工业时序数据库TDengine 架构、性能与实战全解析
一、引言
1.1 工业领域时序数据爆发式增长,数据库如何接招?
工业 4.0 与物联网技术的深度融合,正推动工业领域进入数据爆炸时代。从智能工厂的设备传感器、生产流水线监测点,到工业互联网平台的全域数据采集,时序数据已呈现指数级增长态势。据工业互联网产业联盟统计,单条智能生产线每小时可产生数十万条设备状态数据,一座大型智慧工厂日均数据增量可达 TB 级,而整个工业领域的时序数据年增长率已突破 60%。
这种爆发式增长给数据管理带来了前所未有的挑战:既要应对每秒百万级的写入压力,又要保障毫秒级的查询响应;既要实现 PB 级数据的长期存储,又要控制存储成本;既要满足实时监控的即时性需求,又要支撑离线分析的复杂性要求。传统数据管理方案在这场 "数据洪流" 面前逐渐力不从心,专为时序数据设计的专业数据库成为工业数字化转型的核心基础设施。
1.2 时序数据的十大特点
工业时序数据作为工业系统运行状态的 "数字足迹",具有鲜明的行业特征,其核心特点可概括为十点:
带有时间戳:每个数据点都对应唯一的时间点,时间不仅是数据的标识,更是分析的核心维度。没有时间戳,就无法进行趋势分析、对比或预测。
结构化、数值型:时序数据通常来源于传感器或设备,具有固定格式,字段明确定义,多为数值类型,如温度、电流、电压等,便于存储与计算。
写多改少:时序数据一旦生成,极少被修改或删除。系统主要执行写入与追加操作,而非更新,保证数据的完整性与连续性。
数据源唯一:每个设备独立产生自身数据,不存在共享或人工生成的情况。数据来源清晰、可追溯,保证了采集的准确性与真实性。
写多读少:设备持续高速写入数据,而读取主要发生在自动计算、分析或告警场景中。相比互联网应用的“读多写少”,时序系统面临的是持续高并发写入压力。
聚焦趋势而非单点:单个数据点意义有限,用户更关注某一时间段内的趋势、变化或异常,而非某个瞬时值。
有保留期限:时序数据生成速度快、体量巨大,通常根据业务需求设定保留周期(如1天、1周、1月等),到期后自动删除以节省存储空间。
基于时间范围与设备集合的分析:分析查询通常限定时间范围和特定设备子集,例如某厂区、某批次或某型号设备的趋势分析。
实时性要求高:许多时序场景(如监测、报警、预测)要求实时分析与计算,必须在毫秒或秒级内完成数据处理,以便即时响应事件。
数据量巨大且增长可预测:IoT 设备数量庞大、采样周期固定,使得数据增长量可估算。相比突发性的互联网流量,IoT 数据流量稳定可控,但总体规模极为庞大。
1.3 传统方案的弊端
在专业时序数据库普及前,工业企业主要依赖三类传统方案处理时序数据——NoSQL 数据库、关系型数据库以及基于 Hadoop 的大数据平台。然而,在百万级设备、海量高频数据的现实场景下,这些方案的局限性愈发明显。
NoSQL 数据库(如 MongoDB):压缩率低、成本高、扩展代价大
无论是 Redis、MongoDB 还是 ElasticSearch,在面对时序数据场景时都绕不开一个根本问题——压缩率低。 以车联网为例,按照国标 30 秒的采样间隔计算,单台车每天约产生 2880 条数据;当规模达到 10 万台车时,每天新增 2.88 亿行数据。假设每台车采集 250 个信号,每个信号占 8 字节(Double 型),每行数据约 2000 字节,这意味着每天将产生约 562.5 GB 数据,一年累积约 200 TB。 即便压缩率能达到 50%,仍需 100 TB 的存储空间,这通常需要 10 个以上节点的 NoSQL 集群支撑(若使用 Redis,则需要 100 TB 内存规模的集群,成本更为惊人)。根源在于 NoSQL 采用非结构化存储结构化数据的方式,天然导致压缩效果差、存储成本高、节点规模大。
而且其未针对时序数据的查询模式优化,当进行跨时间窗口的聚合分析时,查询延迟常超过秒级甚至分钟级。且缺乏数据生命周期管理能力,需手动开发清理脚本,运维复杂度高。
关系型数据库(如 MySQL、PostgreSQL):写入瓶颈与扩展受限
作为传统 SQL 数据库,MySQL 与 PostgreSQL 在结构化数据场景下表现优秀,但面对高并发写入的时序数据仍显乏力。
以 10 万辆车为例,平均写入速率约为 3,333 行/秒,峰值可达 10 万行/秒。由于车机存在离线补传与定时同步的特性,峰值写入往往超过预期,若数据库吞吐不足极易出现积压。
