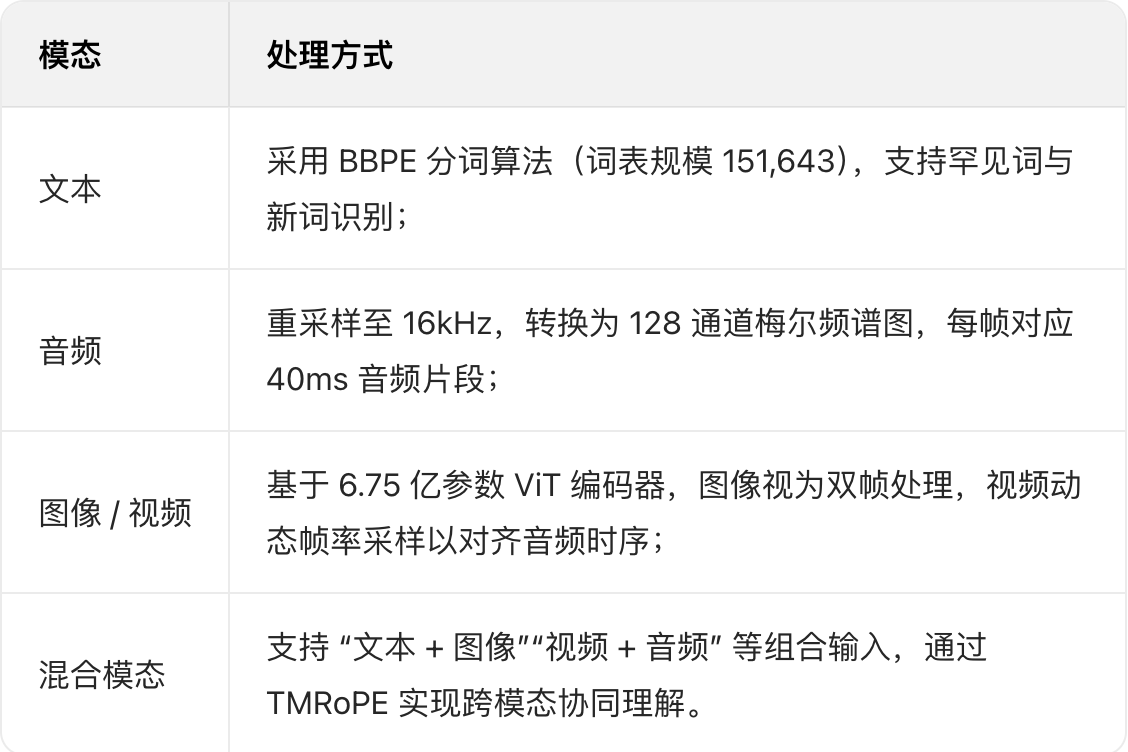
Qwen2.5-Omni、TMRoPE-Time Aligned Rotary Positional Embedding 概念
什么是 diarization
diarization 说话人识别:一种自动识别和标记音频或视频中不同说话人的过程。用于语音识别、会议记录和电话会议等场景
homogeneous ˌhɒməˈdʒiːniəs 同种类的,同性质的;齐性的,齐次的;同形态(固态、液态或气态)的
transcription trænˈskrɪpʃ(ə)n 抄写,打印;抄本,文字记录;音标,标音;乐曲改编;(生化)转录
spoke spəʊk n. 辐条,轮辐;伞骨;(船的)舵轮把柄;扶梯棍;v. 谈话,交谈;说,讲述;(会)讲(某种语言)(speak 的过去式)
auspices ˈɔːspɪsɪz 赞助;保护;预兆(auspice 的复数)
auspice ˈɔːspɪs 赞助,主办;吉兆
devote dɪˈvəʊt v. 献身,致力;用于
manifest ˈmænɪfest
v. 显示,表明;(鬼魂或神灵)显灵,出现;(病症)显现;把……列入货单;显化(指通过可视化和积极思考来帮助梦想成真)
adj. 明显的,显而易见的
n. 旅客名单,载货清单;货运列车编组清单;清单文件,是一个在软件、系统、容器、压缩包等场景中高频出现的核心文件,记录某个对象(如程序、镜像、压缩包)的关键元信息,确保其可识别、可验证、可正确运行或解析
specific spəˈsɪfɪk
adj. 明确的,具体的;特定的;特有的,独特的;有特殊功能的,有特效的;(生物)种的;(关税,税)按数量(根据固定税率)征取而非按货价征取的;(物理)(与参照物同一性质成)比率的
n. 细节,详情;特效药
Speaker diarisation (or diarization) is the process of partitioning an input audio stream into homogeneous segments according to the speaker identity. It can enhance the readability of an automatic speech transcription by structuring the audio stream into speaker turns and, when used together with speaker recognition systems, by providing the speaker’s true identity. It is used to answer the question “who spoke when?” Speaker diarisation is a combination of speaker segmentation and speaker clustering.
The first aims at finding speaker change points in an audio stream. The second aims at grouping together speech segments on the basis of speaker characteristics.
