从一到无穷大 #54 数据管理中宽表(Wide Table)的问题阐述与解决方案
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- 主要挑战与解决方案
- 列式文件元数据膨胀与解码开销
- 部分列查询导致随机I/O或读放大
- 多列扫描内存问题
- 总结
引言
近年来,随着物联网、车辆数据、机器学习特征工程等场景的兴起,“宽表”(Wide Table)越来越常见,在技术领域,宽表并没有统一的列数阈值定义,但行业内普遍将列数超过1000或远超传统数据库单表最优列数上限(通常200-500列)的表定义为宽表。
- 车联网场景下,一辆L4级智能汽车搭载的激光雷达、毫米波雷达、摄像头等传感器,每天产生的结构化数据涉及车辆状态、环境感知、控制指令等1k+字段
- AI训练场景中,特征工程后的用户行为宽表,仅用户画像维度就可能包含基础属性、兴趣标签、行为序列等10k+列
- 工业互联网场景下,一台高端数控机床的实时监控宽表,需记录主轴转速、进给速度、温度压力等1k+监测指标。
在时序数据库中我们经常遇到宽表的场景,在Compactor,查询的场景下带来了非常多的挑战,但是这些并不是特有的,数据管理中对于宽表的解决方案已经有了非常多的研究,这篇文章中希望可以在我的角度谈一下这个宽表在不同场景带来的挑战和业界对应的解决方案。
主要挑战与解决方案
列式文件元数据膨胀与解码开销
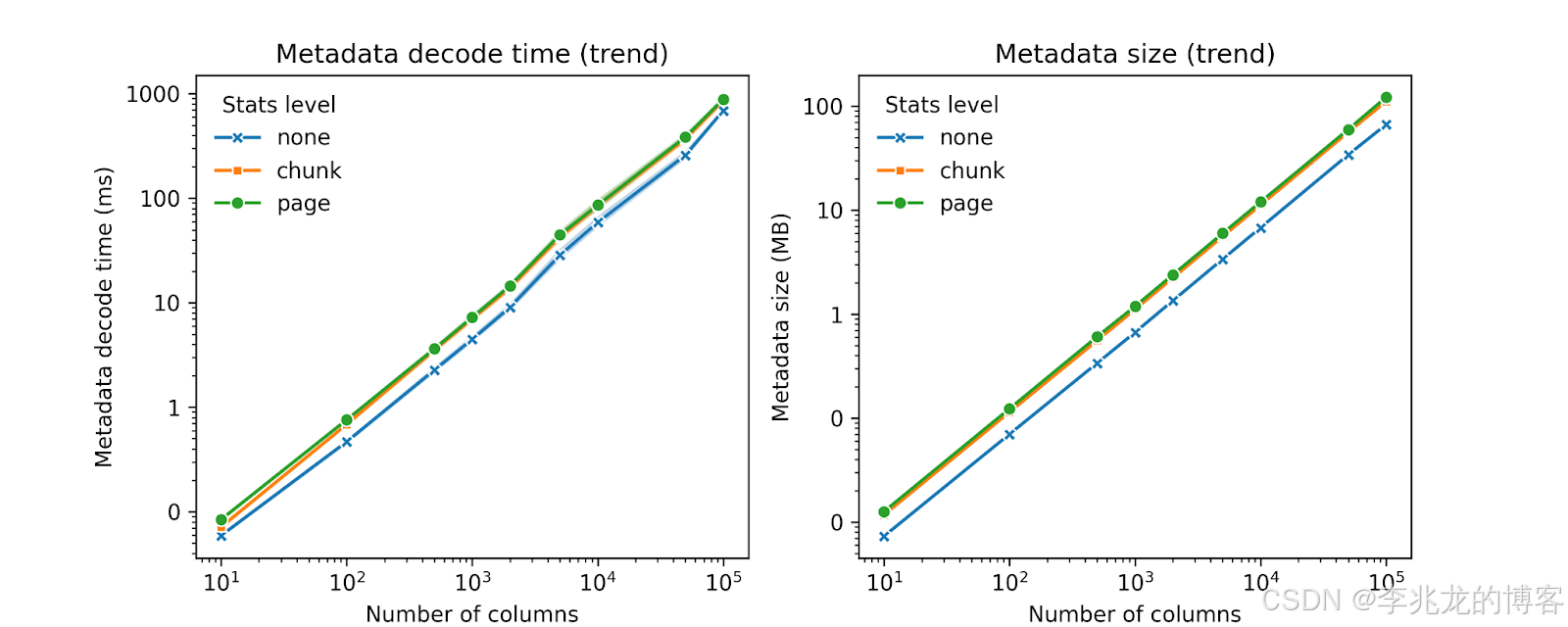
现代湖仓常用列式文件格式(如 Parquet、ORC)存储宽表,其优势是只读取需要的列。但 Parquet 等格式每个文件分为多个“行组(Row Group)”,每个行组对每列都维护列块元数据。随着列数和行组数量增加,文件的元数据(schema、统计信息、索引等)会成倍增长。
上图我们可以看到Parquet 文件的元数据大小和内存消耗与列数和行组数成线性增长,并且每次查询都需要解析这些元数据,开销可观。若宽表仅查询部分列,仍要解析整个文件的元数据,多次解码更是慢。
本质的原因可以抽象为:
- Meta使用 Thrift 或 Protocol Buffers,无法逐列解析,少量列的投影也需要全部解码
- 现有格式解码性能不够
- RowGroup的概念使得元数据分布在文件多处,一个文件的数据需要多次元数据解码
虽然[5][12]提出了一些工程思路解决,比如更好的分配器、优化的内存布局, SIMD 加速,RowGroup内的列重组,RowGroup之间的列合并等,但是都不如彻底重构文件格式来的彻底。
以[7]F3(Future-proof File Format)中为例:


把meta抽到文件末尾,每一列的元数据使用FlatBuffer解码,以解决上面提到的问题。
F3,Nimble,Lance,krypton等文件格式对于元数据的处理思路基本一致,只不过在一些细节上有一些场景的考虑,比如F3就把Wasm二进制嵌入到文件格式,把编解码视为插件,以支持不同版本的库不修改代码即可支持最新编码(存在(10–30%的性能下降)
部分列查询导致随机I/O或读放大
宽表查询时,分为两种查询特征:
- 聚合查询,只关注列集合中的一小部分列(比如几个指标的聚合查询)select agg(x), agg(y), agg(z)
- 需要查询单维度,相当一部分列(车联网场景查询多个传感器信息)select x, y ,z
第一种情况往往只关注列集合中的一小部分特征,如果采用列式存储,不同列的数据物理上可能散布在文件中(每个行组不同偏移):
- 如果不做IO合并,这会导致频繁的小范围随机 I/O
- 如果做IO合并,就会可能出现严重的读放大
- 对象存储中尾延较高,就算使用8MB-16MB这样测试较优[13]的经验值,部分查询也可能会非常慢。
这里的解决方案比较工程,对于少部分列的聚合,[1][5][3]中均使用列合并的策略减少常用列在物理布局中的离散程度。本质上是在后台重写文件,找到一个最优的物理布局解决方案,该方案能在有序列布局上实现最小读取成本,在列排序步骤中,我们只需尽可能减小共同访问列块之间的距离,也就是把经常访问的列在物理上放置在一起,[1]中已经证明了这是一个NP问题,其实现的基于模拟退火的列排序算法可直接用于解决对象中的RowGroup内的列排序问题。
为了减小多个RowGroup的多次IO,一种解决问题的方式是RowGroup合并,如果有新的文件格式当然最好,没有的话简单的在重写中增大RowGroup的大小。
