机器学习21:可解释机器学习(Explainable Machine Learning)(上)
摘要
本周以可解释机器学习为核心议题,系统阐述其在现代人工智能应用中的关键作用。内容重点解析可解释性的重要性——如避免“聪明的汉斯”式表面智能、满足法律合规与公平性要求,并深入探讨模型可解释性与性能强大性之间的权衡关系(如线性模型可解释性强但限制大、深度模型性能优但解释性差)。进一步,将可解释机器学习分类为局部解释与全局解释,并分别介绍其方法与案例,包括显著图、平滑梯度、可视化与探针等技术,揭示模型决策依据,为模型修正与优化提供依据。
Abstract
This week focuses on Explainable Machine Learning as a core topic, systematically elaborating its critical role in modern AI applications. The content highlights the importance of explainability—such as avoiding "Clever Hans"-style superficial intelligence and meeting legal compliance and fairness requirements—while delving into the trade-off between model interpretability and performance power (e.g., linear models are interpretable but limited, deep models are powerful but less interpretable). Furthermore, explainable machine learning is categorized into local and global explanations, with methods and cases introduced respectively, including techniques like saliency maps, SmoothGrad, visualization, and probing, to reveal model decision rationale and support model correction and optimization.
一.可解释机器学习重要性
前面学习了许多模型如给出一张图片可以告诉我们图片内容的影像辨识的模型,但是我们并不能止步于此,接下来要让机器给出得到答案的理由。
可解释机器学习是一个重要议题是因为机器即使能够得到正确答案但是并不代表其就非常聪明。就如心理学案例的“聪明的汉斯”,表面上虽然可以回答各种问题,但实际上汉斯是通过观察周围人的微动作表情得到的答案。那对此如今种种人工智能的应用是否也如此,这就是机器学习的可解释性变得重要。
所以就如根据法律规定,贷款发放方必须对他们的贷款模型进行说明;将某种模型用在法庭上,就要确保模型行为的可解释性不能有偏差;同样当自动驾驶车出现异常行为,这也是需要合理的解释的。
机器学习具有了解释力,则在未来可以通过解释的结果再去修正模型。
二.可解释性与强大性
机器学习的可解释性之所以备受关注,有的说法是因为深度学习网络本身就相当于一个黑盒子,从而就会有一个想法就是是否可以使用其他比较容易解释的模型,就可以避免对于可解释机器学习的研究了呢?
对此可以假设都采用解释力较强的线性模型,所以经过训练后是可以轻易知道它是如何得到结果的,但是线性模型并不具备强大性,它有着巨大的限制。所以很快我们就进入了深度模型,其性能虽然强大但是其坏处就是不容易被解释。就此我们不能因噎废食因为深度模型不具可解释性而去摄取,而是要通过不断探索让强大的模型具有可解释性。
而说到既具有可解释性又强大的模型则决策树是不是一个好的选择呢?决策树相较于线性模型更强大,相较于深度模型更具有可解释性。
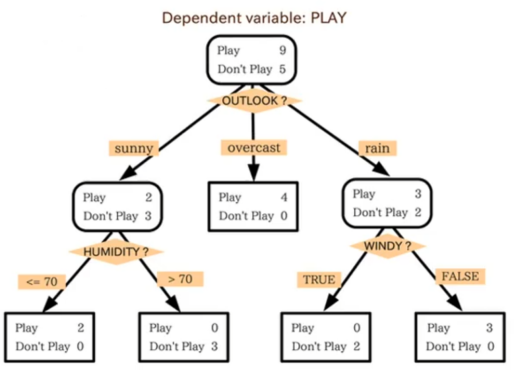
虽然决策树这两点都具备但是这只是单棵树,正常使用时并不是用一个决策树,而真正用的技术是随机森林,由多个决策树共同决定的结果。一个决策树可以通过每个节点和答案知道其如何得到最终判断,而当有一片森林就很难知道这些决策树合起来怎么得出判断的,所以决策树也不是最终的答案。
三.可解释机器学习的分类
可解释机器学习可分为两大类局部解释(Local Explanation)和全局解释(Global Explanation)。就以一个猫的图片为例,局部解释的目的是要机器解释为什么这时一只猫,而对于全局解释而言其目的是对于分类器而言什么样的图片中的动物算一只猫。

