Week 23: 深度学习补遗:Transformer整体构建
文章目录
- Week 23: 深度学习补遗:Transformer整体构建
- 摘要
- Abstract
- 1. Transformer Decoder 解码器
- 1.1 概要
- 1.2 代码实现
- 1.3 关键特性
- 2. Padding Mask 填充掩码
- 2.1 概要
- 2.2 代码实现
- 2.3 效果简析
- 3. Transformer 整体架构总览
- 3.1 概要
- 3.2 掩码机制
- 3.3 整体协同机制
- 总结
Week 23: 深度学习补遗:Transformer整体构建
摘要
本周主要完成了Transformer的Decoder部分构建和整体的构建,同时对掩码机制进行了一定的了解。从更加全面的角度对Transformer进行认识,同时对一个机器学习模型,尤其是Encoder-Decoder架构的模型的实际架构有了初步的了解。
Abstract
This week’s primary focus was on constructing the Decoder component of the Transformer and completing the overall architecture, whilst gaining a foundational understanding of the masking mechanism. This has provided a more comprehensive grasp of the Transformer, alongside an initial appreciation of the practical architecture of machine learning models, particularly those employing the Encoder-Decoder framework.
1. Transformer Decoder 解码器
1.1 概要
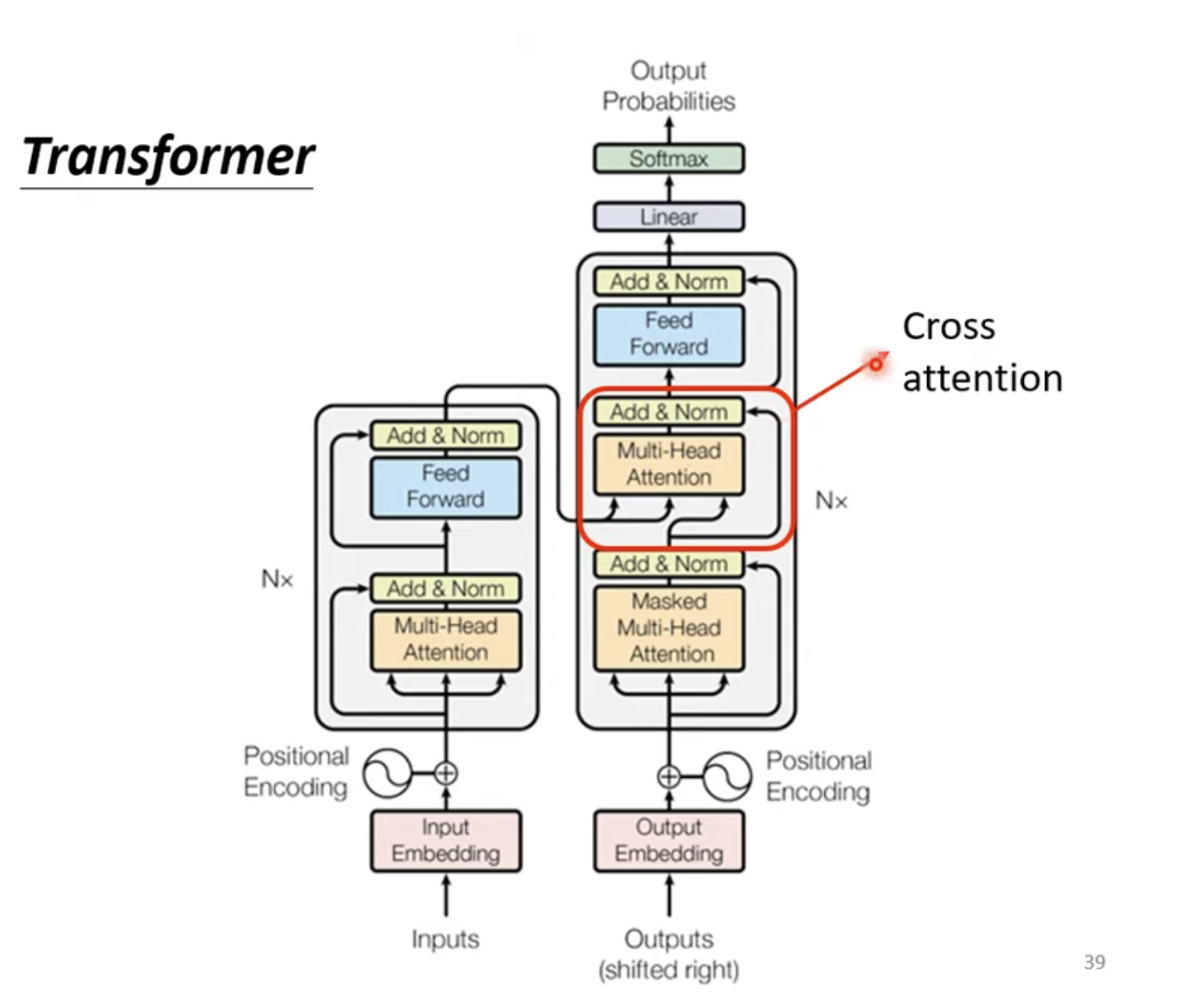
Transformer Decoder作为序列生成的核心组件,其设计巧妙地融合了自回归机制与编码器-解码器架构。与编码器的单向信息流动不同,解码器通过三个关键模块实现了对已生成序列的建模和对源序列信息的融合。其数学核心可表示为:
Self-Attention: SA(X)=softmax(XWQ(XWK)Tdk+Mcausal)XWVCross-Attention: CA(Q,K,V)=softmax(QWQ(KWK)Tdk+Mpad)VWVOutput: Y=FC(LayerNorm(X+Dropout(CA(LayerNorm(X+Dropout(SA(X)),Z)))))WO\begin{aligned} \text{Self-Attention: } \text{SA}(X) &= \text{softmax}\left(\frac{XW_Q(XW_K)^T}{\sqrt{d_k}} + M_{\text{causal}}\right)XW_V \\ \text{Cross-Attention: } \text{CA}(Q, K, V) &= \text{softmax}\left(\frac{QW_Q(KW_K)^T}{\sqrt{d_k}} + M_{\text{pad}}\right)VW_V \\ \text{Output: } Y &= \text{FC}(\text{LayerNorm}(X + \text{Dropout}(\text{CA}(\text{LayerNorm}(X + \text{Dropout}(\text{SA}(X)), Z)))))W_O \end{aligned} Self-Attention: SA(X)Cross-Attention: CA(Q,K,V)Output: Y=softmax(dkXWQ(XWK)T+Mcausal)XWV=softmax(dkQWQ(KWK)T+Mpad)VWV=FC(LayerNorm(X+Dropout(CA(LayerNorm(X+Dropout(SA(X)),Z)))))WO
