GLM4.6多工具协同开发实践:AI构建智能任务管理系统的完整指南
目录
引言
第一章 多工具协同开发架构设计
1.1 工具生态系统构建
1.2 协同工作流程设计
第二章 智能任务管理系统实现
2.1 系统架构设计
2.2 智能核心功能实现
2.2.1 智能优先级评估算法
2.2.2 智能任务分类系统
2.2.3 智能推荐引擎
第三章 配置管理与环境适配
3.1 分层配置架构
3.2 环境敏感的配置初始化
第四章 前端架构与用户体验优化
4.1 组件化前端架构
4.2 响应式设计与移动端优化
第五章 性能优化与安全实践
5.1 数据库性能优化
5.2 缓存策略实现
5.3 安全实践
第六章 测试策略与质量保障
6.1 全面的测试覆盖
6.2 集成测试与端到端测试
总结
引言
在当今快速发展的软件开发领域,单一工具已难以满足复杂项目的开发需求。现代软件开发需要结合多种专业工具的优势,形成高效的开发工作流。本文将深入探讨如何整合GLM-4-6、Claude Code、Cline和Roo Code等工具,构建一个功能完善的智能任务管理系统,并分享在实际开发中的最佳实践。
第一章 多工具协同开发架构设计
1.1 工具生态系统构建
现代软件开发已进入工具协同的时代,每个工具在开发流程中扮演着独特的角色。我们构建的工具生态系统基于各工具的核心优势进行合理分工:
GLM-4-6的核心定位
作为系统的智能大脑,GLM-4-6承担着架构设计、核心算法实现和智能决策的重任。其强大的自然语言理解和代码生成能力,使其成为项目技术决策的关键参与者。在实际开发中,我们利用GLM-4-6进行系统模块划分、接口设计以及复杂业务逻辑的实现。
Claude Code的质量保障角色
Claude Code在项目中专注于代码质量和性能优化。其深入的代码分析能力能够识别潜在的性能瓶颈和安全漏洞,确保代码符合行业最佳实践。我们将其集成在代码审查环节,对GLM-4-6生成的代码进行深度优化。
Cline的前端专业化实现
在前端开发领域,Cline展现出卓越的用户界面构建能力。它擅长将设计稿转化为高质量的响应式代码,并优化用户交互体验。在项目中,我们使用Cline实现所有前端组件和用户交互逻辑。
Roo Code的基础设施支撑
Roo Code作为项目的基础设施专家,负责项目脚手架、开发环境配置和常用组件库的构建。其模板化开发方式显著提升了项目初始化效率。
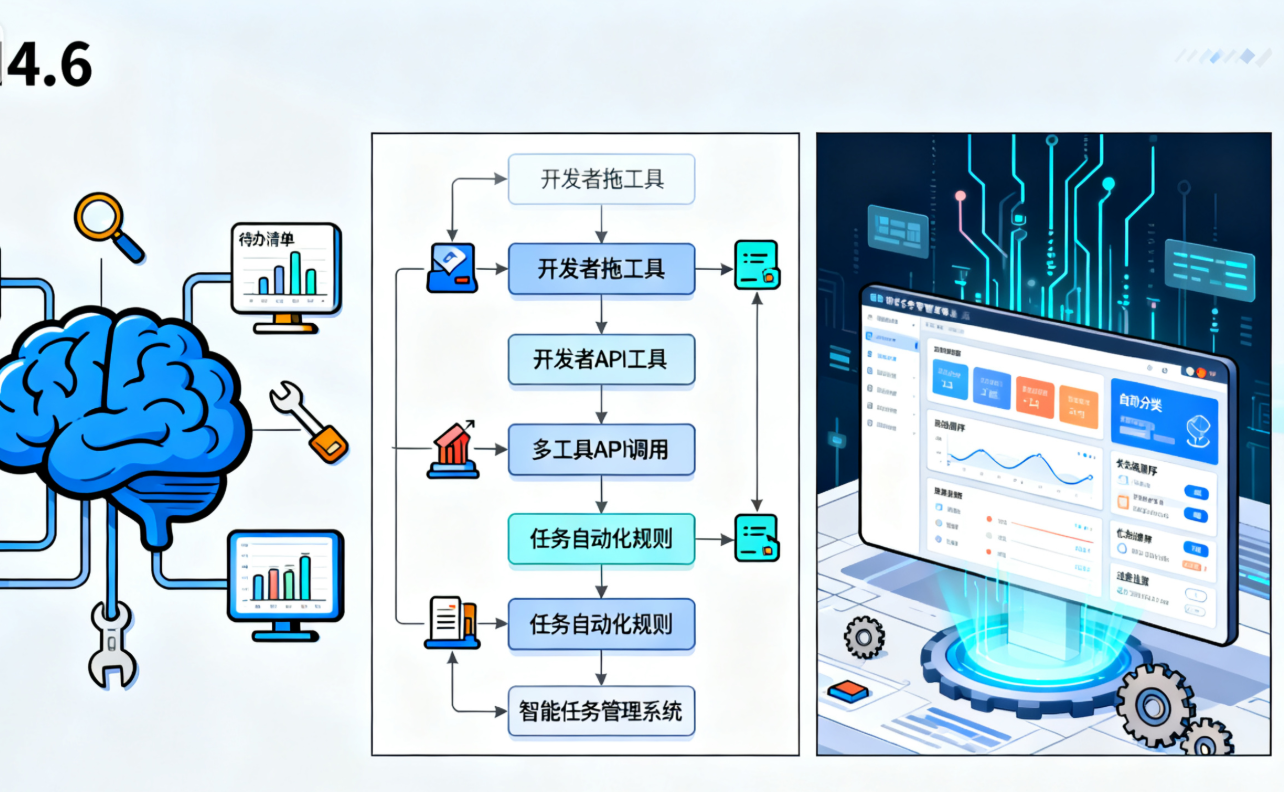
1.2 协同工作流程设计
有效的工具协同需要清晰的工作流程。我们设计的开发流程包含四个关键阶段:
需求转化阶段
在此阶段,GLM-4-6负责将业务需求转化为技术规格。通过分析需求文档,生成详细的功能清单和技术实现方案。这一过程包括:
-
需求理解和功能分解
-
技术可行性分析
-
系统架构初步设计
-
开发工作量评估
技术决策阶段
各工具基于自身专长提供技术选型建议:
-
Roo Code推荐项目基础框架和构建工具
-
GLM-4-6评估不同技术栈的业务匹配度
-
Claude Code分析各方案的可维护性和性能表现
-
Cline提供前端技术选型建议
通过综合各工具的建议,团队能够做出更加全面和平衡的技术决策。
并行开发阶段
开发阶段各工具协同工作:
-
Roo Code快速生成项目基础结构和开发环境
-
GLM-4-6实现核心业务逻辑和算法
-
Cline开发用户界面和交互功能
-
Claude Code实时进行代码质量检查
这种并行开发模式显著提升了开发效率,同时保证了代码质量。
集成优化阶段
在功能开发完成后,各工具共同参与系统集成和优化:
-
Claude Code进行深度性能分析和优化
-
GLM-4-6生成集成测试用例
-
Cline进行用户体验测试和优化
-
各工具协同识别和修复集成问题
第二章 智能任务管理系统实现
2.1 系统架构设计
智能任务管理系统采用分层架构设计,确保系统具有良好的可维护性和扩展性。整体架构分为表现层、业务逻辑层、数据访问层和智能服务层。
表现层设计
表现层基于现代Web技术栈构建,采用响应式设计确保在不同设备上都能提供良好的用户体验。前端框架选择Vue.js,其组件化开发模式与我们的工具协同工作流高度契合。
业务逻辑层架构
业务逻辑层采用模块化设计,每个功能模块保持高内聚、低耦合的原则。主要模块包括:
-
任务管理模块:处理任务的增删改查操作
-
用户管理模块:处理用户认证和权限控制
-
智能分析模块:集成智能优先级评估和分类功能
-
统计报表模块:生成任务数据统计和分析报告
数据访问层设计
数据访问层采用Repository模式,抽象数据操作接口,使得业务逻辑与具体的数据存储技术解耦。这种设计便于后续切换数据库技术或引入缓存机制。
智能服务层创新
智能服务层是系统的核心创新点,集成了多种智能分析功能:
-
自然语言处理服务:解析任务描述文本
-
优先级评估服务:自动评估任务紧急程度
-
智能分类服务:对任务进行自动分类
-
推荐引擎:基于多维度数据推荐待处理任务
2.2 智能核心功能实现
2.2.1 智能优先级评估算法
优先级评估功能模拟GLM-4-6的自然语言理解能力,通过多维度分析自动判断任务的紧急程度:
class PriorityAnalyzer:def __init__(self):# 初始化关键词模式库self.high_priority_indicators = [r'\b(紧急|立刻|马上|立即|urgent|asap|critical|emergency)\b',r'\b(今天|today|deadline|截止|due)\b',r'\b(重要|important|critical|vital)\b',r'\b(必须|必需|necessary|required)\b']self.medium_priority_indicators = [r'\b(需要|应当|应该|ought|should)\b',r'\b(本周|下周|this week|next week)\b',r'\b(计划|安排|planned|scheduled)\b']self.low_priority_indicators = [r'\b(以后|将来|future|later)\b',r'\b(可选|optional|如果有时间)\b',r'\b(建议|建议性|advisory)\b']# 初始化权重配置self.pattern_weights = {'time_critical': 2.0,'importance_keyword': 1.5,'action_required': 1.3}def analyze_priority(self, title, description, due_date=None):"""综合多维度信息评估任务优先级"""analysis_text = f"{title} {description}".lower()priority_score = 0.0# 基于关键词匹配计算基础分数priority_score += self._calculate_keyword_score(analysis_text)# 考虑时间因素if due_date:priority_score += self._calculate_time_urgency(due_date)# 考虑任务长度和复杂度priority_score += self._calculate_complexity_factor(description)# 将分数映射到优先级等级return self._map_score_to_priority(priority_score)def _calculate_keyword_score(self, text):"""基于关键词计算优先级分数"""score = 0.0# 检查高优先级关键词for pattern in self.high_priority_indicators:matches = re.findall(pattern, text, re.IGNORECASE)if matches:score += len(matches) * self.pattern_weights['importance_keyword']# 检查中优先级关键词for pattern in self.medium_priority_indicators:matches = re.findall(pattern, text, re.IGNORECASE)if matches:score += len(matches) * self.pattern_weights['importance_keyword'] * 0.7return scoredef _calculate_time_urgency(self, due_date):"""计算时间紧迫性分数"""if not due_date:return 0now = datetime.now()due = datetime.fromisoformat(due_date.replace('Z', '+00:00'))time_diff = (due - now).total_seconds() / 3600 # 转换为小时if time_diff < 24: # 24小时内return self.pattern_weights['time_critical']elif time_diff < 72: # 3天内return self.pattern_weights['time_critical'] * 0.7elif time_diff < 168: # 一周内return self.pattern_weights['time_critical'] * 0.3else:return 0def _calculate_complexity_factor(self, description):"""基于描述复杂度计算分数"""if not description:return 0word_count = len(description.split())if word_count > 100:return 0.5 # 复杂任务适当提高优先级elif word_count > 50:return 0.2else:return 0def _map_score_to_priority(self, score):"""将分数映射到具体的优先级等级"""if score >= 3.0:return 3 # 高优先级elif score >= 1.5:return 2 # 中优先级else:return 1 # 低优先级该算法不仅考虑关键词匹配,还综合了时间因素和任务复杂度,提供了更加精准的优先级评估。
