Linux下的简单进度条程序
目录
缓冲区
程序实现步骤:
1、编写make指令
2、实现具体代码编辑编辑
缓冲区
Linux下设计缓冲区的核心目的是解决 “速度不匹配” 问题,通过在不同速度的设备 / 模块之间加入 “暂存层”,优化数据传输效率、降低资源开销,最终提升整个系统的性能与稳定性。
直接向屏幕(属于慢速 IO 设备)写入数据效率很低。缓冲区会先暂存数据,等满足特定条件时再一次性写入屏幕,减少 IO 操作次数,提升程序运行速度。(空间换时间)
例如:
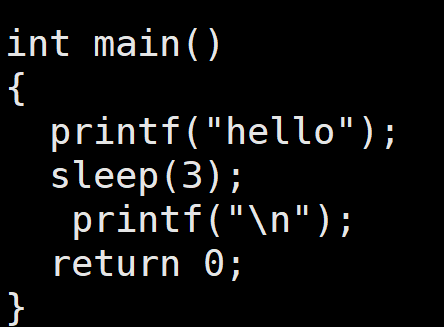
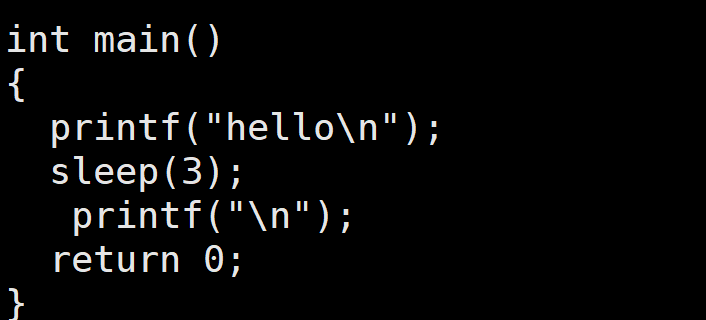
在Linux上运行上面两个代码可以看到下面的立刻就打印出来hello,而上面的则是过了一段时间后才打印。这是因为打印的内容并不是一开始就输入到屏幕文件中,而是先输入到缓冲区中。而换行符 '\n' 具备刷新缓冲区的功能,故下面才能立刻将打印内容输入到屏幕中。
缓冲区刷新的三个条件:
- 遇到换行符
