使用Requests和加密技术实现淘宝药品信息爬取
目录
引言
效果展示
项目目标
需求分析
实现步骤
步骤1:环境准备和库导入
步骤2:创建Excel工作表和数据初始化
步骤3:签名生成函数实现
步骤4:配置请求头和Cookies信息
步骤5:维护会话状态和Cookies管理
步骤6:药品关键词配置和分页策略
步骤7:构建API请求参数和数据处理
步骤8:生成动态签名和发送请求
步骤9:JSONP数据解析和清洗
步骤10:数据提取和格式化
步骤11:数据保存和分页状态维护
步骤12:最终文件保存
完整代码
代码详细讲解
加密技术深度解析
JSONP数据处理技术
数据清洗和格式化
智能分页策略
反爬应对策略
应用场景与价值
法律和道德声明
技术总结
引言
在医药电商快速发展的今天,药品价格信息的透明化对于消费者和行业研究者都具有重要意义。淘宝作为国内领先的电商平台,汇集了大量药品销售信息,这些数据对于市场分析、价格监测和消费者决策具有重要价值。
与传统的网页爬虫不同,本项目面临更加复杂的技术挑战。淘宝平台采用了完善的加密和签名验证机制,需要深入分析API接口和加密逻辑才能成功获取数据。本项目通过逆向工程分析,成功破解了淘宝的签名算法,实现了稳定可靠的药品信息采集系统。
在数据采集技术应用中,我们必须高度重视合法合规。药品信息涉及公共健康安全,所有采集行为应严格遵守相关法律法规,仅用于技术学习和市场研究,不得用于任何商业竞争或非法用途。
效果展示

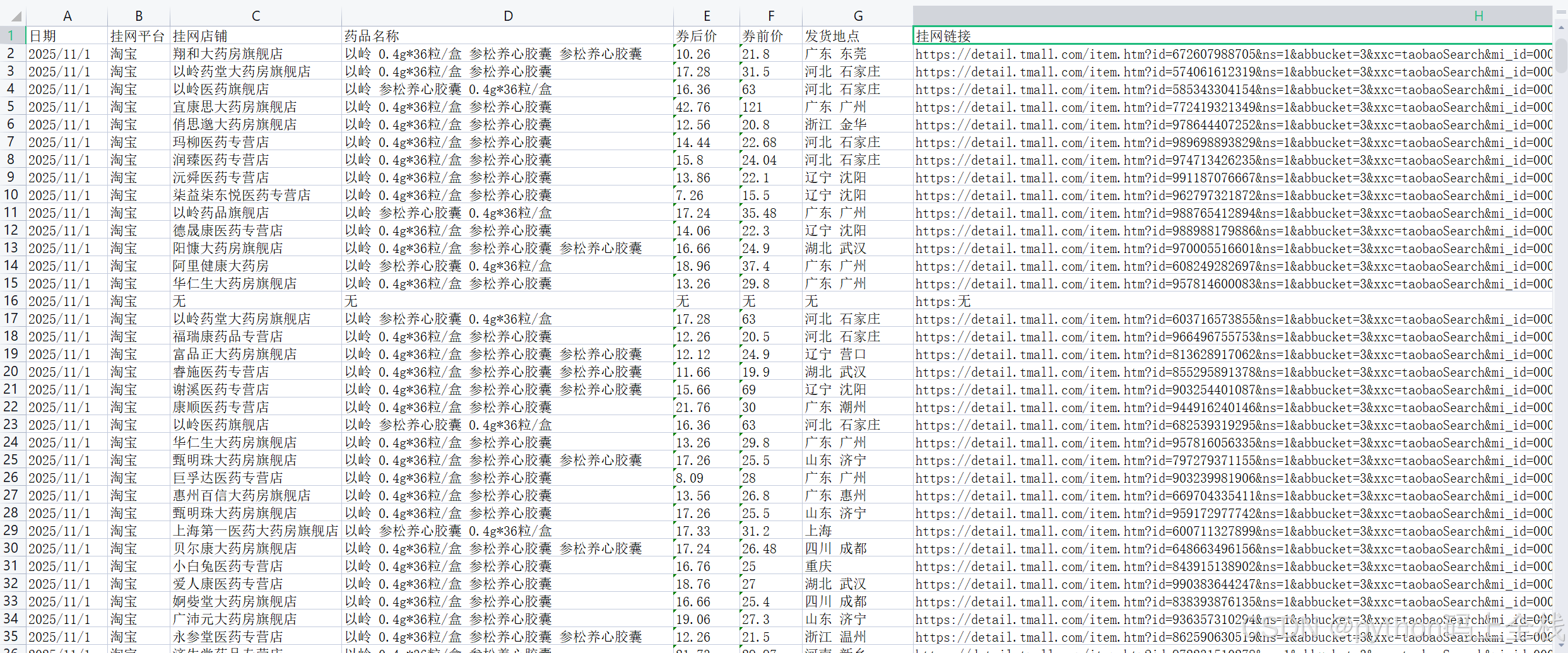
通过本项目实现的爬虫程序,能够