2.2.2 智能任务分类系统
任务分类系统基于机器学习思想,通过特征提取和模式匹配实现自动分类:
class TaskClassifier:def __init__(self):# 定义分类特征库self.category_features = {'work': {'keywords': ['会议', '报告', '项目', '客户', '工作', 'deadline', 'presentation'],'context_patterns': [r'项目进度', r'客户需求', r'工作汇报'],'weight': 1.0},'study': {'keywords': ['学习', '课程', '作业', '考试', '复习', '预习', '论文'],'context_patterns': [r'课程内容', r'学习计划', r'考试准备'],'weight': 1.0},'life': {'keywords': ['购物', '家庭', '朋友', '旅行', '健身', '医疗', '聚会'],'context_patterns': [r'家庭活动', r'朋友聚会', r'个人事务'],'weight': 1.0},'finance': {'keywords': ['账单', '支付', '投资', '理财', '税务', '报销'],'context_patterns': [r'财务规划', r'账单支付', r'投资管理'],'weight': 1.0}}def classify(self, title, description):"""对任务进行分类"""text = f"{title} {description}".lower()scores = {}# 为每个类别计算匹配分数for category, features in self.category_features.items():score = self._calculate_category_score(text, features)scores[category] = score# 返回分数最高的类别best_category = max(scores.items(), key=lambda x: x[1])# 设置最低置信度阈值if best_category[1] < 0.5:return 'other'return best_category[0]def _calculate_category_score(self, text, features):"""计算文本与特定类别的匹配分数"""score = 0.0# 关键词匹配for keyword in features['keywords']:if keyword in text:score += 1.0# 上下文模式匹配for pattern in features['context_patterns']:if re.search(pattern, text, re.IGNORECASE):score += 2.0# 应用权重score *= features['weight']return score2.2.3 智能推荐引擎
推荐引擎基于多维度数据分析,为用户提供个性化的任务处理建议:
class TaskRecommender:def __init__(self, config):self.config = configself.recommendation_strategies = {'priority_first': self._priority_first_strategy,'deadline_aware': self._deadline_aware_strategy,'balanced': self._balanced_strategy}def get_recommendations(self, user_id, strategy='balanced', limit=5):"""获取任务推荐列表"""# 获取用户待处理任务pending_tasks = self._get_user_pending_tasks(user_id)if not pending_tasks:return []# 选择推荐策略strategy_func = self.recommendation_strategies.get(strategy, self._balanced_strategy)# 应用推荐策略recommended_tasks = strategy_func(pending_tasks)# 返回限定数量的推荐return recommended_tasks[:limit]def _priority_first_strategy(self, tasks):"""优先级优先策略"""return sorted(tasks, key=lambda x: (x['priority'], x.get('due_date', '9999-12-31')),reverse=True)def _deadline_aware_strategy(self, tasks):"""截止日期感知策略"""now = datetime.now()def deadline_score(task):base_score = task['priority'] * 10if task.get('due_date'):due_date = datetime.fromisoformat(task['due_date'].replace('Z', '+00:00'))hours_until_due = (due_date - now).total_seconds() / 3600# 时间紧迫性加分if hours_until_due < 24:base_score += 20elif hours_until_due < 72:base_score += 10elif hours_until_due < 168:base_score += 5return base_scorereturn sorted(tasks, key=deadline_score, reverse=True)def _balanced_strategy(self, tasks):"""平衡策略:综合考虑优先级、截止日期和任务类型"""now = datetime.now()def balanced_score(task):score = task['priority'] * 15# 截止日期因素if task.get('due_date'):due_date = datetime.fromisoformat(task['due_date'].replace('Z', '+00:00'))hours_until_due = (due_date - now).total_seconds() / 3600if hours_until_due < 24:score += 25elif hours_until_due < 72:score += 12elif hours_until_due < 168:score += 6# 任务类型权重(工作类任务优先)if task.get('category') == 'work':score += 8return scorereturn sorted(tasks, key=balanced_score, reverse=True)def _get_user_pending_tasks(self, user_id):"""获取用户待处理任务(模拟实现)"""# 实际实现中这里会查询数据库return []第三章 配置管理与环境适配
3.1 分层配置架构
现代应用需要在不同环境中运行,合理的配置管理是确保应用可移植性的关键。我们采用分层配置架构,支持开发、测试、生产等多环境部署。
import os