\n:这是行缓冲模式的核心特性,只要输出中包含\n,缓冲区会立即将当前内容刷新到屏幕 - 调用
fflush(stdout):这是强制刷新的函数,无论缓冲区是否满、是否有\n,都会立即将缓冲区内容写入屏幕。 - 缓冲区已满或程序结束:当缓冲区存储的数据达到上限(通常是 4096 字节),或程序正常退出(执行到
return 0)时,缓冲区也会自动刷新
程序实现步骤:
1、编写make指令
先明确一下我们实现进度条程序的过程步骤:首先,我们采用多文件的形式--这意味着需要实现编译链接多个文件;其次,清理工作必不可少。
先依照实现目标的中间过程来编写make指令(就是怎么处理那些代码文件什么的),把那些需要反复使用的指令编写出make指令减少开发负担。
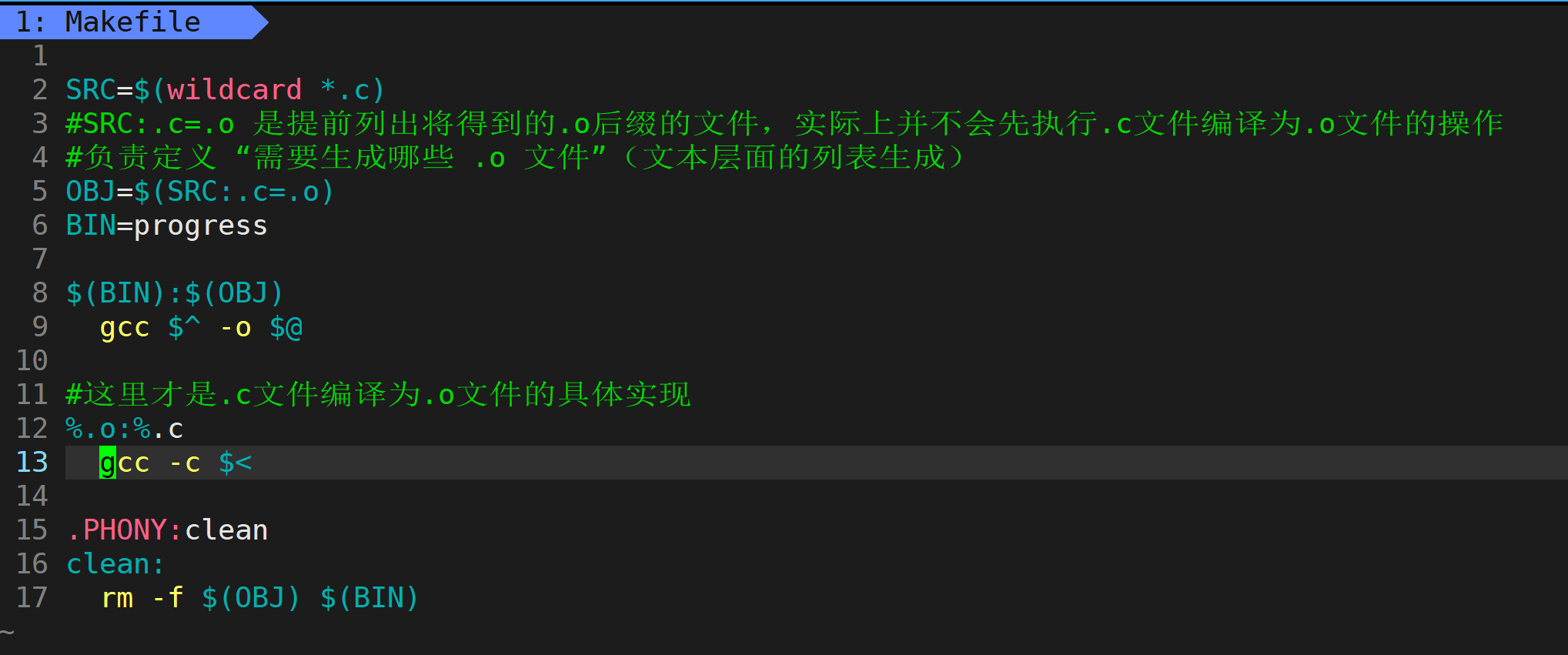
稍微解释一下make的逻辑:因为要将多个源文件(.c)编译为.o文件后再进行链接(.h头文件 gcc自动动态链接)。故先用SRC确定文件中所有的.c 文件,用OBJ提前确定所有.c文件经gcc -c编译后的.o文件(只是提前知道名字,并不会执行编译)。再将.c文件全部gcc -c 编译为.o文件,最后将所有的.o文件链接到一起。