With the increasing number of broadcasts, meeting recordings and voice mail collected every year, speaker diarisation has received much attention by the speech community, as is manifested by the specific evaluations devoted to it under the auspices of the National Institute of Standards and Technology for telephone speech, broadcast news and meetings.
说话人分节(或分节)(speaker diarisation)是根据说话人身份将输入音频流划分为同质段(homogeneous segments)的过程。它可以通过将音频流组织成说话人的旋转来提高自动语音转录(speech transcription)的可读性,当与说话人识别系统(speaker recognition system)一起使用时,它可以提供说话人的真实身份。它用来回答“谁在什么时候说的?”,speaker diarisation 是说话人分割和说话人聚类的结合。
第一个目标是在音频流中找到说话人的变化点。
第二种方法是根据说话人的特征对语音片段进行分组。
随着每年收集的广播、会议录音和语音邮件数量的增加,speaker diarisation 受到了语言界(speech community)的广泛关注,这一点在服务于电话演讲、广播新闻、会议的美国国家标准与技术研究院(National Institute of Standards and Technology,简称 NIST)的主持(auspices)下对其进行的具体评估(specific evaluations)中得到了体现
在xx中得到了体现:as is manifested by
在具体评估中得到了体现:as is manifested by the specific evaluations
前置信息
m3 : multi mode memory
flagship: ˈflæɡʃɪp 旗舰;(作定语)一流;佼佼者
multimodal:ˌmʌltɪˈməʊdəl
adj. [统计] 多峰的;多模式的
n.多峰
intermediate:ˌɪntəˈmiːdiət 中间
perception pəˈsepʃ(ə)n 看法,认识;感觉,感知;洞察力;<法律>(租金、农作物等的)收取,占有
seamlessly:无缝的
synthesis ˈsɪnθəsɪs 综合,综合体;(化学物质的)合成;音响合成;(黑格尔哲学中的)合题;(语法)合成;(语言学)综合
comprehensive ˌkɒmprɪˈhensɪv
adj. 综合性的,全面的;有理解力的
n. 综合中学;专业综合测验
SOTA 是 State of the Art 的缩写,“当前技术水平”,核心含义是某一领域或特定任务中当前最先进、性能最优的技术方案、模型或成果
使用大模型
https://github.com/QwenLM/Qwen2.5-Omni
Qwen2.5-Omni is an end-to-end multimodal model by Qwen team at Alibaba Cloud, capable of understanding text, audio, vision, video, and performing real-time speech generation.