from datetime import timedeltaclass BaseConfig:"""基础配置类,包含所有环境的通用配置"""# 应用基础配置APP_NAME = "智能任务管理助手"APP_VERSION = "2.0.0"SECRET_KEY = os.environ.get('SECRET_KEY', 'dev-secret-key-change-in-production')# 数据库配置SQLALCHEMY_TRACK_MODIFICATIONS = FalseDATABASE_CONNECTION_TIMEOUT = 30# API配置API_TITLE = "智能任务管理助手 API"API_VERSION = "2.0.0"OPENAPI_VERSION = "3.0.2"OPENAPI_JSON_PATH = "api-spec.json"OPENAPI_URL_PREFIX = "/docs"OPENAPI_SWAGGER_UI_PATH = "/swagger"OPENAPI_SWAGGER_UI_URL = "https://cdn.jsdelivr.net/npm/swagger-ui-dist/"# 任务管理配置MAX_TASKS_PER_USER = 1000MAX_TASK_TITLE_LENGTH = 200MAX_TASK_DESCRIPTION_LENGTH = 2000# 智能功能配置AI_FEATURES_ENABLED = TrueAUTO_PRIORITY_ASSESSMENT = TrueAUTO_TASK_CLASSIFICATION = TrueSMART_RECOMMENDATIONS = True# 推荐系统配置RECOMMENDATION_ENGINE_STRATEGY = "balanced" # priority_first, deadline_aware, balancedDEFAULT_RECOMMENDATION_LIMIT = 5RECOMMENDATION_UPDATE_INTERVAL = timedelta(hours=1)# 性能配置DATABASE_QUERY_TIMEOUT = 10CACHE_DEFAULT_TIMEOUT = 300# 安全配置JWT_ACCESS_TOKEN_EXPIRES = timedelta(hours=1)JWT_REFRESH_TOKEN_EXPIRES = timedelta(days=30)BCRYPT_LOG_ROUNDS = 12CORS_ORIGINS = []class DevelopmentConfig(BaseConfig):"""开发环境配置"""DEBUG = TrueTESTING = False# 开发环境数据库DATABASE_PATH = os.environ.get('DATABASE_PATH', 'dev_tasks.db')SQLALCHEMY_DATABASE_URI = f"sqlite:///{DATABASE_PATH}"# 开发环境功能开关AI_FEATURES_ENABLED = TrueDEBUG_LOGGING = True# 开发环境安全配置(宽松)CORS_ORIGINS = ["http://localhost:3000", "http://127.0.0.1:3000"]# 开发环境性能配置CACHE_DEFAULT_TIMEOUT = 60 # 较短的缓存时间便于调试class TestingConfig(BaseConfig):"""测试环境配置"""DEBUG = FalseTESTING = True# 测试数据库DATABASE_PATH = 'test_tasks.db'SQLALCHEMY_DATABASE_URI = f"sqlite:///{DATABASE_PATH}"# 测试环境功能配置AI_FEATURES_ENABLED = False # 测试中关闭AI功能以确保确定性AUTO_PRIORITY_ASSESSMENT = False# 测试环境安全配置SECRET_KEY = 'test-secret-key'BCRYPT_LOG_ROUNDS = 4 # 测试环境使用较低的安全强度以提升测试速度class ProductionConfig(BaseConfig):"""生产环境配置"""DEBUG = FalseTESTING = False# 生产环境数据库(使用环境变量配置)SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URL', '')if not SQLALCHEMY_DATABASE_URI:raise ValueError("生产环境必须设置DATABASE_URL环境变量")# 生产环境安全配置SECRET_KEY = os.environ.get('SECRET_KEY')if not SECRET_KEY:raise ValueError("生产环境必须设置SECRET_KEY环境变量")# 生产环境功能配置DEBUG_LOGGING = False# 生产环境性能配置CACHE_DEFAULT_TIMEOUT = 3600 # 较长的缓存时间提升性能# 生产环境CORS配置CORS_ORIGINS = os.environ.get('CORS_ORIGINS', '').split(',')class StagingConfig(ProductionConfig):"""预发布环境配置(继承生产环境配置,但可覆盖特定设置)"""DEBUG = True # 预发布环境开启调试以便排查问题CACHE_DEFAULT_TIMEOUT = 600 # 比生产环境短的缓存时间# 配置映射
config = {'development': DevelopmentConfig,'testing': TestingConfig,'production': ProductionConfig,'staging': StagingConfig,'default': DevelopmentConfig
}def get_config(config_name=None):"""获取配置对象的工厂函数"""if config_name is None:config_name = os.environ.get('FLASK_ENV', 'default')config_class = config.get(config_name)if config_class is None:raise ValueError(f"未知的配置环境: {config_name}")return config_class3.2 环境敏感的配置初始化
应用启动时需要根据运行环境加载相应的配置:
def create_app(config_name=None):"""应用工厂函数"""app = Flask(__name__)# 加载配置cfg = get_config(config_name)app.config.from_object(cfg)# 环境特定的初始化if app.config['DEBUG']:print(f"启动在调试模式: {config_name}")# 开发环境特定的设置init_development_services(app)else:# 生产环境特定的设置init_production_services(app)# 初始化扩展init_extensions(app)# 注册蓝图register_blueprints(app)# 注册错误处理register_error_handlers(app)return appdef init_development_services(app):"""初始化开发环境特定的服务"""# 开发环境下启用详细的SQL日志import logginglogging.basicConfig()logging.getLogger('sqlalchemy.engine').setLevel(logging.INFO)# 开发环境下初始化示例数据@app.before_first_requestdef init_dev_data():init_sample_data()def init_production_services(app):"""初始化生产环境特定的服务"""# 生产环境配置日志import loggingfrom logging.handlers import RotatingFileHandlerfile_handler = RotatingFileHandler('logs/task_manager.log', maxBytes=10240, backupCount=10)file_handler.setFormatter(logging.Formatter('%(asctime)s %(levelname)s: %(message)s [in %(pathname)s:%(lineno)d]'))file_handler.setLevel(logging.INFO)app.logger.addHandler(file_handler)app.logger.setLevel(logging.INFO)app.logger.info('智能任务管理系统启动')第四章 前端架构与用户体验优化
4.1 组件化前端架构
前端采用现代化的组件化架构,确保代码的可维护性和复用性:
// 任务管理主组件