其中McausalM_{\text{causal}}Mcausal为因果掩码,确保自回归性质;MpadM_{\text{pad}}Mpad为填充掩码,屏蔽无效位置。
1.2 代码实现
class DecoderLayer(nn.Module):def __init__(self, d_model, num_heads, hidden, dropout=0.1):super().__init__()self.self_attention = MultiHeadAttention(d_model, num_heads)self.cross_attention = MultiHeadAttention(d_model, num_heads)self.ffn = FeedForward(d_model, hidden, dropout)# 三个归一化层分别对应三个子层self.norm1, self.norm2, self.norm3 = LayerNorm(d_model), LayerNorm(d_model), LayerNorm(d_model)self.dropout1, self.dropout2, self.dropout3 = nn.Dropout(dropout), nn.Dropout(dropout), nn.Dropout(dropout)def forward(self, x, enc_output, src_mask=None, tgt_mask=None):# 自注意力:处理目标序列内部依赖关系attn_output = self.self_attention(x, x, x, tgt_mask)x = x + self.dropout1(attn_output)x = self.norm1(x)# 交叉注意力:融合编码器输出信息attn_output = self.cross_attention(x, enc_output, enc_output, src_mask)x = x + self.dropout2(attn_output)x = self.norm2(x)# 前馈网络:非线性变换ffn_output = self.ffn(x)x = x + self.dropout3(ffn_output)x = self.norm3(x)return x
1.3 关键特性
Transformer Decoder的独特之处在于其双重注意力机制:自注意力模块通过因果掩码实现"只看过去"的自回归约束,确保生成过程的因果性;交叉注意力模块则作为Encoder-Decoder间的桥梁,让解码器能够动态关注源序列的不同部分。每个子层均采用残差连接与层归一化,缓解深层网络的梯度消失问题。最终通过线性投影将隐藏状态映射到Voc Embedding空间,为下一个Token的预测提供概率分布。
2. Padding Mask 填充掩码
2.1 概要
填充掩码作为Transformer中处理变长序列的关键机制,其核心在于屏蔽注意力计算中填充位置的影响,确保模型只关注有效的序列信息。其数学本质可表述为对注意力分数的逐位置抑制:
Attention(Q,K,V)=softmax(QKTdk+Mpad)V\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + M_{\text{pad}}\right)V Attention(Q,K,V)=softmax(dkQKT+Mpad)V
其中 MpadM_{\text{pad}}Mpad 为填充掩码矩阵,填充位置对应元素设为 −∞-\infty−∞,有效位置为 000,从而在softmax计算中使填充位置的注意力权重趋近于 000。
2.2 代码实现
def make_pad_mask(self, q, k, pad_idx_q, pad_idx_k):len_q, len_k = q.size(1), k.size(1)pad_mask_q = (q != pad_idx_q).unsqueeze(1).unsqueeze(3) # [batch, 1, len_q, 1]pad_mask_k = (k != pad_idx_k).unsqueeze(1).unsqueeze(2) # [batch, 1, 1, len_k]pad_mask = pad_mask_q & pad_mask_k # [batch, 1, len_q, len_k]return pad_mask
