进程3:进程切换
进程优先级
优先级跟权限的对比:
权限是决定是否具备做某事的资格,而优先级则是在进程都具备权限的情况下由于资源不足被迫对进程进行前后优先级排序让更需要的进程更好的获取资源。
进程调度:
Linux对于优先级的处理有一个很重要的方式--进程调度,通过 ps -la 指令我们可以观测到系统目前进程的相关信息:
其中PRI跟NI组成一个系统的优先级。没错,我们可以粗狂的将进程优先级看成两个整形,其最终的优先级为:PRI(新)=PRI(旧)+NI ,PRI越小,该进程优先级越高。
备注:
- UID:表示进程执行者的身份标识
- PID:表示进程的唯一代号(即进程 ID)
- PPID:表示该进程的父进程代号,也就是衍生出当前进程的进程 ID
- PRI:表示进程的执行优先级,数值越小,进程越先被执行
- NI:表示进程的 nice 值(用于调整进程优先级的参数)
NI -- nice值:
Linux下的PRI值默认为80,NI被称为nice值。虽然不推荐手动更改进程的优先级但依旧可以手动更改进程的优先级,怎么改呢?通过nice更改。
手动修改进程的优先级是通过nice值更改的,nice值也被称为优先级的修正数值。
renice <新的nice值> -p <进程PID>
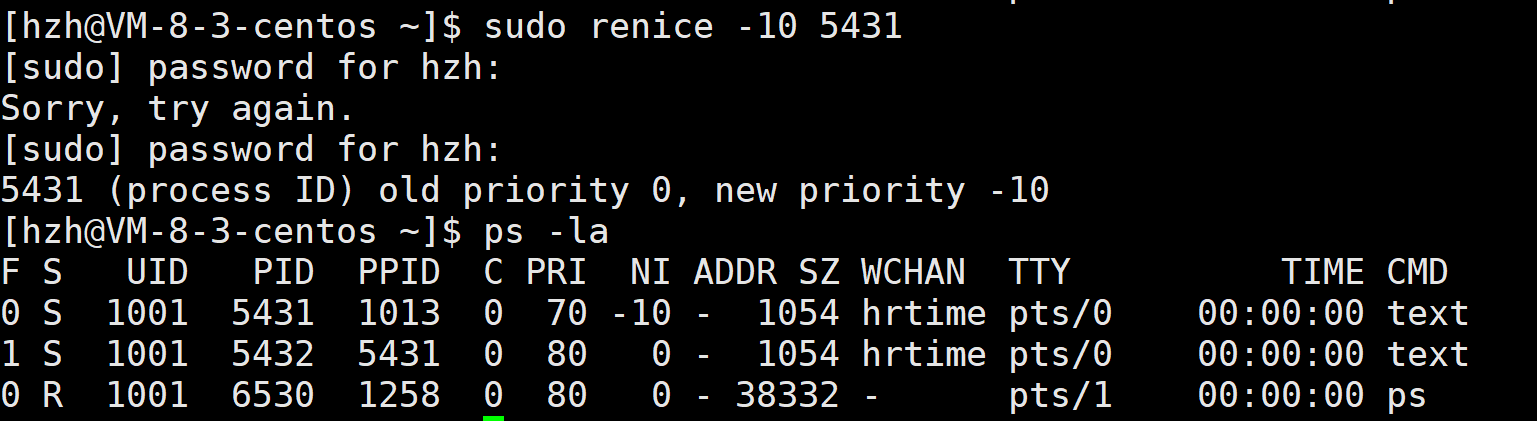
再改一下看看: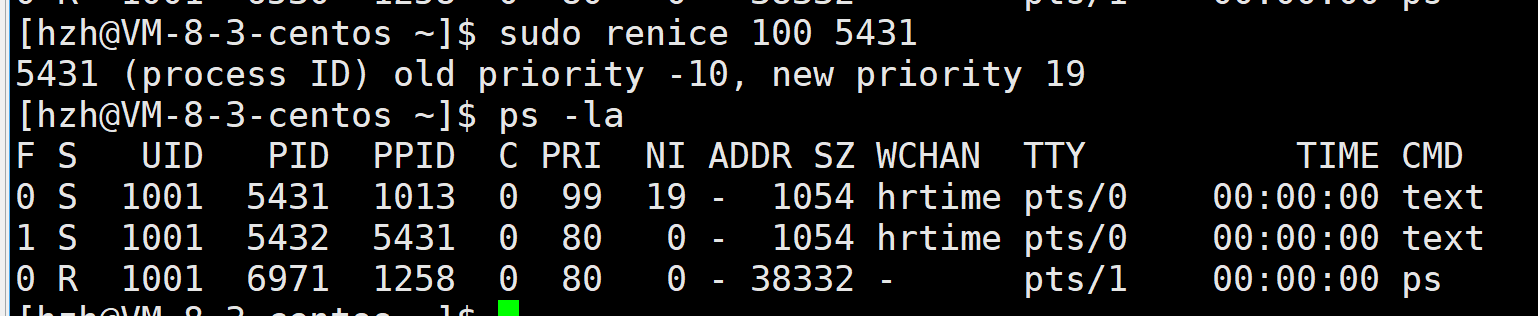
这里有两个值得注意的点:
1、我明明是将nice值改为100,为什么却只改成19。
2、好,就把nice值看成19,那PRI值怎么是99(80+19)而不是70+19=89。
解释:
1、PRI(新)=PRI(旧)+NI ,参与计算的PRI值是旧值(默认值)。
2、nice值是有一定范围的,改的范围是:-20~19 。一旦设置的nice超过这个范围就会取其靠近的界值(设为100就设为19)。
当然具体的缘由还请继续往下看。
分时操作系统:
并发:多个进程在一个CPU下以通过时间片轮转切换的方式使得在一段时间的多个进程都能推进。