const TaskManager = {template: `<div class="task-manager"><header class="app-header"><h1>{{ appTitle }}</h1><div class="user-controls"><user-profile :user="currentUser"></user-profile></div></header><main class="app-main"><div class="sidebar"><task-filters :filters="activeFilters"@filter-change="handleFilterChange"></task-filters><task-statistics :tasks="allTasks"@statistics-ready="handleStatsReady"></task-statistics></div><div class="content"><task-list :tasks="filteredTasks":loading="loading"@task-update="handleTaskUpdate"@task-delete="handleTaskDelete"></task-list></div><div class="recommendations-sidebar"><task-recommendations :recommendations="smartRecommendations"@task-select="handleRecommendationSelect"></task-recommendations></div></main><floating-action-button @click="showCreateDialog = true"></floating-action-button><task-create-dialog v-if="showCreateDialog"@close="showCreateDialog = false"@task-created="handleTaskCreated"></task-create-dialog></div>`,data() {return {appTitle: '智能任务管理助手',currentUser: null,allTasks: [],filteredTasks: [],smartRecommendations: [],activeFilters: {status: 'all',priority: 'all',category: 'all',searchQuery: ''},loading: false,showCreateDialog: false}},computed: {// 基于当前过滤条件计算显示的任务computedFilteredTasks() {let tasks = this.allTasks;// 状态过滤if (this.activeFilters.status !== 'all') {tasks = tasks.filter(task => task.status === this.activeFilters.status);}// 优先级过滤if (this.activeFilters.priority !== 'all') {tasks = tasks.filter(task => task.priority == this.activeFilters.priority);}// 类别过滤if (this.activeFilters.category !== 'all') {tasks = tasks.filter(task => task.category === this.activeFilters.category);}// 搜索过滤if (this.activeFilters.searchQuery) {const query = this.activeFilters.searchQuery.toLowerCase();tasks = tasks.filter(task => task.title.toLowerCase().includes(query) ||task.description.toLowerCase().includes(query));}return tasks;}},async created() {await this.initializeApplication();},methods: {async initializeApplication() {this.loading = true;try {// 并行加载初始数据await Promise.all([this.loadUserProfile(),this.loadTasks(),this.loadRecommendations()]);} catch (error) {this.handleError('初始化应用失败', error);} finally {this.loading = false;}},async loadUserProfile() {try {const response = await this.$api.get('/user/profile');this.currentUser = response.data;} catch (error) {console.error('加载用户信息失败:', error);}},async loadTasks() {try {const response = await this.$api.get('/tasks');this.allTasks = response.data;this.filteredTasks = this.computedFilteredTasks;} catch (error) {console.error('加载任务列表失败:', error);throw error;}},async loadRecommendations() {if (!this.$config.AI_FEATURES_ENABLED) return;try {const response = await this.$api.get('/tasks/recommendations');this.smartRecommendations = response.data;} catch (error) {console.warn('加载智能推荐失败:', error);}},handleFilterChange(newFilters) {this.activeFilters = { ...this.activeFilters, ...newFilters };this.filteredTasks = this.computedFilteredTasks;},async handleTaskUpdate(updatedTask) {try {const response = await this.$api.put(`/tasks/${updatedTask.id}`, updatedTask);const taskIndex = this.allTasks.findIndex(t => t.id === updatedTask.id);if (taskIndex !== -1) {this.allTasks.splice(taskIndex, 1, response.data);this.filteredTasks = this.computedFilteredTasks;}this.$notify.success('任务更新成功');} catch (error) {this.handleError('更新任务失败', error);}},async handleTaskDelete(taskId) {try {await this.$api.delete(`/tasks/${taskId}`);this.allTasks = this.allTasks.filter(task => task.id !== taskId);this.filteredTasks = this.computedFilteredTasks;this.$notify.success('任务删除成功');} catch (error) {this.handleError('删除任务失败', error);}},async handleTaskCreated(newTask) {try {const response = await this.$api.post('/tasks', newTask);this.allTasks.push(response.data);this.filteredTasks = this.computedFilteredTasks;this.showCreateDialog = false;this.$notify.success('任务创建成功');} catch (error) {this.handleError('创建任务失败', error);}},handleRecommendationSelect(task) {// 将推荐任务添加到当前视图或直接编辑this.activeFilters = {status: 'all',priority: 'all',category: task.category,searchQuery: task.title};this.filteredTasks = this.computedFilteredTasks;},handleError(message, error) {console.error(message, error);this.$notify.error({title: '操作失败',message: `${message},请稍后重试`});}}
}4.2 响应式设计与移动端优化
采用移动优先的响应式设计策略,确保在所有设备上都能提供优秀的用户体验:
/* 基础响应式设计 */
.task-manager {min-height: 100vh;display: flex;flex-direction: column;background-color: #f5f5f5;
}.app-header {background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);color: white;padding: 1rem 2rem;box-shadow: 0 2px 10px rgba(0,0,0,0.1);