局部解释
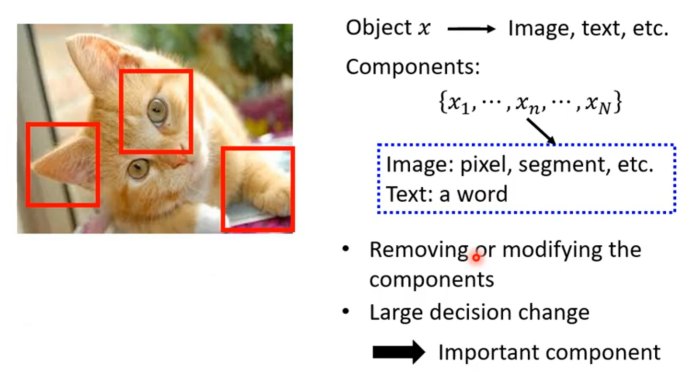
对于局部解释可以问的更清楚点,是图片中哪个部分让机器觉得是一只猫。更常规一点假设模型输入叫做x(可以是影像、文字),再将x拆分成多个部分(对于影像拆成的部分是像素而文字的是token)。现在要问的就是哪个部分对于机器做出最后的决断最为重要。对此就可以将每一个部分拿出并逐个进行改变或删除,若当改变某个部分导致最终的结果发生巨大变化,则说明这个部分非常重要。
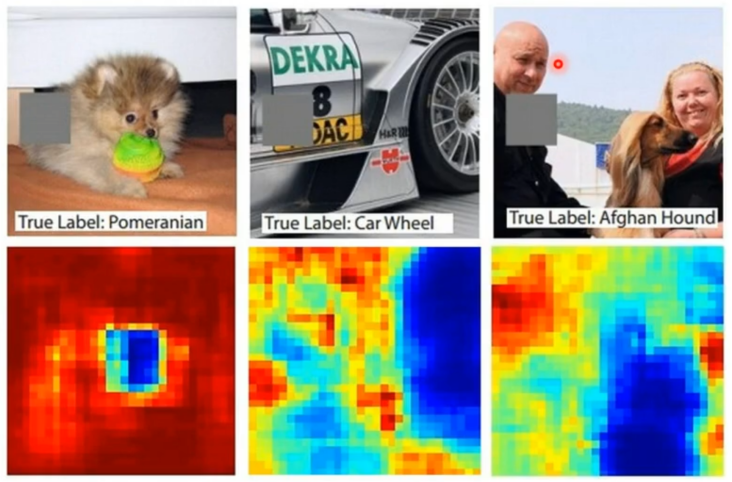
就如下简单的方法,在图片中不同的位置放上这个灰色方块,则网络便可以得到不同的结果。如图片下面的对比图,蓝色区域代表当灰色遮盖这个部分时输出该图片内容正确的概率低,而红色区域代表高。
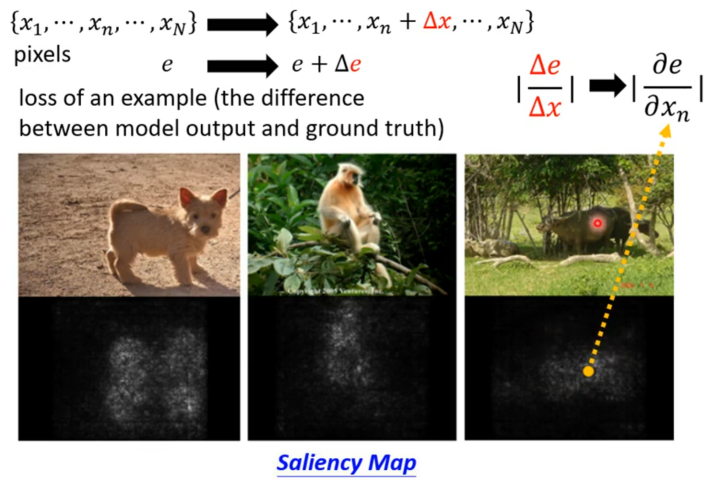
更进阶的的方法就是计算梯度。假设有张图片将其表示为{x1……xN},其中每一个x代表了一个像素。接着通过模型计算Loss,也就是模型输出的结果与正确答案的差距e。若要看每个x对于图片辨识的重要性,就将其中某个像素的值做一个小小变化∆x,然后看Loss会发生什么变化,当其中一个x+∆x导致结果发生巨大变化就代表这个像素对于影像辨识是重要的。通过将∆e与∆x的比值全部计算出来便得到一个显著图(Saliency Map),显著图中比值越大的点对应的颜色越白。
对于显著图也有个宝可梦与数码宝贝分类器的例子。

通过训练得到的正确率有98.9%,测试的正确率也有98.4%。但是通过画出其对应的显著图发现无论数码宝贝还是宝可梦其图中颜色偏白的点分布在图片中的四个角落,而避开图像本体。


这是因为宝可梦图片都是PNG文件,而数码宝贝都是JPEG文件。当读入PNG文件时其背景是黑的,所以机器只要看背景就能够分辨图片中是宝可梦还是数码宝贝,这也就体现出可解释机器学习的重要性。同样的例子也有下面识别马的图片,通过显著图发现图片左下角马的英文对于识别这张图具有重要性,而不是去辨别图中物体特征。

所以要增强显著图的显示,这就可以用到平滑梯度方法(SmoothGrad),这个方法就是随机在图片中添加噪声,然后获取带这些噪声的图的显著图,并将它们进行取平均得到的结果就会比原来好一点。

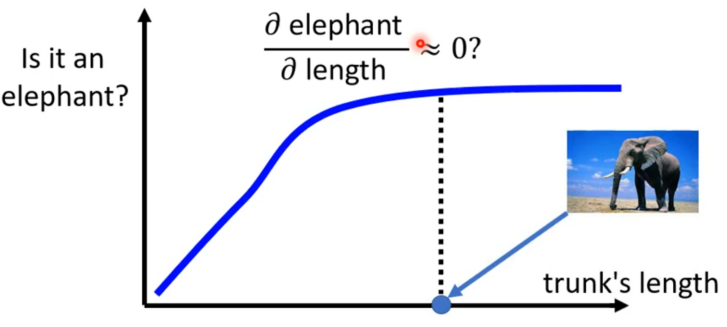
