【AI大模型技术】1.NLP
更多内容:XiaoJ的知识星球
目录
- 1.NLP
- 1.1 NLP Tasks
- 1.2 词表示(Word Representation)
- 1.3 语言模型
- 1.3.1 N-gram 模型
- 1.3.2 神经语言模型(Neural Language Model)
.
1.NLP
自然语言处理(Natural Language Processing,简称NLP)。
NLP致力于使计算机能够理解、解释和生成人类语言,以实现人机之间的有效沟通。
.
1.1 NLP Tasks
以下是一些NLP中的基本任务:
- 词性标注(Part-of-Speech Tagging, POS Tagging)
- 为句子中的每个单词分配一个词性标签,如名词、动词、形容词等。
- 命名实体识别(Named Entity Recognition, NER)
- 识别文本中的命名实体,如人名、地点、组织名等。
- 共指消解(Coreference Resolution)
- 识别文本中指代相同实体的不同表达。
- 依存句法分析(Dependency Parsing)
- 分析句子中词与词之间的依存关系。
- 句法分析(Syntactic Parsing)
- 分析句子的句法结构,构建句子的语法树。
- 语义角色标注(Semantic Role Labeling, SRL)
- 识别句子中谓词的论元(如施事、受事等)及其角色。
- 情感分析(Sentiment Analysis)
- 判断文本表达的是正面、负面还是中性的情感。
- 机器翻译(Machine Translation)
- 将一种语言的文本自动翻译成另一种语言。
- 文本摘要(Text Summarization)
- 生成文本的简短摘要。
- 问答系统(Question Answering, QA)
- 根据问题从文本中找到答案。
- 文本分类(Text Classification)
- 将文本自动分配到一个或多个类别。
- 拼写检查(Spell Checking)
- 识别文本中的拼写错误。
- 词干提取(Stemming)和词形还原(Lemmatization)
- 将单词还原到基本形式。
- 语义文本相似度(Semantic Textual Similarity)
- 评估两段文本在语义上的相似度。
- 文本生成(Text Generation)
- 自动生成文本内容。
- 对话系统(Dialogue Systems)
- 创建能够与人类进行自然对话的系统。
这些任务是NLP领域的基础,许多高级应用和研究都建立在这些基础任务之上。
.
1.2 词表示(Word Representation)
词表示(Word Representation):将符号(symbols)转换成机器能理解的含义(meanings)。
Word Representation让计算机来做,它的目标:
-
计算词相似度(Compute word similarity)
-
推断词的关系(Infer word relation)
1)相关词表示: 如用近义词/上义词(synonym/hypernym)表示当前词。
-
问题:
-
存在细微差异。
-
缺少单词新含义。
-
主观性。
-
数据稀疏。
-
大量人工标注&维护词典。
-
2)独立的符号表示单词: 独热编码 (One-Hot Representation)