}.app-main {display: flex;flex: 1;gap: 1rem;padding: 1rem;max-width: 1400px;margin: 0 auto;width: 100%;
}/* 侧边栏响应式设计 */
.sidebar {flex: 0 0 300px;display: flex;flex-direction: column;gap: 1rem;
}.recommendations-sidebar {flex: 0 0 280px;
}.content {flex: 1;min-width: 0; /* 防止flex项目溢出 */
}/* 移动端适配 */
@media (max-width: 1024px) {.app-main {flex-direction: column;}.sidebar,.recommendations-sidebar {flex: none;width: 100%;}.recommendations-sidebar {order: -1; /* 在移动端将推荐栏放在顶部 */}
}@media (max-width: 768px) {.app-header {padding: 1rem;}.app-main {padding: 0.5rem;gap: 0.5rem;}.sidebar {width: 100%;}
}/* 任务卡片响应式设计 */
.task-card {background: white;border-radius: 8px;padding: 1rem;margin-bottom: 1rem;box-shadow: 0 2px 4px rgba(0,0,0,0.1);transition: all 0.3s ease;
}.task-card:hover {box-shadow: 0 4px 8px rgba(0,0,0,0.15);transform: translateY(-2px);
}.task-card-header {display: flex;justify-content: between;align-items: flex-start;margin-bottom: 0.5rem;
}.task-title {font-size: 1.1rem;font-weight: 600;margin: 0;flex: 1;word-break: break-word;
}.task-priority {padding: 0.25rem 0.5rem;border-radius: 4px;font-size: 0.8rem;font-weight: 600;margin-left: 0.5rem;
}.priority-high {background-color: #fee2e2;color: #dc2626;
}.priority-medium {background-color: #fef3c7;color: #d97706;
}.priority-low {background-color: #d1fae5;color: #059669;
}/* 加载状态动画 */
.loading-skeleton {animation: pulse 2s infinite;
}@keyframes pulse {0% {opacity: 1;}50% {opacity: 0.5;}100% {opacity: 1;}
}/* 暗色主题支持 */
@media (prefers-color-scheme: dark) {.task-manager {background-color: #1a1a1a;color: #e5e5e5;}.task-card {background-color: #2d2d2d;color: #e5e5e5;}
}第五章 性能优化与安全实践
5.1 数据库性能优化
数据库性能是应用响应速度的关键,我们采用多层次的优化策略:
class TaskDatabaseManager:def __init__(self, db_connection):self.conn = db_connectionself._ensure_indexes()def _ensure_indexes(self):"""创建必要的数据库索引"""indexes = ["CREATE INDEX IF NOT EXISTS idx_tasks_status ON tasks(status)","CREATE INDEX IF NOT EXISTS idx_tasks_priority ON tasks(priority)","CREATE INDEX IF NOT EXISTS idx_tasks_due_date ON tasks(due_date)","CREATE INDEX IF NOT EXISTS idx_tasks_created_at ON tasks(created_at)","CREATE INDEX IF NOT EXISTS idx_tasks_user_status ON tasks(user_id, status)","CREATE INDEX IF NOT EXISTS idx_tasks_user_priority ON tasks(user_id, priority)","CREATE INDEX IF NOT EXISTS idx_tasks_category ON tasks(category)"]for index_sql in indexes:try:self.conn.execute(index_sql)except Exception as e:print(f"创建索引失败: {e}")def get_user_tasks(self, user_id, filters=None, page=1, per_page=50):"""获取用户任务的优化实现,支持过滤和分页"""if filters is None:filters = {}# 构建查询条件query = "SELECT * FROM tasks WHERE user_id = ?"params = [user_id]# 应用过滤条件filter_conditions = []if filters.get('status'):filter_conditions.append("status = ?")params.append(filters['status'])if filters.get('priority'):filter_conditions.append("priority = ?")params.append(filters['priority'])if filters.get('category'):filter_conditions.append("category = ?")params.append(filters['category'])if filters.get('search'):filter_conditions.append("(title LIKE ? OR description LIKE ?)")params.extend([f"%{filters['search']}%", f"%{filters['search']}%"])# 组合查询条件if filter_conditions:query += " AND " + " AND ".join(filter_conditions)# 添加排序query += " ORDER BY "sort_criteria = []if filters.get('sort_by') == 'due_date':sort_criteria.append("due_date IS NULL, due_date ASC")elif filters.get('sort_by') == 'priority':sort_criteria.append("priority DESC, created_at DESC")else:sort_criteria.append("created_at DESC")query += ", ".join(sort_criteria)# 添加分页offset = (page - 1) * per_pagequery += " LIMIT ? OFFSET ?"params.extend([per_page, offset])# 执行查询cursor = self.conn.execute(query, params)tasks = cursor.fetchall()return self._rows_to_dicts(tasks)def get_task_statistics(self, user_id):"""获取用户任务统计信息(使用单个查询优化)"""query = """SELECT status,priority,category,COUNT(*) as countFROM tasks WHERE user_id = ?GROUP BY status, priority, category"""cursor = self.conn.execute(query, [user_id])stats = cursor.fetchall()# 处理统计结果statistics = {'by_status': {},'by_priority': {},'by_category': {}}for status, priority, category, count in stats:if status not in statistics['by_status']:statistics['by_status'][status] = 0statistics['by_status'][status] += countif