Qwen2.5-Omni, the new flagship end-to-end multimodal model in the Qwen series. Designed for comprehensive multimodal perception, it seamlessly processes diverse inputs including text, images, audio, and video, while delivering real-time streaming responses through both text generation and natural speech synthesis.
Qwen2.5-Omni, qwen2.5系列全新旗舰端到端多模态模型。它专为全面的多模态感知而设计,无缝地处理各种输入,包括文本、图像、音频和视频,同时通过文本生成和自然语音合成提供实时流响应
核心定位与设计目标
核心定位:打破模态壁垒,实现 “感知 - 理解 - 生成” 全流程端到端统一,无需拼接独立模型,原生支持跨模态协同处理
设计目标:
- 高效融合文本、图像、音频、视频等模态,实现模态间相互增强
- 解决多模态输出干扰问题,确保文本与语音生成互不冲突
- 优化实时性与低延迟,适配 AI 助手、语音交互界面等实际场景
核心技术创新:
- Thinker-Talker 双核架构(核心亮点)
模拟人类 “思考 - 表达” 逻辑,实现文本与语音的并行生成:
- Thinker(思考模块):类似 “大脑”,基于 Transformer 解码器架构,融合音频 / 图像编码器提取特征,负责处理多模态输入、理解语义、生成高层级表征及对应文本(如问答回复、场景描述)
- Talker(表达模块):类似 “发声器官”,采用双轨自回归 Transformer 解码器,实时接收 Thinker 的语义表征与文本,流式生成离散语音单元并转换为自然波形,无需强制时序对齐
两者共享历史上下文信息,支持端到端联合训练,确保文本与语音响应的一致性和连贯性
- TMRoPE 时间对齐多模态位置编码
解决多模态数据(尤其是音频与视频)的时间同步问题:
- 将位置编码拆解为时间、高度、宽度三维维度,适配不同模态的特性(文本仅需时间维度,图像需空间维度,音频仅需时间维度)
- 音频帧(每帧对应 40ms 原始音频)与视频帧按时间轴对齐,通过 “时间交错法” 每 2 秒分块排列,确保时序一致性
- 跨模态位置编号规则:后一模态的位置 ID 从前一模态最大 ID 加 1 开始,避免注意力机制混淆,即针对输入的语音、文字、图像、视频等,按照模态赋值不同的位置ID区间给不同的模态使用
- 流式处理与低延迟优化
多模态编码器采用分块流式处理,无需等待全部数据加载,支持实时预填充与分段处理,适配长序列音视频数据
结合滑动窗口 DiT(扩散 Transformer)模型,最小化语音生成的初始延迟,流式语音的自然度与稳健性优于多数现有方案
性能优势
- 单模态任务:图像能力与 Qwen2.5-VL 相当,音频能力优于 Qwen2-Audio;语音识别错误率较同类模型降低 23%(CommonVoice 数据集),视频理解准确率 89.2%(MVBench 数据集),超越 Gemini-1.5 Pro
- 多模态任务:在 OmniBench、AV-Odyssey Bench 等权威榜单中取 SOTA(当前最优)成绩,跨模态推理综合得分 91.5(开源模型新高)
- 指令跟随:端到端语音指令跟随能力与文本输入处理水平相当,在 MMLU 通用知识、GSM8K 数学推理等基准测试中表现优异
典型应用场景
- 智能交互助手:支持语音 + 视觉多轮对话(如智能家居控制、车载语音助手)
- 跨模态内容处理:图文问答、视频摘要生成、音频转写 + 翻译、图像 / 文档解析(合同截图、流程图分析)
- 实时音视频应用:直播字幕生成、在线教育实时讲解、视频会议语音转写与总结