-
独热编码 (One-Hot Representation):
-
用于将分类变量转换为一种数学格式,以便计算机可以更容易地处理。
-
独热编码中,每个类别值都被表示为二进制向量,向量长度等于类别的数量,只有一个位置是1,其余位置都是0。这个1表示该类别在向量中的位置,而0则表示其他所有类别。
-
-
问题:
- 会假设两词向量之间都是正交的,会导致两个词进行相似度计算都是0。
3)上下文(context)表示单词:利用当前词上下文的词,来表示当前词语。
利用向量来表示上下文的词语出现的频度来计算,称为稠密向量。利用稠密向量可计算出两词语的相似度。
-
共现计数(Co-Occurrence Counts):
-
NLP的统计方法,用于分析和表示词汇在其上下文中的共同出现频率。
-
这种技术可揭示词之间关系,尤其常一起出现的词汇,它们可能具有相似的语义或语法功能。
-
-
问题:
-
增加词汇量。
-
需要大量存储空间。
-
出现频度低的词语,效果不佳。
-
4)Word Embedding(词嵌入):
通过将单词、短语或句子映射到实数向量空间,使得语义相近的单词在向量空间中的位置相近,从而捕捉单词之间的语义和语法关系。
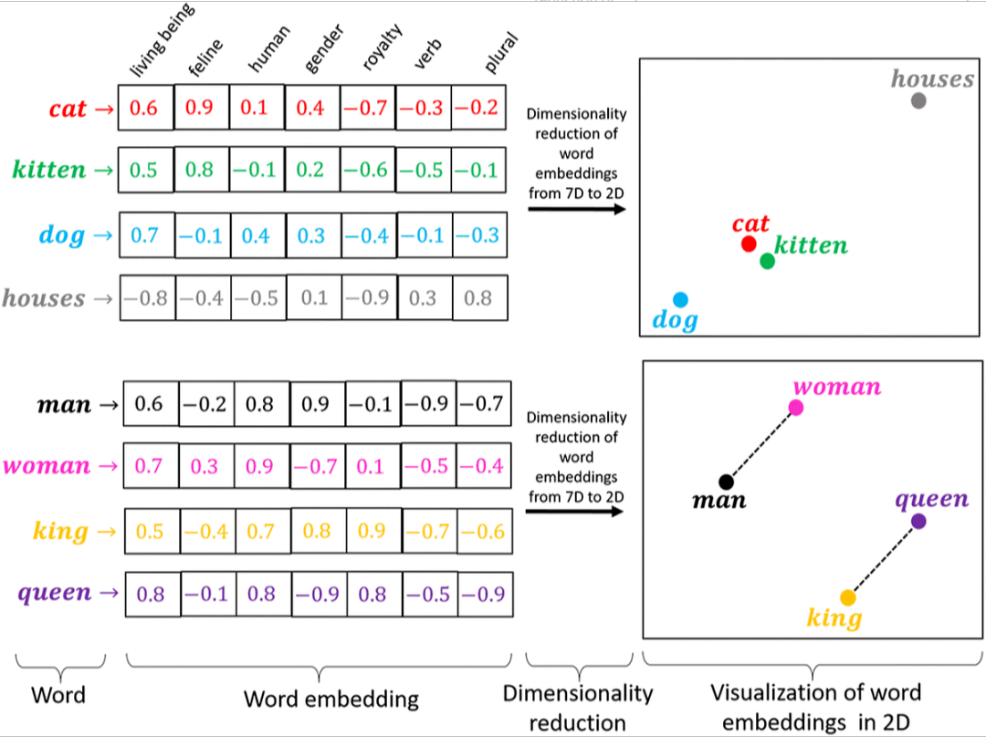
-
可以使用Word2Vec、GloVe、FastText等词嵌入算法来训练一个通用的嵌入矩阵:
-
将One-Hot编码表示的矩阵与嵌入矩阵相乘,就可以将高维稀疏的矩阵嵌入到一个低维稠密的矩阵中。
.
1.3 语言模型
语言模型:是根据已有单词,预测将出现的单词的任务。
计算将出现单词的条件概率:
P ( w n ∣ w 1 , w 2 , ⋯ , w n − 1 ) P(w_n \mid w_1, w_2, \cdots, w_{n-1}) P(wn∣w1,w2,⋯,wn−1)
计算一个词序列的联合概率:(成为一句话的概率)
P ( W ) = P ( w 1 , w 2 , ⋯ , w n ) P(W) = P(w_1, w_2, \cdots, w_n) P(W)=P(w1,w2,⋯,wn)
计算示例:

1.3.1 N-gram 模型
收集不同单词出现频率的统计数据,来预测下一个单词。
示例:4-gram
- P(wj∣ never to late to) = count( too late to wj) / count( too late to)
Markov假设:使用有限的N个单词计算概率,其他的忽略掉。
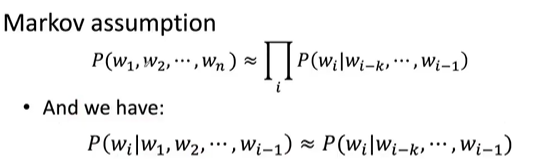
简单语言模型:
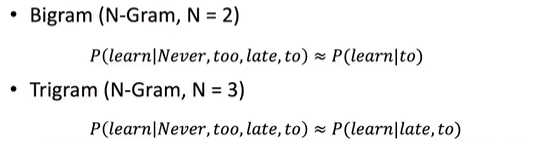
问题:
-
需要存储所有可能的n-gram计数,所以模型大小是O(exp(n))。
-
不考虑超过1、2个单词的上下文。
-
没抓住单词相似性。
1.3.2 神经语言模型(Neural Language Model)
基于神经网络来学习词的分布式表示的语言模型。
-
将单词与分布向量联系起来。
-
根据特征向量计算词序列的联合概率。
-
优化词特征向量(嵌入矩阵E)和损失函数参数(映射矩阵W)。
基本思路:
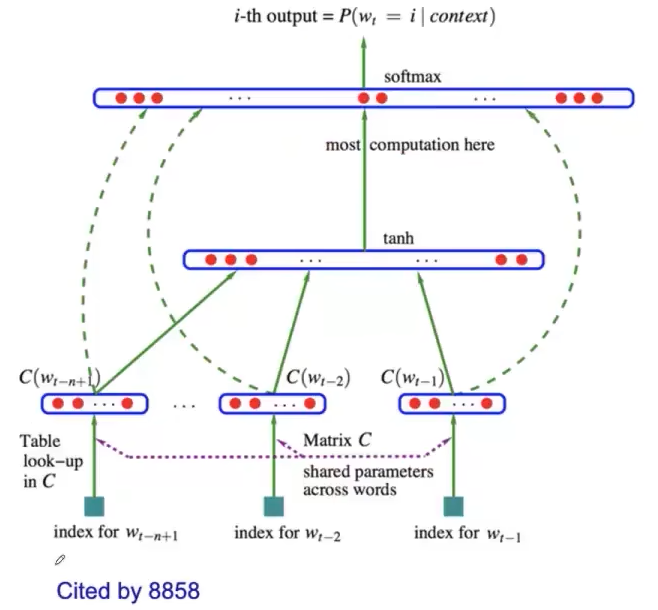
.
声明:资源可能存在第三方来源,若有侵权请联系删除!