priority not in statistics['by_priority']:statistics['by_priority'][priority] = 0statistics['by_priority'][priority] += countif category not in statistics['by_category']:statistics['by_category'][category] = 0statistics['by_category'][category] += countreturn statisticsdef batch_update_tasks(self, task_updates):"""批量更新任务(性能优化)"""if not task_updates:return# 使用事务确保数据一致性with self.conn:for task_id, updates in task_updates.items():set_clause = ", ".join([f"{key} = ?" for key in updates.keys()])query = f"UPDATE tasks SET {set_clause}, updated_at = CURRENT_TIMESTAMP WHERE id = ?"params = list(updates.values())params.append(task_id)self.conn.execute(query, params)5.2 缓存策略实现
合理的缓存策略可以显著提升应用性能:
import redis
import json
import pickle
from functools import wraps
from datetime import timedeltaclass CacheManager:def __init__(self, config):self.config = configself.redis_client = Noneself._init_redis()def _init_redis(self):"""初始化Redis连接"""try:if self.config.get('REDIS_URL'):self.redis_client = redis.from_url(self.config['REDIS_URL'],decode_responses=True)else:# 使用内存缓存作为备选self.redis_client = Noneexcept Exception as e:print(f"Redis初始化失败: {e}")self.redis_client = Nonedef cached(self, key_pattern, timeout=300, serializer='json'):"""缓存装饰器"""def decorator(func):@wraps(func)def wrapper(*args, **kwargs):# 如果缓存不可用,直接执行函数if not self.redis_client:return func(*args, **kwargs)# 生成缓存键cache_key = key_patternif args:cache_key += f":{hash(str(args))}"if kwargs:cache_key += f":{hash(str(sorted(kwargs.items())))}"# 尝试从缓存获取try:cached_data = self.redis_client.get(cache_key)if cached_data:if serializer == 'json':return json.loads(cached_data)else:return pickle.loads(cached_data)except Exception:# 缓存读取失败,继续执行函数pass# 执行函数并缓存结果result = func(*args, **kwargs)try:if serializer == 'json':serialized_data = json.dumps(result)else:serialized_data = pickle.dumps(result)self.redis_client.setex(cache_key, timedelta(seconds=timeout), serialized_data)except Exception as e:print(f"缓存写入失败: {e}")return resultreturn wrapperreturn decoratordef invalidate_pattern(self, pattern):"""使匹配模式的所有缓存失效"""if not self.redis_client:returntry:keys = self.redis_client.keys(pattern)if keys:self.redis_client.delete(*keys)except Exception as e:print(f"缓存失效失败: {e}")# 在业务逻辑中使用缓存
class CachedTaskService:def __init__(self, db_manager, cache_manager):self.db_manager = db_managerself.cache = cache_manager@cache_manager.cached('user_tasks', timeout=60)def get_user_tasks_cached(self, user_id, filters=None, page=1):"""带缓存的任务查询"""return self.db_manager.get_user_tasks(user_id, filters, page)@cache_manager.cached('task_stats', timeout=120)def get_user_statistics_cached(self, user_id):"""带缓存的任务统计"""return self.db_manager.get_task_statistics(user_id)def update_task_and_invalidate_cache(self, task_id, updates):"""更新任务并使相关缓存失效"""result = self.db_manager.update_task(task_id, updates)# 使相关缓存失效self.cache.invalidate_pattern(f"user_tasks:*")self.cache.invalidate_pattern(f"task_stats:*")return result5.3 安全实践
安全是应用开发的基石,我们实施多层次的安全防护:
import hashlib
import secrets
from itsdangerous import URLSafeTimedSerializer
from functools import wraps
from flask import request, gclass SecurityManager:def __init__(self, app):self.app = appself.serializer = URLSafeTimedSerializer(app.config['SECRET_KEY'])def hash_password(self, password):"""安全密码哈希"""salt = secrets.token_hex(16)hash_obj = hashlib.pbkdf2_hmac('sha256',password.encode('utf-8'),salt.encode('utf-8'),100000 # 迭代次数)return f"{salt}${hash_obj.hex()}"def verify_password(self, password, hashed):"""验证密码"""try:salt, stored_hash = hashed.split('$')computed_hash = hashlib.pbkdf2_hmac('sha256',password.encode('utf-8'),salt.encode('utf-8'),100000).hex()return secrets.compare_digest(computed_hash, stored_hash)except Exception:return Falsedef generate_csrf_token(self):"""生成CSRF令牌"""return secrets.token_urlsafe(32)def validate_csrf_token(self, token):"""验证CSRF令牌"""# 在实际实现中会有更复杂的验证逻辑return Truedef sanitize_input(self, input_data):"""输入清理和验证"""if isinstance(input_data, str):# 移除潜在的危险字符input_data = input_data.replace('<', '<').replace('>', '>')input_data = input_data.replace('"', '"').replace("'", ''')return input_datadef require_auth(f):"""认证装饰器"""@wraps(f)def