但是光看梯度并不能完全反映一个部分的重要性,就如通过鼻子长度来辨别大象,当鼻子越来越长就越可能是大象,但若超过某一个极限时,鼻子再长也不会更像大象。
前面是看一个模型的输入中哪些部分是重要的,现在看当网络得到一个输入时是如何进行处理的得到最终答案的。
①可视化
以语音辨识为例,当一个网络收到一个语音然后判断这个语音属于哪个音位。假设第一层和第二层都有100个神经,所以第一二层可以看作有100维向量的输出,接着再将100维向量降维到二维画到图上观察现象。
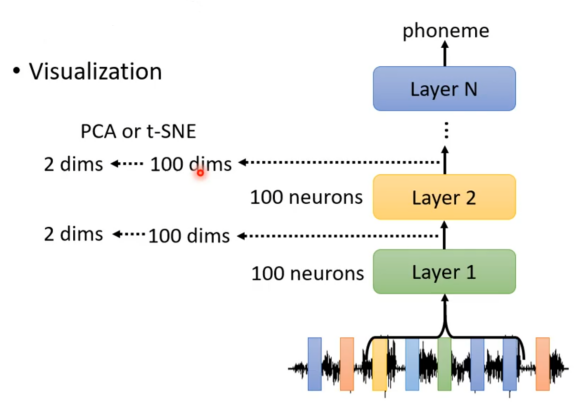
得到的结果就如下:
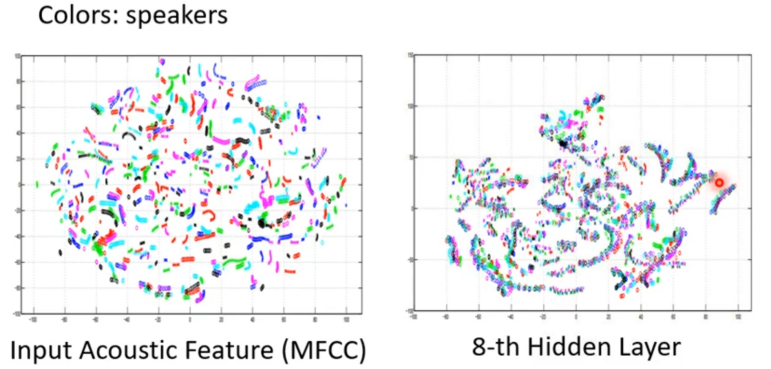
其中第一个图是MFCC降到二维画出的图,其中不同颜色代表不同的发言人,但是其中资料和有多内容是一样的,不同的人说同一句话并没有归类在一起。当用到第八层的网络时看到右边图的结果,可以发现图中变成一条一条的没有特定颜色的结果,这些一条条代表的是内容相同的句子所以得到精确分类的结果。
②探针(Probing)
除了通过肉眼观察外,还可以训练一个探针(分类器),如词性分类器(Pos Classifier),将BERT的embedding输入到其中判断属于哪个词性的词,若这个分类器正确率高,就代表这些embedding中有许多词性的信息,反之没有词性信息。
但是同样的要注意分类器自身问题,也有可能是分类器自身原因导致的正确率偏低或偏高。
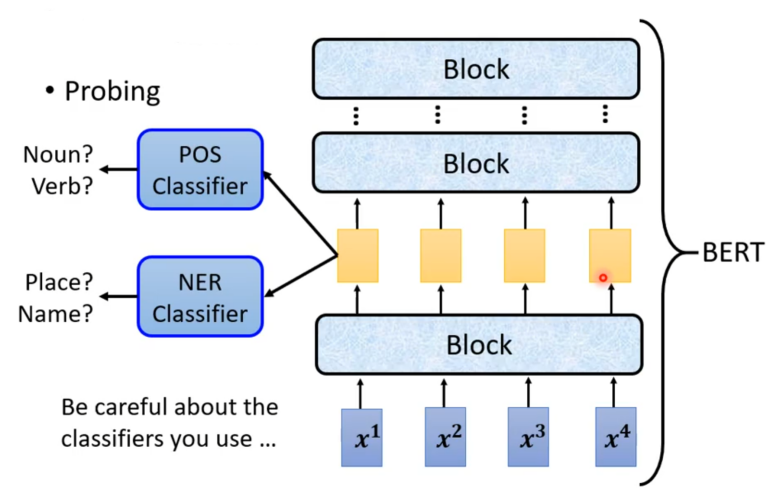
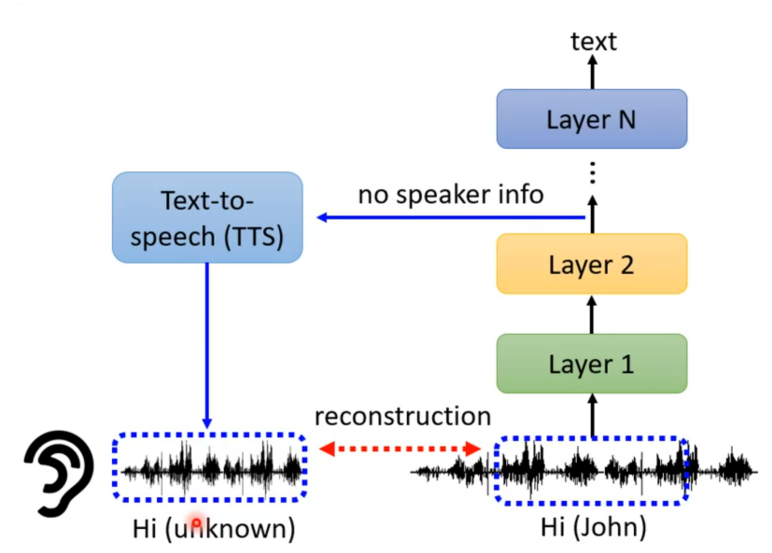
对于探针不一定要是分类器也可以是其他的类型。就如在训练语音合成模型,其实接收语音辨识模型中的embedding作为输入,然后尝试输出一段声音信息。 接着就会有趣的发现当将embedding输入到TTS模型中得到的语音与原来的发言人的声音不同,也就是说语音辨识模型会抹去发言人特征只保留语音内容。
总结
可解释机器学习旨在增强模型决策的透明性,对于合规、公平与模型优化至关重要。它在可解释性与性能间存在权衡:线性模型易解释但能力有限,深度模型强大但如同黑盒。技术分为局部解释(如显著图、平滑梯度)与全局解释(如可视化、探针),通过识别关键特征或理解整体逻辑来揭示决策依据。