“RAG简单介绍
“RAG” 的英文缩写也是“检索生成增强”,是 “Retrieval-Augmented Generation” 的简称。它是一种结合了信息检索和文本生成的人工智能技术,旨在通过从外部知识库中检索相关信息来辅助语言模型输出,从而提高响应的质量和准确性。
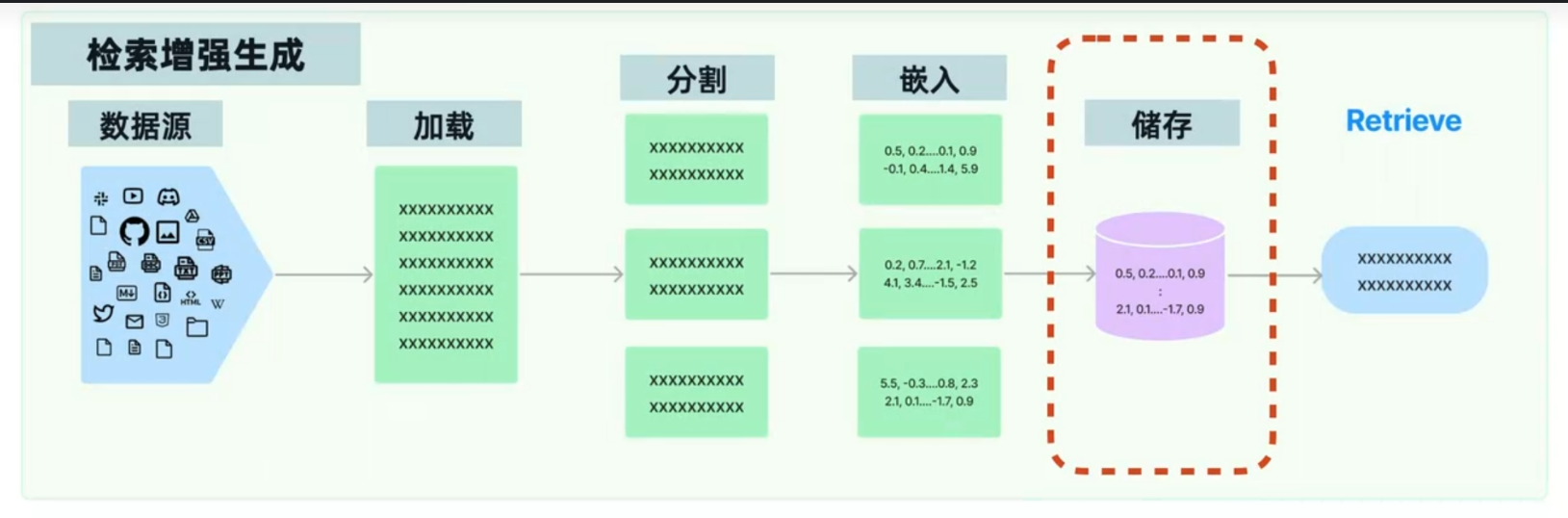
这个也就是前面我们深度学习的,把我们的数据通过语义相关来存储一篇内容,然后检索生成增强来生成一段信息。下面我来举出几个例子
1 加载本地文件
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./llama2.pdf")
docs = loader.load()
print(docs[2].page_content)这样就可以打印第二张的内容。
2 加载网页文件
from langchain.document_loaders import WebBaseLoaderloader = WebBaseLoader("https://www.summerpalace-china.com/intro/")
docs = loader.load() # 自动爬取网页正文内容这样就可以加载一个网页的内容,后面可以根据这个网页里面的内容检索生成增强
3 按格式分隔
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
#%%
loader = PyPDFLoader("./llama2.pdf")
docs = loader.load()
#%%
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50,separators=["\n\n", "\n", "。", "!", "?", ",", "、", ""]
)
#%%
texts = text_splitter.split_documents(docs)
texts例如这里我们按照separators=["\n\n", "\n", "。", "!", "?", ",", "、", ""]这些分开,如果超过500个,最长500个词,超过就分开。并且我们会回溯50个词。例如0-500,450-550’‘’‘’‘’‘这样。
4 加载大模型分词
from langchain_openai import OpenAIEmbeddings
from langchain_community.embeddings import DashScopeEmbeddings
#%%
embeddings_model = OpenAIEmbeddings(model="text-embedding-v2",openai_api_key="你的api",)# 如果你使用的是课程提供的API,则需要提供额外参数
# embeddings_model = OpenAIEmbeddings(model="text-embedding-3-large",
# openai_api_key="<你的API密钥>",
# openai_api_base="https://api.aigc369.com/v1")
#%%
from langchain_community.embeddings import DashScopeEmbeddings
embeddings = DashScopeEmbeddings(model="text-embedding-v2",dashscope_api_key="<你的API密钥>",#dashscope_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)text = "This is a test document."query_result = embeddings.embed_query(text)
print("文本向量长度:", len(query_result), sep='')doc_results = embeddings.embed_documents(["My friends call me TOM","Hello World!"])