在未调优的情况下,MySQL 对单行 2KB 的数据写入,单节点 1,000 TPS 基本已达极限。此外,随着数据量增长到千万级(例如单表 2,000 万行以上),B+ 树索引维护将显著拖慢写入速度,即便只建立时间戳索引也会影响性能。
更进一步,MySQL 的横向扩展依赖中间件,缺乏原生的分布式能力,而 PostgreSQL 虽通过扩展分支尝试支持时序数据,但依然难以解决高并发与高可扩展性矛盾。
基于 Hadoop 的大数据平台(如 HBase):架构复杂、计算慢、维护难
此类数据库擅长离线批处理,但实时性不足,数据从采集到可用的延迟通常在分钟级以上,无法满足工业监控的实时告警需求。同时部署成本高昂,一套最小化集群需至少 6 台服务器,中小企业难以负担。
在 Hadoop 生态仍占主导的年代,HBase 曾广泛应用于工业监控,其最初设计用于大规模爬虫数据存储,并非面向时序数据场景。从架构设计看,它存在以下问题:
压缩率不高:以列族(Column Family)为单位的列存结构虽支持灵活扩展,但压缩效果有限,数据体积仍然庞大。
运维复杂:部署 HBase 需依赖 HDFS、ZooKeeper、MapReduce 等多组件,系统复杂度高,安装、配置与维护成本大。
计算性能不足:HBase 节点自身不具备时序计算能力,像 OpenTSDB 这样的上层系统在执行降采样、聚合或时间段检索时,必须将数据汇聚至单节点处理,导致并发度低、网络 I/O 开销大,查询性能有限。
这些弊端直接制约了工业数据价值的挖掘,专业时序数据库的出现成为必然选择。
二、挑选时序数据库的关键要点
2.1 性能指标:写入与查询的双重考验
性能是时序数据库的核心竞争力,需从写入吞吐量与查询延迟两个维度综合评估。
写入吞吐量(Write Throughput)
写入吞吐量直接决定数据库能否承接工业场景的高频数据采集需求,通常以 "点 / 秒" 为单位计量。工业场景中,单机需支撑至少 10 万点 / 秒的写入能力才能满足中型生产线需求,大型工厂则要求集群写入能力达到百万点 / 秒级。
评估时需关注持续写入稳定性而非瞬时峰值,部分数据库在短时间内可达到高吞吐量,但持续运行 1 小时后性能会下降 50% 以上。同时需考虑资源占用率,优秀的时序数据库在达到 30 万点 / 秒写入时,CPU 使用率应控制在 30% 以内。
查询延迟(Query Latency)
查询性能需区分场景评估:简单查询(如单设备最新数据查询)应达到毫秒级(<100ms),满足实时监控需求;复杂查询(如 1000 台设备的日均值聚合)应控制在秒级(<2s),支撑运营分析需求。
工业场景中,查询的并发能力同样关键。当 100 个客户端同时发起查询时,优秀的时序数据库性能衰减应不超过 20%,而传统方案在此场景下常出现查询超时。
2.2 存储效率:压缩比决定成本
存储成本在工业时序数据管理总成本中占比可达 60% 以上,而压缩比是决定存储效率的核心指标。压缩比通常指原始数据量与压缩后数据量的比值,比值越高,存储成本越低。
不同数据库的压缩能力差异显著:传统关系型数据库压缩比仅为 2:1-3:1,而专业时序数据库通过列式存储、差值编码、字典编码等多层压缩技术,压缩比可达到 8:1 甚至 10:1。以 100 万点/秒的写入速度计算,每天产生的数据量约为 86GB,采用 8:1 压缩比的数据库每年仅需 38TB 存储空间,而采用 3:1 压缩比的方案则需 102TB,三年存储成本相差可达数十万元。
除压缩比外,还需关注分级存储能力,即能否自动将冷数据迁移至低成本存储介质(如 S3 对象存储),进一步降低长期存储成本。
2.3 数据模型:是否贴合业务结构
合理的数据模型能降低开发复杂度,提升数据读写效率。工业时序数据的核心关联关系包括设备、指标、时间三大要素,优秀的时序数据库应支持 "设备 - 指标 - 时间" 三维模型。
理想的数据模型需具备以下特性:
支持为设备定义静态标签(如设备型号、安装位置),便于按维度筛选数据;
支持多指标同时写入,减少网络交互次数;
原生支持指标类型区分(数值型、布尔型、字符串型),无需额外定义 schema。
部分数据库采用扁平的数据模型,将所有指标存储在单一表中,导致查询时需频繁进行过滤操作,性能下降 30% 以上。而贴合工业业务结构的数据模型可使开发效率提升 40%,查询性能提升 2-3 倍。
2.4 扩展性:应对未来数据增长
工业企业的设备数量与采集点会随数字化进程持续增加,数据库的扩展性直接决定其生命周期价值。扩展性评估需关注两个维度:
水平扩展能力
