webrtc降噪-NoiseEstimator类源码分析与算法原理
NoiseEstimator是WebRTC音频处理中的核心噪声估计组件,主要负责实时分析并跟踪音频信号中的噪声频谱特性。它采用混合估计策略,结合分位数统计方法和参数化噪声模型(白噪声+粉红噪声),在启动阶段快速建立噪声基线,在稳定运行阶段基于语音概率自适应更新。通过指数平滑机制,在噪声段加速收敛,在语音段保守更新,有效平衡噪声跟踪速度与语音保护。该组件为后续降噪算法提供准确的噪声谱估计,是保证语音增强效果和语音质量的关键基础模块 。
1. 核心功能
NoiseEstimator 类是 WebRTC 噪声抑制模块的核心组件,主要功能包括:
实时估计音频信号的噪声频谱特性
结合多种噪声估计方法(分位数估计、参数化模型)
根据语音概率自适应更新噪声估计
提供多种噪声谱估计结果供后续降噪处理使用
2. 核心算法原理
2.1 参数化噪声建模(白噪声+粉红噪声)
数学公式:
P(f) = A / f^α (粉红噪声模型)
其中:
P(f):频率 f 处的噪声功率A:粉红噪声幅度参数(pink_noise_numerator_)α:粉红噪声指数(pink_noise_exp_)
// 线性回归估计粉红噪声参数 float denom = sum_log_i_square * (kFftSizeBy2Plus1 - kStartBand) - sum_log_i * sum_log_i; float num = sum_log_i_square * sum_log_magn - sum_log_i * sum_log_i_log_magn; float pink_noise_adjustment = num / denom; // 估计 α 参数// 计算参数化噪声谱 float denom = PowApproximation(use_band, parametric_exp); parametric_noise_spectrum_[i] = parametric_num / denom; // P(f) = A / f^α
2.2 分位数噪声估计
quantile_noise_estimator_.Estimate(signal_spectrum, noise_spectrum_); // 基于信号统计分布的分位数来估计噪声水平
2.3 自适应噪声更新
// 基于语音概率的指数平滑更新 noise_spectrum_[i] = gamma * prev_noise_spectrum_[i] +(1.f - gamma) * (prob_non_speech * signal_spectrum[i] +prob_speech * prev_noise_spectrum_[i]);
3. 关键数据结构
class NoiseEstimator {
private:const SuppressionParams& suppression_params_; // 噪声抑制参数float white_noise_level_ = 0.f; // 白噪声水平估计float pink_noise_numerator_ = 0.f; // 粉红噪声分子 Afloat pink_noise_exp_ = 0.f; // 粉红噪声指数 α// 多种噪声谱估计结果std::array<float, kFftSizeBy2Plus1> prev_noise_spectrum_; // 前一帧噪声谱std::array<float, kFftSizeBy2Plus1> conservative_noise_spectrum_; // 保守噪声估计std::array<float, kFftSizeBy2Plus1> parametric_noise_spectrum_; // 参数化噪声估计std::array<float, kFftSizeBy2Plus1> noise_spectrum_; // 最终噪声估计QuantileNoiseEstimator quantile_noise_estimator_; // 分位数噪声估计器
};4. 核心方法详解
4.1 PrepareAnalysis()
void PrepareAnalysis() {std::copy(noise_spectrum_.begin(), noise_spectrum_.end(),prev_noise_spectrum_.begin());
}
// 功能:保存当前噪声谱到前一帧,为新一轮分析做准备4.2 PreUpdate()
