【Block总结】MSC,多尺度稀疏交叉注意力网络在遥感场景分类中的应用|即插即用
📄 论文基本信息
| 项目 | 内容 |
|---|---|
| 标题 | Multiscale Sparse Cross-Attention Network for Remote Sensing Scene Classification (MSCN) |
| 中文题目 | 多尺度稀疏交叉注意力网络在遥感场景分类中的应用 |
| 发表期刊 | IEEE Transactions on Geoscience and Remote Sensing (TGRS) 2025 |
| 所属单位 | 西安电子科技大学人工智能学院、南京理工大学计算机科学与工程学院 |
| 核心目标 | 解决遥感图像中因目标尺度多变、小目标易丢失以及背景复杂带来的分类挑战。 |
💡 论文主要创新点
该论文的创新性主要体现在以下三个层面:
- 新颖的网络架构(MSCN):提出了一个多尺度稀疏交叉注意力网络,其核心思想是将高层语义特征与每一个浅层细节特征进行交叉融合,改变了传统方法中简单的特征拼接方式,从而更充分地挖掘不同层级特征中的互补信息。
- 核心的注意力机制(MSC):设计了多尺度稀疏交叉注意力(MSC)机制,通过多尺度池化捕捉复杂内容,并创新性地引入TopK稀疏操作过滤掉大量无关信息,从而在提升特征表达能力的同时,增强模型的抗干扰能力。
- 特征增强模块(GCE):开发了多组空间通道注意力机制(GCE),该模块通过分组处理并强化关键特征的注意力权重,使得最终用于分类的特征更具判别力。
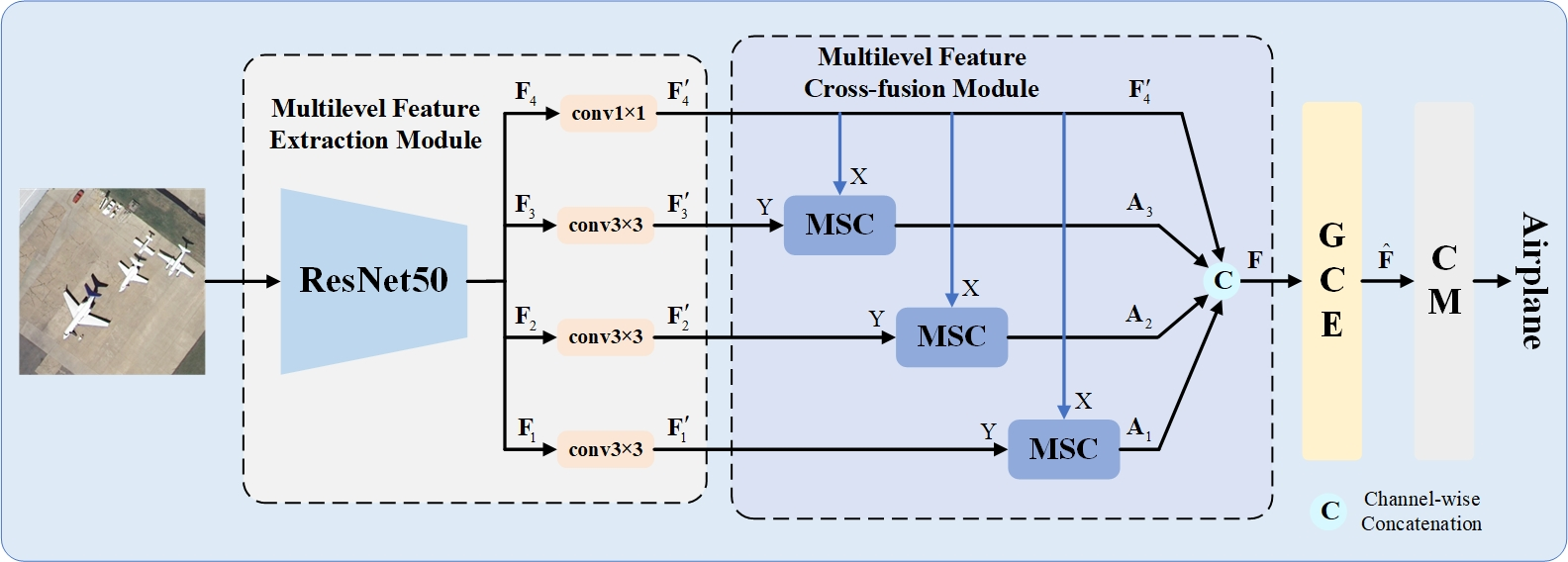
🛠️ 方法详解:MSCN如何工作
MSCN的整体框架包含四个主要组件,其工作流程如下:
🔍 核心组件解析
-
多级特征提取模块(MFEM):该模块使用卷积神经网络(CNN)作为主干,从输入图像中提取出低、中、高三个层级的特征。其中,浅层特征包含丰富的细节信息(如纹理、边缘),而深层特征则包含更强的语义信息(如物体类别)。
-
多级特征交叉融合模块(MFCM):这是论文的核心。该模块通过多尺度稀疏交叉注意力(MSC)机制,将高层特征与每一个浅层特征进行交叉融合。这样做的好处是,能够用深层语义来引导和增强浅层特征,使细节信息也具有类别判别性,同时避免了小目标在深层网络中丢失的问题。
-
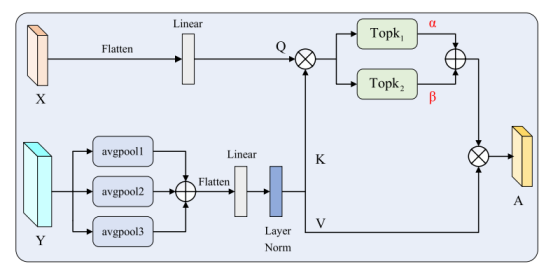
多尺度稀疏交叉注意力(MSC)机制:其内部操作可分为四步:
- 多尺度信息提取:对输入特征进行不同窗口大小的平均池化,捕获从局部细节到全局结构的多种尺度信息。
- 特征映射:将融合后的多尺度特征与另一输入特征分别映射为查询(Q)、键(K)、值(V)矩阵。
- 稀疏操作:计算注意力矩阵后,使用两次TopK操作进行稀疏化。一次保留较多元素以把握整体关联,一次保留较少元素以聚焦最核心的部分,从而有效过滤掉无关噪声。
- 自适应融合:通过可学习的参数自适应地融合两种稀疏化后的注意力图,最后与值矩阵加权得到输出。
-
全局上下文增强器(GCE)与分类模块(CM):GCE模块对融合后的特征进一步施加注意力,增强关键区域的权重。最后,CM模块执行最终的场景分类。
代码
import torch
import torch.nn as nn
from einops import rearrange
from math import sqrtclass MSC(nn.Module):def __init__(self, dim, num_heads=8, topk=True, kernel=[3, 5, 7], s=[1, 1, 1], pad=[1, 2, 3],qkv_bias=False, qk_scale=None, attn_drop_ratio=0., proj_drop_ratio=0., k1=2, k2=3):super(MSC, self).__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5self.q = nn.Linear(dim, dim, bias=qkv_bias)self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop_ratio)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop_ratio)self.k1 = k1self.k2 = k2self.attn1 = torch.nn.Parameter(torch.tensor([0.5]), requires_grad=True)self.attn2 = torch.nn.Parameter(torch.tensor([0.5]), requires_grad=True)# self.attn3 = torch.nn.Parameter(torch.tensor([0.3]), requires_grad=True)self.avgpool1 = nn.AvgPool2d(kernel_size=kernel[0], stride=s[0], padding=pad[0])self.avgpool2 = nn.AvgPool2d(kernel_size=kernel[1], stride=s[1], padding=pad[1])self.avgpool3 = nn.AvgPool2d(kernel_size=kernel[2], stride=s[2], padding=pad[2])self.layer_norm = nn.LayerNorm(dim)self.topk = topk # False Truedef forward(self, x, y):# x0 = xy1 = self.avgpool1(y)y2 = self.avgpool2(y)y3 = self.avgpool3(y)# y = torch.cat([y1.flatten(-2,-1),y2.flatten(-2,-1),y3.flatten(-2,-1)],dim = -1)y = y1 + y2 + y3y = y.flatten(-2, -1)y = y.transpose(1, 2)y = self.layer_norm(y)x = rearrange(x, 'b c h w -> b (h w) c')# y = rearrange(y,'b c h w -> b (h w) c')B, N1, C = y.shape# print(y.shape)kv = self.kv(y).reshape(B, N1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)k, v = kv[0], kv[1]# qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)B, N, C = x.shapeq = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)attn = (q @ k.transpose(-2, -1)) * self.scale# print(self.k1,self.k2)mask1 = torch.zeros(B, self.num_heads, N, N1, device=x.device, requires_grad=False)index = torch.topk(attn, k=int(N1 / self.k1), dim=-1, largest=True)[1]# print(index[0,:,48])mask1.scatter_(-1, index, 1.)attn1 = torch.where(mask1 > 0, attn, torch.full_like(attn, float('-inf')))attn1 = attn1.softmax(dim=-1)attn1 = self.attn_drop(attn1)out1 = (attn1 @ v)mask2 = torch.zeros(B, self.num_heads, N, N1, device=x.device, requires_grad=False)index = torch.topk(attn, k=int(N1 / self.k2), dim=-1, largest=True)[1]# print(index[0,:,48])mask2.scatter_(-1, index, 1.)attn2 = torch.where(mask2 > 0, attn, torch.full_like(attn, float('-inf')))attn2 = attn2.softmax(dim=-1)attn2 = self.attn_drop(attn2)out2 = (attn2 @ v)out = out1 * self.attn1 + out2 * self.attn2 # + out3 * self.attn3# out = out1 * self.attn1 + out2 * self.attn2x = out.transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)hw = int(sqrt(N))x = rearrange(x, 'b (h w) c -> b c h w', h=hw, w=hw)# x = x + x0return x# 测试代码
if __name__ == '__main__':input = torch.randn(1, 32, 64, 64) # [B, C=32, H=64, W=64]input1 = torch.randn(1, 32, 64, 64) # [B, C=32, H=64, W=64]model = MSC(dim=32)output = model(input,input1)print("输入张量形状:", input.shape)print("输出张量形状:", output.shape)
📊 效果与总结
性能效果
根据论文介绍,MSCN模型在多个公开遥感场景分类数据集上进行了实验,并取得了优异的效果。
- 有效性:实验结果验证了MSCN模型及其核心组件(MSC机制、GCE模块)能够显著提升遥感场景分类的准确率。
- 抗干扰性:得益于稀疏注意力机制,模型对复杂背景和无关信息具有更好的鲁棒性。
- 小目标友好:多尺度交叉融合策略有效缓解了小目标特征在深层网络中被丢失的问题,提升了像“小型飞机”这类目标的分类精度。
总结
总而言之,这篇论文针对遥感场景分类中的核心难题,提出了一个结构新颖、机制有效的解决方案。MSCN网络通过多尺度稀疏交叉注意力成功实现了对多层次特征的高效融合与去噪,在保持计算效率的同时,显著提升了模型的分类性能。这项工作为后续的遥感图像分析研究提供了重要的技术参考和思路启发。
希望以上总结对你有所帮助。如果你对论文中提到的具体实验数据或与其它模型的对比细节感兴趣,我可以尝试帮你进一步寻找相关信息。