优秀的时序数据库应采用分布式架构,支持通过增加节点线性提升性能与存储容量。评估时需验证 "节点数量翻倍时,写入吞吐量是否接近翻倍",理想情况下性能提升比例应达到 80% 以上。
同时需关注扩展的便捷性,是否支持一键添加节点,是否需要重启集群,扩展过程中业务是否中断。TDengine 通过虚拟节点(vnode)技术,实现了集群的无缝扩展,节点增加后无需调整应用配置。
功能扩展性
需支持与工业生态工具的无缝集成,包括数据采集工具(如 Telegraf、OPC UA 客户端)、可视化工具(如 Grafana、Tableau)、流处理工具(如 Flink、Kafka)等。缺乏生态支持会导致集成开发成本增加,项目周期延长。
三、TDengine TSDB:为工业物联网而生的时序数据库
3.1 架构概览
TDengine TSDB 由涛思数据自主研发,自 2017 年发布以来持续迭代,其架构设计深度贴合工业物联网场景需求,采用 "存储-计算-接入" 一体化架构,核心组件包括:
客户端层
提供多语言 SDK(C/C++、Java、Python 等 10 余种语言),支持 JDBC、ODBC 等标准接口,同时内置 MQTT、Kafka、OPC UA 等工业协议接入能力,企业版通过 taos-explorer 工具可实现数据源零代码接入,大幅降低集成难度。
集群管理层
基于虚拟节点(vnode)技术实现数据分片,每个 vnode 负责特定设备的数据存储与计算,确保写入与查询的水平扩展能力。通过 Leader-Follower 模式构建虚拟节点组,实现数据冗余与自动故障转移,故障恢复时间小于 30 秒,保障工业场景的高可用性需求。
存储引擎层
采用列式存储架构,针对时序数据特性设计了多级压缩算法(差值编码、XOR 编码、LZ4 压缩),压缩比可达 8:1(典型值)。支持按时间分区(如按天分区),实现数据的快速定位与生命周期管理,超过保留期的数据可自动删除。同时支持冷热数据分离,冷数据自动迁移至低成本存储,降低 50% 以上的存储成本。
计算引擎层
内置丰富的时序函数(如滑动窗口、插值、聚合函数等),支持实时计算与离线分析。采用分布式计算架构,聚合查询时先在各 vnode 内完成本地计算,再进行全局汇总,在大规模分析场景中查询效率可提升 3–5 倍。
3.2 核心优势总结
TDengine TSDB 凭借针对性的架构设计,在工业场景中展现出四大核心优势:
极致性能
单机写入吞吐量可达 380 万点/秒,远超 InfluxDB 的 22 万点/秒与 OpenTSDB 的 15 万点/秒。在 TSBS 测试的 IoT 场景中,TDengine 的写入性能是 InfluxDB 的 1.82-16.2 倍,查询性能更是达到 InfluxDB 的 2.4-426.3 倍。这种性能优势使 TDengine 可轻松支撑十万级设备的同时数据采集。
成本优化
通过 8:1 的高压缩比与冷热数据分离技术,TDengine 可将存储成本降低 70% 以上。以大理卷烟厂为例,其迁移至 TDengine 后,成功存储 7000 亿条历史数据,且存储成本较原方案下降 60%。同时集群版完全开源,无需支付高昂的商业许可费用,进一步降低企业使用成本。
简化架构
集成了数据采集、存储、计算、可视化等全链路功能,无需额外部署 Kafka、Spark 等组件,架构复杂度降低 50%。提供零代码数据接入工具与可视化管理界面,使系统部署周期从数月缩短至数周。
国产化适配
完全自主研发,符合信创体系要求,已适配麒麟、统信等国产操作系统,以及飞腾、鲲鹏等国产芯片。可为工业企业提供从硬件到软件的全栈国产化解决方案,保障数据安全与供应链稳定。
四、基于国际 TSBS 时序数据性能基准测评平台的测试报告
TSBS(Time Series Benchmark Suite)是国际公认的时序数据库性能测评标准,通过模拟真实场景的数据模型与查询模式,从写入、查询、存储、资源占用等维度全面评估数据库性能。TDengine 3.0 在 TSBS 的 IoT 和 DevOps 场景测试中均表现优异,下文将重点解读两大场景的测试结果。
4.1 IT 运维场景的报告解读
TSBS 的 IoT 场景测试预设了五种规模的卡车车队场景,使用亚马逊 AWS 的 EC2 提供的 r4.8xlarge 类型实例作为基础运行平台,包括 1 台服务器、1 台客户端共两个节点构成的环境。在写入、查询和存储方面的对比结果如下:
写入性能