并行:多个进程在多个CPU中同时进行。
实时操作系统和分时操作系统都是一种操作系统类型。分时操作系统通过时间片轮转允许多个进程轮流使用CPU资源达到多个进程并发;而实时操作系统虽然也允许进程切换,但优先保障关键任务的 “响应时效性”,延迟必须在规定范围内,其进程轮转(也就是驱动优先级调度)更加严格。
日常中的手机、电脑都是分时操作系统;实时操作系统在工业领域的应用更加广泛。
进程组织:
task_struct双链表:
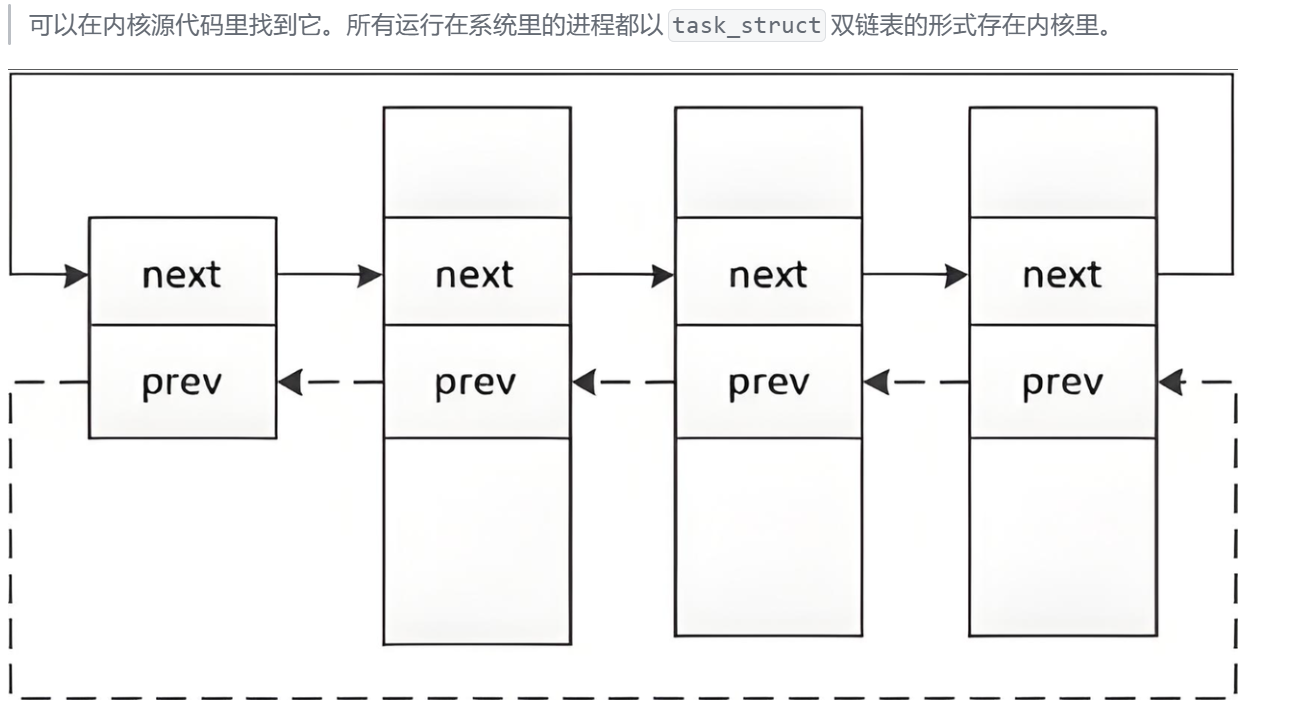
上图是Linux内核中task_struct双链表的形式,于之前学习到的双链表不同,task_struct双链表的前后指针并不是指向前后节点的起始地址,而是指向前后节点中一个 struct list_head的地址。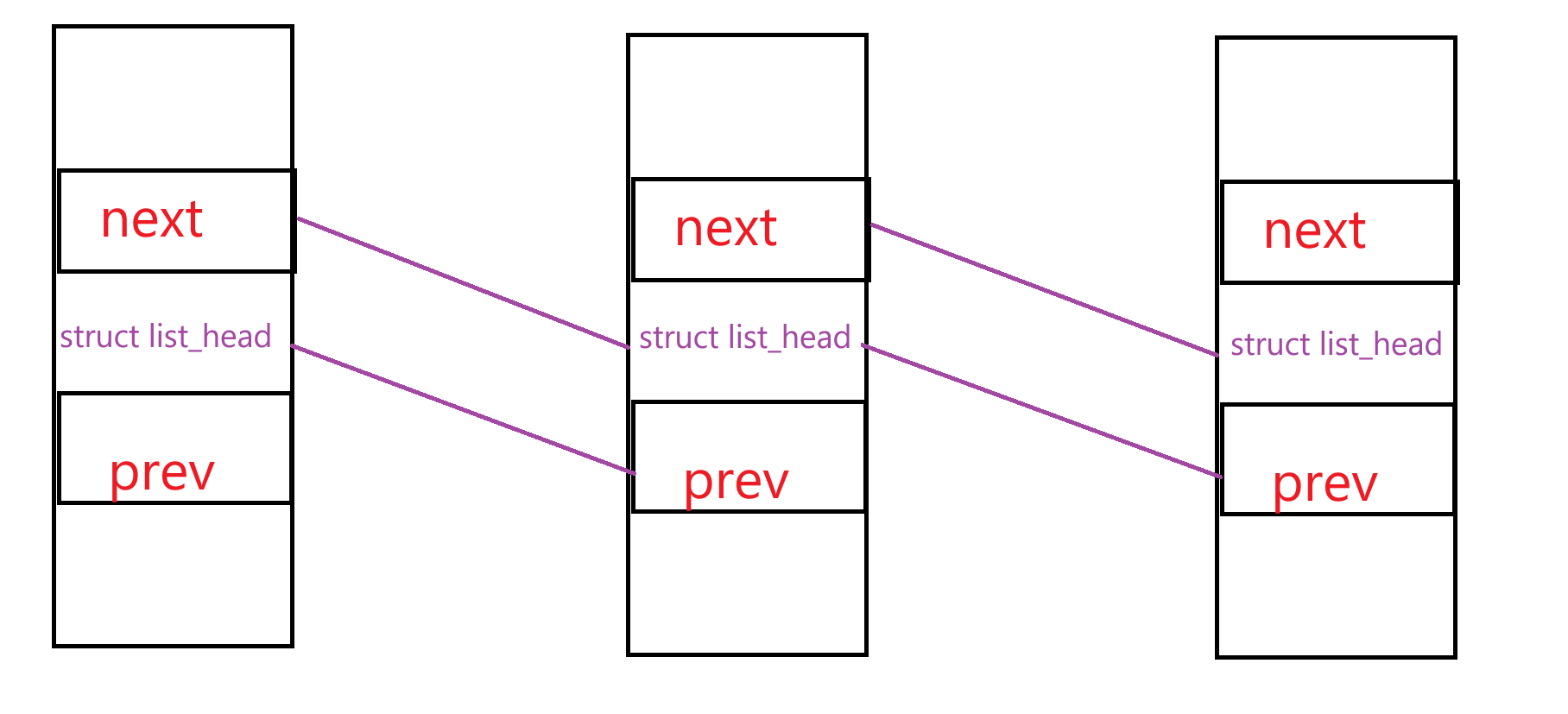