- 多模态搜索与分析:基于图像 / 音频 / 视频内容的精准检索、企业多模态数据(如产品视频、客服录音)分析
什么是端到端语音指令跟随能力
AI 模型直接接收原始语音信号作为输入,无需人工拆分 “语音转文字(ASR)→ 文本理解 → 指令执行 → 文字转语音(TTS)” 等独立步骤
通过统一的端到端架构完成 “听懂指令→理解意图→执行任务→生成响应” 全流程的核心能力
模型能像人类对话一样,直接 “听” 懂语音指令并精准完成任务,无需中间环节的人工干预或模块拼接
区别于传统语音交互的关键
- 具备该能力的模型(如 Qwen2.5-Omni)通过统一架构(如 Thinker-Talker 双核设计),直接处理原始语音信号,实现 “输入语音→输出结果” 的端到端闭环,避免了模块间的数据损耗或适配问题
- 理解 + 执行双精准,媲美文本输入,不仅能准确识别语音中的关键词、语义逻辑(比如区分 “查询天气” 和 “设置闹钟” 的不同意图),还能完成复杂任务(如数学推理、通用知识问答、多模态协同任务),性能与 “文本输入→模型响应” 的效果相当
- 实时流式响应,交互自然支持 “分块输入 + 即时输出”,无需等待完整语音指令结束就能开始处理,响应延迟可低至 0.1 秒,类似真人对话的实时反馈。同时生成的语音响应自然流畅,减少发音错误、不当停顿等问题,交互体验更接近真实沟通
- 多模态协同兼容,能结合语音与其他模态(图像、视频、文本)完成复杂指令,比如 “听语音指令 + 看图片,描述图中物体”、“听语音需求 + 分析视频内容,生成步骤指导”,这依赖于模型对多模态信息的统一融合能力(如 Qwen2.5-Omni 的 TMRoPE 技术实现音频与视频的时间轴对齐,确保多模态指令的精准同步)
典型应用场景
- 智能语音助手:直接语音指令 “设置明天 7 点的闹钟”、“查询最近的咖啡店”,模型实时响应并完成操作,无需手动输入辅助
- 多模态协同任务:语音指令 “分析这个视频里的食材,告诉我烹饪步骤”(结合视频 + 语音)、“看这张图片,用语音说明它的主题”(结合图像 + 语音)
- 专业场景交互:视障者的实时语音导航(“前面是否有障碍物”)、智能客服的语音咨询(“查询订单物流”)、教育场景的语音答疑(“用语音讲这道数学题的解法”)
- 终端设备部署:因架构轻量化(如 Qwen2.5-Omni 仅 7B 参数),可部署在手机、笔记本等终端设备,实现离线或低延迟的语音指令跟随
核心优势
- 降低开发成本:无需单独集成 ASR、TTS、语言理解等模块,减少模块适配、数据校准的工作量,开发者直接基于模型快速搭建语音交互应用
- 提升交互效率:端到端架构减少中间环节的耗时,实时流式响应让对话更流畅,避免用户长时间等待
- 增强鲁棒性:避免了传统方案中 “某一模块出错导致全流程失效” 的问题(比如 ASR 转写错误影响后续理解),整体稳定性更高
- 适配复杂场景:能处理带口音、语速变化、背景噪音的语音指令,同时支持复杂逻辑任务(如多步骤指令、推理类需求),适用范围更广
端到端语音指令跟随能力,让 AI 的语音交互从 “机械的‘转文字→处理→转语音’拼接”,升级为 “类人类的‘听懂→理解→执行’自然沟通”
它不仅简化了技术落地流程,更让语音交互更高效、更自然,成为智能助手、多模态交互、终端 AI 等场景的核心技术支撑
什么是128通道梅尔频谱图(Mel Spectrum)
spectrum ˈspektrəm 范围,幅度;光谱;波谱,频谱;余象
音频信号处理中的一种高维度特征表示形式,核心是将原始音频(如声波)转换为符合人类听觉特性的 128 维特征图
既能保留关键音频信息,又能压缩冗余数据,是语音识别、音频分类、语音生成等任务的核心输入特征
人类听觉对低频声音(如 200-2000Hz)的频率变化更敏感,对高频声音(如 10000Hz 以上)的敏感度降低