相对于 TimescaleDB,TDengine 写入速度最领先的场景达到其 3.3 倍(场景一),最小的为 1.04倍(场景四);且对于场景四,如果将每个采集点的记录条数由 18 条增加到 576 条,且 vgroups=24 时,TDengine 写入速度是 TimescaleDB 的 7 倍。相对于 InfluxDB,TDengine 写入速度最领先的场景达到其 16.2 倍(场景五),最小为 1.82 倍(场景三)。
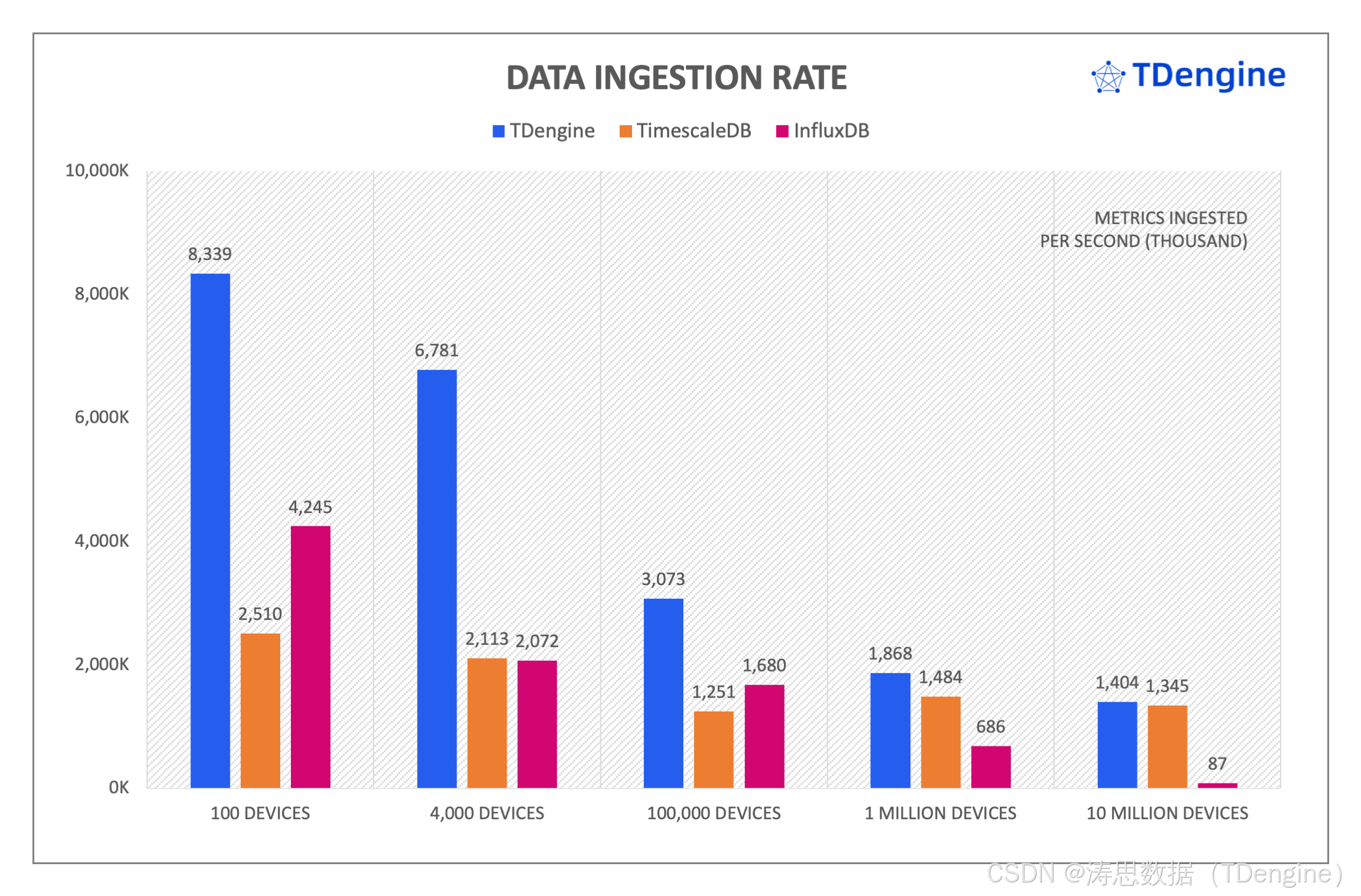
查询性能
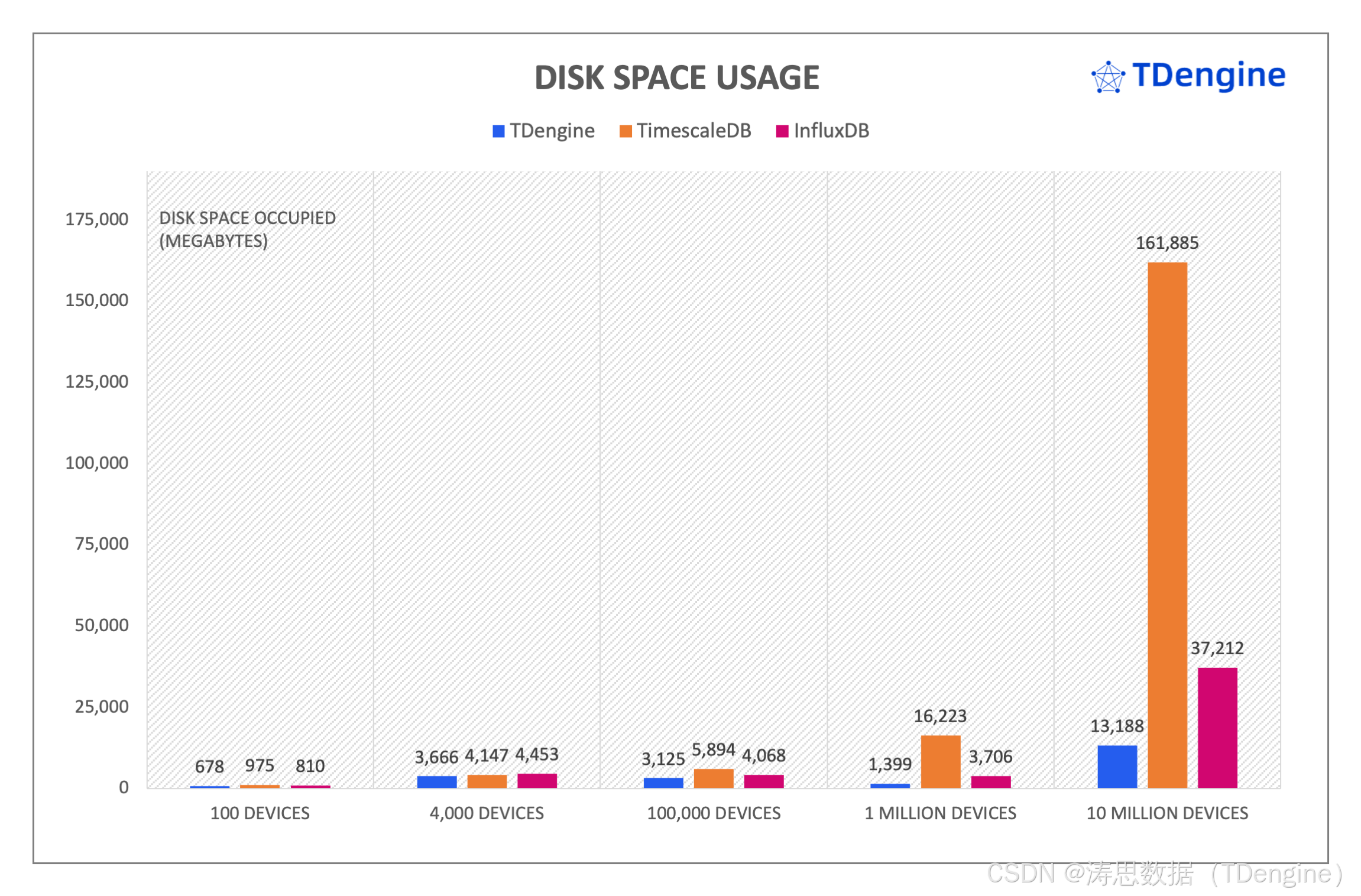
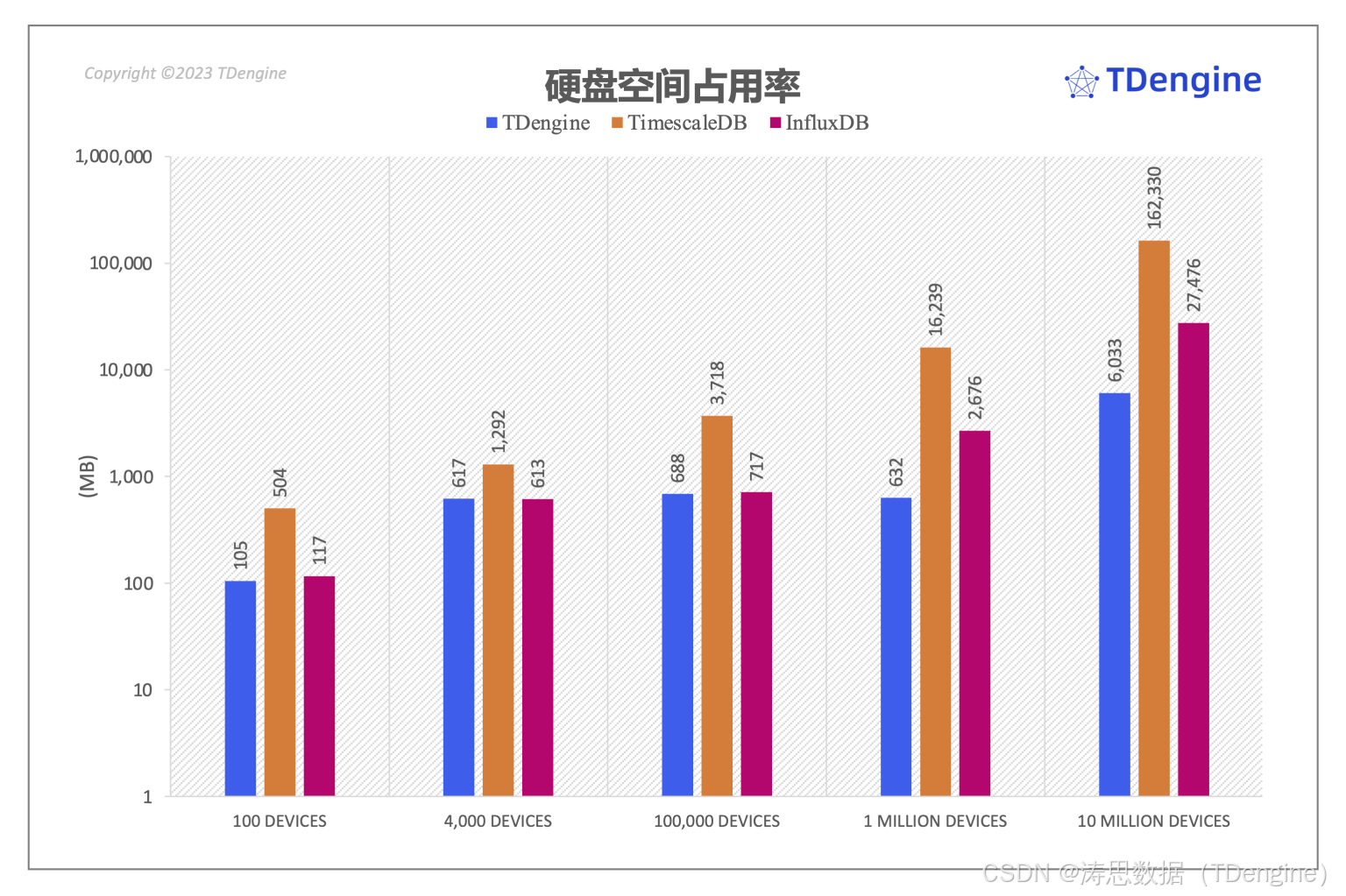
磁盘占用空间
磁盘空间占用方面,TimescaleDB 在所有五个场景下数据规模均显著地大于 InfluxDB 和 TDengine,并且这种差距随着数据规模增加快速变大。TimescaleDB 在场景四和场景五中占用磁盘空间是 TDengine 的 11.6 倍和 12.2 倍。在前面三个场景中,InfluxDB 落盘后数据文件规模与 TDengine 非常接近,但是在大数据规模的场景四和场景五中,InfluxDB 落盘后文件占用的磁盘空间是 TDengine 的 2.6 倍和 2.8 倍。
一键执行对比测试
执行以下命令:nohup bash tsdbComparison.sh > test.log &测试脚本将自动安装 TDengine, InfluxDB, TimeScaleDB 等软件,并自动运行各种对比测试项。在目前的硬件配置下,整个测试跑完需要大约三天的时间。测试结束后,将自动生成 CSV 格式的对比测试报告,并存放在客户端的 /data2 目录,对应 load 和 query 前缀的文件夹下。
4.2 DevOps 场景中的报告解读
基于 TSBS 标准数据集,TDengine 团队对时序数据库 InfluxDB, TimescaleDB 和 TDengine 针对 TSBS 指定的 DevOps 中 cpu-only 五个场景进行了对比测试。在写入、查询和存储方面的对比结果如下:
写入性能
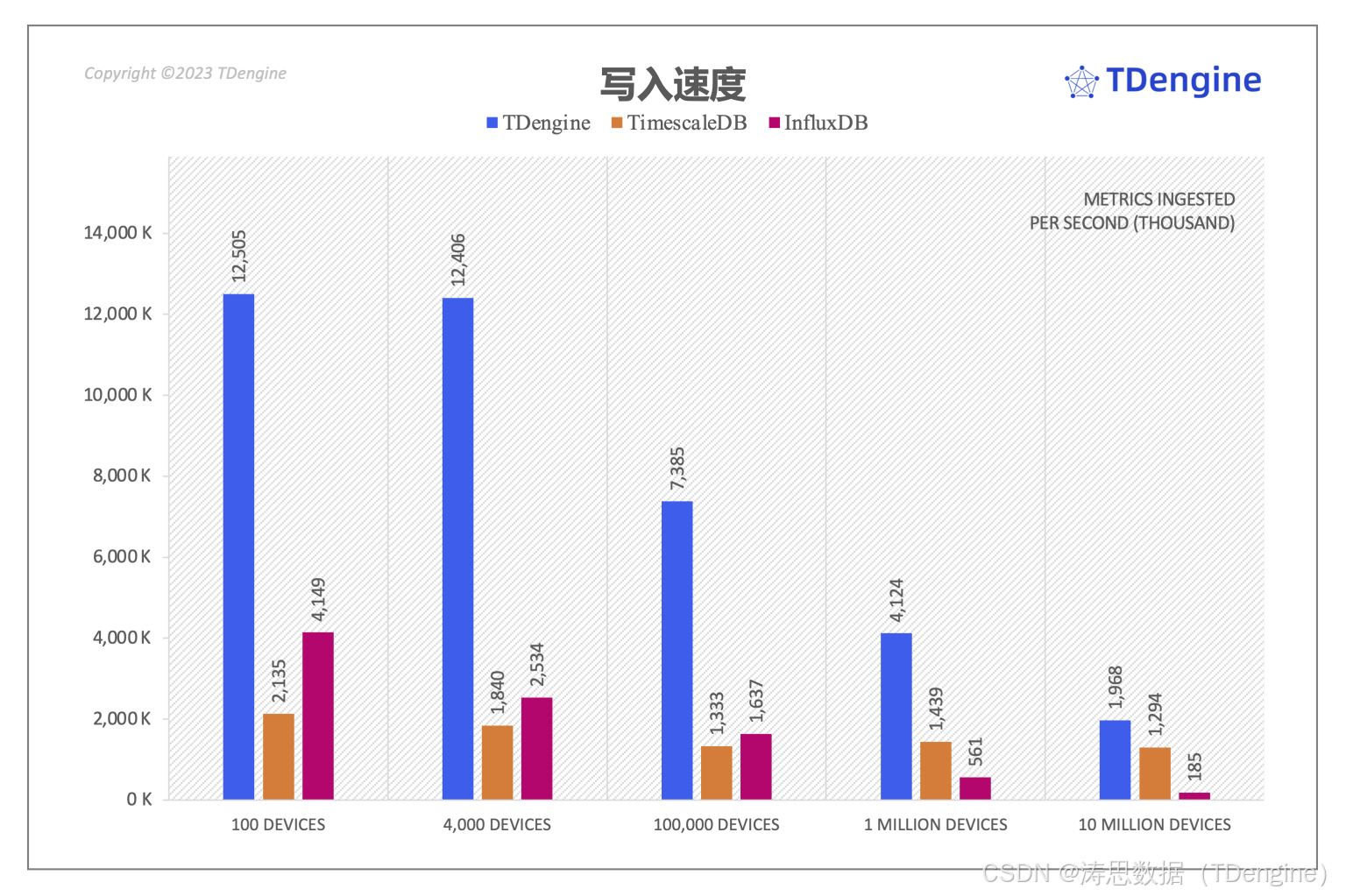
在 TSBS 全部的 cpu-only 五个场景中,TDengine 写入性能均优于 TimescaleDB 和 InfluxDB。相对于 TimescaleDB, TDengine 写入速度最领先的场景是其 6.7 倍(场景二),最少也是 1.5 倍(场景五),而且对于场景四,如果将每个采集点的记录条数由 18 条增加到 576 条,TDengine 写入速度是 TimescaleDB的 13.2 倍。相对于 InfluxDB,TDengine 写入速度最领先的场景是其 10.6 倍(场景五),最少也是 3.0 倍(场景一)。此外,TDengine 在写入过程中消耗了最少 CPU 资源和磁盘 IO 开销。
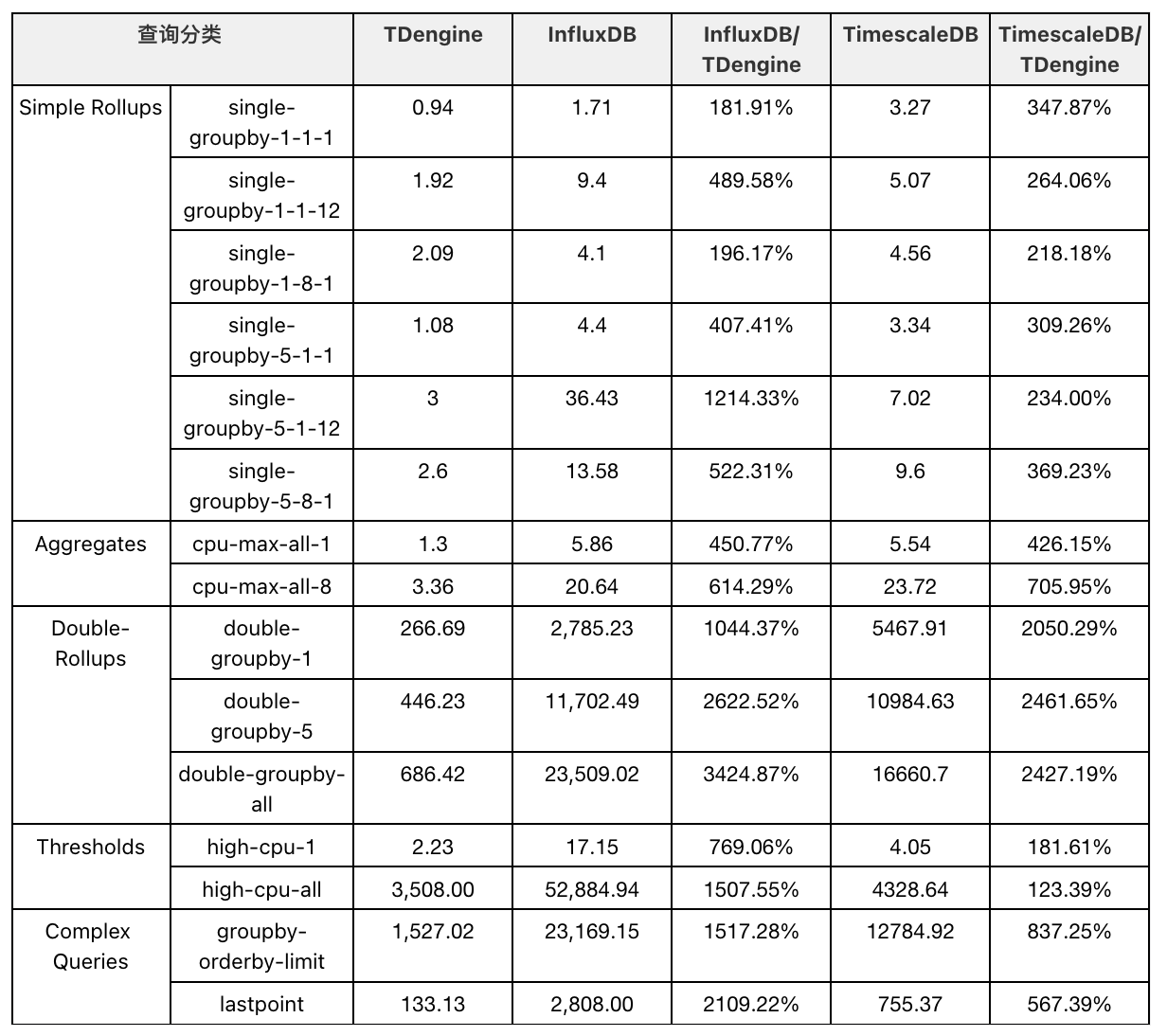
查询性能
查询方面,在场景一(只包含 4 天的数据)与场景二的 15 个不同类型的查询中,TDengine 的查询平均响应时间全面优于 InfluxDB 和 TimescaleDB,而且在复杂查询上优势更为明显,同时具有最小的计算资源开销。相对于 InfluxDB,场景一,TDengine查询性能是其 1.9 ~ 37.0 倍,平均 11.3 倍,场景二,TDengine 查询性能是其 1.8 ~ 34.2 倍,平均是 11.3 倍。相对于 TimeScaleDB,场景一,TDengine 查询性能是其 1.1 ~ 28.6 倍,平均 7.6 倍,场景二,TDengine查询性能是其 1.2 ~ 24.6 倍,平均 7.7 倍。

磁盘占用空间
磁盘空间占用方面,TimescaleDB 在所有五个场景下的数据规模均显著大于 InfluxDB 和 TDengine,并且这种差距随着数据规模增加快速变大。TimescaleDB 在场景四和场景五中占用磁盘空间是 TDengine 的 25.6 倍和 26.9 倍。在前面三个场景中,InfluxDB 落盘后数据文件规模与 TDengine 非常接近,但是在大数据规模的场景四和场景五中,InfluxDB 落盘后文件占用的磁盘空间是 TDengine 的 4.2 倍和 4.5 倍。
一键执行对比测试