struct list_head {struct list_head *next; // 指向下一个list_head节点的指针struct list_head *prev; // 指向前一个list_head节点的指针
};那么问题来了:
1、前后指针指向前后节点的node_struct地址,那么其又该如何获取整个task_struct数据结构中的数据的
2、为什么要这样设计
解决问题1:
C语言中,一个结构体中成员地址按照成员声明顺序依次从小到大往后排列。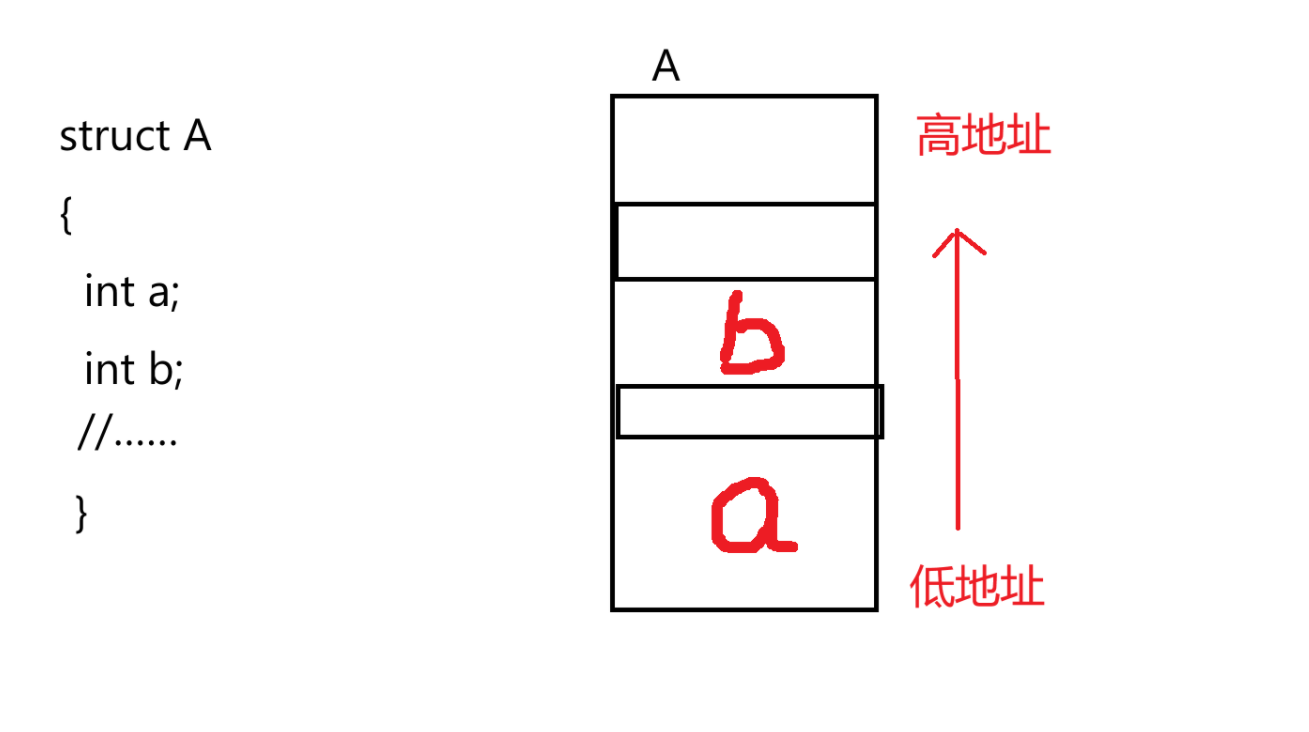
现在如果只知道b变量的地址,那又怎么求得整个结构体的地址的呢?
首先明确一点,由于C语言中无论单类型还是复合类型(数组、结构体)在内存中的存储都是一片连续的区域。其通常选最低的那一部分作为整个类型的地址。
比如 int a ;int类型变量为4个字节,其在内存中就是由4个连续的空间组成。在这4个字节中最靠前的那个字节的地址处于低地址,也取其作为整个int 类型变量a的地址。
地址的大小不是为4/8个字节大小吗, 一个字节又怎么会存下一个地址?其实就是存不下!