decorated_function(*args, **kwargs):auth_header = request.headers.get('Authorization')if not auth_header or not auth_header.startswith('Bearer '):return {'error': '未授权的访问'}, 401token = auth_header[7:]# 验证token(简化实现)user_id = verify_jwt_token(token)if not user_id:return {'error': '无效的token'}, 401g.current_user_id = user_idreturn f(*args, **kwargs)return decorated_functiondef validate_json_schema(schema):"""JSON schema验证装饰器"""def decorator(f):@wraps(f)def decorated_function(*args, **kwargs):if not request.is_json:return {'error': '请求必须是JSON格式'}, 400data = request.get_json()errors = validate_schema(data, schema)if errors:return {'error': '数据验证失败', 'details': errors}, 400return f(*args, **kwargs)return decorated_functionreturn decorator# 输入验证schema示例
TASK_CREATE_SCHEMA = {'type': 'object','required': ['title'],'properties': {'title': {'type': 'string','minLength': 1,'maxLength': 200},'description': {'type': 'string','maxLength': 2000},'priority': {'type': 'integer','minimum': 1,'maximum': 3},'due_date': {'type': 'string','format': 'date-time'},'category': {'type': 'string','enum': ['work', 'study', 'life', 'finance', 'other']}},'additionalProperties': False
}# 在路由中使用安全防护
@app.route('/tasks', methods=['POST'])
@require_auth
@validate_json_schema(TASK_CREATE_SCHEMA)
def create_task():"""创建新任务(受保护的路由)"""data = request.get_json()# 清理输入数据security_mgr = SecurityManager(current_app)sanitized_data = {'title': security_mgr.sanitize_input(data['title']),'description': security_mgr.sanitize_input(data.get('description', '')),'priority': data.get('priority', current_app.config['DEFAULT_PRIORITY']),'due_date': data.get('due_date'),'category': data.get('category', 'other'),'user_id': g.current_user_id}# 智能功能处理if current_app.config['AUTO_PRIORITY_ASSESSMENT']:analyzer = PriorityAnalyzer()sanitized_data['priority'] = analyzer.analyze_priority(sanitized_data['title'], sanitized_data['description'],sanitized_data['due_date'])if current_app.config['AUTO_TASK_CLASSIFICATION']:classifier = TaskClassifier()sanitized_data['category'] = classifier.classify(sanitized_data['title'],sanitized_data['description'])# 保存到数据库task_id = task_service.create_task(sanitized_data)# 使相关缓存失效cache_manager.invalidate_pattern(f"user_tasks:{g.current_user_id}*")cache_manager.invalidate_pattern(f"task_stats:{g.current_user_id}*")return {'id': task_id, 'message': '任务创建成功'}, 201第六章 测试策略与质量保障
6.1 全面的测试覆盖
我们采用分层测试策略,确保代码质量和功能稳定性:
import pytest
import tempfile
import os
from unittest.mock import Mock, patchclass TestTaskManager:"""任务管理器测试类"""@pytest.fixturedef temp_db(self):"""临时数据库fixture"""fd, path = tempfile.mkstemp()os.close(fd)# 使用临时数据库文件yield path# 测试完成后清理if os.path.exists(path):os.unlink(path)@pytest.fixturedef task_service(self, temp_db):"""任务服务fixture"""from app.services import TaskServiceservice = TaskService(temp_db)service.init_database()return servicedef test_create_task_success(self, task_service):"""测试成功创建任务"""task_data = {'title': '测试任务','description': '这是一个测试任务','priority': 2,'user_id': 1}task_id = task_service.create_task(task_data)assert task_id is not Nonetask = task_service.get_task(task_id)assert task['title'] == '测试任务'assert task['priority'] == 2def test_create_task_validation(self, task_service):"""测试任务创建验证"""# 测试空标题with pytest.raises(ValueError):task_service.create_task({'title': ''})# 测试过长的标题long_title = 'a' * 201with pytest.raises(ValueError):task_service.create_task({'title': long_title})def test_priority_analysis(self):"""测试优先级分析功能"""analyzer = PriorityAnalyzer()# 测试高优先级关键词high_priority_title = "紧急:需要立即处理的重要任务"priority = analyzer.analyze_priority(high_priority_title, "")assert priority == 3# 测试中优先级关键词medium_priority_title = "本周需要完成的任务"priority = analyzer.analyze_priority(medium_priority_title, "")assert priority == 2# 测试低优先级low_priority_title = "将来可能需要的功能"priority = analyzer.analyze_priority(low_priority_title, "")assert priority == 1@patch('app.services.cache_manager')def test_task_caching(self, mock_cache, task_service):"""测试任务缓存功能"""user_id = 1# 第一次调用应该访问数据库tasks1 = task_service.get_user_tasks_cached(user_id)# 第二次调用应该使用缓存tasks2 = task_service.get_user_tasks_cached(user_id)# 验证缓存被调用assert