这一实现巧妙地利用了广播机制,通过将查询序列和键序列的非填充标记分别扩展为四维张量,再进行按位与运算,得到最终的填充掩码矩阵。在MultiHeadAttention中,通过 score.masked_fill(mask == 0, float('-inf')) 将无效位置的注意力分数设为负无穷大,确保softmax后的权重分布符合预期。
2.3 效果简析
填充掩码广泛应用于自注意力机制和交叉注意力机制中,既能在编码器阶段处理源序列的填充Token,又能在解码器的自注意力中屏蔽目标序列的填充位置,同时在交叉注意力中确保解码器不会关注编码器输出的填充部分,从而实现了对变长序列的统一处理。
| 序列 | 1 | 2 | 3 | 4 | 5 | 原始长度 |
|---|---|---|---|---|---|---|
| Sequence 1 | 0 (有效) | 0 (有效) | 0 (有效) | 1 (遮蔽) | 1 (遮蔽) | 3 |
| Sequence 2 | 0 (有效) | 0 (有效) | 0 (有效) | 0 (有效) | 0 (有效) | 5 |
| Sequence 3 | 0 (有效) | 0 (有效) | 1 (遮蔽) | 1 (遮蔽) | 1 (遮蔽) | 2 |
在可视化中,0 (有效) 表示该位置是序列的原始内容,模型应该关注它。1 (遮蔽) 表示该位置是填充部分,模型应该忽略它。
简单来说就是对于不同的输入长度,通过Mask让其不受长度的影响,遮蔽空白的Token。
3. Transformer 整体架构总览
3.1 概要
Transformer作为端到端序列建模的里程碑式架构,其核心创新在于精心设计的掩码机制与双重注意力策略的协同作用。通过编码器-解码器的分层处理,配合多种掩码约束,实现了从源序列到目标序列的精准转换。其数学核心可表述为多层次的掩码约束注意力计算:
Source Attention: Asrc=softmax(QsrcKsrcTdk+Mpadsrc)VsrcTarget Self-Attention: Atgt=softmax(QtgtKtgtTdk+Mpadtgt+Mcausal)VtgtCross-Attention: Across=softmax(QtgtKsrcTdk+Mpadcross)Vsrc\begin{aligned} \text{Source Attention: } & A_{src} = \text{softmax}\left(\frac{Q_{src}K_{src}^T}{\sqrt{d_k}} + M_{pad}^{src}\right)V_{src} \\ \text{Target Self-Attention: } & A_{tgt} = \text{softmax}\left(\frac{Q_{tgt}K_{tgt}^T}{\sqrt{d_k}} + M_{pad}^{tgt} + M_{causal}\right)V_{tgt} \\ \text{Cross-Attention: } & A_{cross} = \text{softmax}\left(\frac{Q_{tgt}K_{src}^T}{\sqrt{d_k}} + M_{pad}^{cross}\right)V_{src} \end{aligned} Source Attention: Target Self-Attention: Cross-Attention: Asrc=softmax(dkQsrcKsrcT+Mpadsrc)VsrcAtgt=softmax(dkQtgtKtgtT+Mpadtgt+Mcausal)VtgtAcross=softmax(dkQtgtKsrcT+Mpadcross)Vsrc
其中三种掩码机制分别处理填充屏蔽、自回归约束和跨序列对齐问题。
3.2 掩码机制
- 填充掩码(Padding Mask)
填充掩码确保模型注意力机制不会关注序列中的填充token,其实现通过四维张量的广播机制实现。这种设计巧妙地利用了PyTorch的广播机制,确保查询和键的配对都是有效位置,在自注意力和交叉注意力中都能正确屏蔽填充位置。