print("文本向量数量:", len(doc_results), ",文本向量长度:", len(doc_results[0]), sep='')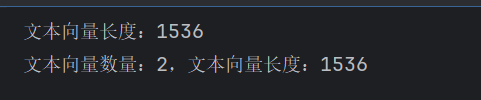
# 如果希望嵌入向量维度更小,可以通过dimensions参数进行指定
embeddings_model = DashScopeEmbeddings(model="text-embedding-v3",dashscope_api_key="api",
# dimensions=1024)embeded_result = embeddings_model.embed_documents(["Hello world!", "You good."])
len(embeded_result[0])5 生成了一个检索器
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.embeddings import DashScopeEmbeddings
#%%
loader = PyPDFLoader("./卢浮宫.pdf")
docs = loader.load()
#有利于查找非结构化信息
#%%
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=100,separators=["\n\n", "\n", "。", "!", "?", ",", "、", ""]
)
#%%
texts = text_splitter.split_documents(docs)
texts
#%%
embeddings_model = DashScopeEmbeddings(model="text-embedding-v2",dashscope_api_key="你的api",# base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
# dimensions=1024)
#%%
db = FAISS.from_documents(texts, embeddings_model)
'''
# 分批处理文档
batch_size = 10
for i in range(0, len(texts), batch_size):batch_docs = texts[i:i+batch_size]if i == 0:# 第一批文档创建数据库vectordb = FAISS.from_documents(documents=batch_docs,embedding=embeddings_model,persist_directory=persist_directory)else:# 后续批次添加到数据库vectordb.add_documents(batch_docs)
'''
retriever = db.as_retriever()
#定义一个检索器
retrieved_docs = retriever.invoke("卢浮宫这个名字怎么来的?")
print(retrieved_docs[0].page_content)这样就生成了一个检索器。
6 加载记忆模块
from langchain.chains import ConversationalRetrievalChain
#带记忆的索引增强生成对话链
from langchain.memory import ConversationBufferMemory
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.embeddings import DashScopeEmbeddings
#%%
!pip install --upgrade cryptography
loader = PyPDFLoader("./卢浮宫.pdf")
docs = loader.load()
#%%
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=40,separators=["\n", "。", "!", "?", ",", "、", ""]
)
#%%
texts = text_splitter.split_documents(docs)
#%%
embeddings_model = DashScopeEmbeddings(model="text-embedding-v2",dashscope_api_key="你的api",# base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
# dimensions=1024)
#%%
db = FAISS.from_documents(texts, embeddings_model)
#%%
retriever = db.as_retriever()
#%%
model = ChatOpenAI(model="qwen-plus",openai_api_key="你的api",openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1")
#%%
memory = ConversationBufferMemory(return_messages=True, memory_key='chat_history', output_key='answer')
#%%
qa = ConversationalRetrievalChain.from_llm(llm=model,retriever=retriever,memory=memory
)
#%%
question = "卢浮宫这个名字怎么来的?"
qa.invoke({"chat_history": memory, "question": question})
#%%
memory
#%%
question = "对应的拉丁语是什么呢?"
qa.invoke({"chat_history": memory, "question": question})
#%%
qa = ConversationalRetrievalChain.from_llm(llm=model,retriever=retriever,memory=memory,return_source_documents=True#显示回答参考的原片段
)
#%%
question = "卢浮宫这个名字怎么来的?"
qa.invoke({"chat_history": memory, "question": question})这个就是有一个记忆器,可以存储我们问过的信息