梅尔频谱基于 “梅尔刻度(Mel Scale)”—— 一种模拟人类听觉特性的频率映射,将线性频率(Hz)转换为非线性的梅尔频率(Mel),让特征更贴合人类对声音的感知逻辑
通道(Channel)对应 “梅尔频率带” 的数量
128 通道意味着将音频的梅尔频率范围(通常是 0-8KHz or 0-16KHz)均匀划分为 128 个连续频率带,每个通道对应一个频率带的能量值
类比理解:就像把钢琴键盘分成 128 个音区,每个音区的 “平均音量” 就是一个通道的数值
频谱图(Spectrogram)以 “时间” 为横轴、“频率(这里是梅尔频率)” 为纵轴、“能量(或幅度)” 为颜色 / 数值的二维图。
128 通道梅尔频谱图的纵轴就是 128 个梅尔频率带(对应 128 个通道)
横轴是时间帧(如每帧对应 40ms 音频),每个 “时间 - 频率” 交点的数值代表该时刻、该频率带的声音能量
生成流程(从原始音频到 128 通道梅尔频谱图),原始音频(如.wav 文件)是连续的声波信号,需通过 4 步转换为目标特征:
- 音频采样将连续声波转换为离散数字信号,比如按 16kHz 采样率(每秒取 16000 个点)处理,得到一维的 “时间 - 振幅” 序列
- 分帧与加窗将长音频切分为短时间帧(如每帧 40ms,帧移 10ms),避免相邻帧的信号突变;对每帧加窗(如汉明窗),减少帧边缘的失真
- 傅里叶变换(STFT)对每帧信号做短时傅里叶变换(STFT),将 “时间 - 振幅” 域转换为 “频率 - 幅度” 域,得到该帧的线性频谱(Hz 频率下的能量分布)
- 梅尔滤波与通道压缩通过 128 个 “梅尔滤波器” 对线性频谱进行滤波 —— 每个滤波器对应一个梅尔频率带,计算该频率带内的总能量
最终得到 “时间帧 ×128 通道” 的二维矩阵,即 128 通道梅尔频谱图
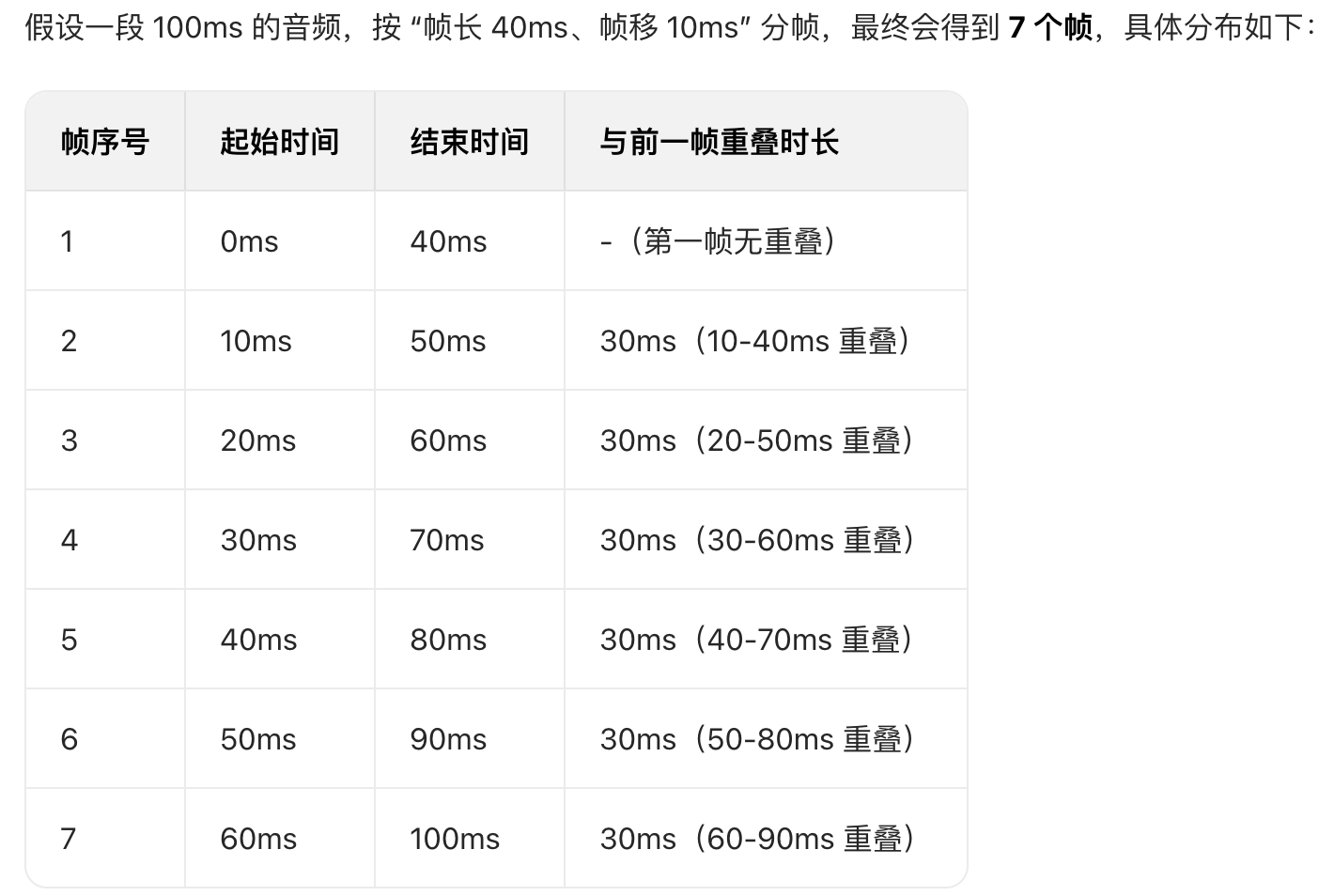
通过帧重叠避免信息丢失,“帧移(Frame Shift)” 是指从一个帧的起始位置,到下一个帧的起始位置的时间差,这里是 10ms
帧移≠帧长,两者的差值就是 “帧重叠”。比如 40ms 帧长、10ms 帧移,意味着相邻帧会重叠 40 - 10 = 30ms(重叠率 75%)
为什么需要重叠?
如果帧与帧完全不重叠(帧移 = 帧长),相邻帧的边界可能出现 “信息断裂”(比如一个音素刚好被切在两帧之间),导致后续分析遗漏细节;重叠后能让相邻帧的特征平滑过渡,避免边界失真
为什么每帧一般是 40ms?
这个时长是行业常用选择,太短会导致片段信息不足(比如无法完整包含一个元音),太长则会让片段内频率变化过大(比如包含多个音素,特征模糊),40ms 能平衡 “信息完整性” 和 “时间分辨率”
梅尔频谱的核心价值是什么?
- 把 “连续信号” 变成 “可分析的离散片段”:深度学习模型无法直接处理无限长的连续音频,分帧后每个帧都是独立的 “短样本”,可逐一提取频率、能量等特征;适配模型输入深度学习模型(如 Transformer、CNN)无法直接处理一维原始音频,128 通道的二维频谱图能将音频转换为模型可接受的 “空间特征”(类似图像的 “高度 × 宽度” 维度),同时 128 通道的维度既能保留足够的频率细节,又不会因维度过高导致计算量激增
- 平衡 “时间精度” 和 “特征稳定性”:40ms 的帧长能保证每个片段包含足够的音频信息(比如一个完整的语音音素),10ms 的帧移能让时间分辨率足够高(每 10ms 更新一次特征),既不会因帧太长丢失时间细节,也不会因帧太短导致特征不稳定;保留关键听觉信息基于梅尔刻度的设计,能重点保留人类敏感的低频信息(如语音中的辅音、元音特征),过滤高频冗余数据,让模型更高效地学习语音语义(比如区分 “你好” 和 “您好” 的发音差异)。