假设在 32 位系统中,一个 int 变量占用4 个字节,我们把这四个字节中处于最低位(也就是起始的那个)字节的地址编号作为整个变量的地址。(字节也是有地址的)
其 “地址” 的定义本质上是连续内存块的 “起始标识”,而这个起始标识必然对应整个内存块中最低的地址。
现在对于知道结构体中某一成员的地址(int b)要求得结构体的地址——也就是结构体中处于最低位的成员地址编号可以通过 已知成员地址编号 减去 该成员偏移量 求得。
结构体地址=&b-&((struct A*)0->b)上面这种写法是将0地址强转为相对应的结构体类型后获取其地址就是b成员变量的偏移量(就相当于把结构体的地址先设为0地址),再通过取到b成员的地址减去偏移量就得到结构体地址。知道了结构体地址,获取调用其它任意成员不就简简单单。
其实这就是标准库里的offsetof宏(定义在<stddef.h>)
#define offsetof(type, member) ((size_t)&((type*)0)->member)解决问题2:
再看一下list_head的结构:
struct list_head {struct list_head *next; // 指向下一个list_head节点的指针struct list_head *prev; // 指向前一个list_head节点的指针
};我们可以看到list_head设计的十分简单,这带来这些好处:通用性、灵活性、轻量化
因为设计简单,list_head不仅做到轻量化,能够容易的被多个链表使用(通用性);还能够被很轻松的跟其它数据结构结合如:前后指针指向的可以是一个其它链表,也可以是一个红黑树或其他。(灵活性)
总之,task_struct这种设计方法提高了链表的可扩展性,仅需要维护一套统一的链表操作逻辑,多进程可通过多个 list_head 成员适配不同功能链表。