def make_pad_mask(self, q, k, pad_idx_q, pad_idx_k):"""生成填充掩码,屏蔽padding token"""len_q, len_k = q.size(1), k.size(1)pad_mask_q = (q != pad_idx_q).unsqueeze(1).unsqueeze(3) # [batch, 1, len_q, 1]pad_mask_k = (k != pad_idx_k).unsqueeze(1).unsqueeze(2) # [batch, 1, 1, len_k]return pad_mask_q & pad_mask_k # [batch, 1, len_q, len_k]
- 因果掩码(Causal Mask)
因果掩码实现自回归约束,确保解码器在生成当前位置时只能看到之前的位置信息。通过下三角矩阵的构建,将未来位置的注意力分数设为负无穷,从而在Softmax计算中使这些位置的权重为0,严格维护了时间序列的因果性,保证了训练的效果。
def make_causal_mask(self, q, k):"""生成因果掩码,确保自回归性质"""len_q, len_k = q.size(1), k.size(1)return torch.tril(torch.ones(len_q, len_k)).type(torch.bool)
- 交叉注意力掩码(Cross-Attention Mask)
交叉注意力掩码处理解码器对编码器输出的关注约束,确保解码器不会关注源序列中的填充位置。这一掩码在解码器的交叉注意力模块中起到关键作用,使解码器能够动态地将目标序列的每个位置与源序列的有效位置进行对齐。
src_tgt_mask = self.make_pad_mask(tgt, src, self.tgt_pad_idx, self.src_pad_idx)
3.3 整体协同机制
交叉注意力作为Transformer的核心创新之一,实现了编码器-解码器间的信息桥梁:
attn_output = self.cross_attention(x, enc_output, enc_output, src_mask)
其数学本质是将解码器的当前状态作为查询(Query),编码器的输出作为键(Key)和值(Value),通过注意力机制动态计算目标序列每个位置应该关注源序列的哪些部分。这种设计使得模型能够根据不同的生成阶段,灵活地调整对源序列不同部分的关注度,从而实现精准的跨语言信息转换。
def forward(self, src, tgt):# 三种掩码的协同作用src_mask = self.make_pad_mask(src, src, self.src_pad_idx, self.src_pad_idx) # 源序列填充掩码tgt_mask = self.make_pad_mask(tgt, tgt, self.tgt_pad_idx, self.tgt_pad_idx) & self.make_causal_mask(tgt, tgt) # 目标序列填充+因果掩码src_tgt_mask = self.make_pad_mask(tgt, src, self.tgt_pad_idx, self.src_pad_idx) # 交叉注意力填充掩码enc_output = self.encoder(src, src_mask) # 编码阶段dec_output = self.decoder(tgt, enc_output, src_tgt_mask, tgt_mask) # 解码阶段return dec_output
通过填充掩码确保模型只关注有效信息,通过因果掩码维护自回归的时间约束,通过交叉注意力掩码实现跨序列的精准对齐。这三种掩码机制与双重注意力策略的协同作用,使Transformer能够在严格的约束条件下实现高度灵活的序列建模,
总结
本周,对Transformer模型的构建进行了收尾,更主要的关注在了Transformer模型上的几个灵魂部分,Mask机制上,体会到了不同的Mask机制的不同作用。其次,通过的Transformer模型的构建,初步的了解到了一个现代机器学习模型在PyTorch上的构建结构。最后,在理解了Transformer的基础上,后续可以在阅读论文的同时快速对代码进行构建和复现的尝试,理解不同论文的创新以及创新的实现方式。