _msearch {"index":"employees"} {"size":0,"aggs":{"job_agg":{"terms":{"field": "job.keyword"}}}} {"index":"employees"} {"size":0,"aggs":{"max_salary":{"max":{"field": "salary"}}}}