CPU中的调度队列--struct_runqueue: 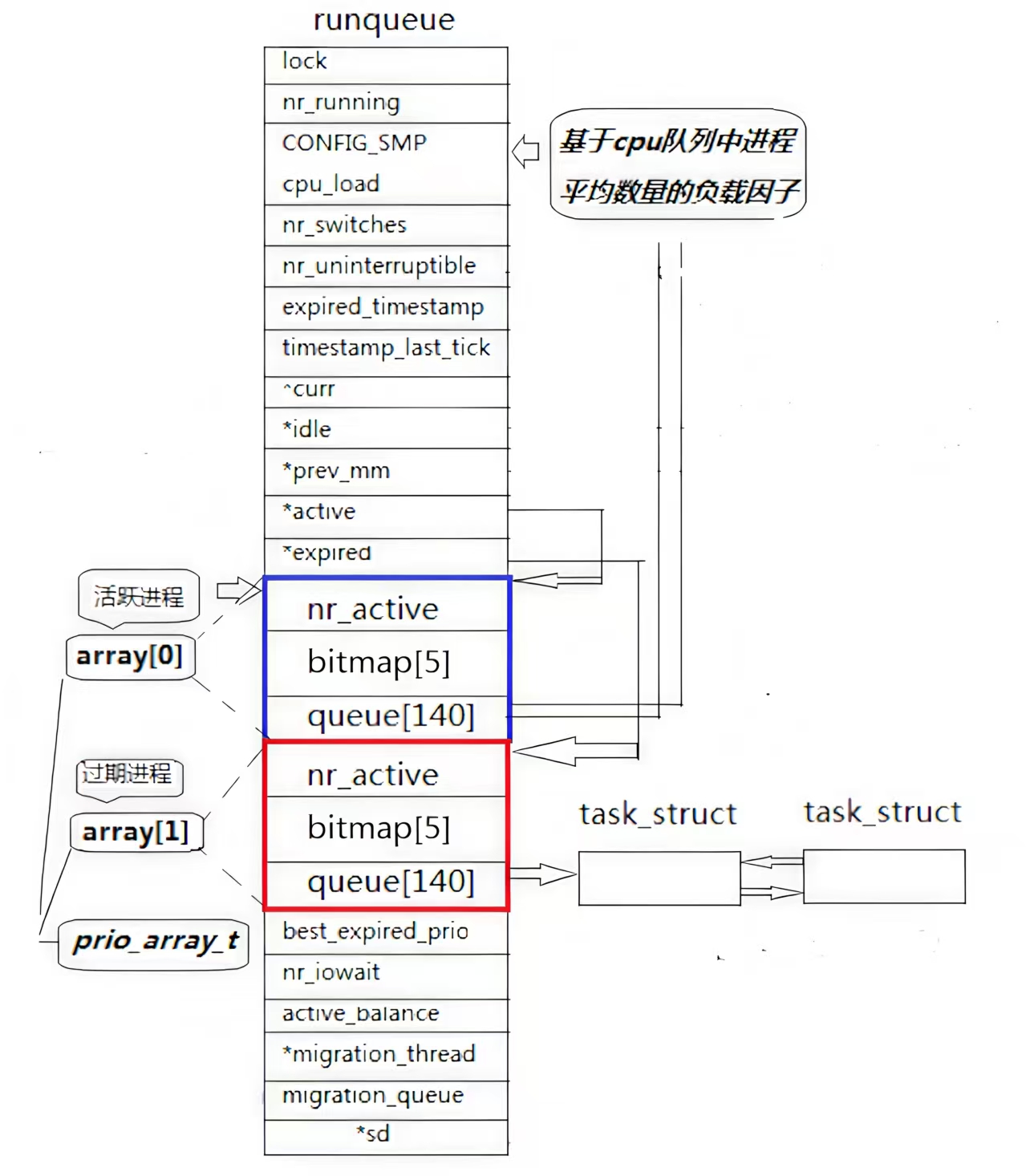
上图是Linux2.6版本内核中的struct_runqueue示意图,之前关于nice值的种种问题将在这里揭晓。
首先我们要明白struct_runqueue是干什么的,struct_runqueue是O (1) 调度器(也称为 “实时调度器”)的核心数据结构,用于管理单个 CPU 的就绪进程队列,是实现 “每个 CPU 独立调度、减少锁竞争” 的关键设计。其核心作用是维护该 CPU 上可运行的进程(就绪态),并支持高效的进程选择、优先级管理和负载均衡。
其实就是每个 CPU 专属的 “就绪进程管理工具箱”,核心能力是在 “常数时间(O (1))” 内找到并调度优先级最高的就绪进程,同时解决多 CPU(SMP)场景下的锁竞争问题(锁现在不管)
优先级数组--prio_arry_t :
优先级数组array中只有两个元素,我们只看其中一个进行解读。

struct prio_array {int nr_active; // 成员1:队列中活跃进程的总数unsigned long bitmap[5]; // 成员2:优先级位图(共140位)struct list_head queue[140]; // 成员3:按优先级分组的进程链表数组
};nr_active:该变量用于记录该队列中的进程总个数。
bitmap[5]:这个数组类型为unsigned long类型,在32位环境下具有5*4*8=160比特空间;在64位环境下具有5*8*8=320比特空间,都能够满足所需空间大于140的要求并做到浪费最小。