- 抗干扰能力强相比原始音频,梅尔频谱图对背景噪音(如环境杂音、电流声)的鲁棒性更强 —— 通过能量聚合,噪音的局部干扰会被平滑,而语音的核心频率特征会被突出,提升后续任务(如语音指令跟随)的准确率
典型应用场景
- 语音识别(ASR)作为输入特征,让模型识别语音中的文字内容(如将 “查询天气” 语音转换为文本),128 通道能平衡识别精度与计算效率
- 语音生成(TTS)在语音合成或流式语音生成中(如 Qwen2.5-Omni 的 Talker 模块),梅尔频谱图是 “文本→语音” 的中间桥梁 —— 先生成目标梅尔频谱,再通过声码器转换为可听的声波
- 音频分类区分不同类型的音频(如音乐、语音、环境音),或识别语音情感(如开心、愤怒),128 通道的频率细节能帮助模型捕捉分类关键特征
梅尔频谱图有啥用
语音识别(ASR)—— 从 “频谱图” 到 “文字”
目标是把音频对应的语义,转化为可阅读的文本(比如将 “查询天气” 的语音频谱图,输出文字 “查询天气”)
流程如下:
特征预处理(可选)
对梅尔频谱图做细节优化,减少噪音干扰:
- 加窗平滑:用汉明窗等降低频谱图的帧间突变,避免模型误判
- 归一化:将频谱图的能量值缩放到
0~1或 -1~1区间(比如减去均值、除以标准差),让模型训练更稳定 - 差分特征:计算 “当前帧 - 前一帧” 的差值,捕捉频谱的动态变化(比如语音中辅音到元音的过渡)
输入模型提取语义
用擅长处理 “二维时序特征” 的模型,从频谱图中学习语音与文字的对应关系:
常用模型:CNN(提取局部频谱特征,如 “啊”、“哦” 的频率差异)+ Transformer(捕捉长时依赖,如 “今天”“天气” 的语义关联)、CTC(Connectionist Temporal Classification,解决 “频谱帧与文字长度不匹配” 问题)
例:Qwen2.5-Omni 的语音识别模块,会先将 128 通道梅尔频谱图输入 CNN,再用 Transformer 解码器输出对应的文字 token
输出文本后处理
修正模型预测的 “粗糙文本”,提升可读性:
- 去除冗余字符(如模型误判的 “啊”“嗯” 等语气词)
- 语法纠错(如将 “今田” 修正为 “今天”)
- 标点补全(给长句添加逗号、句号,比如 “明天去公园玩”→“明天去公园玩。”)
语音生成(TTS)—— 从 “文字 / 语义” 到 “新频谱图” 再到 “音频”
目标是根据文字或语义,生成自然的语音(比如将文字 “你好”,生成对应的人声 “你好”),梅尔频谱图是 “文字→音频” 的关键中间载体
文本 / 语义转 “目标频谱图”
先把输入的文字(或模型生成的语义),转化为 “符合语音规律的梅尔频谱图”:
- 文本预处理:将文字拆分为音素(比如 “你好” 拆为 “nǐ”“hǎo”),标注声调、停顿等信息
- 模型生成:用 TTS 专用模型(如 Transformer-TTS、VITS),根据音素信息生成对应的梅尔频谱图(比如 “nǐ” 对应低频能量较高的频谱,“hǎo” 对应高频能量略高的频谱)
Qwen2.5-Omni 的 Talker 模块,会先接收 Thinker 输出的语义,再生成匹配语义的梅尔频谱图(比如 “开心” 的语音频谱,能量波动更活跃)
频谱图转 “可听音频”
用 “声码器(Vocoder)” 将梅尔频谱图还原为原始声波信号:
常用声码器:Griffin-Lim(简单但音质一般)、HiFi-GAN(高保真,能还原人声细节)、MelGAN(速度快,适合实时生成)
原理:声码器会根据频谱图的 “频率 - 能量 - 时间” 信息,反向计算出对应的声波振幅,最终生成可播放的音频文件(如.wav 格式)
音频分类 / 识别 —— 从 “频谱图” 到 “类别标签”
给音频打 “分类标签”(比如判断一段频谱图对应的是 “音乐”、“人声” 还是 “环境噪音”,或识别语音中的情感是 “开心”“愤怒”)