执行以下命令:nohup bash tsdbComparison.sh > test.log &测试脚本将自动安装 TDengine, InfluxDB, TimeScaleDB 等软件,并自动运行各种对比测试项。在目前的硬件配置下,整个测试跑完需要大约一天半的时间。测试结束后,将自动生成 CSV 格式的对比测试报告,并存放在客户端的 /data2 目录。
五、实战篇:TDengine TSDB 下载、安装与使用指南
本节首先介绍如何通过安装包快速安装 TDengine TSDB-Enterprise,然后介绍如何在 Linux 环境下体验 TDengine TSDB 的写入、查询、可视化管理、与 Grafana 集成和零代码数据写入等功能。如果你希望为 TDengine TSDB 贡献代码或对内部技术实现感兴趣,请参考 TDengine TSDB GitHub 主页。
5.1 安装 TDengine TSDB
从列表中下载获得 tar.gz 安装包:
tdengine-tsdb-enterprise-3.3.8.1-linux-arm64.tar.gz (427.24MB)
tdengine-tsdb-enterprise-3.3.8.1-linux-x64.tar.gz (438.31MB)
进入到安装包所在目录,使用
tar解压安装包,以 x64 架构为例:
tar -zxvf tdengine-tsdb-enterprise-3.3.8.1-linux-x64.tar.gz进入到安装包所在目录,先解压文件后,进入子目录,执行其中的 install.sh 安装脚本。
sudo ./install.sh更多类型和版本的安装包,请前往 TDengine 产品下载中心下载。
5.2 启动 TDengine TSDB
完成安装后,请在终端执行以下脚本,启动所有服务:
start-all.sh TDengine TSDB 的所有组件均使用 systemd 来进行服务管理,可以使用以下命令查看服务的状态:
sudo systemctl status taosd
sudo systemctl status taosadapter
sudo systemctl status taoskeeper
sudo systemctl status taos-explorer如果查看到服务的状态为 "Active: active (running) since ...", 则说明服务已经启动成功。
5.3 快速体验
体验 TDengine TSDB 命令行
为便于检查 TDengine 的状态,执行数据库(Database)的各种即席(Ad Hoc)查询,TDengine TSDB 提供一命令行应用程序(以下简称为 TDengine TSDB CLI)taos。要进入 TDengine 命令行,用户只要在终端执行 taos (Linux/Mac) 或 taos.exe (Windows) 即可。TDengine CLI 的提示符号如下:
taos>在 TDengine TSDB CLI 中,用户可以通过 SQL 命令来创建/删除数据库、表等,并进行数据库(Database)插入查询操作。在终端中运行的 SQL 语句需要以分号(;)结束来运行。示例:
CREATE DATABASE demo;
USE demo;
CREATE TABLE t (ts TIMESTAMP, speed INT);
INSERT INTO t VALUES ('2019-07-15 00:00:00', 10);
INSERT INTO t VALUES ('2019-07-15 01:00:00', 20);
SELECT * FROM t;ts | speed |
========================================2019-07-15 00:00:00.000 | 10 |2019-07-15 01:00:00.000 | 20 |Query OK, 2 row(s) in set (0.003128s)除执行 SQL 语句外,系统管理员还可以从 TDengine TSDB CLI 进行检查系统运行状态、添加删除用户账号等操作。TDengine TSDB CLI 连同应用驱动也可以独立安装在机器上运行,更多细节请参考 TDengine TSDB 命令行。
体验写入