2、实现具体代码
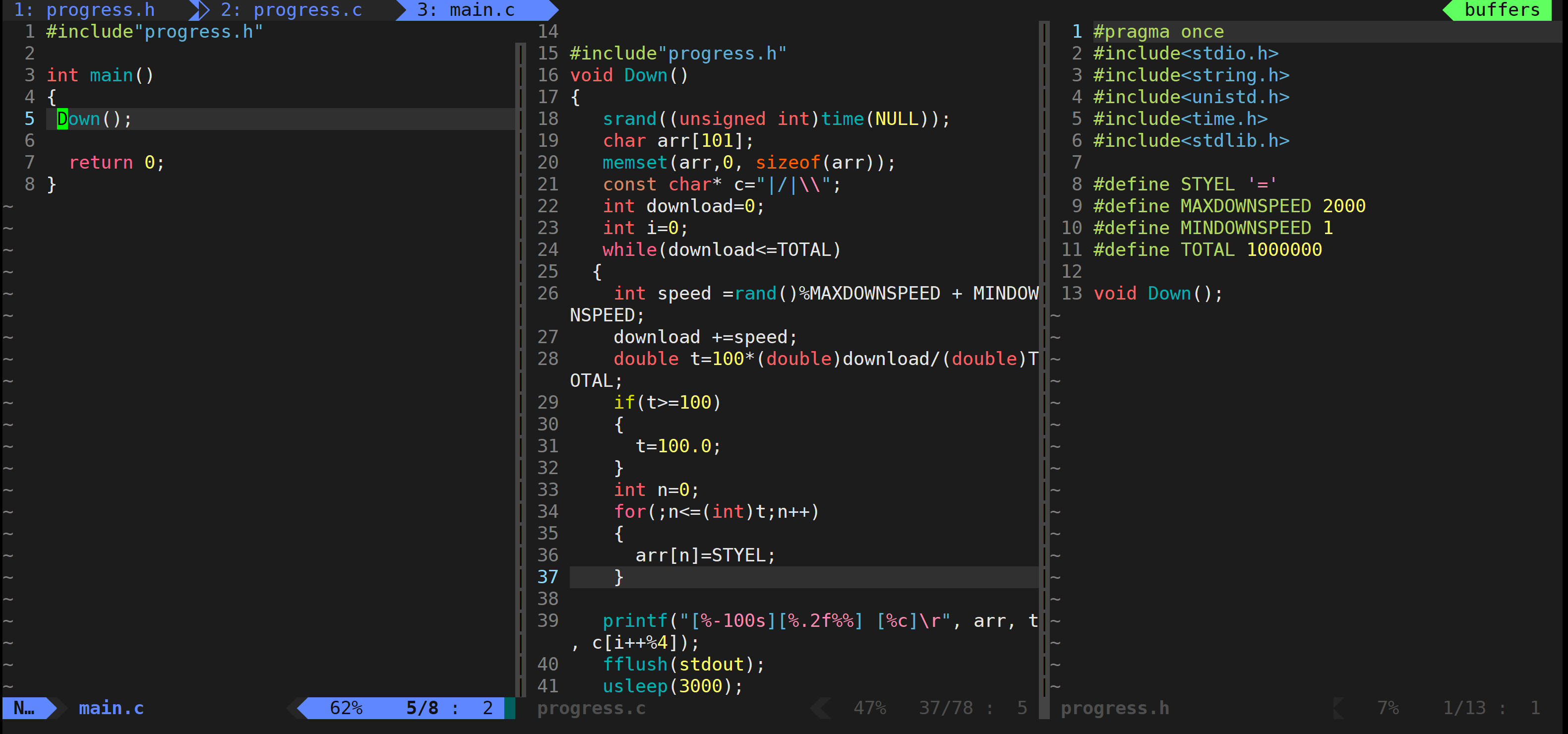
我这只是简单模拟一下进度条,这次主要的目的是掌握Linux上的简单程序编写过程,对于进度条程序的编写到是其次的。
注意事项:
1.用宏定义来确定某些值,当其需要改动的时候只需要改动宏就行。
2.进度条的推进需要不断刷新缓冲区,如果使用换行符刷新就不符合实际,这时候就用函数fflush(stdout)来刷新缓冲区。
3.每次刷新的时候进度条都要进行回车(\r),并且是左对齐。
4.进度条需要一个不断变化的光标来判断程序是否卡死
5.因为上面是模拟了网络波动下载速度并不确定的情况,故当循环内计算下载量大于下载包大小时需要将下载量改为总包大小(上面偷懒了没改),以及将下载百分比改为100%
另外还需要注意的是:如果每次while循环末不增加usleep让其“休息一下”的话光标会因为节奏过快导致终端来不及反应导致光标乱跳,增加usleep降低了进度条的更新频率,给终端足够的时间处理光标定位和内容刷新。