为了解决尾延较高的问题,通常使用Straggler Mitigation(类似于Racing Reads )的方案,即在查询时间超过预期时发起多次IO,取其中较快的查询结果返回。
针对于第二种单维度扫描的场景,其实列存就不是最好的解决问题的方式了,是一个典型的行存场景,Lindorm-UWC则是典型的解决方案,即打包value到一个value中,多个列的查询一个IO就可以解决,如果存在少量的聚合请求,还可以引入列存索引来加速聚合查询。

如果使用HBase,100个metric就会转化为100个kv查询。
多列扫描内存问题
当一次查询需要读取几十到几百列时,所需的内存开销也随之大幅增加,这个问题目前没有看到系统性的解决方案。也是困扰我的难题之一。
内存消耗集中在两个地方:
- 每个列文件的列块(page)需要加载到内存,使用了块压缩是page会被放大10倍以上。
- 另一方面,执行算子在处理列数据时也要在内存中持有多份列向量。
如果对文件的顺序没有依赖这并不是一个大问题,因为内存的开销集中在TableScan算子,只需要给每个TableScan添加Split就可以了,开销只有一份,但是在LocalMerge时,基本使用基于loserTree的归并排序,要求输入有序,如果输入文件较多,就需要文件数*列数的内存开销,因为整个过程是流式的,内存在查询执行完成前也不会释放,这出现在多文件的去重场景,Compactor和查询中都可能遇到。
目前的解决方案就只是减小page大小,减小计算引擎的Batch大小,减小输入文件数的调参来解决这个问题。
总结
宽表的问题本质是存储布局与查询需求的错配,也是业务场景演进过程中必然会发生的问题。当存储格式无法适配宽表的列数规模和访问模式时,各种痛点自然会暴露。解决问题的关键不在于追求万能格式,而在于实现场景-存储-查询的三重匹配。
站在业务选型的角度,查询特征,数据特征都成为技术选型的关键,反过来看,也更容易让我们清楚某个产品的独到优势。
以时序数据库为例,要求实时,高性能,低成本,查询场景多为聚合,偶尔为扫描的情况,反推真正的有优势的架构是什么,反而我认为时序数据库走类似Lakehouse的路不对,因为写入性能差,查询性能也受制于对象存储,需要高效的预取,缓存等机制。反而是X-Stor TSDB当前的架构是很优秀的,即保留了实时查询的性能和实时性,又保证了基于对象存储的成本和大规模分析的稳定性。
参考:
- Wide table layout optimization based on column ordering and duplication
- Lindorm-UWC: An Ultra-Wide-Column Database for Internet of Vehicles
- Magnus: A Holistic Approach to Data Management for Large-Scale Machine Learning Workloads
- The Hopsworks Feature Store for Machine Learning
- Pixels: An Efficient Column Store for Cloud Data Lakes
- Optimizing Data Pipelines for Machine Learning in Feature Stores
- F3: The Open-Source Data File Format for the Future
- Lance: Efficient Random Access in Columnar Storage through Adaptive Structural Encodings
- Shared Foundations: Modernizing Meta’s Data Lakehouse
- https://github.com/facebookincubator/nimble
- Compactor: A hidden engine of database performance
- How Good is Parquet for Wide Tables (Machine Learning Workloads) Really?
- Exploiting Cloud Object Storage for High-Performance Analytics