taosBenchmark 是一个专为测试 TDengine 性能而设计的工具,它能够全面评估 TDengine 在写入、查询和订阅等方面的功能表现。该工具能够模拟大量设备产生的数据,并允许用户灵活控制数据库、超级表、标签列的数量和类型、数据列的数量和类型、子表数量、每张子表的数据量、写入数据的时间间隔、工作线程数量以及是否写入乱序数据等策略。
启动 TDengine 的服务,在终端中执行如下命令:
taosBenchmark -y系统将自动在数据库 test 下创建一张名为 meters 的超级表。这张超级表将包含 10,000 张子表,表名从 d0 到 d9999,每张表包含 10,000 条记录。每条记录包含 ts(时间戳)、current(电流)、voltage(电压)和 phase(相位)4 个字段。时间戳范围从“2017-07-14 10:40:00 000”到“2017-07-14 10:40:09 999”。每张表还带有 location 和 groupId 两个标签,其中,groupId 设置为 1 到 10,而 location 则设置为 California.Campbell、California.Cupertino 等城市信息。
执行该命令后,系统将迅速完成 1 亿条记录的写入过程。实际所需时间取决于硬件性能,但即便在普通 PC 服务器上,这个过程通常也只需要十几秒。
taosBenchmark 提供了丰富的选项,允许用户自定义测试参数,如表的数目、记录条数等。要查看详细的参数列表,请在终端中输入如下命令
taosBenchmark --help有关 taosBenchmark 的详细使用方法,请参考 taosBenchmark 参考手册
体验查询
使用上述 taosBenchmark 插入数据后,可以在 TDengine CLI(taos)输入查询命令,体验查询速度。
查询超级表 meters 下的记录总条数
SELECT COUNT(*) FROM test.meters;查询 1 亿条记录的平均值、最大值、最小值
SELECT AVG(current), MAX(voltage), MIN(phase) FROM test.meters;查询 location = "California.SanFrancisco" 的记录总条数
SELECT COUNT(*) FROM test.meters WHERE location = "California.SanFrancisco";查询 groupId = 10 的所有记录的平均值、最大值、最小值
SELECT AVG(current), MAX(voltage), MIN(phase) FROM test.meters WHERE groupId = 10;对表 d1001 按每 10 秒进行平均值、最大值和最小值聚合统计
SELECT _wstart, AVG(current), MAX(voltage), MIN(phase) FROM test.d1001 INTERVAL(10s);在上面的查询中,使用系统提供的伪列 _wstart 来给出每个窗口的开始时间。
关于 Windows 系统的安装体验详情,可进入 https://docs.taosdata.com/get-started/package/ 查看。
六、真实案例见证 TDengine 实力
6.1 TDengine 落地的主要行业
TDengine 凭借工业级的稳定性与性能,已在钢铁、能源、交通、水利等多个重点行业实现规模化落地,覆盖工业物联网的核心场景:
智能制造:支撑设备状态监控、生产工艺优化、质量追溯等场景,服务卷烟、汽车、电子等制造企业;
能源电力:适配风电、光伏、电网等场景,实现设备运维、发电量预测、负荷调度的数据管理;
车联网:满足新能源汽车电池监控、自动驾驶数据存储、车队管理等高频写入场景;
石油化工:覆盖油气开采、炼化生产、管道运输等环节的实时数据处理;
智慧水务:支撑水质监测、管网压力监控、泵站运维等数据的采集与分析。
截至 2025 年,TDengine 已服务超过 2000 家工业企业,管理的时序数据总量突破 100PB。
6.2 TDengine 的企业案例
案例一:大理卷烟厂——制丝工艺的国产化智能升级
大理卷烟厂作为云南中烟核心生产基地,主产“玉溪”“红塔山”等高端卷烟,是红塔集团核心品牌的重要支撑工厂。近年来,工厂积极推进数字化转型,在制丝、复烤等关键环节引入“智能控制 + AI 预测”,并通过 TDengine TSDB 时序数据库实现了生产数据架构的国产化替代与智能化升级,构建起“质效协同”的智能制造工厂。
背景与挑战