struct list_head queue[140]:这个数组代表了操作系统140个不同优先级数(这也是bitmap数组空间设置的依据),在这个数组中每个优先级都成为数组的下标,这样一来根据优先级选择进程就是一个哈希过程,整体的时间复杂度可以达到O(1)级别。
优先级位图--bitmap[5]:
我们已经知道具有140个不同的优先级数,可总有特殊情况如整个对列中只有优先级最低的进程存在,这时候还要把queue数组遍历一遍吗?其实不用,上面说过bitmap的空间为160比特(32位环境)/320比特(64位环境)。我们在bitmap数组中使用140个比特空间来记录各个优先级进程的存在与否,存在记为1否则为0。这样就能加速找到最高优先级的进程。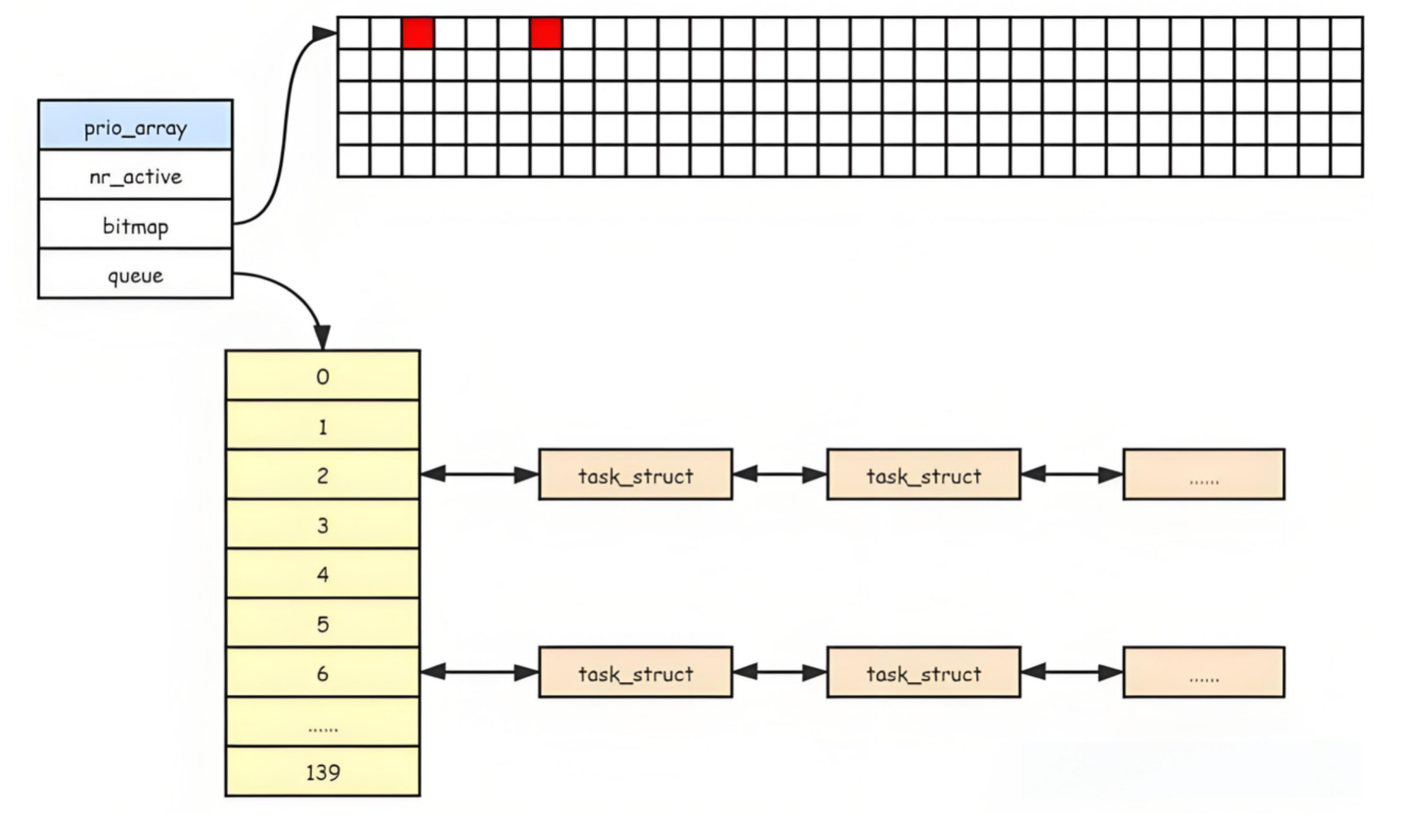
struct list_head queue[140]:
优先级调度就体现在这一数组中,0~99 优先级是 Linux 系统为实时进程(Real-Time Process) 预留的优先级范围,专门用于处理对 “响应速度” 和 “执行确定性” 要求极高的任务。这个对于初学者来说并不好搞,目前只需要了解知道这个东西,后续学习还得看后续的。
目前对于我们来说100~139才是我们必须掌握的,100~139之间有多少个数据呢,和nice值的 -20~19 一样都是40个,恍然大悟了吧~
不知道大家这时候有没有一个疑惑之前不是说 PRI(new)=PRI(old)+NI ,PRI默认为80吗,这怎么总感觉不对劲。
其实为了方便用户观测,ps、top等工具在表示优先级的时候会做出一定的调整(调整方案可能不同)。以ps为例:
实际上我们创建的进程默认优先级为120,ps就认为这个数字太大了不方便用户使用就使用PRI来代替直接的优先级表示。在nice值的协助下PRI的范围就是60~99,实际上真正的优先级为120+NI
活跃进程和过期进程: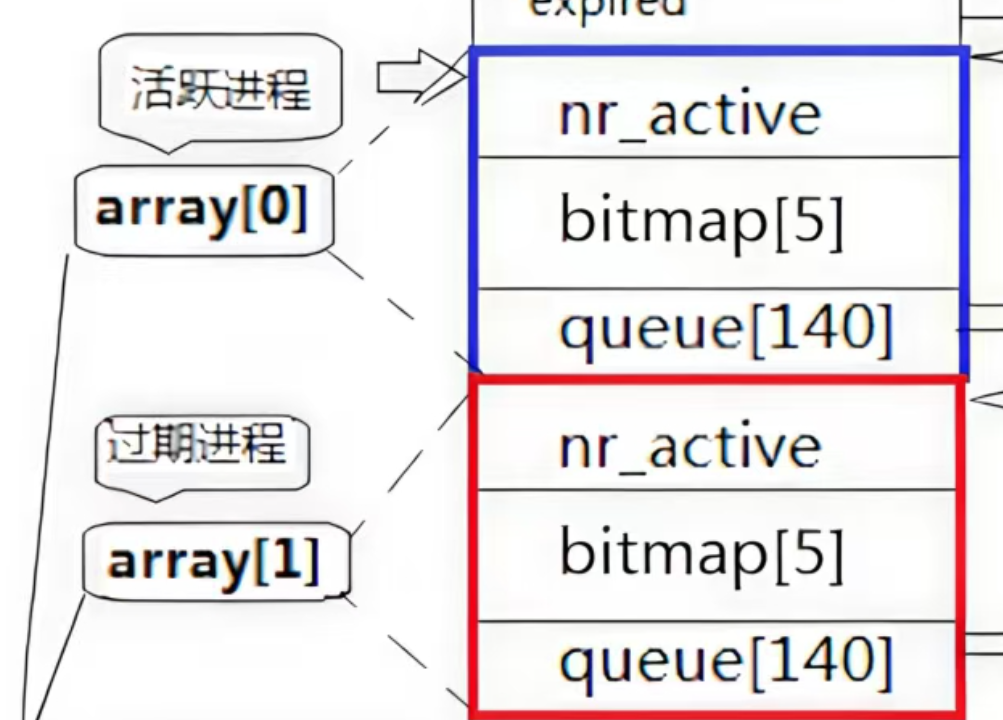