特征增强(突出分类关键信息)
针对分类任务优化频谱图:
- 裁剪无效区域:去掉频谱图中能量接近 0 的高频 / 低频部分(比如人类语音主要集中在 200~8000Hz,高于 16000Hz 的部分可裁剪)
- 特征拼接:将梅尔频谱图与 “梅尔频率倒谱系数(MFCC)” 拼接,同时保留全局频谱和局部细节(MFCC 更侧重语音的语义特征)
输入分类模型预测标签
用擅长 “图像分类” 或 “时序分类” 的模型,学习频谱图与类别的对应关系:
常用模型:CNN(适合从频谱图的 “视觉特征” 分类,如噪音的频谱杂乱、音乐的频谱有规律)、ResNet(解决深层 CNN 的梯度消失问题,提升分类精度)、RNN(捕捉频谱的时序变化,比如愤怒语音的频谱能量波动大)
判断一段频谱图是否为 “婴儿哭声”,模型会学习 “婴儿哭声的频谱集中在 1000~3000Hz,且能量骤升骤降” 的特征,输出 “是” 或 “否” 的标签
结果后处理(提升分类可信度)
概率阈值过滤:若模型预测 “是婴儿哭声” 的概率仅 30%(低于设定的 50% 阈值),则判定为 “未识别”
多帧投票:对一段音频的多个频谱帧(如 100ms 音频的 7 帧)分别分类,取多数帧的标签作为最终结果(避免单帧误判)
总结
梅尔频谱图的本质是 “音频的结构化特征载体”,后续所有操作都围绕 “如何用模型把这个载体转化为任务需要的输出” 展开
识别任务要 “转文字”,生成任务要 “转新音频”,分类任务要 “转标签”
不同场景的差异只在 “模型选择” 和 “细节处理”,但核心都是让模型 “读懂” 频谱图中的音频信息
什么是TMRoPE
Rotary Positional Embedding,旋转位置编码
rotary ˈrəʊtəri
adj. 绕轴转动的;(机器)有旋转部件的,旋转式的
n. <美>环岛,环形交通枢纽;旋转式装置
TMRoPE(Time-aligned Multimodal RoPE,时间对齐多模态旋转位置嵌入)是由通义千问团队提出的新型多模态位置编码方法
核心用于解决文本、音频、图像、视频等多模态数据在时间轴与空间维度上的对齐问题
核心定位:解决多模态数据的 “时空同步难题”
传统位置编码(如标准 RoPE)仅适用于单一模态(如文本),无法处理多模态数据的异质性:
- 文本是 “一维序列”(仅需顺序信息)
- 音频是 “时间序列”(仅需时间维度信息)
- 图像是 “二维空间”(仅需高度、宽度信息)
- 视频是 “时空融合体”(需同时包含时间、高度、宽度信息)
当多模态数据混合输入(如 “文本 + 视频 + 音频”)时,传统编码会导致时间不同步(如音频某句话与视频对应动作错位)、空间信息丢失(如图像像素位置无意义)等问题。TMRoPE 通过多维位置信息融合,让模型能精准感知 “谁在何时何地做了什么”
技术原理:三维位置编码 + 时间对齐策略
TMRoPE 的核心创新是将旋转位置嵌入(RoPE)扩展为时间(temporal)、高度(height)、宽度(width)三维编码,并针对不同模态设计差异化的编码逻辑,同时搭配时间交错策略实现多模态同步:
三维位置编码拆解

示例
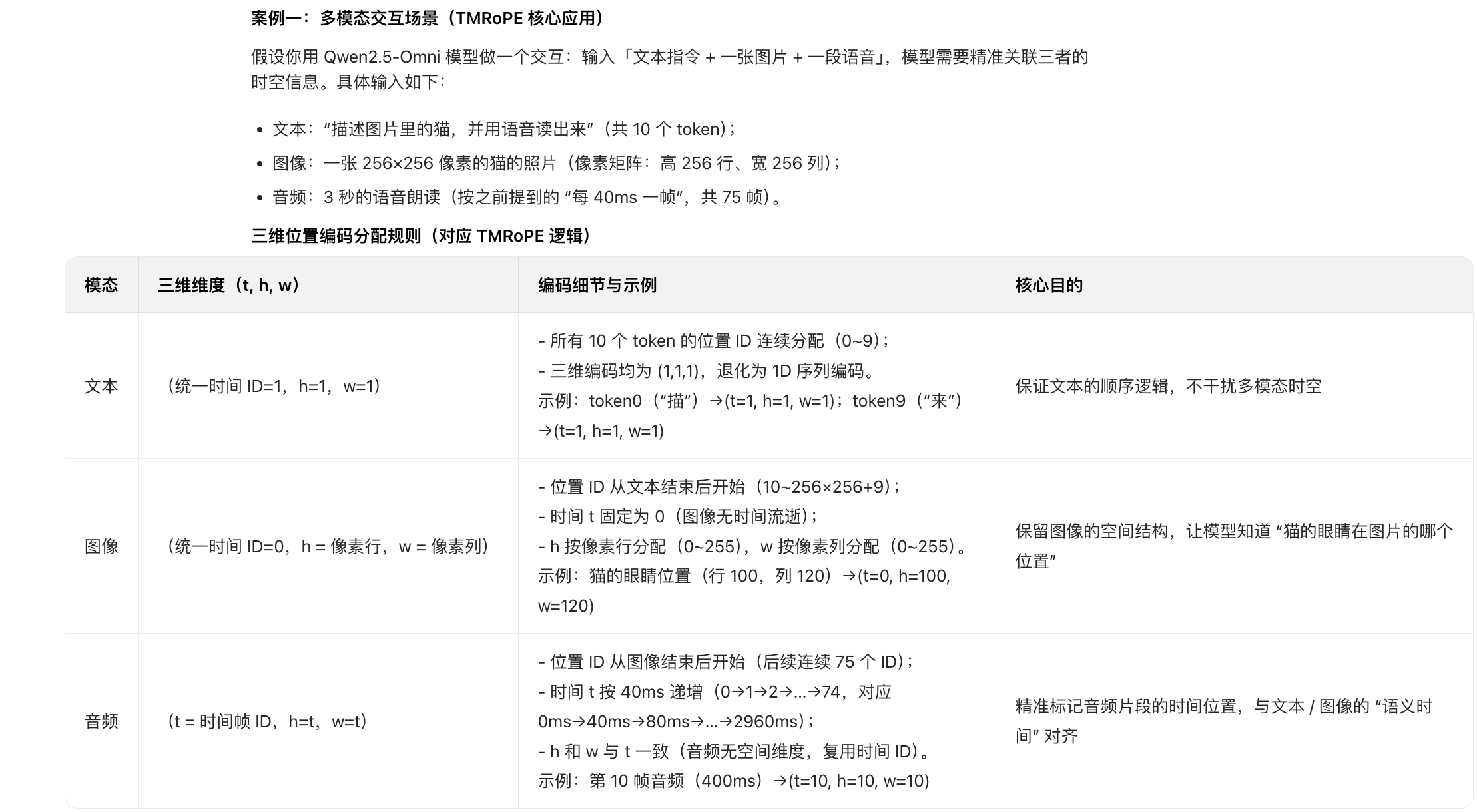
40ms 帧长、10ms 帧移,那么100ms的音频需要7个位置ID
无时间概念
文本:无空间结构、无时间变化 → 时间 ID / 高度 ID / 宽度 ID 都相同(退化为 1 维编码,本质是三维格式的特例)
图像:有空间结构、无时间变化 → 时间 ID 固定,高度 ID / 宽度 ID 按像素位置分配(三维格式,核心是空间二维)
有时间概念
音频:无空间结构、有时间变化 → 高度 ID = 时间 ID、宽度 ID = 时间 ID(三维格式统一,但核心是时间维度)