制丝车间是决定卷烟品质的核心环节。早期工厂采用基于 SQL Server 的 Wonderware historian 数据库进行数据存储与分析,但随着业务规模扩大,该方案暴露出实时性不足、存储成本高、系统割裂严重等问题。工艺参数调整延迟长、质量事故追溯耗时数小时,已难以满足数字化生产要求。
解决方案
在全面评估实时性能、国产化兼容性与成本效益后,大理卷烟厂选择 TDengine TSDB 作为新一代时序数据平台,并分阶段完成系统升级与数据迁移:
系统演进:从 2.x 社区版到 3.0.4 企业版,再升级至 3.3.6 企业版,性能与功能持续增强;
数据采集与整合:通过 taos-explorer 与 taosX 工具,零代码接入 Kafka、MQTT、OPC 等多源数据,覆盖制丝、卷包等关键工序共 4 万余监测点位;
历史数据迁移:利用 taosX 将 3 年累计超 7000 亿条历史数据平滑迁移至新集群,实现系统平稳切换;
智能化应用:结合 AI 在线优化系统,构建设备预测性维护机制,实现工艺参数的实时优化与自适应控制。
实施成效
实时性显著提升:工艺调控延迟从分钟级降至秒级,出口水分标偏稳定在优于工艺标准的区间;
成本大幅降低:凭借列式压缩与冷热分离机制,存储成本远低于原方案;
效率全面提升:多系统数据整合后,质量事故追溯由数小时缩短至分钟级,设备运行效率显著提高;
国产化落地:实现了工业数据平台的全栈国产化,系统运行稳定可靠,2025 年获授“玉溪品牌原料打叶复烤示范性区域加工中心”称号。
案例二:蔚来能源——充换电设备数据的高效管理与优化
蔚来能源(NIO Power)作为蔚来汽车集团旗下的能源业务板块,致力于为用户提供极致的补能体验。截止 2021 年底,蔚来能源已在全国布局换电站 777 座、超充桩 3,404 根、目充桩 3,461 根,并为用户安装家充桩 9.6 万余根,构建起覆盖全国的能源网络。
为了高效管理庞大的设备体系,蔚来能源需要将各类充换电设备产生的运行数据实时汇聚至云端,实现数据的统一存储、监控与分析,为运维、调度与能效优化提供支撑。
背景与挑战 项目初期,蔚来能源采用 MySQL + HBase 混合架构:MySQL 用于存储最新实时数据,HBase 存储历史数据。随着全国范围内充电设施的快速铺开,这一架构逐渐暴露出多项问题:
查询性能受限:HBase 仅支持 Rowkey 索引,不适合多条件、多维度的复杂查询;
维护复杂度高:需手动管理预分区与二级索引,业务模型稍有调整就需重建表结构;
查询效率低下:长时间跨度数据扫描性能差,聚合分析响应慢,无法支持图表渲染;
运维成本高:依赖 ZooKeeper,部署繁琐,集群维护压力大。
面对全国数千套设备与海量数据的持续增长,蔚来能源迫切需要一种更高效、轻量且可扩展的时序数据库解决方案。
实施过程 为确保迁移平稳,蔚来能源设计了分阶段方案:
数据双写:新系统上线初期,同时写入 HBase 与 TDengine,确保数据一致性与可回退;
批量写入策略:采用 1,000 条 / 500ms 的批写机制,单次写入耗时 <10ms,有效提升并发处理能力;
查询切换机制:按时间范围动态判断查询来源,确保迁移前后查询结果无缝衔接;
集群上线:逐步将各类设备数据切换至 TDengine 集群,替换原有 HBase 存储。
实施成效
查询性能提升显著:单设备 24 小时数据查询由秒级响应降至毫秒级,支持更复杂的可视化分析;
存储空间减少约 50%:数据压缩效果突出,整体计算与存储成本下降超过 60%;
运维负担大幅减轻:无需依赖 ZooKeeper,系统扩容简单,集群部署与维护效率显著提高;
系统运行稳定可靠:上线后集群长期稳定运行,为全国数千座换电与充电设施提供高效数据支撑。
更多用户案例可前往 https://www.taosdata.com/tdengine-user-cases 查看。
七、AI 时代,TDengine 通过 AI 大模型的结合,完成新的产品路线和数据价值挖掘前景
AI 技术的崛起为工业数据价值挖掘提供了新范式,TDengine 通过融合 AI 大模型,从 "数据存储平台" 升级为 "智能数据管理平台",构建 "存储-计算-智能" 一体化的产品路线。
8.1 TDgpt 时序数据分析 AI 智能体
TDgpt 是 TDengine 内置的时序数据分析 AI 智能体,面向预测、异常检测、补齐与分类等场景。它可无缝对接时序数据模型、LLM、机器学习与传统统计算法,并支持算法的动态切换;通过一条 SQL 即可调用内置能力。借助开放 SDK,开发者还能将自研算法/模型集成到 TDgpt,供业务直接使用。