我们已经讲过了优先级数组的其中一个,我们可以把那个看成活跃进程队列,剩下的那个被称为过期进程队列。
活跃进程队列和过期进程队列的物理结构是相同的,只不过顾名思义活跃进程队列管理的是将要进入CPU的进程,而过期进程队列管理的是已经进入过CPU但是已经退出,正等待着二次进入的进程。
假设有一个A进程,A进程要进入CPU时排进活跃进程队列进行等待。等到A到达CPU但是一段时间后其工作还没完成但时间片到了被“赶出”CPU时就会进入过期进程队列进行二次等待。
待到活跃进程队列进程全部执行完,nr_active==0的时候活跃进程队列的指针会跟过期进程队列的指针发生swap交换,这样一来原本的过期进程队列又变回活跃进程队列继续按照优先级进入CPU,原本的活跃进程队列变为过期进程队列等待接受那些从CPU撤下但还未结束的进程。(有点像左手倒右手,反复横跳)
进程饥饿:
假设现在有一大堆优先级为101的进程涌入,那么就会导致优先级不如101的进程残生堆积迟迟得不到CPU的算力。
解决进程饥饿的方案:
1、Linux会将新插入的进程放入过期进程队列而不是等待队列,这样优先保障活跃进程队列的进程执行。(存在其它系统直接将新进程插入活跃队列中的情况)
2、活跃和过期进程队列的双轮换机制——就像面包只有一个,那就较为平均的分给每一个孩子(更饿的孩子优先级高,可以多吃到一些),虽然每个孩子都吃不饱但好歹都吃到了
3、优先级老化:低优先级进程 “主动升级” 抢 CPU。当一个进程长时间未得到CPU资源时系统会提高其优先级。
4、nice 值调整的权限限制:普通用户只能将自己的进程的nice值调大(更谦让,优先级降低),或在root授权下调小(优先级提升)
为什么不推荐改动进程的优先级:
1、防止引发进程饥饿
2、改动会导致进程队列的重新插入操作,效率低
3、很容易引起各种风险