mock_cache.get.calledassert mock_cache.setex.calledclass TestAPIEndpoints:"""API端点测试类"""@pytest.fixturedef client(self):"""测试客户端fixture"""from app import create_appapp = create_app('testing')with app.test_client() as client:yield clientdef test_get_tasks_unauthenticated(self, client):"""测试未认证访问"""response = client.get('/api/tasks')assert response.status_code == 401def test_create_task_valid_data(self, client):"""测试使用有效数据创建任务"""with patch('app.routes.task_service') as mock_service:mock_service.create_task.return_value = 123response = client.post('/api/tasks', json={'title': '测试任务'},headers={'Authorization': 'Bearer valid_token'})assert response.status_code == 201assert 'id' in response.get_json()def test_create_task_invalid_data(self, client):"""测试使用无效数据创建任务"""response = client.post('/api/tasks',json={'title': ''}, # 空标题headers={'Authorization': 'Bearer valid_token'})assert response.status_code == 400# 性能测试
class TestPerformance:"""性能测试类"""def test_batch_task_creation_performance(self, task_service):"""测试批量创建任务的性能"""import timestart_time = time.time()# 批量创建100个任务for i in range(100):task_service.create_task({'title': f'性能测试任务 {i}','user_id': 1})end_time = time.time()execution_time = end_time - start_time# 验证性能要求(100个任务应该在2秒内完成)assert execution_time < 2.0def test_database_query_performance(self, task_service):"""测试数据库查询性能"""import time# 先创建一些测试数据for i in range(50):task_service.create_task({'title': f'查询测试任务 {i}','user_id': 1,'priority': i % 3 + 1})start_time = time.time()# 执行复杂查询tasks = task_service.get_user_tasks(1, {'priority': 2,'status': 'pending'})end_time = time.time()query_time = end_time - start_time# 验证查询性能assert query_time < 0.1 # 查询应该在100毫秒内完成6.2 集成测试与端到端测试
class TestIntegration:"""集成测试类"""@pytest.fixturedef authenticated_client(self):"""认证的测试客户端"""from app import create_appapp = create_app('testing')with app.test_client() as client:# 设置认证tokenclient.environ_base['HTTP_AUTHORIZATION'] = 'Bearer test_token'yield clientdef test_full_task_lifecycle(self, authenticated_client):"""测试完整的任务生命周期"""# 1. 创建任务create_response = authenticated_client.post('/api/tasks', json={'title': '集成测试任务','description': '这是集成测试创建的任务','priority': 2,'category': 'work'})assert create_response.status_code == 201task_id = create_response.get_json()['id']# 2. 获取任务列表list_response = authenticated_client.get('/api/tasks')assert list_response.status_code == 200tasks = list_response.get_json()assert any(task['id'] == task_id for task in tasks)# 3. 更新任务update_response = authenticated_client.put(f'/api/tasks/{task_id}',json={'status': 'completed'})assert update_response.status_code == 200# 4. 验证任务状态更新get_response = authenticated_client.get(f'/api/tasks/{task_id}')assert get_response.status_code == 200task = get_response.get_json()assert task['status'] == 'completed'# 5. 删除任务delete_response = authenticated_client.delete(f'/api/tasks/{task_id}')assert delete_response.status_code == 200# 6. 验证任务已删除get_response = authenticated_client.get(f'/api/tasks/{task_id}')assert get_response.status_code == 404# 模拟测试
class TestWithMocks:"""使用模拟对象的测试"""def test_recommendation_service_with_mock_ai(self):"""使用模拟AI服务的推荐测试"""with patch('app.services.AIService') as MockAIService:# 配置模拟AI服务mock_ai_instance = MockAIService.return_valuemock_ai_instance.analyze_priority.return_value = 3mock_ai_instance.classify_task.return_value = 'work'# 创建任务服务(会使用模拟的AI服务)task_service = TaskService(':memory:')task_service.init_database()# 创建任务,应该使用模拟的AI服务task_id = task_service.create_task({'title': '测试任务','user_id': 1})# 验证AI服务被调用mock_ai_instance.analyze_priority.assert_called_once()mock_ai_instance.classify_task.assert_called_once()总结
通过以上实践,我们可以看到: 1. **GLM-4.6的强大能力**:在系统设计、智能分析、代码生成等方面发挥了重要作用 2. **多工具协同的价值**:不同工具各司其职,协同工作,显著提高了开发效率 3. **现代化开发实践**:采用了配置管理、模块化、测试、部署等现代化开发实践。
本文系统阐述了基于GLM-4-6等多工具协同的智能任务管理系统开发全流程,构建了一套完整的现代化软件开发方法论。通过工具间的精准分工与高效协作,实现了从需求分析到部署运维的全链路优化:GLM-4-6作为智能核心承担架构设计与算法实现,Claude Code确保代码质量,Cline专注用户体验,Roo Code提供基础设施支持。
该系统深度融合智能分析能力,创新性地实现了基于多维度评估的任务优先级自动判定、基于模式识别的智能分类以及个性化任务推荐机制。在技术架构层面,采用分层配置管理支持多环境部署,组件化前端设计保障用户体验,并通过数据库优化、缓存策略和多层次安全防护确保系统性能与可靠性。
整套方案体现了“智能驱动、工具协同、工程化实践”的现代软件开发理念,不仅提供了具体的技术实现方案,更展示了一种可扩展、可复用的开发范式,为复杂软件项目的开发提供了经过验证的最佳实践路径。