零门槛 · 一条 SQL 即可用
预测(Forecast)
FORECAST(column_expr, option_expr)
option_expr: { "algo=expr1[,wncheck=1|0][,conf=conf_val][,every=every_val][,rows=rows_val][,start=start_ts_val][,expr2]"}异常检测(Anomaly Window)
ANOMALY_WINDOW(column_name, option_expr)option_expr: {"algo=expr1 [,wncheck=1|0] [,expr2]"}动态算法切换与可扩展
在 SQL 选项中指定
algo、model等参数即可切换不同算法/模型;通过 SDK 接入自研模型,应用侧无需改造即可使用最新算法。
典型应用
电力/新能源:用公开数据集演示电力负荷与风电发电量预测的完整流程;
运维监控:基于公开 NAB 数据集进行 CPU 等指标的异常检测;
工业现场:对设备与工艺指标进行预测、异常窗口识别与数据补齐,支撑可视化、告警与报表。
8.2 TDengine IDMP :AI 原生的工业数据管理平台
TDengine IDMP 是一款 AI 原生的工业数据管理平台。它通过树状层次结构组织传感器、设备及产线数据,对数据进行语境化、标准化处理,并提供实时分析、可视化、事件管理与报警等一体化能力。IDMP 利用 AI 技术,能够基于采集数据智能感知业务场景,无需用户提问,即可自动生成该场景所需的实时分析与可视化面板。这一“无问智推”特性,让业务人员无需编程或数据分析经验,即可快速获得业务洞察。
核心功能
数据建模:采用树状层次结构管理数据,每个节点代表传感器、设备、产线或工厂,具备属性、分析、面板与事件定义,实现结构化管理。
数据情景化:支持为每个节点配置描述信息、类别、位置、物理单位、极限值等,让数据具备丰富的业务语义。
数据标准化:通过模板与映射关系实现多源数据统一,包括单位自动转换与计算表达式管理。
实时分析:基于 TDengine 流式计算能力,支持滑动窗口、事件窗口、状态窗口等实时计算,快速发现异常与趋势。
事件管理:分析结果可触发事件与告警,并支持确认、升级与回溯分析。
数据可视化:内置 Grafana 风格面板,提供趋势图、柱状图、仪表盘等多种展示方式,支持自定义看板。
无问智推与智能问数:结合 AI 模型自动推荐分析任务和报表,用户可通过自然语言发起分析请求或创建可视化面板。
企业级管理:提供基于角色的权限控制、版本管理、单点登录及数据导入导出功能。
系统关系与定位
TDengine IDMP 不直接存储时序数据,而是基于 TDengine TSDB 或其他数据库运行,负责上层的数据管理与智能洞察。它是对 TDengine TSDB 的功能补充:
TSDB 负责高性能的时序数据写入与查询;
IDMP 负责数据标准化、语义化与 AI 驱动的智能分析,与 TSDB 共同构建 AI-Ready 的数据平台。
典型应用场景
工业过程监控与优化:实时监测生产线状态、分析设备运行趋势、提升生产效率。
设备健康与预测性维护:基于振动、电流、温度等传感器数据进行健康评估与风险预测。
能源管理与可持续发展:监控能耗与碳排放,实现节能与 ESG 管理。
智慧城市与基础设施监控:支持桥梁、地铁、水务、能源等基础设施的统一监控。
八、结语:TDengine 不只是一个数据库,更是工业数据的全路径管理平台
从技术特性来看,TDengine 凭借 8:1 的高压缩比、百万级的写入吞吐量、毫秒级的查询延迟,解决了工业时序数据的存储与性能难题;从架构设计来看,其分布式集群与边缘-云协同能力,适配了工业场景的规模化与分布式需求;从价值实现来看,通过 TDgpt 与 IDMP 的融合,完成了从数据存储到智能决策的全链路赋能。
大理卷烟厂的国产化转型、蔚来汽车的车联网数据管理等案例证明,TDengine 已超越传统数据库的范畴,成为工业数据的全路径管理平台。它不仅实现了数据的高效存储与管理,更通过 AI 技术激活了数据价值,为工业数字化转型提供了坚实的技术底座。
在国产化替代与 AI 赋能的双重趋势下,TDengine 正推动工业数据管理进入 "存储更高效、分析更智能、决策更精准" 的新时代,成为工业企业实现降本增效、提质升级的核心驱动力。