void PreUpdate(int32_t num_analyzed_frames,rtc::ArrayView<const float, kFftSizeBy2Plus1> signal_spectrum,float signal_spectral_sum) {// 1. 分位数噪声估计quantile_noise_estimator_.Estimate(signal_spectrum, noise_spectrum_);// 2. 启动阶段使用参数化噪声模型if (num_analyzed_frames < kShortStartupPhaseBlocks) {// 白噪声估计:信号总能量 × 过减因子white_noise_level_ += signal_spectral_sum * kOneByFftSizeBy2Plus1 *suppression_params_.over_subtraction_factor;// 粉红噪声参数估计(线性回归)// 对数据取对数后拟合直线:log(P) = log(A) - α·log(f)// 3. 混合分位数估计和参数化估计noise_spectrum_[i] = (分位数噪声 × 当前帧数 + 参数化噪声 × 剩余帧数) / 总启动帧数}
}4.3 PostUpdate()
void PostUpdate(rtc::ArrayView<const float> speech_probability,rtc::ArrayView<const float, kFftSizeBy2Plus1> signal_spectrum) {constexpr float kNoiseUpdate = 0.9f; // 基础更新系数for (size_t i = 0; i < kFftSizeBy2Plus1; ++i) {float prob_speech = speech_probability[i];float prob_non_speech = 1.f - prob_speech;// 自适应更新系数:语音概率高时更新更保守float gamma = prob_speech > 0.2f ? 0.99f : kNoiseUpdate;// 保守噪声估计:只在确信的非语音段更新if (prob_speech < 0.2f) {conservative_noise_spectrum_[i] += 0.05f * (signal_spectrum[i] - conservative_noise_spectrum_[i]);}// 主噪声谱更新:指数平滑noise_spectrum_[i] = gamma * prev_noise_spectrum_[i] +(1.f - gamma) * (prob_non_speech * signal_spectrum[i] +prob_speech * prev_noise_spectrum_[i]);}
}5. 设计亮点
混合估计策略:结合分位数统计方法和参数化物理模型,提高估计准确性
自适应更新机制:根据语音概率动态调整更新速率,语音段保守更新,噪声段快速跟踪
多版本噪声估计:提供常规、保守、参数化等多种估计结果,适应不同应用场景
启动阶段优化:在初始阶段使用参数化模型快速建立噪声基线
计算效率优化:使用查表法(log_table)和近似计算降低计算复杂度
6. 典型工作流程
6.1 时序图
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ Prepare │ │ PreUpdate │ │ PostUpdate │ │ Analysis │───▶│ │───▶│ │ └─────────────┘ └─────────────┘ └─────────────┘│ │ │▼ ▼ ▼ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ 保存当前噪声 │ │ 分位数估计 │ │ 自适应更新 │ │ 到前一帧 │ │ 参数化建模 │ │ 保守估计 │ └─────────────┘ └─────────────┘ └─────────────┘
6.2 流程图
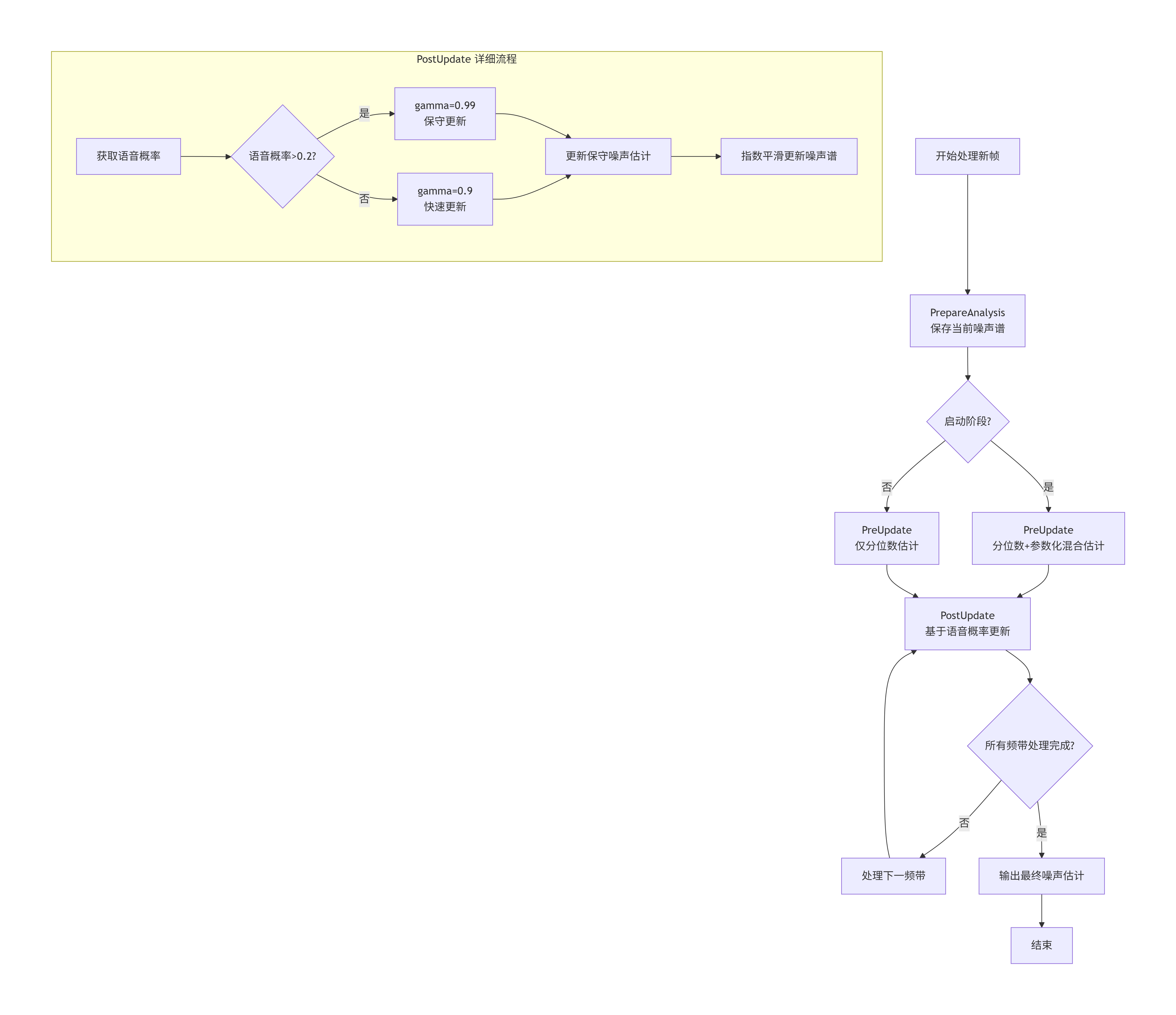
关键流程说明:
PrepareAnalysis:帧开始时保存状态,确保时序一致性
PreUpdate:核心噪声估计,启动阶段使用混合策略,稳定后使用分位数估计
PostUpdate:基于VAD结果的精细调整,在确信的噪声段加速收敛
保守估计:专门用于防止语音失真,只在高度确信的噪声段更新
这种设计使得噪声估计既能在平稳噪声环境下快速收敛,又能在语音活动期间保持稳定,避免语音失真。