视频:有空间结构、有时间变化 → 时间 ID 随帧递增,高度 ID / 宽度 ID 按帧内像素位置分配(完整三维编码)

时间交错策略(Time-interleaving)
为进一步强化音视频同步,TMRoPE 会将视频帧与音频片段按时间切块(每 2 秒为一个单位)
以 “视觉在前、听觉在后” 的方式交错排列,让模型能高效关联同一时间窗口内的音视频信息(如视频帧的动作与对应音频的台词)
示例
3 秒美食教程片段(含视频 + 音频)
假设一段 3 秒的美食视频,包含:
视频:共 3 帧(帧率 1 帧 / 秒,简化便于理解),每帧对应 1 秒画面:
- 视频帧 1(0~1 秒):手持土豆的特写;
- 视频帧 2(1~2 秒):刀削土豆的动作;
- 视频帧 3(2~3 秒):土豆丝落在盘中的画面;
音频:3 秒同步旁白(按 40ms 帧长、10ms 帧移,共 75 帧,简化为 3 个关键片段): - 音频段 1(0~1 秒):“首先准备一个土豆”;
- 音频段 2(1~2 秒):“用刀切成细丝”;
- 音频段 3(2~3 秒):“切好后装盘备用”。
3 秒的音视频会被分成 2 个时间窗口块(最后一块不足 2 秒时按实际时长算):
- 窗口 1:覆盖 0~2 秒(完整 2 秒)
- 窗口 2:覆盖 2~3 秒(剩余 1 秒)
对每个窗口内的视频帧(视觉)和音频片段(听觉),先放视觉数据、再放听觉数据,形成 “视觉 - 听觉” 的交错单元,同时分配连续的位置 ID(确保模型能按顺序关联):

关键效果:解决 “音视频不同步” 的核心问题
如果不按这种方式排列,比如把所有视频帧堆在前面、所有音频段堆在后面(视频帧 1→2→3→音频段 1→2→3),模型会看到 “完整切土豆流程” 后才听到旁白,无法对应 “哪个动作配哪句台词”。
TMRoPE 的 “2 秒切块 + 视觉在前、听觉在后” 设计,能让模型在每个小窗口内 “先看画面、再听声音”,自然建立 “动作 - 台词” 的对应关系,就像人看视频时 “边看画面边听解说” 的认知逻辑一致
延伸到实际高帧率场景(更贴近真实情况)
如果视频是 30 帧 / 秒(每帧约 33ms)、音频是 40ms / 帧,2 秒窗口内会包含:
- 视频:60 帧(视觉数据,先连续排列)
- 音频:50 帧(听觉数据,紧跟视频排列)
模型会在这 2 秒窗口内,先处理完 60 帧视频的画面时序,再处理 50 帧音频的语音时序
由于窗口仅 2 秒,画面与声音的时间差被控制在极小范围,完全能感知 “某一帧视频动作(如刀落下的瞬间)” 对应 “某一帧音频(如‘切’的发音)”,实现毫秒级的音视频同步
核心价值
支撑全模态模型的关键能力,TMRoPE 是 Qwen2.5-Omni 实现 “端到端多模态理解与流式生成” 的基础:
- 精准时空对齐:解决音视频时间同步(如语音指令与视频动作匹配)、图像空间信息保留(如识别图片中物体的位置)问题
- 统一模态表示:将文本、音频、图像、视频的位置信息映射到同一向量空间,为多模态融合提供统一基础
- 低延迟流式处理:配合分块处理策略,支持长序列多模态数据的实时处理(如流式语音对话、实时视频分析)
应用场景
- 视频理解与生成:视频问答(精准回答 “何时何地发生了什么”)、自动字幕生成(台词与画面动作对齐)
- 智能监控与安防:跨摄像头目标追踪、异常行为检测(如基于时空轨迹识别逆行)
- 自动驾驶:多传感器融合(对齐激光雷达、摄像头的时空数据)、障碍物预测
- 流式多模态对话:实时语音 + 视频输入的智能交互(如边看视频边提问,模型精准关联上下文)
总结
TMRoPE 本质是 “适配多模态数据的增强型位置编码”
通过三维时空信息建模 + 时间对齐策略,突破了传统 RoPE 仅适用于单一模态的局限
让模型能像人类一样 “同时看、听、理解” 动态世界的时空关联,是下一代全模态 AI 的核心技术之一